判别专题

(感知机-Perceptron)—有监督学习方法、非概率模型、判别模型、线性模型、参数化模型、批量学习、核方法
定义 假设输入空间(特征空间)是 χ \chi χ ⊆ R n \subseteq R^n ⊆Rn,输出空间是y = { + 1 , − 1 } =\{+1,-1 \} ={+1,−1} 。输入 x ∈ χ x \in \chi x∈χ表示实例的特征向量,对应于输入空间(特征空间)的点;输出 y ∈ y \in y∈y表示实例的类别。由输入空间到输出空间的如下函数: f ( x ) = s

基于中心引导判别学习的弱监督视频异常检测
WEAKLY SUPERVISED VIDEO ANOMALY DETECTION VIA CENTER-GUIDED DISCRIMINATIVE LEARNING 基于中心引导判别学习的弱监督视频异常检测 abstract 由于异常视频内容和时长的多样性,监控视频中的异常检测是一项具有挑战性的任务。在本文中,我们将视频异常检测看作是一个弱监督下视频片段异常分数的回归问题。因此,我们提出了
机器学习面试:生成模型和判别模型基本形式有哪些?
在机器学习中,生成模型(Generative Models)和判别模型(Discriminative Models)是两类重要的模型类型,它们在建模思路、基本形式和应用场景上有显著的区别。以下是这两种模型的基本形式和它们的主要特点。 生成模型(Generative Models) 生成模型旨在学习数据的联合分布 P(X,Y),即学习特征 X与标签 Y之间的关系。其核心目标是生成符合训练数据分布

判别以邻接表方式存储的有向图中是否存在由顶点vi到顶点vj的路径(i≠j)
试基于图的深度优先搜索策略写一算法,判别以邻接表方式存储的有向图中是否存在由顶点vi到顶点vj的路径(i≠j)。 注意:算法中涉及的图的基本操作必须在此存储结构上实现。 图的邻接表以及相关类型和辅助变量定义如下: Status visited[MAX_VERTEX_NUM];typedef char VertexType;typedef struct ArcNode {int adj

超分中的GAN总结:常用的判别器类型和GAN loss类型
1. 概述 在真实数据超分任务上,从SRGAN开始,Loss函数基本是Pixel loss + GAN loss + Perceptual loss的组合。 与生成任务不同,对于超分这种复原任务,如果只使用Gan loss或者GAN loss的权重比较大的话,效果就比较差。 SRGAN成功的两个关键点:1. 引入了感知损失函数(Perceptual Loss),它是让生成图像产生细节的关键,
分意图 Prompt 调试、后置判别改写、RLHF 缓解大模型生成可控性
分意图 Prompt 调试、后置判别改写、RLHF 这三种方法是为了提高大模型生成内容的可控性,具体原因如下: 分意图 Prompt 调试: 通过针对不同的任务或意图设计特定的 Prompt,可以更精确地引导模型生成符合期望的内容。分意图 Prompt 调试的核心是将复杂的问题分解为更易于模型理解和处理的小问题,从而减少生成内容的偏差和不确定性。这种方法通过精细化控制 Prompt,能够在一定

数据结构:小白专场:树的同构2程序框架、建树及同构判别
T1T2是之前提到的结构数组,是全局变量,作为参数传进去 调用Ismorphic这个函数判断R1R2是不是同构的 首先考虑如何构建BuidTree函数 输入数据的结构如左图 知道n之后,n不为0,循环,循环一次读入一行数据 为了处理方便,三个信息读入的时候都处理成字符的方式读进来,left和right再把字符处理整数再放到left和right里面去 用了scanf三个%c读入三
深度判别特征学习在口音识别中的应用
论文:https://arxiv.org/pdf/2011.12461 代码:https://github.com/coolEphemeroptera/AESRC2020 摘要 使用深度学习框架进行口音识别是一项与深度说话人识别相似的工作,它们都期望为输入语音提供可识别的表示。相比于说话人识别网络学习的个体级特征,深度口音识别提出了一个更具挑战性的任务,即为说话人创建群体级口音特征。本文中,我

