本文主要是介绍有自监督和有判别力训练的域外意图检测(Out-of-Scope Intent Detection with Self-Supervision andDiscriminative Training)阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

发表在ACL2021上面的一篇文章
论文链接:Out-of-Scope Intent Detection with Self-Supervision and Discriminative Training - ACL Anthology
代码链接:https:// github.com/liam0949/DCLOOS
Abstract
在任务型对话中域外意图检测十分重要。在训练阶段,outlier utterances 是任意和未知的,论文中介绍现有的方法主要依赖对数据分布进行假设,例如常用的mixture of Gaussians,但是会导致多步训练或设定规则,例如为离群检测设置一个可靠的阈值。
这篇论文中,作者提出了一种通过在训练中模拟测试场景来训练out-of-scope intent classififier ,这个方法不需要对数据分布进行假设,也不需要额外的处理或阈值设置。
也就是在训练阶段构造了一组pseudo outliers(伪异常值),通过利用inliner features用自监督的方式生成synthetic outliers 和 从其他开放域数据集中采样out-of-scope sentences来获得pseudo outliers。
利用pseudo outliers训练一种可直接应用于测试本文任务的鉴别分类器。
Introduction
自然语言理解的第一步是intent detection(意图识别),主要目标是识别用户话语中多种多样的意图,也可以理解为是一个分类任务。然而,在训练过程中定义的意图类有时候会不能涵盖测试阶段的可能的用户意图。因此,范围外(OOD)的(或未知的)意图检测是必不可少的,它的目的是开发一个模型,可以准确地识别已知的(在训练中看到的)意图类,同时检测在训练中没有遇到的范围外的意图类。
在以往的方法中,一般来说,以往的研究方法是通过学习已知意图的decision boundaries(决策边界),然后使用一些可靠的度量来区分已知意图和未知意图来解决这个问题。
eg:margin-based optimization objective、off-the-shell outlier detection algorithm such as LOF、阈值等。
与之前的工作相比,本篇论文提出通过明确地建模未知意图的分布,构造了一组伪范围外的例子来帮助训练过程。
我们假设在语义特征空间中,现实世界的异常值可以很好地表示为两种类型:几何上接近inliers 的: “hard” outliers 和远离内联的““easy” outliers。这两种离群值在后面有介绍。
通过在训练过程中为未知类构造pseudo outliers,形成了一个(K+1)的分类任务(K个已知类+ 1 未知类别)。
贡献如下:
- 提出了一种新的out-of-scope intent detection方法,通过匹配训练和测试任务,来消除训练数据和泛化的测试数据之间的差距。
- 提出了构造两种类型的pseudo outliers的方法。一种利用自监督方法,另外一种利用公开的辅助数据集的方法。
- 在四个真实世界的对话数据集上进行了广泛的实验,证明论文提出的方法的有效性,并进行了详细的消融研究。
Related Work
open-world(开放世界)领域中时常能够见到如下几个任务:
OD: Outlier Detection, “离群检测”
Outlier Detection(OD,离群检测) 的任务旨在检测出给定数据集中与其他样本显著不同的样本,其中这种不同既可以来源于covariate shift也可以来源于semantic shift。
AD: Anomaly Detection, “异常检测”
Anomaly Detection(AD,异常检测)任务旨在找出测试集中所有偏离“预设的正常样本”的异常样本。这种偏移可能是来源于covariate shift或者semantic shift。该任务通常假设另一种偏移类型不存在。这两种不同的样本偏移类型对应着“异常检测”的两个子任务:“感知上的异常检测”sensory AD,和“语义上的异常检测”semantic AD。
ND: Novelty Detection, “新类检测”
Novelty Detection(ND,新类检测 )的任务旨在找出测试集中不属于训练集中任何类别的“新类”样本,检测到的“新类”样本通常会为下一步增量学习(incremental learning) 提供更多的学习样本,或者作为全新的类型进行探索研究。
OSR: Open Set Recognition, “开集识别”
“开集识别”(Open Set Recognition, OSR)要求多分类器同时达到如下两个要求:(1) 对测试集中属于“已知类别“的进行准确分类;“已知类别”代表训练集中存在的类别。 (2)检测出”未知”类别, “未知类别”不属于训练集中任何类别。
OOD Detection: Out-of-Distribution Detection, “分布外检测
定义:OOD Detection(分布外检测)任务,和新类识别类似,是在找出测试集中不属于训练集中任何类别的“新类”样本。但是在新类识别的基础上,同时完成多分类任务。相比于“开集识别”,“分布外检测”的训练集可以是单类别的也可以是多类别的。
解决方法
解决“广义分布外检测”中各个任务的方法。因为它们各个任务的目标大体相同,各个任务的解法自然也是相似的。解法基本分为四大类:
· Density-based Methods 基于密度估计的方法
· Reconstruction-based Methods 基于重构的方法
· Classification-based Methods 基于分类的方法
· Distance-based Methods 基于距离的方法
- 使用一个confifidence score,来决定了一个话语超出范围的可能性。eg: m binary Sigmoid classififiers for m known classesrespectively and select a threshold to reject OOD
- 第二组通过重建损失来识别范围外的句子.eg: build an autoencoder to encode and decode in-scope utterancesand obtain reconstruction loss by comparing input embeddingswith decoded ones.
