本文主要是介绍深度判别特征学习在口音识别中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:https://arxiv.org/pdf/2011.12461
代码:https://github.com/coolEphemeroptera/AESRC2020
摘要
使用深度学习框架进行口音识别是一项与深度说话人识别相似的工作,它们都期望为输入语音提供可识别的表示。相比于说话人识别网络学习的个体级特征,深度口音识别提出了一个更具挑战性的任务,即为说话人创建群体级口音特征。本文中,我们借鉴并改进了深度说话人识别框架来识别口音,具体而言,我们采用卷积循环神经网络作为前端编码器,并使用循环神经网络整合局部特征以生成语句级别的口音表示。创新地,为了解决过拟合问题,我们在训练期间简单地添加了基于连接时序分类(CTC)的语音识别辅助任务,并且针对模糊的口音区分,我们引入了一些在面部识别工作中强大的判别损失函数来增强口音特征的判别能力。我们的研究表明,提出的带有判别训练方法的网络(不进行数据增强)在2020年口音英语语音识别挑战赛的口音分类赛道上显著领先于基线系统,其中Circle-Loss损失函数在口音表示的判别优化中表现最佳。

1. 引言
在特定语言下,口音是一种可以受社会地位、教育和居住地区影响的习得或行为性说话特性,我们主要关注由地域因素引起的口音。口音识别(AR)技术可以用于有针对性地解决与口音相关的问题或预测说话人的可靠身份,以提供定制服务,近年来受到了广泛关注。本文中,我们在2020年口音英语语音识别挑战赛(AESRC2020)的口音分类赛道上设计了一种带有判别特征学习方法的深度框架,该数据集中包含来自8个国家的英语语音口音。
在深度特征学习中,AR任务与说话人识别(SI)和语言识别(LI)相似,它们都希望为输入语音提供一个可区分的表示。在建模方法上,它们可以共享相同的深度范式:(i)使用深度神经网络(DNN)提取帧级特征,(ii)帧级特征的时间整合,(iii)判别特征学习。在我们的工作中,我们使用卷积循环神经网络(CRNN)来提取帧级描述符,具体来说,我们的CRNN提取器由ResNet和双向GRU网络组成,接着使用双向GRU将计算出的局部描述符整合为全局的语句级特征。
然而,为许多说话人学习群体级口音特征比学习个体级说话人特征更难,这种难度具体体现在以下两点:
- 过拟合:在有限的训练数据下,由于口音的数量远少于说话人的数量,并且输入语音包含丰富且多样的信号,在这种小规模分类目标下快速收敛并不等同于获得准确的口音表示。因此,即使在封闭集上效果完美,学习到的决策路径也可能不准确。
