本文主要是介绍CLIP--Learning Transferable Visual Models From Natural Language Supervision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:CLIP论文笔记--《Learning Transferable Visual Models From Natural Language Supervision》_visual n-grams模型-CSDN博客
- openAI,2021,将图片和文字联系在一起,----->得到一个能非常好表达图片和文字的模型
- 主题:多模态理解任务
任务:计算图片和文本的相似度
训练:有监督的对比学习
背景
- zero-shot transfer:零样本迁移到下游任务(一些NLP模型可以直接在A数据集上预训练,再到B,C,D数据集做任务时,这个模型可以不使用这个数据集的任何数据(zero-shot)进行参数微调而直接做任务)
- “狭窄的视觉概念”是指模型在ImageNet等数据集上训练,只是为了学会区分像“猫”、“狗”这样的类,但不同的猫种类模型是不会区分的,比如“橘猫”和“奶牛猫”,即其他的视觉信息没有被充分利用。
- Visual N-Grams促成CLIP的诞生的最重要的论文。【用自然语言监督信号来让促成一些现存的CV分类数据集(包含ImageNet数据集)实现zero-shot transfer。】
方法
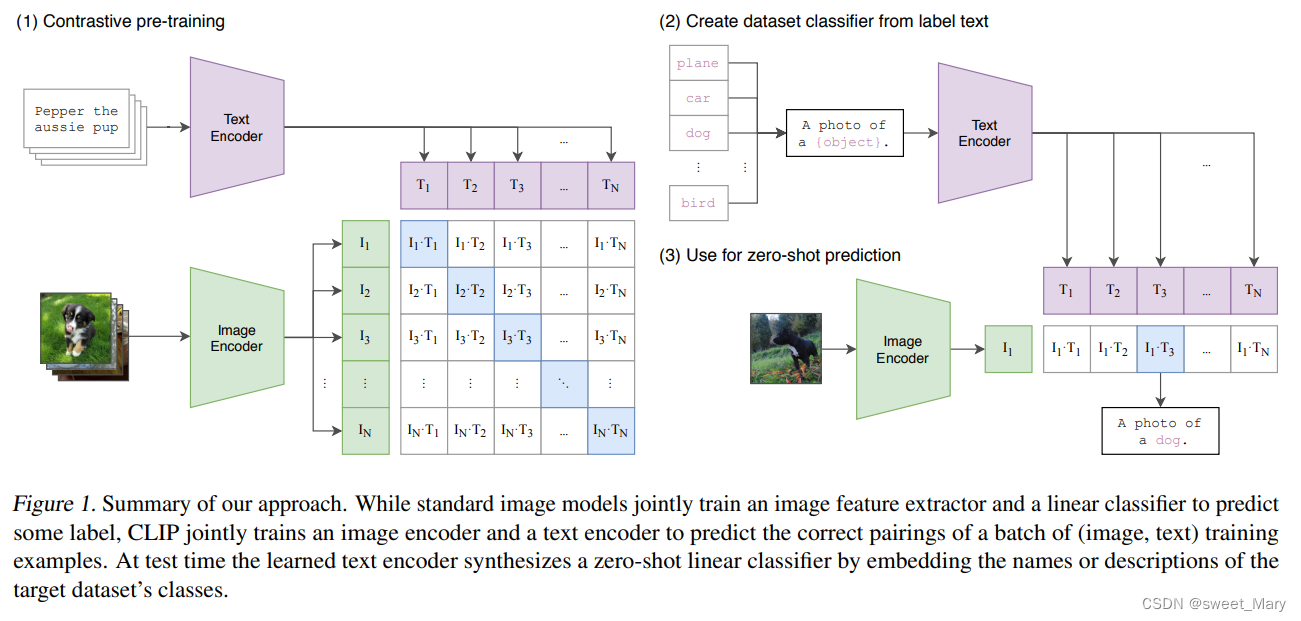
- 标准的图像模型 VS CLIP:
- 标准的图像模型:一个图像特征提取器和一个线性分类器---预测标签
- CLIP:一个图像编码器和一个文本编码器---预测一批(图像、文本)正确配对
- 测试:输入句子(a photo of {label}---Prompt工程)+图片
- 从自然语言中学习:将图片表示与语言联系起来,从而实现灵活的zero-shot transfer
- 超大数据集:用4亿对来自网络的图文数据集,将文本作为图像标签,进行训练。这个数据集称为WebImageText(WIT)
- 预训练
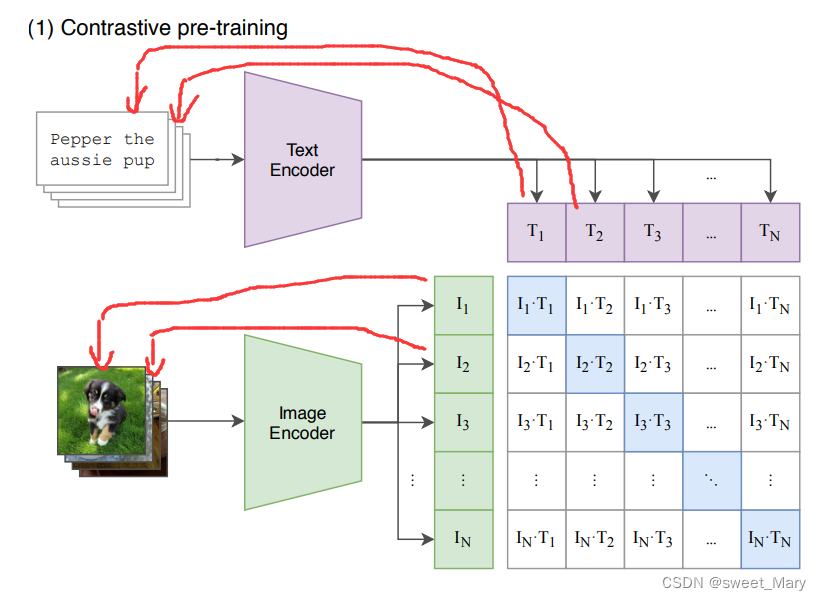
- 图片分类任务------>图文匹配任务
- 贡献点:采用了海量图文对数据和超大batch size进行预训练,并不在于其模型结构
- 模态之间的cosine similarity:N个匹配的图文对相似度最大,
个不匹配的图文对相似度最小
- 对角线上都是配对的正样本对,而矩阵的其他元素,则是由同个batch内的图片和不配对的文本(相反亦然)组成的负样本。
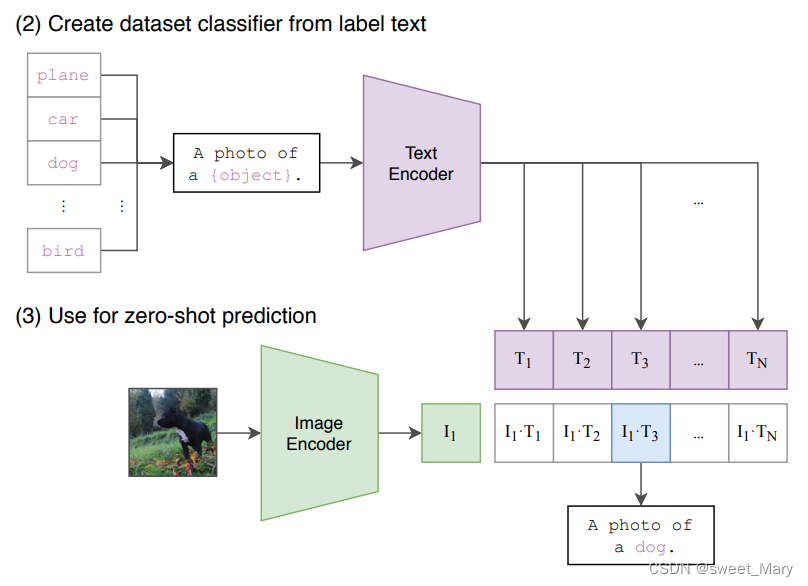
- 测试
这篇关于CLIP--Learning Transferable Visual Models From Natural Language Supervision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[VC] Visual Studio中读写权限冲突](/front/images/it_default.jpg)