- 利用异常值检测算法。 eg: local outlier factor (LOF)/robust covariance estimators
Methodology

问题定义部分,给出问题的定义:给定K个类别,未知意图检测模型去预测一句话中的意图,这句话可能包含的是已经知道的意图或者是未知域的意图。可以总结为是一个(K+1)个类别的意图。
论文作者的方法概述:
本质上是通过利用自监督方法和开放域数据来构建域外的样本从而在训练结果形成一个(K+1)-way的分类任务。同时,作者提出的方法并没有对数据分布进行假设。
接下来从representation learning(表示学习)、construction of pseudo outliers(伪异常值的构建)和discriminative training(鉴别性训练)三个方面对论文提出的方法进行阐述。
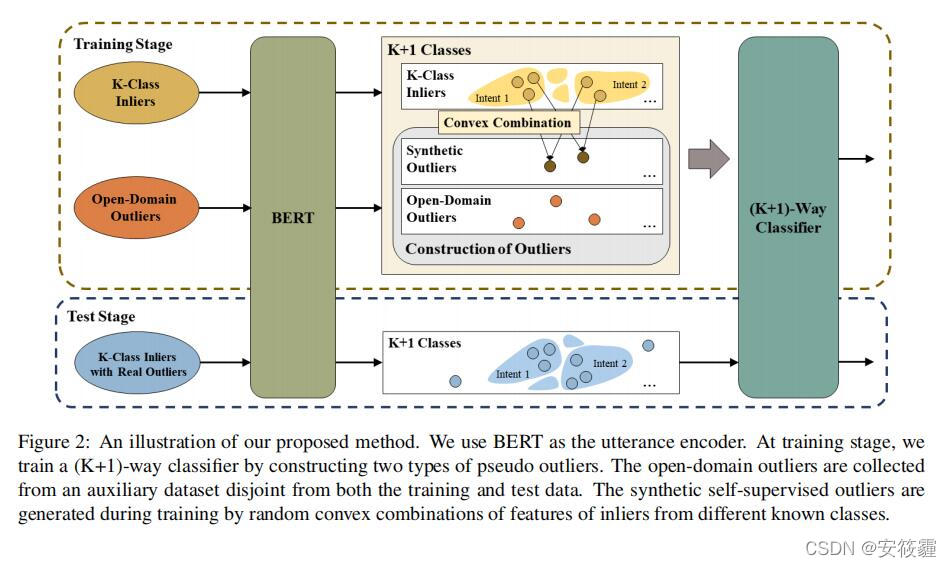
representation learning(表示学习)
在这一个部分主要是使用到了Bert这一预训练模型,将特殊分类标记[CLS]的d维输出向量作为语句u的表示。公式如下:(公式非常好理解)

其中:
BERT 的输入可以包含一个句子对 (句子 A 和句子 B),也可以是单个句子(句子A)。其中还包括了一些有特殊作用的标志位:(这个可以查阅资料做一下了解)
- [CLS] 标志放在第一个句子的首位,经过 BERT 得到的的表征向量 C 可以用于后续的分类任务。
- [SEP] 标志用于分开两个输入句子,例如输入句子 A 和 B,要在句子 A和句子B 后面增加 [SEP] 标志。
- [UNK]标志指的是未知字符
