本文主要是介绍Detecting Twenty-thousand Classes using Image-level Supervision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Detecting Twenty-thousand Classes using Image-level Supervision
- 摘要
- 背景方法
- Preliminaries
- Detic:具有图像类别的检测器
- loss
- 技术细节扩展
- Grad-CAM
- Grad-CAM原理
- 总结
摘要

摘要 由于检测数据集的规模较小,目前的物体检测器在词汇量方面受到限制。而图像分类器的数据集更大,也更容易收集,因此它们的词汇量要大得多。我们提出的 Detic 只需在图像分类数据上训练检测器的分类器,从而将检测器的词汇量扩展到数以万计的概念。与之前的工作不同,Detic 不需要复杂的分配方案,就能根据模型预测将图像标签分配给方框,因此更容易实现,并与一系列检测架构和骨干兼容。我们的研究结果表明,即使对于没有方框注释的类别,Detic 也能生成出色的检测器。它在开放词汇和长尾检测基准上的表现都优于之前的工作。在开放词汇 LVIS 基准上,Detic 为所有类别带来了 2.4 mAP 的增益,为新类别带来了 8.3 mAP 的增益。在标准 LVIS 基准上,如果对所有类别或仅对稀有类别进行评估,Detic 可获得 41.7 mAP,从而缩小了样本较少的对象类别的性能差距。我们首次使用 ImageNet 数据集的全部 21000 个类别来训练检测器,并证明它无需微调即可泛化到新的数据集。代码见 https://github.com/facebookresearch/Detic 。
现阶段的目标检测器的性能已经到了一个瓶颈。
- 作者认为限制其性能进一步提升的主要原因是其可获得的训练数据量规模太小。
- 另一方面,图像分类的数据量就相对来说大得多同时更加容易收集,也因此图像分类可以在更大规模的词汇表上进行推理。
作者基于此,提出了自己命名为Detic的目标检测训练方法,其可以非常简单的使用图像分类的数据集来对目标检测器的分类头进行训练。简单,是Detic的最大卖点,之前的类似弱监督的工作都是基于预测然后进行box-class的分配,实现起来十分繁琐且兼容性很差,只能在特定的检测器结构上进行训练,Detic则可易于实现,在大部分的检测建构和backbone上都可以接入使用。
背景方法

物体检测包括两个子问题:寻找物体(定位)和命名物体(分类)。传统方法将这两个子问题紧密结合在一起,因此依赖于所有类别的盒式标签。尽管做了很多数据收集工作,但检测数据集 [18 , 28 , 34 , 49] 的总体规模和词汇量都远远小于分类数据集 [10]。例如,最近的 LVIS 检测数据集 [18] 有 1000 多个类别,12 万张图像;OpenImages [28] 有 500 个类别,180 万张图像。此外,并非所有类别都包含足够的注释来训练强大的检测器(见图 1 顶部)。在分类方面,即使是已有十年历史的 ImageNet [10] 也有 21K 个类别和 1400 万张图片(图 1 底部)。
现阶段目标检测的标注数据量相对于图像分类来说少得太多,LVIS 120K的图片,包含了1000+类,OpenImages 1.8M的图片,包含了500+类,而10年前的古董级图像分类数据集ImageNet就有21K个类别、14M的图片数目。在有限的类别上训练出来的目标检测器,总是会出现差错。而Detic使用了图像分类的数据,能够检测出得类别就更加多样、更加精确。如下图所示,一个普通的LVIS检测器将狮子检测成了熊,将狐狸检测成了水獭,而Detic则检测正确。
传统的目标检测将分类和定位耦合在一起,对训练的数据集有较高的要求,数据集需要包括物体的种类,以及bbox位置信息,这就导致了要检测多少类就需要多少类的数据标注。
而detic将分类与定位解耦成两个问题,在定位时不再那么依赖标注数据。

在本文中,我们提出了带图像类别的检测器(Detic),它除了检测监督外,还使用图像级监督。我们发现,定位和分类子问题可以解耦

因此,我们将重点放在分类子问题上,使用图像级标签来训练分类器并扩大检测器的词汇量。我们提出了一种简单的分类损失,将图像级监督应用于规模最大的提案,而不对其他有图像标签的数据输出进行监督。这种方法易于实现,并能大量扩展词汇量。
对于采用第二种数据如何定位,文中没有细说(文中的重点是分类),但是提到了用的是弱监督学习的思想,目前在弱监督学习的定位中采用最多的方法是 Gard-Cam(detic可能不是用的这个,但是感觉应该是一样的思想)。Gard-cam起初是用来可视化CNN任务的,稍作修改即可用来定位。

