本文主要是介绍ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:https://arxiv.org/pdf/2102.03334.pdf
代码地址:https://github.com/dandelin/vilt.

摘要
目前的VLP方法严重依赖于图像特征提取过程,其中大部分涉及区域监督(如目标检测)和卷积体系结构(如ResNet)。虽然在文献中被忽略了,但我们发现在效率/速度方面存在问题,简单地提取输入特征比多模态交互步骤需要更多的计算,本文在总结了以往多模态学习工作的基础上,提出了一种新的多模态学习方法,它是第一个基于patch projection的多模态预训练模型,首个使用patch projection来做visual embedding的方法。证明了可以将BERT的方法和Vison Transformer结合起来用于多模态transformer。体现了全词掩码在预训练时以及图像增强在微调时的重要性。
背景
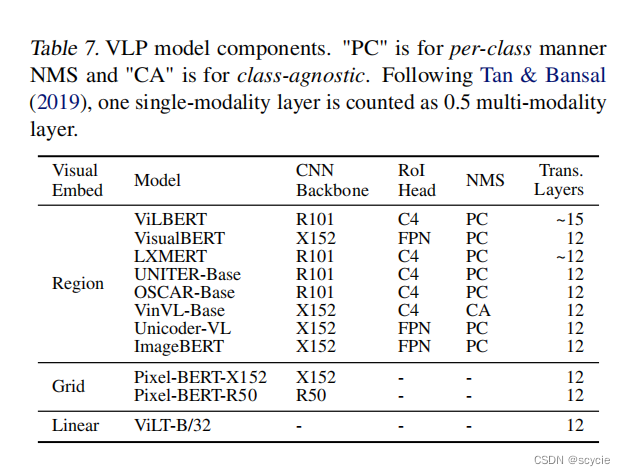
以往的图像提取方法有两种,一种是基于目标检测的语义特征提取,一种是基于卷积神经网络的特征提取,无论以上哪一种,都出现了图像处理计算资源过大的问题。这篇文章用VIT的方法改进了图像特征处理的方法。
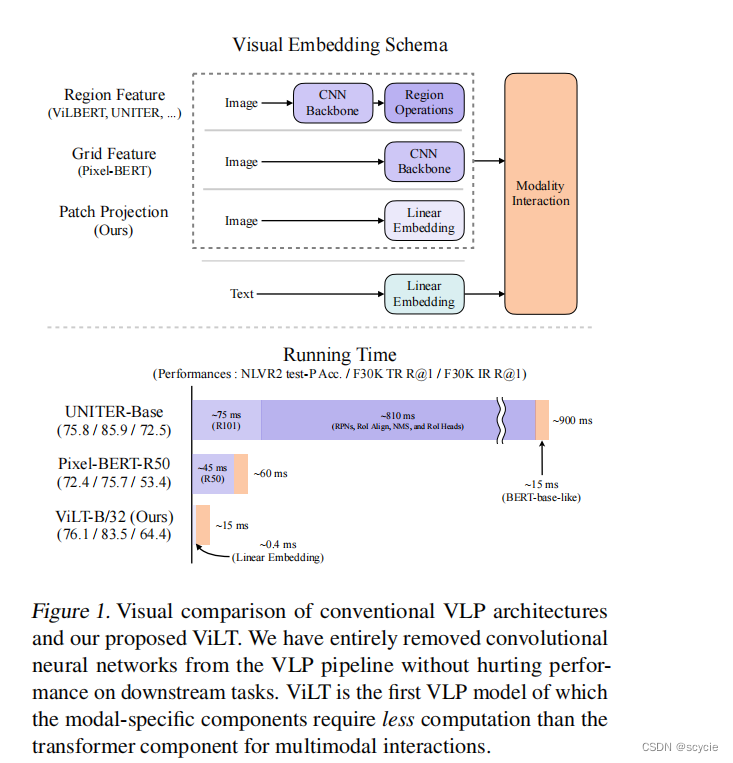
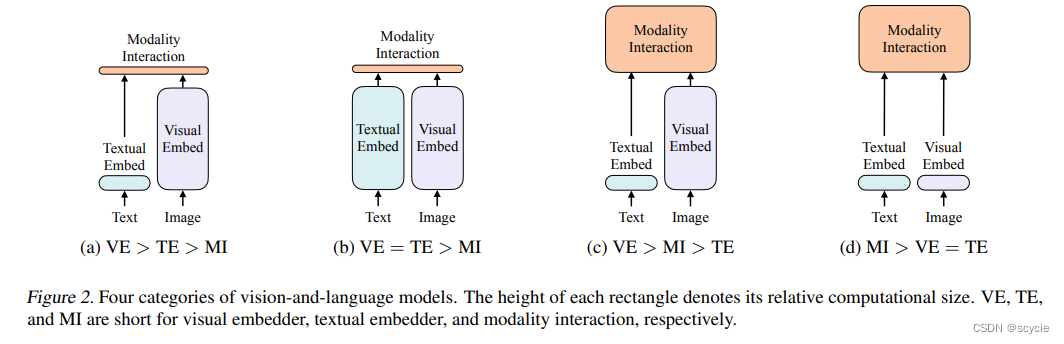
下图分别为以往的多模态学习分类的方法,前两种以文本和图像的特征提取为主要任务,后两种在多模态特征融合的方式上为主要任务。
(a) 如VSE等,对图像和文本独立使用encoder,图像的参数量更大,文本的更轻,使用简单的点积或者浅层attention层来表示两种模态特征的相似性
(b) 如CLIP等,个模态单独使用参数量大的transformer encoder,使用池化后的图像特征点积计算特征相似性。
© ViLBERT、UNTER等。这些方法使用深层transformer进行交互作用,但是由于vison embbeding仍然使用参数量大的卷积网络进行特征抽取,导致计算量依然很大。