GAN的学习 - 训练过程(冻结判别器)
20200823 - 0. 引言 在前一篇文章《GAN的学习[1]》中简单介绍了构造GAN的过程,包括如何构造生成器和判别器,如何训练GAN等,但是其中存在一个问题,就是在训练过程中怎么保证判别器不更新权值。下面针对这部分进行具体的描述。 (20200910 - 增加) 经过了这段时间的学习,对这部分内容有了重新的认识。本篇文章记录的时候,我并不知道tensorflow是怎么实现这种冻结操作的

搜索与图论:染色法判别二分图
搜索与图论:染色法判别二分图 题目描述参考代码 题目描述 输入样例 4 41 31 42 32 4 输出样例 Yes 参考代码 #include <cstring>#include <iostream>#include <algorithm>using namespace std;const int N = 100010, M = 200010;in

模式识别五--PCA主分量分析与Fisher线性判别
文章转自:http://www.kancloud.cn/digest/prandmethod/102847 本实验的目的是学习和掌握PCA主分量分析方法和Fisher线性判别方法。首先了解PCA主分量分析方法的基本概念,理解利用PCA 分析可以对数据集合在特征空间进行平移和旋转。实验的第二部分是学习和掌握Fisher线性判别方法。了解Fisher线性判别方法找的最优方向与非
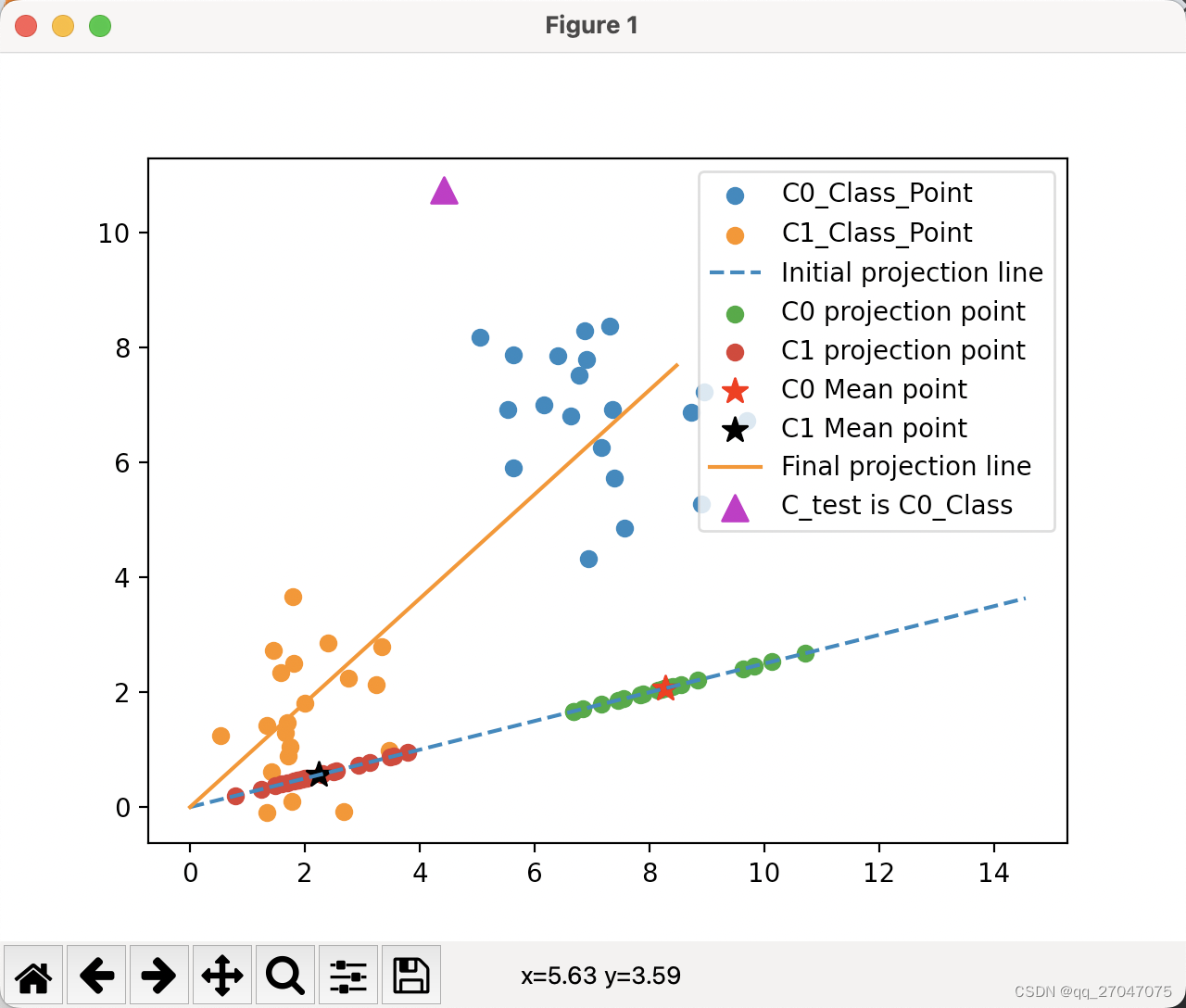