我们发现问题,并提出一个更简单的替代现有的弱监督检测技术在开放词汇设置。
我们提出的损失族显著提高了新类别的检测性能,与监督性能上限非常匹配。
我们的检测器无需微调即可转换到新的数据集和词汇
- 作者找到现阶段目标检测弱监督训练出现的问题,并使用了更简单易用的替换方案。
- 作者为了使用图像级别的监督信号,提出了一个新的损失函数,实验表明,这个损失函数可以非常有效地提升目标检测器的性能,尤其是在novel class的检测中。
- 作者训练出来的目标检测器可以无需微调,直接迁移到新的数据集和检测词汇表上。
Preliminaries

我们使用对象检测和图像分类数据集来训练对象检测器。我们提出了一种简单的方法来利用图像监督来学习对象检测器,包括没有盒子标签的类。我们首先描述目标检测问题,然后详细说明我们的方法

问题设置。给定一幅图像,目标检测解决两个子问题:( 1)定位:找到所有目标及其位置,表示为一个盒子 😭 2)分类:给第j个目标分配一个类别标签cj 。这里C test是用户在测试时提供的类词汇。
在训练期间,我们使用检测数据集,词汇C det既有类标签又有box标签。我们还使用图像分类数据集,词汇表C cls只有图像级类标签。词汇C test、C det、C cls可能重叠,也可能不重叠。

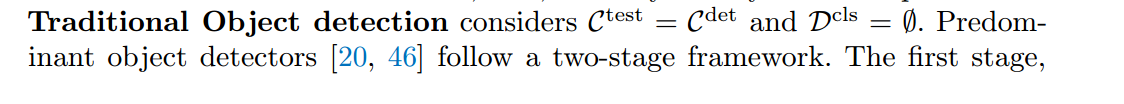

传统的对象检测认为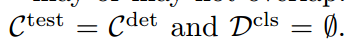 ,主要的目标检测器遵循两阶段框架。
,主要的目标检测器遵循两阶段框架。
第一阶段,称为区域建议网络(RPN),取图像I并生成一组对象建议: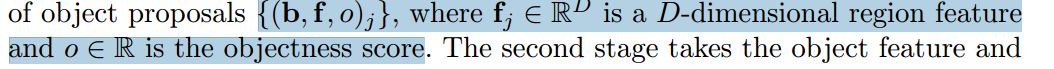
第二阶,段取对象特征,输出每个对象的分类评分和细化后的盒子位置。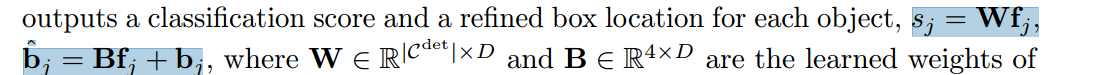
w,b分别是分类层和回归层的学习权重。

我们的工作重点是在第二阶段提高分类。在我们的实验中,RPN和边界框回归器并不是当前的性能瓶颈,因为现代探测器在测试中使用了过多的建议数量(每张图像< 20个对象使用1K个建议)。
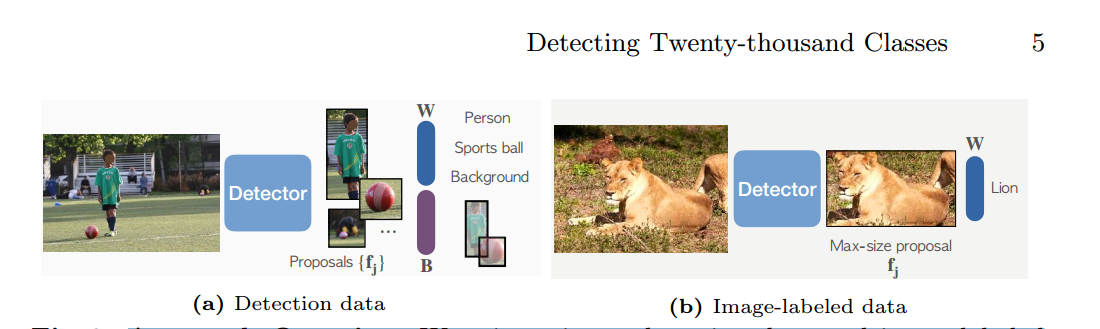