- 难以检测口音:在许多正式的社交场合中,说话人倾向于采用标准化的发音(如中文的普通话),这种发音会缩小不同口音之间的差异,使得口音识别更加困难。换句话说,这种不可区分的口音会导致深度网络中的嵌入表示模糊。
为了解决上述两个问题,我们提出了以下两个解决方案:(i)针对问题1,我们采用多任务学习(MTL)训练方法,即在训练期间,我们在前端编码器上简单地添加了基于CTC的语音识别辅助任务。(ii)针对问题2,我们在面部识别工作中采用了一些流行的判别损失函数来增强口音特征的判别能力。
2. 深度分类架构
我们借鉴并改进了深度说话人识别框架,以创建用于口音分类的语句级表示。本文提出的深度口音识别网络由以下部分组成:(1)基于CRNN的前端编码器,用于提取帧级描述符,由基于ResNet的CNN子部分和基于双向GRU的RNN子部分构成;(2)特征整合层,用于将任意帧级局部特征整合为语句级全局特征向量;(3)训练期间的判别损失函数,用于增强全局口音特征的判别能力;(4)基于softmax的分类器,附加在全局特征上,给出口音的后验分布。
为了应对过拟合问题,我们在训练期间在前端编码器后添加了一个基于CTC的ASR分支。总体而言,我们的模型在训练期间有三个输出,其中预测结果由基于softmax的分类器给出。
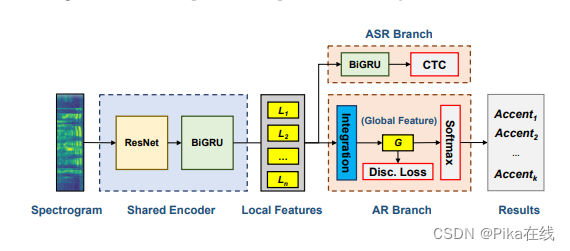
2.1 前端编码器
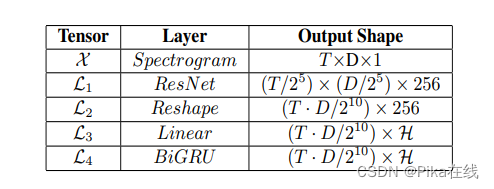
输入的二维频谱图经过ResNet(特征图数量减半)的处理,得到的特征图L1。然后,将时间维度和特征维度结合起来,形成特征序列L2。接着,通过线性层将描述符的维度降低到H,并得到张量L3。最后,采用双向GRU进一步提取序列特征L4。
2.2 多对一特征整合
为了将由变长输入导致的可变数量的局部描述符合并为固定长度的语句级嵌入向量,我们采用基于RNN的整合方法,具体来说,我们使用双向GRU逐步摄取每个描述符,并将最后的隐藏状态作为整合结果。
2.3 基于CTC的ASR目标
我们选择基于CTC的ASR辅助任务来遏制训练期间的过拟合问题。CTC公式使用L长度的字母序列O和带有“空白”符号的帧级字母序列Z。CTC目标的计算方法见公式。
3. 判别特征学习
损失函数在深度特征学习中起着重要作用。我们采用在面部识别工作中强大的判别损失函数来改进模糊的口音表示。
3.1 Softmax损失
