natural专题

NLP-文本匹配-2017:BiMPM【Bilateral Multi-Perspective Matching for Natural Language Sentences】
NLP-文本匹配-2016:BiMPM【Bilateral Multi-Perspective Matching for Natural Language Sentences】

NLP-文本匹配-2016:ESIM【Enhanced LSTM for Natural Language Inference】
NLP-文本匹配-2016:ESIM【Enhanced LSTM for Natural Language Inference】

MYSQL -NATURAL JOIN ,exist 函数
NATURAL JOIN 是一种 SQL 连接类型,它会自动基于两个表中具有相同名称的列进行连接。使用 NATURAL JOIN 时,不需要显式指定连接条件。它会帮你自动查询两张连接表中 所有相同的字段 ,然后进行 等值 连接 两表都有 manager_id 和 department_id selectlast_name,department_name,employee_id

CVPR2017《Detecting Oriented Text in Natural Images by Linking Segments》阅读笔记
前言 本文是对CVPR2017《Detecting Oriented Text in Natural Images by Linking Segments》论文的简要介绍和细节分析。该论文是华中科大白翔组的工作,主要针对自然场景下文本检测模型由char-level到word-level和line-level的检测。 关键词:SSD、Segment、Link、Scene Text Detectio
Synthetic Data for Text Localisation in Natural Images(人工合成带有文本的图片)
https://github.com/JarveeLee/SynthText_Chinese_version 1.解决python3的pickle.load错误:a bytes-like object is required, not 'str' 经过几番查找,发现是Python3和Python2的字符串兼容问题,因为数据文件是在Python2下序列化的,所以使用Python3读取时,需要将‘
[CLIP] Learning Transferable Visual Models From Natural Language Supervision
通过在4亿图像/文本对上训练文字和图片的匹配关系来预训练网络,可以学习到SOTA的图像特征。预训练模型可以用于下游任务的零样本学习 1、网络结构 1)simplified version of ConVIRT 2)linear projectio
论文阅读:《A Primer on Neural Network Models for Natural Language Processing》(二)
https://blog.csdn.net/u011239443/article/details/80119245 4 前馈神经网络(略) 5 单词嵌入 神经网络方法的一个主要组成部分是使用嵌入-在低维空间中表示每个特征作为向量。但是向量来自哪里呢?本节将调查常见的方法。 5.1 随机初始化 当有足够的监督训练数据可用时,可以将特征嵌入与其他模型参数相同:将嵌入向量初始化为随机值,并让网
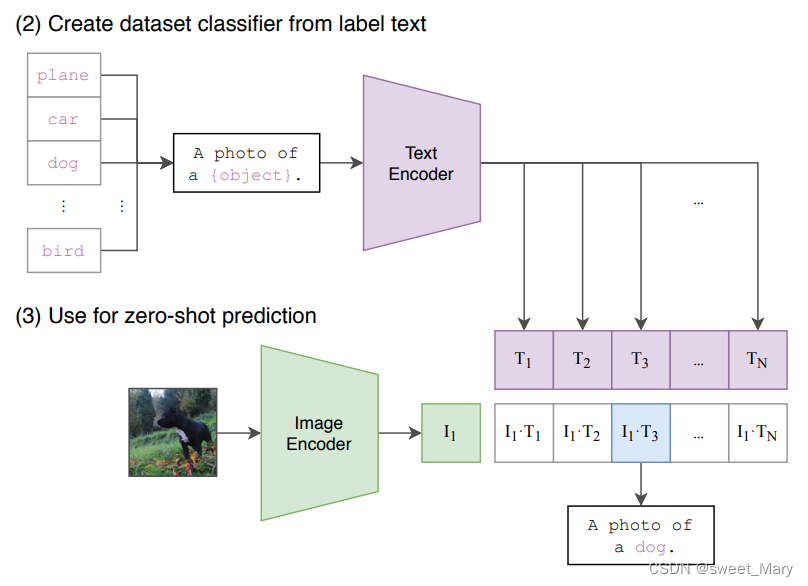
CLIP--Learning Transferable Visual Models From Natural Language Supervision
参考:CLIP论文笔记--《Learning Transferable Visual Models From Natural Language Supervision》_visual n-grams模型-CSDN博客 openAI,2021,将图片和文字联系在一起,----->得到一个能非常好表达图片和文字的模型主题:多模态理解任务 任务:计算图片和文本的相似度 训练:有监督的对比学习 背景
A Bayesian Hierarchical Model for Learning Natural Scene Categories
Mathematics 伯努利分布(Bernoulli Distribution):0-1分布(或两点分布)。 Reference: http://maider.blog.sohu.com/306392863.html 多项式分布(Multinomial Distribution):二项式分布的推广。 γ分布(Gamma Distribution):与β分布的联系。

