本文主要是介绍CLIP论文笔记:Learning Transferable Visual Models From Natural Language Supervision,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导语
- 会议:ICML 2021
- 链接:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf
当前的计算机视觉系统通常只能识别预先设定的对象类别,这限制了它们的广泛应用。为了突破这一局限,本文探索了一种新的学习方法,即直接从图像相关的原始文本中学习。本文开发了一种简单的预训练任务,通过预测图片与其对应标题的匹配关系,从而有效地从一个包含4亿图像-文本对的大数据集中学习图像表征。该方法能够在没有额外特定数据训练的情况下,让模型在多达30种不同的计算机视觉任务上达到与传统方法相媲美的性能。例如,在不使用任何训练数据的情况下,CLIP模型在ImageNet上实现了与原始ResNet-50相同的准确率。
1 引言与动机
直接从原始文本中学习的预训练方法在过去几年里已经彻底改变了自然语言处理领域。通过将“文本到文本”作为标准化的输入输出接口,如GPT-3等,这些架构能够在无需针对具体任务设计专门的输出头的情况下,直接转移到下游数据集。尽管在计算机视觉领域,使用众包数据集如ImageNet进行模型预训练仍是常规做法,但有研究显示,从网络文本直接学习的预训练方法在计算机视觉中同样具有突破性潜力。历史上,已有多个工作展示通过训练模型预测与图像相关的文字,可以有效地提升图像的表示学习。
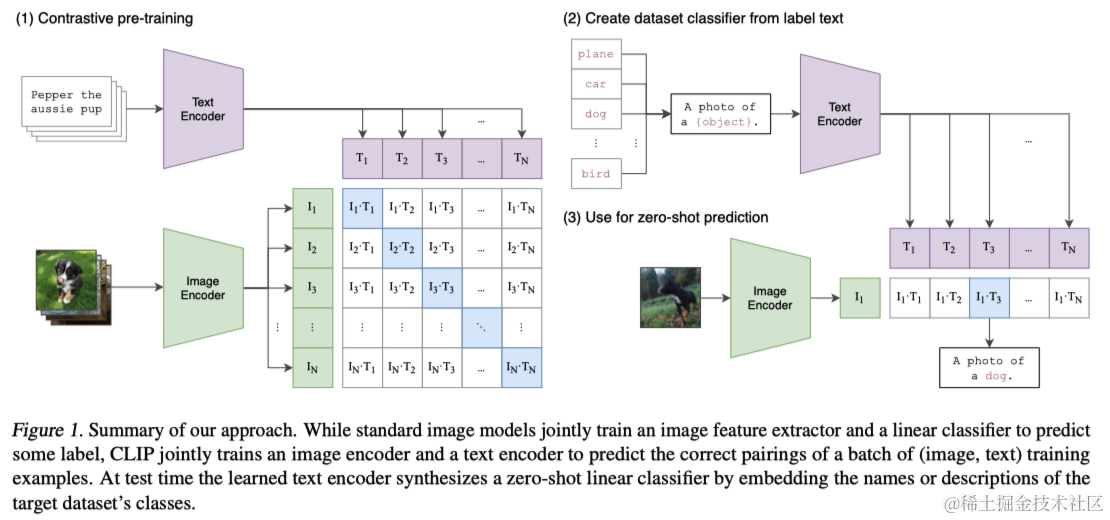
在此基础上,本文提出了一个新的模型CLIP(Contrastive Language-Image Pre-training),这是一个简化版的ConVIRT,旨在通过大规模的自然语言监督学习图像表示。本文首先创建了一个包含4亿图像-文本对的新数据集,并发现CLIP在从自然语言监督中学习方面极为有效。通过对比训练多个模型,观察到转移性能与计算投入成平滑可预测的关系。
CLIP在预训练期间学会执行包括OCR、地理定位和动作识别在内的多种任务,并且在30多个现有数据集上的零样本转移性能可以与先前的任务特定监督模型相媲美。此外,CLIP的线性探针(Linear Probing,即固定模型参数,仅微调分类头)表示学习分析显示其性能优于最佳公开可用的ImageNet模型,并具有更高的计算效率。这些发现突显了利用自然语言进行图像表示学习的巨大潜力,同时也提示了这种方法在未来的政策和伦理方面可能带来的重要影响。
2 方法
2.1 自然语言监督
尽管利用自然语言作为训练信号的思想并不新颖,但相关工作中使用的术语多样且似乎相互矛盾。不同的研究,虽然都采用了从文本学习视觉表征的方法,但被分别标记为无监督、自监督、弱监督和监督学习。本文强调,这些研究的共同点在于对自然语言作为训练信号的重视,而不是具体方法的细节。