- [MASK] 标志用于遮盖句子中的一些单词,将单词用 [MASK] 遮盖之后,再利用 BERT 输出的 [MASK] 向量预测单词是什么。
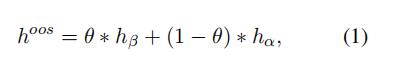
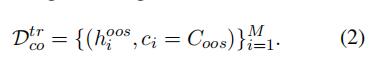
公式1代表生成的异常值, 是一个从均匀分布中采样的值,公式2代表生成的所有异常值的集合。
该方法的假设一些容易区分的outliers是远离inliers的,因此在其他kaifang数据集上的样本由于分布不同,可以作为outliers。于是通过模拟真实世界的outliers来构造open-domain outliers。采样的数据集包括SQuaD 2.0,Yelp和IMDB等对话系统数据集。

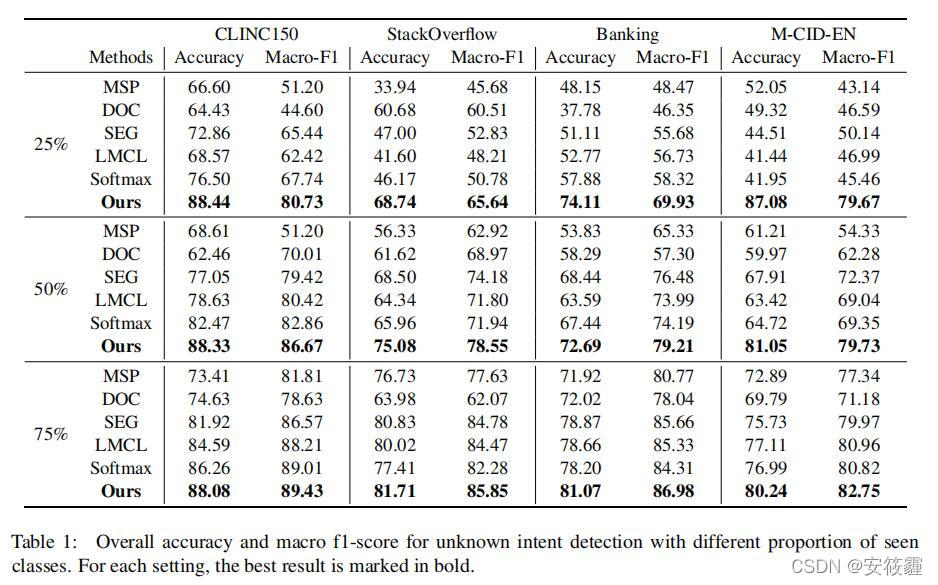
Experiments
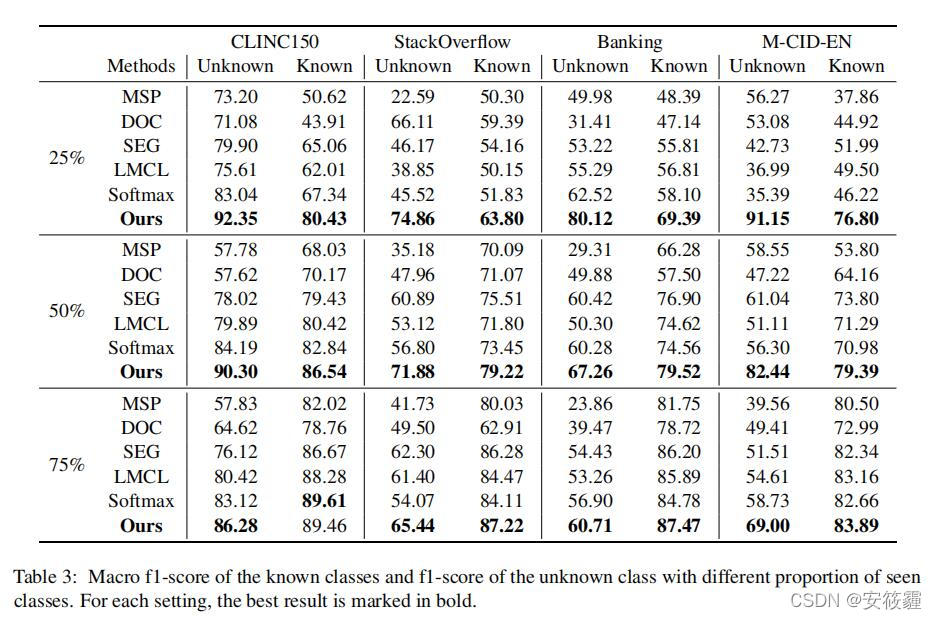
Conclusion
我认为本篇论文的方法本质上是一个数据增强(data augment)的方法。主要使用了一个对域内意图(inliers)进行凸组合(convex combination)来构建outliers和采样其他公开数据作为域外意图(outliers)来进行数据增强。
思考:这种增强方法是否可以使用对比学习来代替,尤其是对域内意图进行处理的时候,使用对比学习。
这篇关于有自监督和有判别力训练的域外意图检测(Out-of-Scope Intent Detection with Self-Supervision andDiscriminative Training)阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