【论文阅读笔记】HermesSim(Code is not Natural Language) (Security 24)
个人博客地址 HermesSim [Security 24] 论文:《Code is not Natural Language: Unlock the Power of Semantics-Oriented Graph Representation for Binary Code Similarity Detection》 仓库:https://github.com/NSSL-SJTU/Her
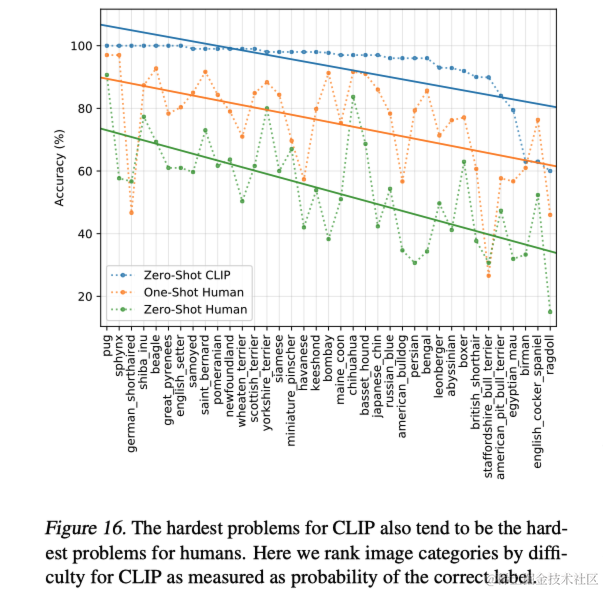
CLIP论文笔记:Learning Transferable Visual Models From Natural Language Supervision
导语 会议:ICML 2021链接:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf 当前的计算机视觉系统通常只能识别预先设定的对象类别,这限制了它们的广泛应用。为了突破这一局限,本文探索了一种新的学习方法,即直接从图像相关的原始文本中学习。本文开发了一种简单的预训练任务,通过预测图片与其对应标题的匹配关系,从而有效地从一

Detection of ADHD based on Eye Movements during Natural Viewing论文代码复现
Detection of ADHD based on Eye Movements during Natural Viewing论文的复现 论文链接:https://arxiv.org/pdf/2207.01377.pdf 代码链接:https://github.com/aeye-lab/ecml-ADHD 1.环境搭建 原始环境搭建存在不兼容,修改后requiremen.txt 降

浅读 Natural Language Generation Model for Mammography Reports Simulation
浅读 Natural Language Generation Model for Mammography Reports Simulation 这是一篇报告生成 去伪 的文章,重点看生成报告的 真实性 Abstract Extending the size of labeled corpora of medical reports is a major step towards a succ
Coursera自然语言处理专项课程03:Natural Language Processing with Sequence Models笔记 Week02
Natural Language Processing with Sequence Models Course Certificate 本文是https://www.coursera.org/learn/sequence-models-in-nlp 这门课程的学习笔记,如有侵权,请联系删除。 文章目录 Natural Language Processing with Seque

【论文阅读】CodeBERT: A Pre-Trained Model for Programming and Natural Languages
目录 一、简介二、方法1. 输入输出表示2. 预训练数据3. 预训练MLMRTD 4. 微调natural language code searchcode-to-text generation 三、实验1. Natural Language Code Search2. NL-PL Probing3. Code Documentation Generation4. 泛化实验
【论文阅读】Ask me anything: Dynamic memory networks for natural language processing
目录 一、简介二、方法/模型模型架构Input ModuleQuestion ModuleEpisodic Memory Module内存更新 Answer Module 三、实验1. 数据集2. 实验设置3. 实验结果 四、结论 paper地址:https://arxiv.org/pdf/1506.07285v5.pdf 代码地址:https://github.com/
自然语言处理概述(Natural Language Process)
近年来,人工智能逐渐成为了当前社会最热门的行业之一,也逐渐的进入了寻常百姓家。比如我们熟知的AlphaGo击败韩国围棋冠军李世石,小米的语音助手小爱同学,英国的智能机器人Sophia,喜马拉雅的小雅音响,Tesla的自动驾驶汽车等等。一方面我们在享受着人工智能带来的种种便利,一方面我们也在担心自己的工作会不会很快被人工智(Ai)能替代。其实在此我举一个Google translator的例子,这是
NLU(Natural Language Understanding)IS HARD ! !!
转自:https://github.com/fighting41love/hardNLU NLU is hard!!!!!! 一直关注刘群老师的微博,常常看见他分享的一些好玩的#自然语言理解太难了#。 遂整理了NLU实在是太难了系列语句,大家一笑无妨。这里列举了一些关于分词、实体识别、知识图谱相关的语句,按照难度从低到高排列,最高难度的放在了最后(需要强大的知识图谱哦,欢迎大家把答案开在