随着深度上下文表示学习的进步,我们现在具备了有效利用这一丰富监督源的工具。与传统的众包图像分类标注相比,自然语言监督的扩展性更强,它允许从互联网上的大量文本中被动学习,而不需要符合典型的机器学习格式。此外,与大多数无监督或自监督学习方法相比,从自然语言学习不仅仅是学习一种表征,而且还能将该表征与语言连接起来,从而实现灵活的零样本转移。接下来的部分将详细介绍本研究确定的具体方法。
2.2 创建足够大的数据集
虽然已有数据集如MS-COCO、Visual Genome和YFCC100M提供了一定的图像-文本对,但它们的规模相对较小或元数据质量参差不齐。例如,YFCC100M数据集虽然拥有1亿张照片,但其元数据的实用性有限,过滤后只剩1500万张照片,与ImageNet的规模相当。
为充分发挥自然语言监督的潜力,本文构建了一个新的、包含4亿对(图像,文本)的数据集,称为WIT(WebImageText)。该数据集从互联网上公开可用的资源中收集而来,旨在涵盖尽可能广泛的视觉概念。在数据集构建过程中,作者使用了500,000个搜索查询,并通过每个查询最多包含20,000对(图像,文本)来实现类别的近似平衡。这样的方法不仅提供了与GPT-2训练用的WebText数据集相似的词汇量,还为自然语言视觉监督提供了一个前所未有的规模。
2.3 选择高效的预训练方法
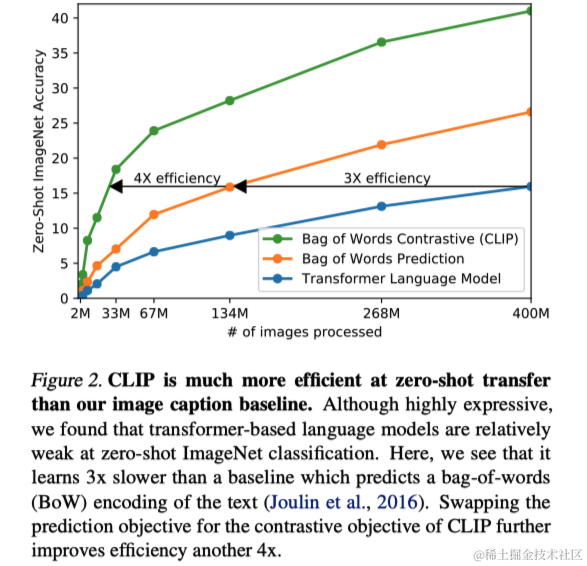
鉴于先前系统例如ResNeXt101-32x48d和Noisy Student EfficientNet-L2的高计算需求,从自然语言中学习视觉概念是一项艰巨的任务。因此,训练效率成为了成功扩展自然语言监督的关键。作者最初尝试了类似于VirTex的方法,即从零开始共同训练图像CNN和文本Transformer来预测图像的标题。但是,这种方法在效率上的扩展遇到了困难。作者随后探索了一种可能更简单的代理任务,即预测哪些文本与哪些图像配对,而非预测文本的确切单词。这一转变到使用对比目标后,观察到零样本转移到ImageNet的效率提高了四倍。
为此,作者开发了CLIP模型,它通过预测批次中实际发生的图像和文本配对来训练。CLIP通过联合训练图像编码器和文本编码器来学习一个多模态嵌入空间,最大化真实配对的图像和文本嵌入的余弦相似度,同时最小化错误配对的相似度。此外,CLIP模型的训练相对简化,不依赖于预训练权重或复杂的投影技术,仅使用线性投影,并直接在训练中优化温度参数,避免了作为超参数的调整。
CLIP的简单伪代码实现如下:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)# symmetric loss function labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
这些方法的改进显示了自然语言监督在学习图像表示时的潜力,并突出了在大规模数据集上训练时过拟合不是主要问题,使得训练过程更为高效和简化。
2.4 选择和扩展模型
本文探讨了用于图像编码器的两种不同架构。首先采用了广泛应用并且性能验证的ResNet-50作为基础架构,对其进行了多项改进,包括采用ResNetD改进和抗锯齿模糊池化技术,并引入了基于注意力的池化机制。此外,作者还尝试了新近提出的ViT,并对其实现进行了轻微的修改,以提高其效率。
