本文主要是介绍[UNILM]论文实现:Unified Language Model Pre-training for Natural Language.........,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、完整代码
- 二、论文解读
- 2.1 介绍
- 2.2 架构
- 2.3 输入端
- 2.4 结果
- 三、过程实现
- 四、整体总结
论文:Unified Language Model Pre-training for Natural Language Understanding and Generation
作者:Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon
时间:2019
地址:https://github.com/microsoft/unilm
一、完整代码
这里我们使用python代码进行实现
# 完整代码在这里
# 有时间再弄.......
二、论文解读
2.1 介绍
这篇论文主要讲的是一个统一的语言模型的预训练,其就是结合三种语言模型来对结果进行优化:unidirectional, bidirectional, sequence-to-sequence;前者的代表是GPT;中间的代表是BERT;后面很新奇,但是其本质也很简单,类似于GPT在mask加掩码;

这里并不是一个模型中包含这三种层来进行训练,而是共享参数然后对每一个语言模型的要求进行mask再来训练;

一个语言模型对应一个或几个下游任务,让模型理解这个下游任务,然后叠加,这个就是UNILM;
2.2 架构
模型架构如图所示:
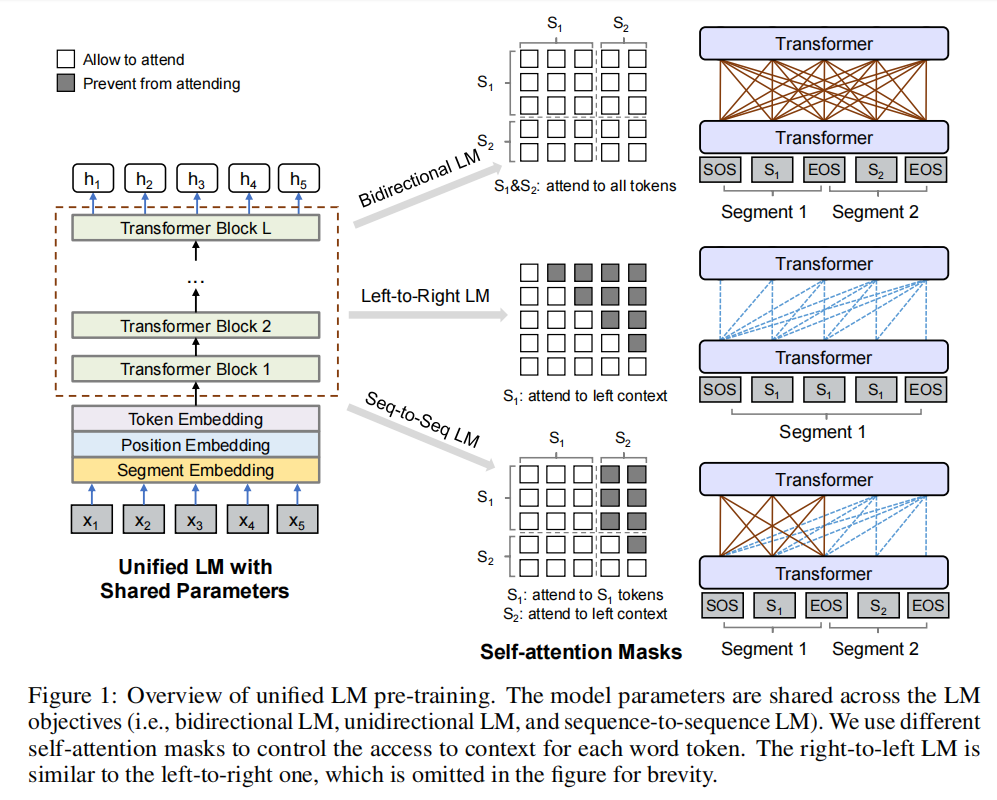
这个不就是mask一下吗,换着花样水,感觉就是统一了一下,没想到这也能发论文,哈哈哈哈;

以上是其架构的公式;注意这里在训练时M结构是不发生改变的;
2.3 输入端
这里在输入端和bert一样,选择加随机掩码的方式,把随机的字符换成[mask]
2.4 结果
Question Answering
第一个被称为extractive QA,其中答案是段落中的文本跨度。另一种称为generative QA,答案需要动态生成。

Question Generation
Given an input passage and an answer span, our goal is to generate a question that asks for the answer.
就是给一段文本和答案,输出该答案的问题;

Response Generation
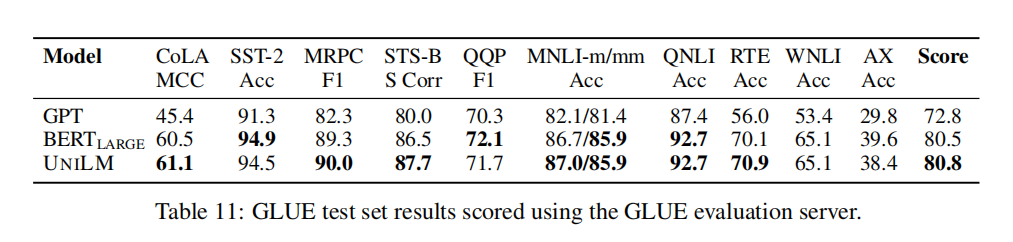
这样可以说明我们结合三种模型的效果在训练步骤一致的情况下和BERT是不相上下的,但是这里要清楚的是:UNILM的初始架构是和BERT large是一致的,这样看来UNILM有种类似于regularization的效果;
三、过程实现
实现过程比较简单,有时间再弄;
四、整体总结
这篇文章最重要一点就是结合多种模型来适配多种任务得到的效果要比单一的模型要好;
这篇关于[UNILM]论文实现:Unified Language Model Pre-training for Natural Language.........的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