Softmax损失结合了softmax函数和交叉熵损失,旨在使所有类别在概率空间中具有最大的对数似然。给定语句级口音特征Gi及其对应的标签yi,Softmax损失的计算方法见公式。
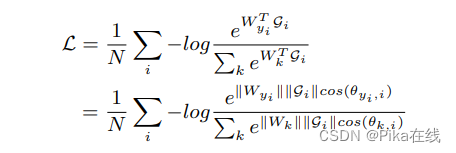
3.2 CosFace/AM-Softmax
为了改进预测的泛化性,我们需要一个可靠的度量空间,最大化类间差异并最小化类内差异。CosFace和AM-Softmax通过L2正则化特征和权重向量去除径向变化,并引入加性余弦边距项来进一步最大化角度空间中的决策边距。
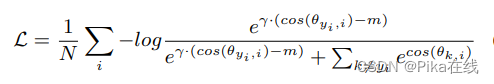
3.3 ArcFace
与CosFace和AM-Softmax类似,ArcFace在类权重和嵌入特征的归一化下,将边距移至余弦运算符的内部,以更直接地优化特征空间。
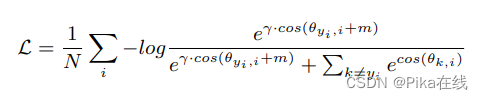
3.4 Circle-Loss
Circle-Loss在深度特征学习中提出了一种统一的视角,包括两种基本范式:类级标签学习和对级标签学习,它们都旨在最大化类内相似性并最小化类间相似性。Circle-Loss通过灵活的优化方法和明确的收敛状态改进了特征学习效果。
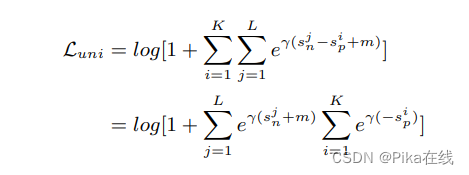
4. 实验
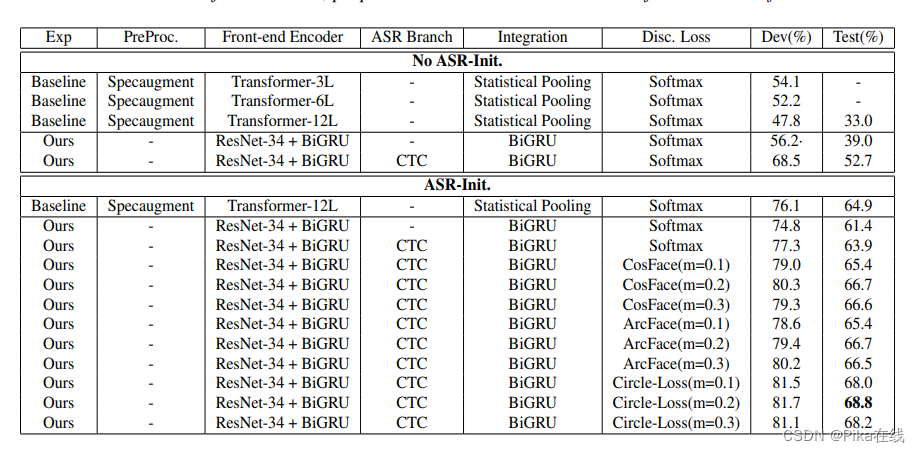
我们在AESRC2020语音数据集上训练和测试了我们的网络。该数据集包括来自八个国家的英语口音。实验结果表明,使用判别损失函数的模型在口音分类准确性上明显优于基线系统。八国口音英语数据集分布,U:句子,S:说话人

实验结果
5. 结论
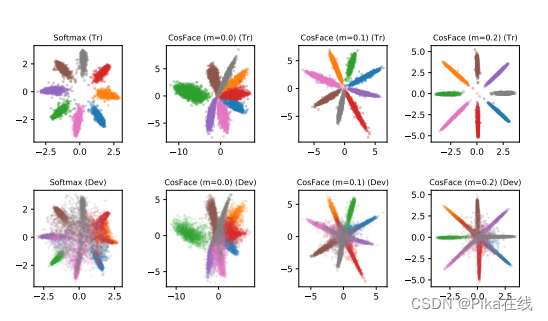
本文借鉴了说话人识别中的深度范式,提出了一种深度口音识别网络。我们通过引入基于CTC的ASR辅助任务解决了过拟合问题,并采用面部识别中的判别特征学习方法解决了模糊的口音表示问题。在AESRC2020口音识别赛道上,我们提出的模型在判别优化上表现优异,Circle-Loss在特征学习中表现最佳。八国二维口音特征图分布如下:
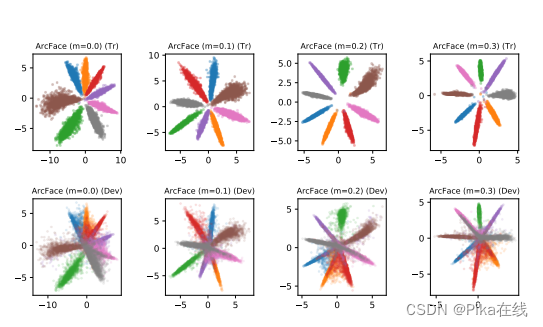
八国三维口音特征图分布如下:
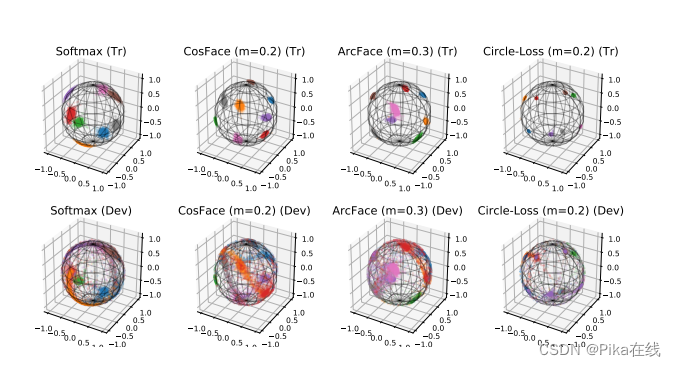
这篇关于深度判别特征学习在口音识别中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