方法概述。我们在检测数据和图像标记数据上混合训练。当使用检测数据时,我们的模型使用标准检测损失来训练检测器的分类器(W)和盒预测分支(B)。当使用图像标记的数据时,我们仅使用我们修改的分类损失来训练分类器。
我们的损失训练从最大尺寸的提议中提取的特征。
Detic的数据集分为两类,一种是传统目标检测数据集,一种是label-image数据(可以类比为图像分类的数据,没有bbox信息)。
对于第一种数据来说,训练时就按照传统目标检测的流程进行,得到分类权重
以及bbox预测分支
,对于第二种数据来说,我们只训练来自固定区域的特征进行分类。使用这两种数据可以训练种类更多的分类器(跟传统的目标检测相比降低了数据获取的成本)。
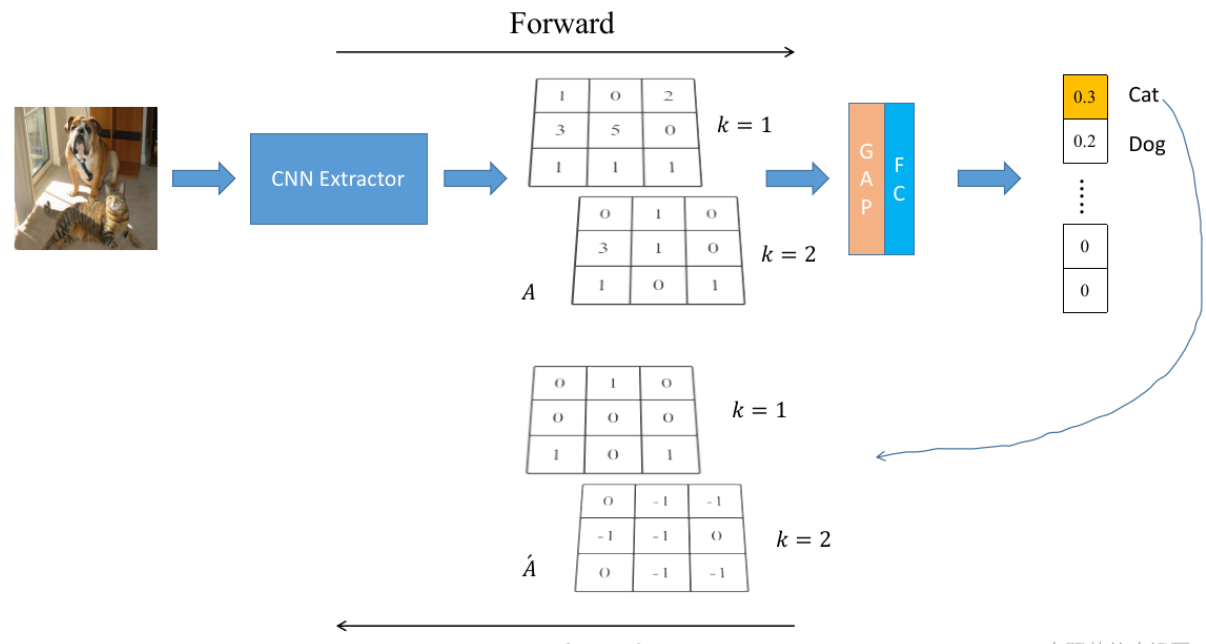
Detic:具有图像类别的检测器

如图3所示,我们的方法利用了来自检测数据集Ddet的盒子标签和来自分类数据集Dcls的图像级标签。在训练期间,我们使用来自两种类型的数据集的图像组成一个小批量。对于带有方框标签的图像,我们遵循标准的两阶段检测器训练[46]。对于图像级标记图像,我们只训练来自固定区域的特征进行分类。因此,我们只计算具有GT标签的图像的定位损失(RPN损失和边界盒回归损失)。下面,我们描述我们改进的图像级标签的分类损失。

