本文主要是介绍[SPSS]判别分析的SPSS实现——以根据生化指标对胃病患者进行判别为例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、导入数据并查看数据情况:
1、数据总体状况:

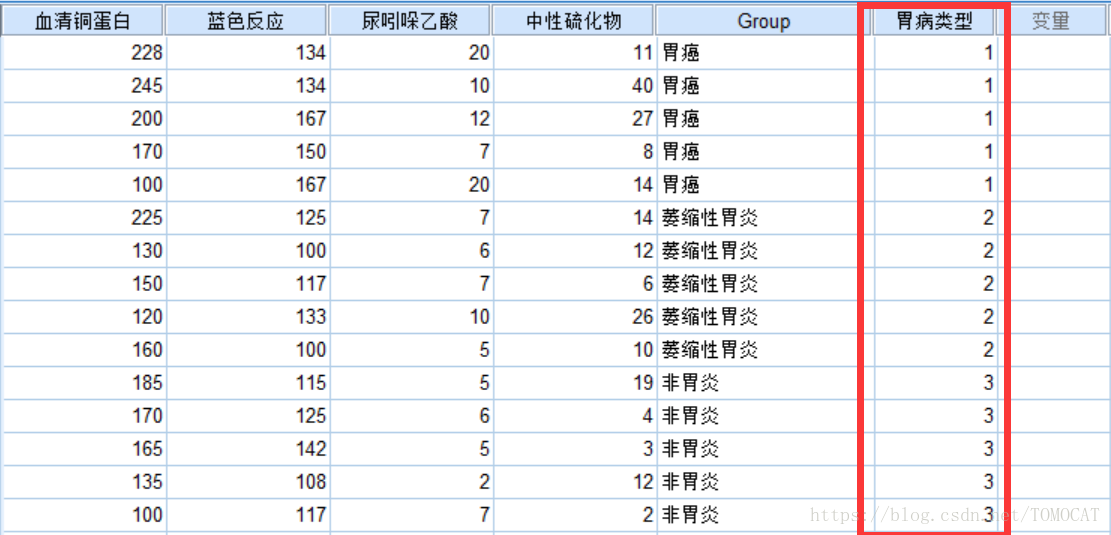
其中Group表示病人胃病类型。
2、更改变量名:把x1,x2,x3,x4改成具有意义的变量名并且修改变量度量类型,如下图所示:

3、变量的描述性统计
操作:分析-描述性

描述性统计结果如下:

可以看到数据的分布没有特别的离异点,也没有缺失值和不合理的分布,从而可以用该数据做接下来的距离判别分析。
4、由于后续做判别分析的时候,Group无法作为分类变量,从而这里引入胃病类型作为分类变量,如下图所示:
二、判别分析
0、判别分析原理:判别分析是多元统计中用于判别样品所属类型的一种统计分析方法,是一种在已知研究对象用某种方法已经分成若干类的情况下,确定新的样品的观测数据属于哪一类的研究方法。
1、距离判别法:
(1)原理:根据待判定样本与已知类别样本之间的距离远近做出判断,把待判定样本归类为距离原样本最近的类别。
(2)判别公式(以两总体马氏距离为例):

(3)判别过程和结果:
由于SPSS中的判别分析没有距离判别这一方法,因此距离判别法无法在SPSS中直接实现。我们通过R语言来做。其中Rcode放在另外一个文件,这里只显示回判结果。

可见只有8号样本回判错误。
2、贝叶斯判别法:
(1)原理:

则把X0判给Gl。
(2)判别过程:
按下图选择判别分析:
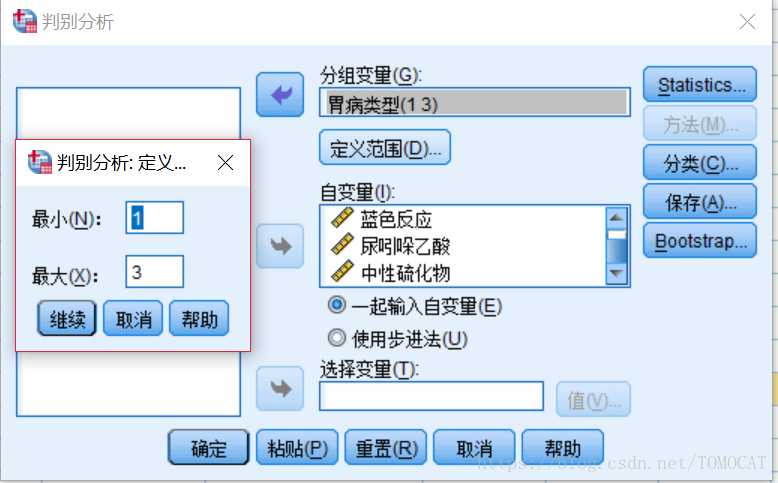
把胃病类型放入分组变量,四个自变量放入分类自变量中,定义分组变量的范围为1到3,如下所示:
在Statistics选项卡中选择函数系数下面的Fisher’s和未标准化选择判别方法,含义如下所示:
Fisher’s:给出Bayes判别函数的系数。(注意:这个选项不是要给出Fisher判别函数的系数。这个复选框的名字之所以为Fisher’s,是因为按判别函数值最大的一组进行归类这种思想是由Fisher提出来的。这里极易混淆,请注意辨别。)
Unstandardized:给出未标准化的Fisher判别函数(即典型判别函数)的系数(SPSS默认给出标准化的Fisher判别函数系数)。

单击分类按钮,定义判别分组参数和选择输出结果。选择输出栏中的个案结果,输出一个判别结果表,包括每个样品的判别分数、后验概率、实际组和预测组编号等。其余的均保留系统默认选项。

