本文主要是介绍【论文阅读】Ask me anything: Dynamic memory networks for natural language processing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、简介
- 二、方法/模型
- 模型架构
- Input Module
- Question Module
- Episodic Memory Module
- 内存更新
- Answer Module
- 三、实验
- 1. 数据集
- 2. 实验设置
- 3. 实验结果
- 四、结论

paper地址:https://arxiv.org/pdf/1506.07285v5.pdf
代码地址:https://github.com/radiodee1/awesome-chatbot
一、简介
自然语言处理中的许多问题都可以当作QA问题来处理,动态记忆网络(DMN)是一种处理输入序列和问题、形成情景记忆并生成相关答案的神经网络结构。
DMN使用input-question-answer三元组作为输入,可用于解决序列标注问题,分类问题,sequence-to-sequence 任务以及问答任务。(当作QA任务)
问题会触发一个迭代注意过程,该过程允许模型将其注意条件设置为输入和先前迭代的结果。然后用递归序列模型对这些结果进行推理,生成答案。
二、方法/模型
模型架构
(主要基于GRU)
动态记忆网络DMN包括输入模块、问题模块、情境记忆模块、应答模块:
- Input Module 输入模块:将任务中的原始文本输入编码为分布式向量表示
- Question Module 问题模块:将任务中的问题编码为分布式向量表示
- Episodic Memory Module 情境记忆模块:根据输入的表示来检索新信息
- Answer Module 应答模块:Answer模块从内存模块的最终内存向量中生成一个答案

流程如下:
- 计算输入和问题的向量表示
- 根据问题触发Attention机制,使用门控的方法选择出跟问题相关的输入
- 情景记忆模块会结合相关的输入和问题进行迭代生成记忆,并且生成一个答案的向量表示。
- 应答模块结合该向量以及问题向量,生成最终的答案
Input Module
可以利用RNN编码输入的句子,word embeddings作为循环网络的输入,在每个时间步长t处,网络更新其隐藏状态ht= RNN(L[wt], ht−1),其中L为嵌入矩阵,wt为输入序列第t个单词的单词索引。
输入单句时,输出递归网络的隐藏状态;输入多句时,将句子连接成一个单词标记的长列表,并在每个句子之后插入一个句子结束标记,每个句子结束标记处的隐藏状态就是输入模块的最终表示。
本文的循环神经网络选取的是GRU:

简写为: h t = G R U ( x t , h t − 1 ) h_t= GRU(x_t, h_{t−1}) ht=GRU(xt,ht−1)
Question Module
给定问题 T Q T_Q TQ个词, t时刻问题编码器的隐藏状态为: q t = G R U ( L [ w t Q ] , q t − 1 ) q_t= GRU(L[w^Q_t], q_{t−1}) qt=GRU(L[wtQ],qt−1) L表示上一节中的word embedding矩阵, w t Q w^Q_t wtQ表示问题中第 t t t个单词的索引。输入模块和问题模块之间共享word embedding矩阵。与输入模块不同,问题模块输出递归网络编码器的最终隐藏状态 q = q T Q q = q_{T_Q} q=qTQ
Episodic Memory Module
情景记忆模块在输入模块输出的表示上迭代,同时更新其内部情景记忆。在一般形式下,情景记忆模块由注意机制和不断更新记忆的循环网络组成。在每次迭代过程中,注意机制参与事实表征c,同时考虑问题表征q和之前的记忆 m i − 1 m^{i−1} mi−1生成事件 e i e^i ei, 然后这个情节和之前的记忆 m i − 1 m^{i−1} mi−1一起被用来更新情景记忆: m i = G R U ( e i , m i − 1 ) m^i = GRU(e^i, m^{i−1}) mi=GRU(ei,mi−1) 这个GRU的初始状态被初始化为问题向量本身,即 m 0 = q m^0= q m0=q。对于某些任务来说,对输入进行多次传递是有利于情景记忆模块的。在 T M T_M TM通过之后,最后的内存 m T M m^{T_M} mTM传递给答案模块。
内存更新
为了计算第i步的情节,对输入序列 c 1 , … , c T C c1,…, c_{T_C} c1,…,cTC应用共享了 g i g^i gi权重的GRU。GRU最终的隐藏状态作为传递给应答模块的episode vector。t时刻GRU隐藏状态的更新方程和episode情景计算方程分别为:
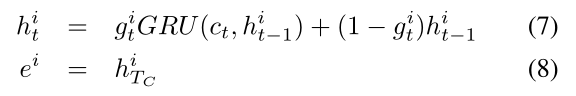
Answer Module
answer模块根据给定的向量生成一个答案。根据任务类型的不同,答案模块要么在情景记忆结束时触发一次,要么在每个时间步中触发一次。
使用另一个初始状态被初始化为最后一个内存 a 0 = m T M a_0= m^{T_M} a0=mTM的GRU。在每个时间步中,它将最后一个隐藏状态为 a t − 1 a_{t-1} at−1的问题q以及之前预测的输出 y t − 1 y_{t−1} yt−1作为输入。
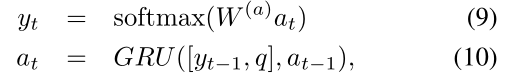
在这里,我们将最后生成的单词和问题向量连接起来作为每个时间步的输入。输出通过正确序列的交叉熵错误分类进行训练,并附加一个特殊的序列结束标记。
三、实验
1. 数据集
-
Facebook的bAbI数据集(问答),用于测试模型检索事实和推理的能力
-
SST(情感分类),提供了短语级的细粒度标签,所有完整的句子(根节点)的测试集分为:非常消极的、负面的、中性的、积极的,或非常积极。
-
WSJ-PTB(词性标注)

2. 实验设置
使用GloVe对单词向量进行预先训练
3. 实验结果
QA:

情感分析:

词性标注:

四、结论
DMN模型是各种NLP应用程序的潜在通用体系结构,包括分类、问题回答和序列建模。
有帮助的话可以点个赞喔~

这篇关于【论文阅读】Ask me anything: Dynamic memory networks for natural language processing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