本文提出的模型基于(d)类结构,其将VE设计的如TE一样轻量的方法,该方法的主要计算量都集中在模态交互上。
方法
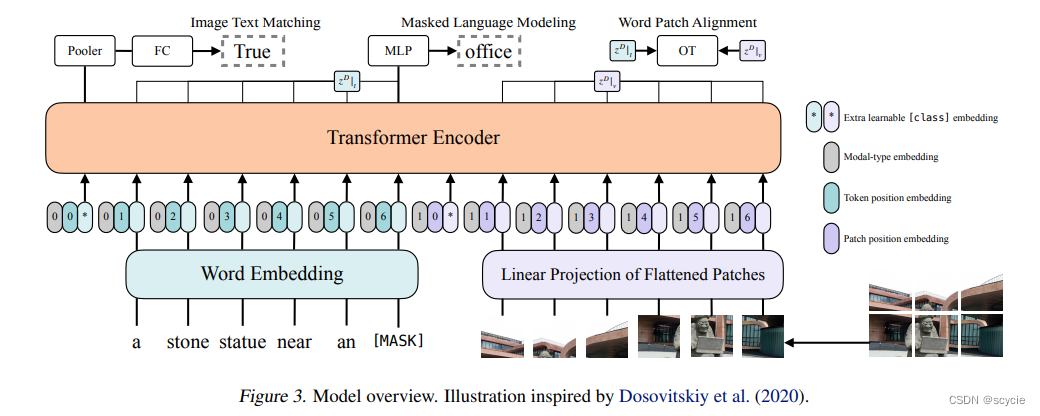
将文本和图像嵌入与其对应的模态类型(灰色部分)加入位置嵌入得到嵌入向量,然后连接成一个组合序列。将组合序列输入到transformer,上下文向量迭代更新通过深度变压器层,直到最后得到输出的上下文序列。 这里模型驱动损失函数分为三个部分,分别是Image Text Matching 、Masked Language Modeling、Word Patch Alignment.
Image Text Matching部分是将第一部分的cls输出进行Pool FC后的图像文本对与负样本的图像文本对进行一个判断,如果是一对,则为true,不是一对,则为false。即ITM loss.
随机以0.5的概率将文本-图片对中的图片替换其他图片,然后对文本标志位对应输出使用一个线性的ITM head将输出feature映射成一个二值logits,用来判断图像和文本是否匹配。
同时ViLT借鉴UNITER,设计了一个word patch alignment (WPA)来计算textual subset和visual subset的对齐分数。(这个需要研究一下UNITER的论文)
其思想是计算得到的word embedding和图像区域块 vision embedding之间的相关性(这里没有公示,估计真的论文还没放上去)。
在这个图像文本判断loss里,还有一个Word Patch Alignment loss,这部分是用来判断图像和文本之间的距离的,因为他们具有匹配关系,所以他们的距离越近越好。
Masked Language Modeling部分是很常规的语言训练模型用到的方法,遮掩掉一个单词,再进行一个重建恢复。即 MLM loss
实验
实验部分用到了两个训练技巧,一个是图像增强,去掉了色彩转换和裁剪,另一个就是整个单词遮掩。
Whole Word Masking