第三章 线性判别 -基于(二维向量投影)
完整代码如下: import numpy as npimport matplotlib.pyplot as pltnp.random.seed(150)x1 = np.random.normal(7, 1, [20, 1])x2 = np.random.normal(7, 1, [20, 1])C0 = np.concatenate((x1, x2), axis=1).T
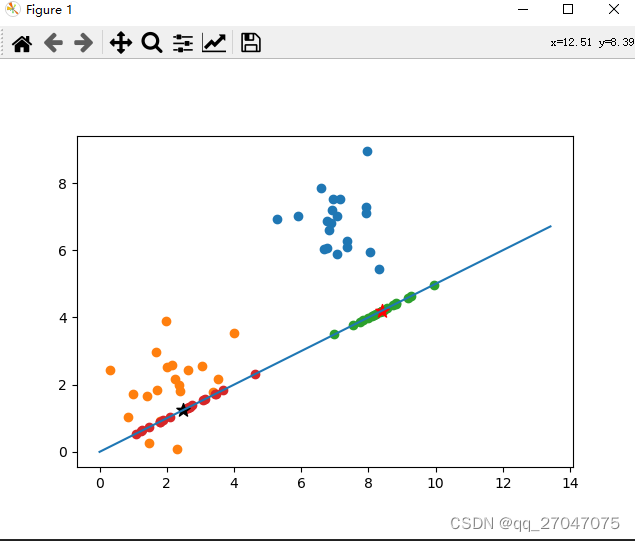
第三章 线性判别 -二维向量投影
计算二维平面上的点到某向量w上的投影点。 import numpy as npimport matplotlib.pyplot as pltx1=np.random.normal(7,1,[20,1])x2=np.random.normal(7,1,[20,1])C0=np.concatenate((x1,x2),axis=1).T #C0类x1=np.random.norm
关于瑕点型反常积分的收敛性判别
关于暇点型反常积分的收敛性判别 @(微积分) 积分上下限确定的积分,在上下限范围内存在着暇点,此时应该怎么做比较容易分析出积分是否收敛是个很有意思的问题。 不加证明的总结一个有效的解决思路:假设在(a,b)上,f(a)趋向于无穷大。则积分 ∫baf(x)dx \int_a^bf(x)dx是否收敛。 方法是: 判定limx→a+f(x)(x−a)δ是否存在,其中δ∈(0,1)