自然语言处理(Natural Language Processing,NLP)解密
专栏集锦,大佬们可以收藏以备不时之需: Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9 Python 专栏:http://t.csdnimg.cn/hMwPR Redis 专栏:http://t.csdnimg.cn/Qq0Xc TensorFlow 专栏:http://t.csdnimg.cn/SOien Logback 专栏:http://t.cs

Elasticsearch: NLP (Natural Language Processing)在 Elasticsearch 中的应用 - 7.x
特别指出:这篇文章的内容适合 Elastic Stack 7.x 的发布。在最新的 Elastic Stack 8.x 的发布中,我们不需要安装任何的 NLP plugin。 通过 NLP,我们可以把我们导入的文档进行丰富,从而有更多内容供我们进行搜索,为我们更为精准的搜索打下基础。在今天的文章里,我来介绍一下 NLP 在 Elasticsearch 中的实际应用。我们可以看一下如下
【图像拼接】源码精读:Adaptive As-Natural-As-Possible Image Stitching(AANAP/ANAP)
第一次来请先看这篇文章:【图像拼接(Image Stitching)】关于【图像拼接论文源码精读】专栏的相关说明,包含专栏内文章结构说明、源码阅读顺序、培养代码能力、如何创新等(不定期更新) 【图像拼接论文源码精读】专栏文章目录 【源码精读】As-Projective-As-Possible Image Stitching with Moving DLT(APAP)第一部分:全局单应Globa
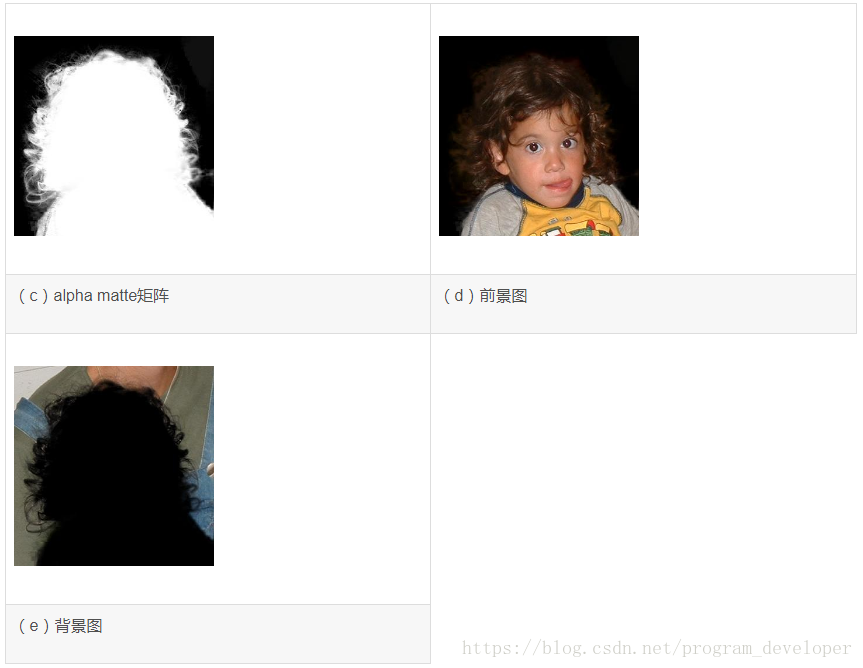
图像抠图的closed form算法(A Closed-Form Solution to Natural Image Matting)
关于图像抠图算法,Levin等人在2007年基于图像的局部光滑假设,利用代数的方法推导出了alpha matte矩阵闭合解的形式。原文名称是”A Closed Form Solution to Natural Image Matting”。 在抠图问题中,假设第i个像素点的值 Ii I i I_{i}是由前景点 Fi F i F_{i}和背景点 Bi B i B_{i}按下式加权合成的:
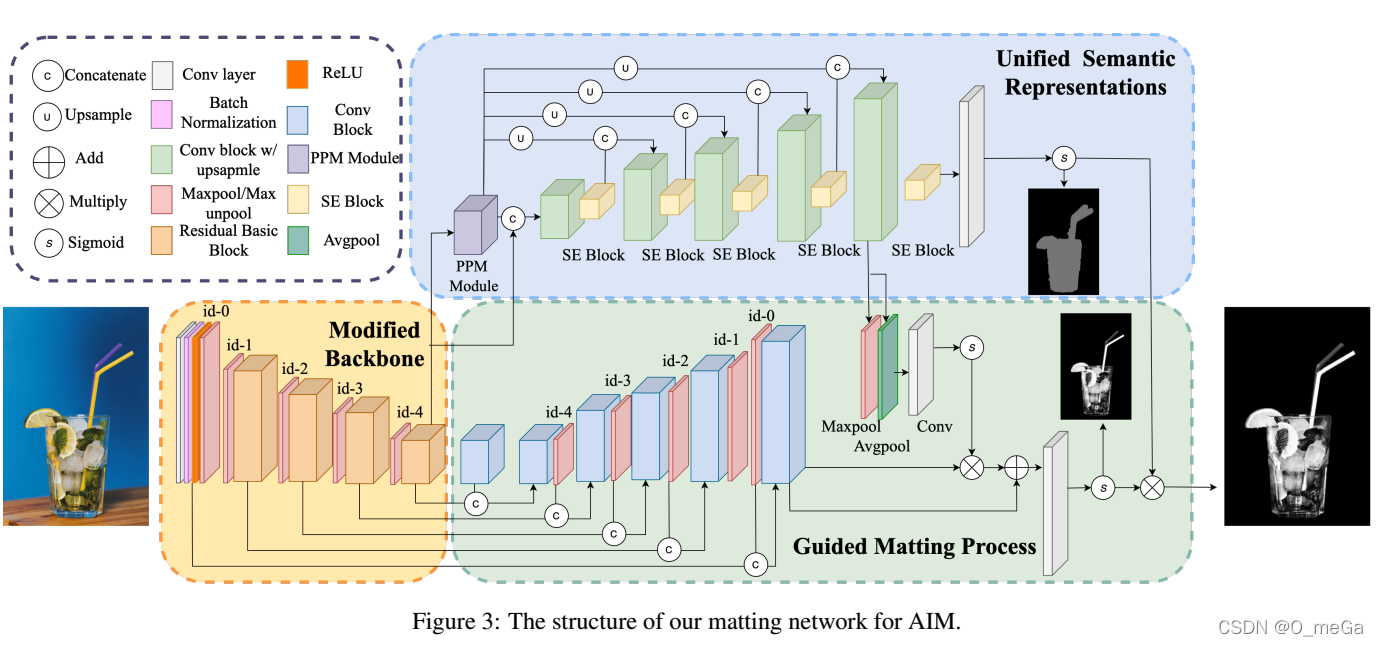
2.AIM: Deep Automatic Natural Image Matting