这是一种将词的tokens进行mask的技巧,其目的是使模型充分利用其他模态的信息。
这个预训练任务的训练方式是:
比如“giraffe”一词,
分词器会将成3个部分[“gi”, “##raf”, “##fe”]。
如果并非所有标记都被屏蔽,例如 [“gi”, “[MASK]”, “##fe”],则模型可能仅依赖附近的两个语言标记 [“gi”, “##fe”] 来预测被屏蔽的“##raf”而不是使用图像中的上下文信息。
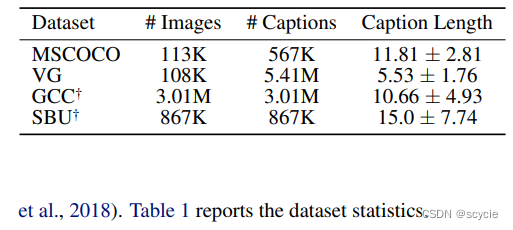
数据集
一共用了四个数据集分别是Microsoft COCO(MSCOCO) (Lin et al., 2014), Visual Genome (VG) (Krishna et al., 2017), SBU Captions (SBU) (Ordonez et al.,2011), and Google Conceptual Captions (GCC)
对比试验
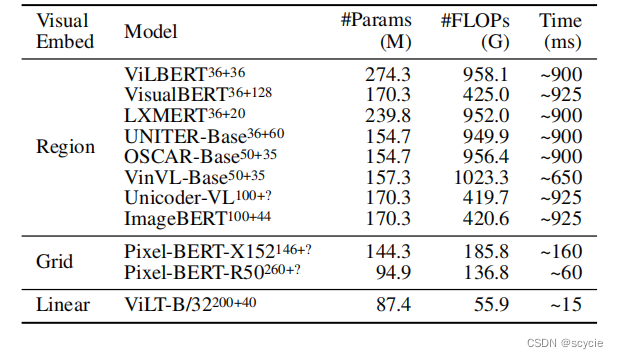
分别在目标检测方法,网格特征提取、及本方法进行了对比,在性能差不多的情况下,提高了计算时间。
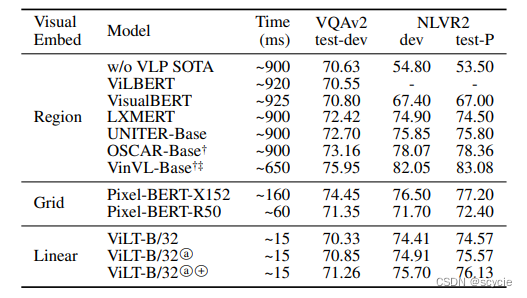
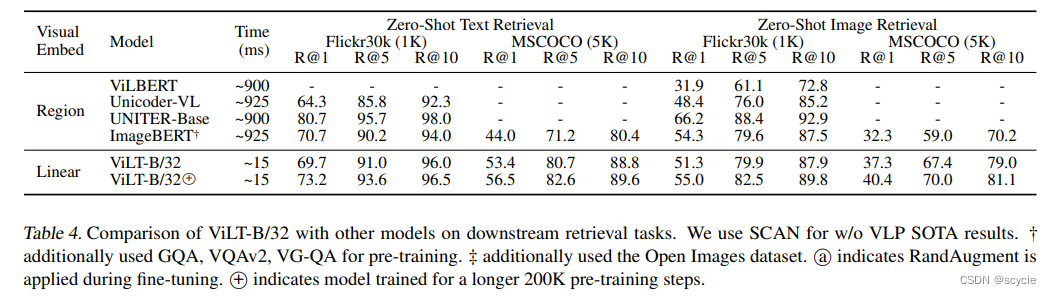
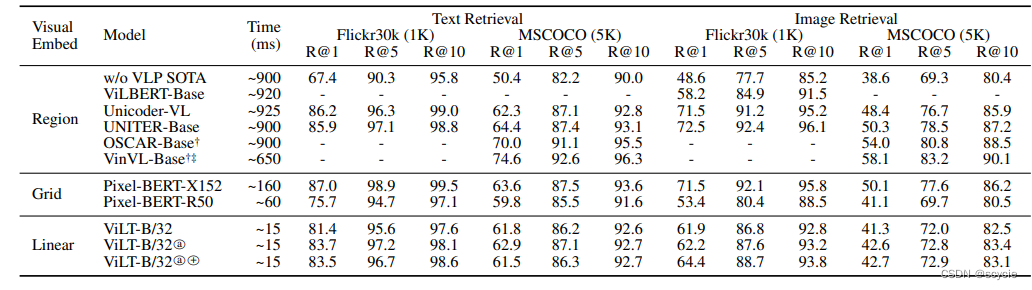
下面这个实验是在下游任务上的对比,可以发现本方法效果差不多甚至在某些方面更好
消融实验
主要验证模型预训练中采取的两个预训练任务以及一个微调时使用的技术的效果。
Whole word masking
Masked patch prediction
图像增强技技术:RandAugment
下图试验了 训练步数对结果的影响,到25K时发现对实验结果还没有较大的影响。但为了实验性能,还是在200K时分别测试预训练任务及微调技术的效果影响

结果可视化

这篇关于ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