如上图所示,一个普通的LVIS检测器将狮子检测成了熊,将狐狸检测成了水獭,而Detic则检测正确。
loss
弱监督目标检测
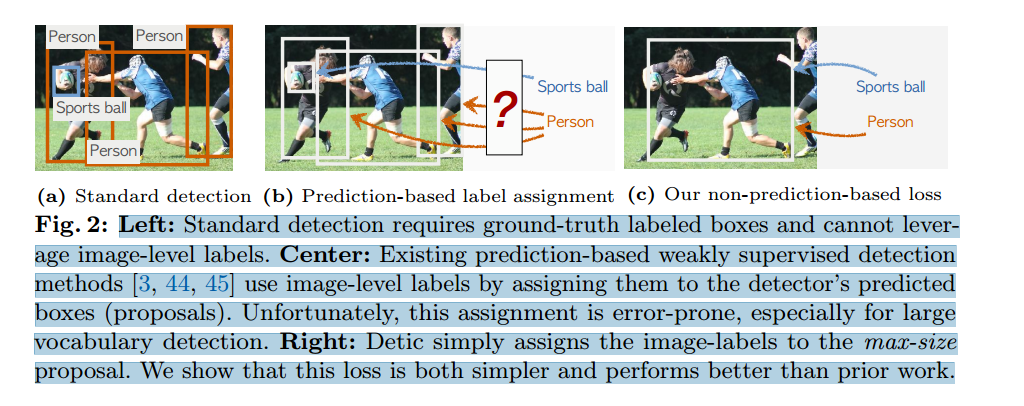
左图:标准检测需要地面实况标签盒,无法利用图像级标签。
中间: 现有的基于预测的弱监督检测方法[3, 44, 45]通过将图像级标签分配给检测器的预测框(建议)来使用图像级标签。遗憾的是,这种分配容易出错,尤其是在大词汇量检测中。
右图 Detic 只需将图像标签分配给最大尺寸的提议。我们的研究表明,这种损失比之前的工作更简单,性能也更好。