目录 亮点大体过程参考 亮点 不仅关注显著的前景抠图,对不显著前景抠除效果也不错;端到端,无需额外输入;思路清晰明了。 大体过程 编码器下采样提取特征;解码器一个分支经过psp(各种池化融合)模块不断上采样(关注全局信息),最终获得三个通道的特征图a(按通道获取最大值的索引,便可得到trimap);解码器另一个分支不断与编码器同尺度特征图concat+卷积+上采样(关注局
![[UNILM]论文实现:Unified Language Model Pre-training for Natural Language.........](https://img-blog.csdnimg.cn/direct/bdb2bfeb4c9b41ada63ef02eb2e2200c.png)
[UNILM]论文实现:Unified Language Model Pre-training for Natural Language.........
文章目录 一、完整代码二、论文解读2.1 介绍2.2 架构2.3 输入端2.4 结果 三、过程实现四、整体总结 论文:Unified Language Model Pre-training for Natural Language Understanding and Generation 作者:Li Dong, Nan Yang, Wenhui Wang, Furu Wei,
![[译] 使用Natural Language API分析文本的实体与情感](http://ww1.sinaimg.cn/large/005MY9Xigy1fq3h4ul57oj30l605ndgg.jpg)
[译] 使用Natural Language API分析文本的实体与情感
CSDN广告邮件太多了,邮箱已经屏蔽了CSDN,留言请转SegmentFault:https://segmentfault.com/a/1190000014216330 原文:Natural Language APIでエンティティと感情を分析する 概要 使用 Cloud Natural Language API ,可以从文本中提取实体、分析情感、解析文本构成。 此次向导中,我们将针对

Discourse Marker Augmented Network with Reinforcement Learning for Natural Language Inference
基于连词加强网络和强化学习的自然语言推理模型 这篇文章是浙江大学CAD&CG国家重点实验室和阿里巴巴-浙大前沿技术联合研究院合作设计了基于连词加强网络的自然语言推理方法,并在此基础上应用了强化学习来整合不同样本的标注意见不统一的情况,从而提升模型的稳定性。该成果已发表于自然语言处理领域国际顶级会议ACL 2018。最近看到这篇文章感到对自己启发挺大,所以写个微博记录一下~ 摘要 自然语言推理