Fisher线性判别与感知器算法Matlab实现
参考用书: 本文是在学习此书Chapter4时,跑的实验。 4.1.4 Fisher‘s Linear Discriminate [plain] view plain copy function [w y1 y2 Jw] = FisherLinearDiscriminat(data, label) % FLD Fisher Linear Dis
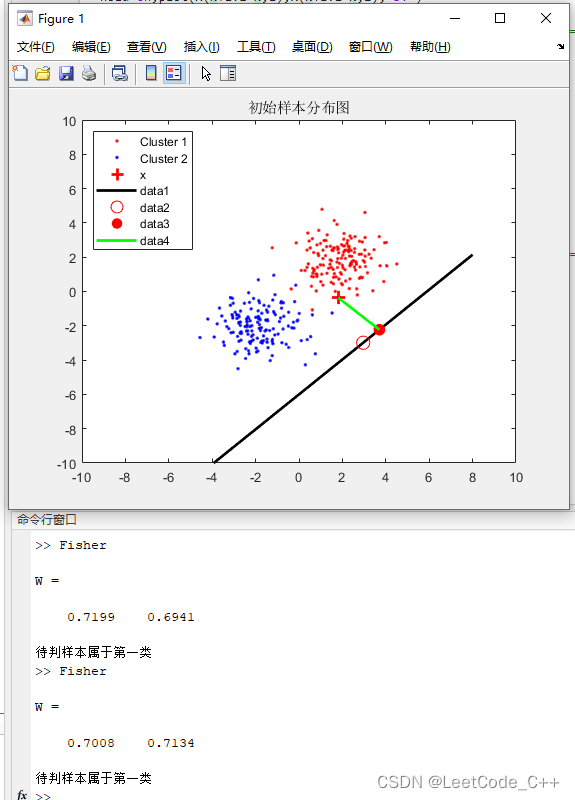
MATLAB分类与判别模型算法:基于Fisher算法的分类程序【含Matlab源码 MX_002期】
算法思路介绍: 费舍尔线性判别分析(Fisher's Linear Discriminant Analysis,简称 LDA),用于将两个类别的数据点进行二分类。以下是代码的整体思路: 生成数据: 使用 randn 函数生成随机数,构建两个类别的合成数据点。第一个类别的数据点分布在以 (2,2) 为中心的正态分布中。第二个类别的数据点分布在以 (-2,-2) 为中心的正态分布中。 计算类别均

自顶向下语法分析方法:LL(1)文法的判别
例子:文法G[S]为 S->AB|bC A->ε|b B->ε|aD C->AD|b D->aS|c 第一步,求出能推出ε的非终结符 首先建立一个以文法的非终结符为上界的一维数组,其数组元素为非终结符,对应每一非终结符有一个标志位,用以记录能否推出ε。如下表 非终结符SABCD初值未定未定未定未定未定第1次扫描是是否第2次扫描是否 能否推出ε步骤如下: 第二步,计算FIR

如何判别学术会议等级?
在学术研究领域,高校教师和研究生常常会收到大量的学术会议和投稿征文通知。然而,并非所有会议都值得参与。有些会议可能只是浪费时间和金钱,甚至可能导致论文版权问题。因此,如何判断学术会议的等级和选择有价值的会议就显得尤为重要。 那么,具体应如何判别学术会议等级呢? 第一,可以查看会议的届次来判断其可靠性。 通常,举办届数较多的会议更值得信赖。这些会议往往会有完整的会议历史
时序动作定位 | 基于判别增强的弱监督时序动作定位融合检测网络
<Fusion detection network with discriminative enhancement for weakly-supervised temporal action localization> 一、摘要 弱监督时序动作定位旨在仅使用视频级动作标签识别和定位未修剪视频中的动作实例。由于缺乏帧级注释信息,正确区分视频中的前景和背景片段对于动作的时间定位至
利用顺序栈实现:判别表达式中括弧是否正确配对(BracketMatch函数)
#include<stdio.h>#include<stdlib.h>#define INITSTACKSIZE 20#define INCREASESIZE 10typedef char SElemType;typedef struct {SElemType *base;SElemType *top;int stacksize;} SqStack;void initStack(SqSt

Bayes判别示例数据:鸢尾花数据集
使用Bayes判别的R语言实例通常涉及使用朴素贝叶斯分类器。朴素贝叶斯分类器是一种简单的概率分类器,基于贝叶斯定理和特征之间的独立性假设。在R中,我们可以使用`e1071`包中的`naiveBayes`函数来实现这一算法。下面,我将通过一个简单的示例展示如何在R中应用朴素贝叶斯方法来进行数据分类。 示例数据:鸢尾花数据集 这个例子使用的是鸢尾花数据集(Iris dataset),这是一个常用的