其中 f 代表proposal对应的RoI feature,c是最大的proposal对应的类别,也就是是该图片对应的类别,W是分类器的权重。同时,再加上传统目标检测器里使用的loss,就组成了Detic的最终loss。
参考文献1
参考文献2
技术细节扩展
关于使用分类数据集训练网络模型,完成定位,文中没有细说(文中的重点是分类),但是提到了用的是弱监督学习的思想,目前在弱监督学习的定位中采用最多的方法是gard-cam(detic可能不是用的这个,但是感觉应该是一样的思想)…
Grad-CAM
论文名称:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
论文下载地址:https://arxiv.org/abs/1610.02391
推荐代码(Pytorch):https://github.com/jacobgil/pytorch-grad-cam
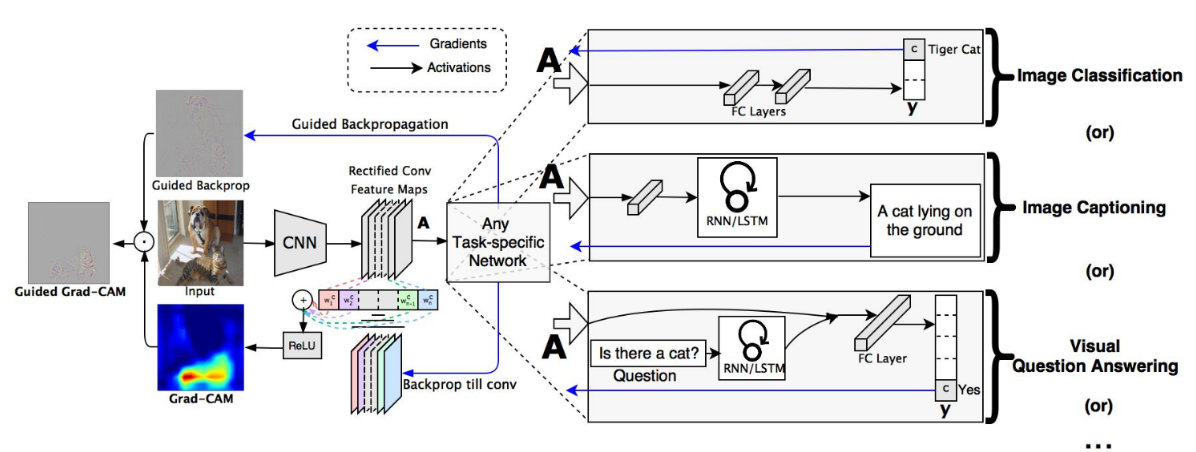
对于常用的深度学习网络(例如CNN),普遍认为是个黑盒可解释性并不强(至少现在是这么认为的),它为什么会这么预测,它关注的点在哪里,我们并不知道。很多科研人员想方设法地去探究其内在的联系,也有很多相关的论文。通过Grad-CAM我们能够绘制出如下的热力图(对应给定类别,网络到底关注哪些区域)。Grad-CAM(Gradient-weighted Class Activation Mapping)是CAM(Class Activation Mapping)的升级版(论文3.1节中给出了详细的证明),Grad-CAM相比与CAM更具一般性。CAM比较致命的问题是需要修改网络结构并且重新训练,而Grad-CAM完美避开了这些问题。本文不对CAM进行讲解,有兴趣的小伙伴自行了解。
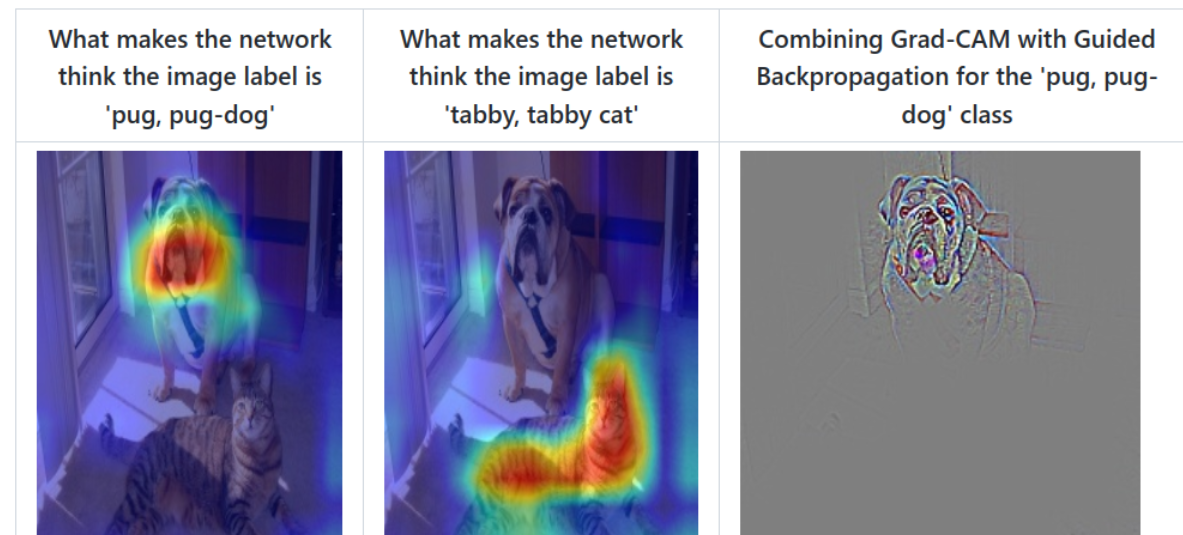
我们通过网络关注的区域能够反过来分析网络是否学习到正确的特征或者信息。在论文6.3章节中举了个非常有意思的例子,作者训练了一个二分类网络,Nurse和Doctor。如下图所示,第一列是预测时输入的原图,第二列是Biased model(具有偏见的模型)通过Grad-CAM绘制的热力图。第三列是Unbiased model(不具偏见的模型)通过Grad-CAM绘制的热力图。通过对比发现,Biased model对于Nurse(护士)这个类别关注的是人的性别,可能模型认为Nurse都是女性,很明显这是带有偏见的。比如第二行第二列这个图,明明是个女Doctor(医生),但Biased model却认为她是Nurse(因为模型关注到这是个女性)。而Unbiased model关注的是Nurse和Doctor使用的工作器具以及服装,明显这更合理。

Grad-CAM原理



参考文献3
参考文献4
总结
Unfortunately, this assignment requires good initial detections which leads to a chicken-and-egg problem–we need a good detector for good label assignment, but we need many boxes to train a good detector. Our method completely side steps the label assignment process by supervising the classification sub-problem alone when using classification data.
不幸的是,这种分配需要良好的初始检测,这会导致先有鸡还是先有蛋的问题——我们需要一个好的检测器来实现良好的标签分配,但我们需要很多盒子来训练一个好的检测器。 我们的方法通过在使用分类数据时单独监督分类子问题来完全回避标签分配过程
这里说的是弱监督检测器:对于完全的弱监督学习来说,定位依赖于检测结果
Detic解决的问题:对于传统目标检测任务,数据标注比较麻烦;对于完全的弱监督学习来说,定位依赖于检测结果。
所以detic采取了一个中合的办法
这篇关于Detecting Twenty-thousand Classes using Image-level Supervision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