点击保存选项,指定在数据文件中生成代表判别分组结果和判别得分的新变量,生成的新变量的含义分别为:
预测组成员:存放判别样品所属组别的值;
判别分数:存放Fisher判别得分的值,有几个典型判别函数就有几个判别得分变量;
组成员概率:存放样品属于各组的Bayes后验概率值。

运行后得到结果,下一步分析结果。
(3)判别结果解释:
数据视图下可以直接看到判别结果:

贝叶斯判别函数系数如下所示:

费雪判别函数:
第一组:F1=-79.212+0.164x1+0.753x2+0.778x3+0.073x4
第二组:F2=-46.721+0.013x1+0.595x2+0.317x3+0.012x4
第三组:F3=-49.598+0.130x1+0.637x2+0.100x3-0.059x4
费雪判别准则:
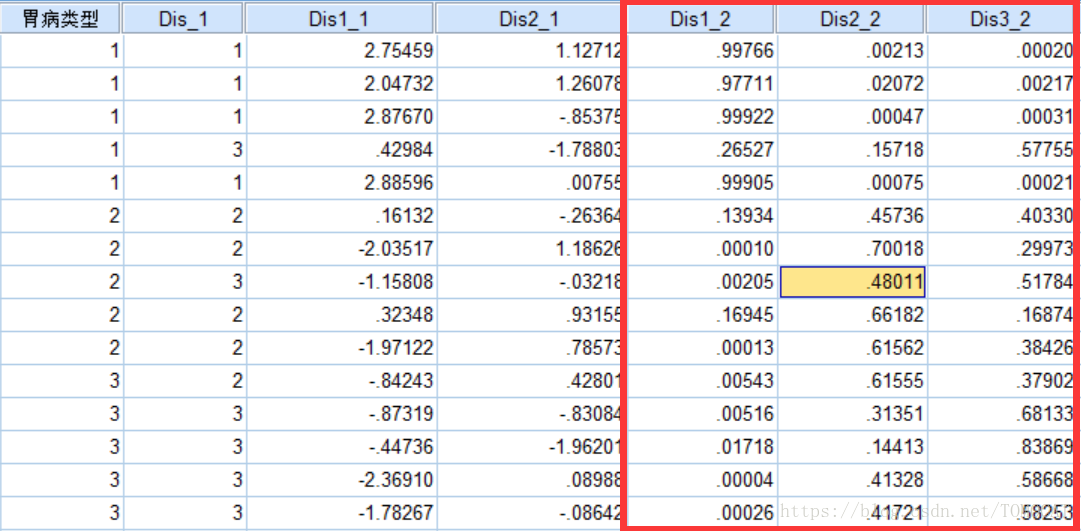
将各样品的自变量值代入上述三个Bayes判别函数,得到三个函数值。比较这三个函数值,哪个函数值比较大就可以判断该样品判入哪一类。结合如下数据视图可以得到结论:
3、费歇尔判别法
典型判别函数系数:

两个Fisher判别函数:
F1=0.453x1+0.596x2+0.662x3+0.299x4
F2=-0.175x1-0.811x2+0.600x3+0.608x4
组重心处的Fisher判别函数值:

判别准则:
两个Fisher函数式计算的是各观测值在各个维度上的坐标,这样就可以通过这两个函数式计算出各样品观测值的具体空间位置。
群组重心函数为各类别重心在空间中的坐标位置。这样,只要在前面计算出各观测值的具体坐标位置后,再计算出它们分别离各重心的距离,就可以得知它们的分类了。
4、结果解释:
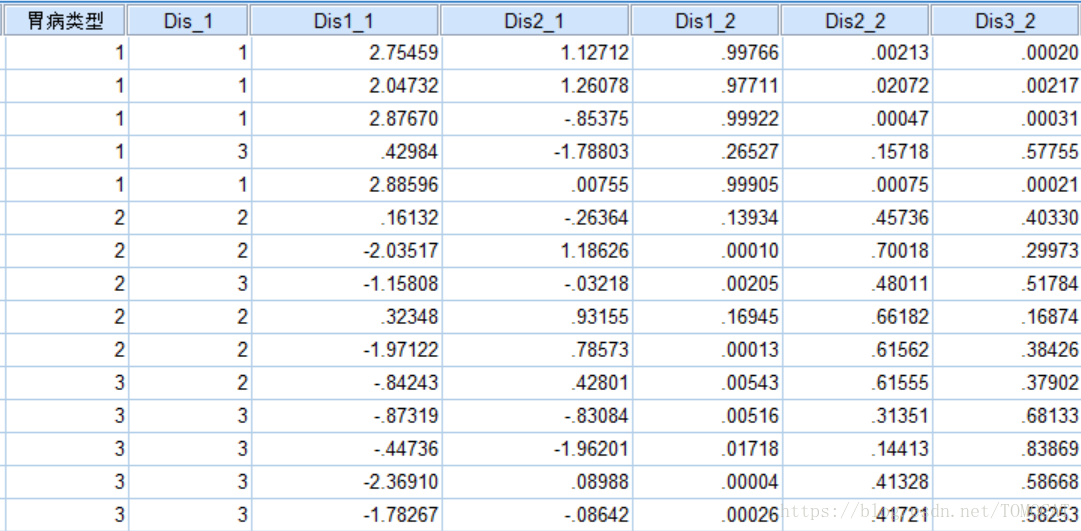
变量dis-1存放判别样品所属组别的值,变量dis1-1和dis2-1分别代表将样品各变量值代入第一个和第二个判别函数所得的判别分数,变量dis1-2、dis2-2和dis3-2分别代表样品分别属于第1组、第2组和第3组的Bayes后验概率值。
这篇关于[SPSS]判别分析的SPSS实现——以根据生化指标对胃病患者进行判别为例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