Fisher判别示例:鸢尾花(iris)数据(R)
先读取iris数据,再用程序包MASS(记得要在使用MASS前下载好该程序包)中的线性函数lda()作判别分析: data(iris) #读入数据iris #展示数据attach(iris) #用变量名绑定对应数据library(MASS) #加载MASS程序包ld=lda(Species~Sepal.Length+Sepal.Width+Petal.Len gth+Pe

如何判别三角形和求10 个整数中最大值?
分享每日小题,不断进步,今天的你也要加油哦!接下来请看题------> 一、已知三条边a,b,c能否构成三角形,如果能构成三角形,判断三角形的类型(等边三角形、等腰三角形或普通三角形 #include <stdio.h>int main(){int a = 0;int b = 0;int c
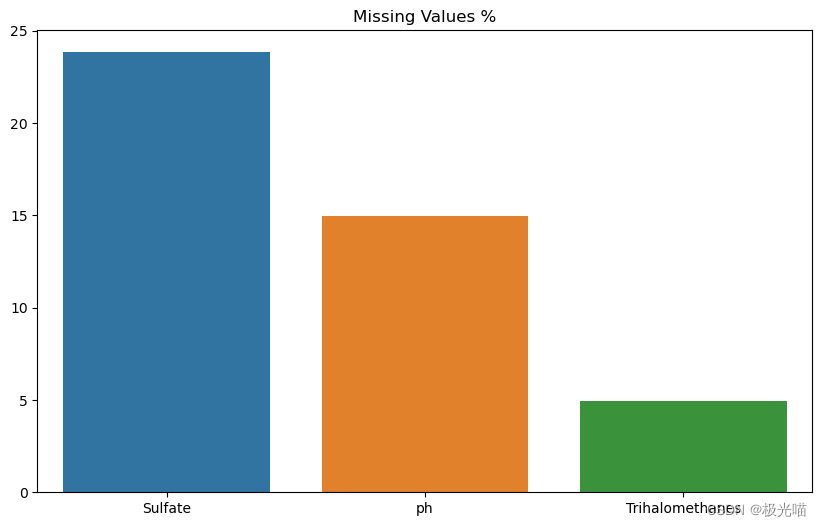
判别饮用水可饮用的多机器学习模型
注意:本文引用自专业人工智能社区Venus AI 更多AI知识请参考原站 ([www.aideeplearning.cn]) 项目背景 饮用水是人类生存的基本需求之一,也是维护健康和有效保护健康政策的重要组成部分。因此,确保饮用水质量对于国家、地区和地方层面的健康和发展至关重要。在某些地区,已经证明投资于供水和卫生设施可以产生净经济效益,因为减少了不良健康效应和医疗成本,这些成本超过了实施干
监督学习:生成模型和判别模型
生成模型与判别模型 http://blog.csdn.net/zouxy09 一直在看论文的过程中遇到这个问题,折腾了不少时间,然后是下面的一点理解,不知道正确否。若有错误,还望各位前辈不吝指正,以免小弟一错再错。在此谢过。 一、决策函数Y=f(X)或者条件概率分布P(Y|X) 监督学习的任务就是从数据中学习一个模型(也叫分类器),应用这一模型,对给定的输
![[SPSS]判别分析的SPSS实现——以根据生化指标对胃病患者进行判别为例](https://img-blog.csdn.net/20180812220611991?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RPTU9DQVQ=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[SPSS]判别分析的SPSS实现——以根据生化指标对胃病患者进行判别为例
一、导入数据并查看数据情况: 1、数据总体状况: 其中Group表示病人胃病类型。 2、更改变量名:把x1,x2,x3,x4改成具有意义的变量名并且修改变量度量类型,如下图所示: 3、变量的描述性统计 操作:分析-描述性 描述性统计结果如下: 可以看到数据的分布没有特别的离异点,也没有缺失值和不合理的分布,从而可以用该数据做接下来的距离判别分析。 4、由于后续做判别