文本编码器则采用了Transformer架构,并进行了适当的调整以优化性能。本文使用了具有63M参数的Transformer,操作在文本的小写字节对编码(BPE)表示上,最大序列长度被限制以提高计算效率。此外,文本序列处理采用了[SOS]和[EOS]标记,并将文本的特征表示通过线性投影映射到多模态嵌入空间。
在模型扩展方面,与传统单一维度增强不同,作者采纳了在宽度、深度和分辨率上均衡增加计算资源的方法。这种方法不仅提高了模型的整体性能,也体现了现代计算视觉研究中对效率和综合能力的重视。文本编码器的扩展则专注于增加宽度而非深度,因为本文研究发现CLIP模型的性能对文本编码器的容量变化不敏感。
2.5 训练
作者训练了5种ResNets和3种ViT。对于ResNets,训练了一个ResNet-50、一个ResNet-101和三种遵循EfficientNet风格模型扩展的ResNet,分别使用约为ResNet-50的4倍、16倍和64倍的计算资源,被称为RN50x4、RN50x16和RN50x64。对于ViT,训练了一个ViT-B/32、一个ViT-B/16和一个ViT-L/14。
所有模型均训练了32个Epoch。使用Adam优化器并应用解耦权重衰减正则化,对所有非增益或偏差的权重进行正则化,并使用余弦调度来衰减学习率。初始超参数是通过在训练了1个Epoch的基线ResNet-50模型上使用网格搜索、随机搜索和手动调整的组合设置的。
由于计算限制,对更大的模型,超参数则是通过启发式方法调整的。可学习的温度参数τ初始化为0.07,并进行了限制,以防止对数因子扩展超过100,这一措施被发现对防止训练不稳定是必要的。使用非常大的批量大小,为32,768。使用混合精度来加速训练并节省内存。为了节省额外的内存,使用了梯度检查点、半精度Adam统计和半精度随机舍入的文本编码器权重。嵌入相似性的计算也被分片,每个GPU只计算其本地批次嵌入所需的部分成对相似性。
最大的ResNet模型,RN50x64,在592个V100 GPU上训练了18天,而最大的ViT在256个V100 GPU上训练了12天。对于ViT-L/14,还在一个额外的Epoch内以更高的336像素分辨率进行预训练,以提升性能,类似于FixRes。本文将这个模型标记为ViT-L/14@336px。除非另有说明,本文报告的所有“CLIP”结果均使用这个表现最佳的模型。
3 实验
3.1 零样本迁移
3.1.1 动机
零样本学习通常指的是在图像分类中泛化到未见过的对象类别的研究。本文更广泛地使用这个术语,研究对未见过的数据集的泛化能力。Visual N-Grams首次研究了以上所述方式对现有图像分类数据集的零样本转移。这也是所知的唯一一个使用通用预训练模型研究对标准图像分类数据集的零样本转移的工作,并作为对CLIP进行情境化的最佳参考点。
本文关注研究零样本转移作为任务学习评估的灵感来自于NLP领域展示任务学习的工作。Liu等人首次将任务学习识别为当一个训练用来生成维基百科文章的语言模型学会可靠地在不同语言之间转录名称时的“意外副作用”。尽管GPT-1侧重于作为转移学习方法的预训练,以改善监督微调,但它还包括了一个剖析研究,表明四种启发式零样本转移方法的性能在预训练过程中稳步提高,而无需任何监督适应。这一分析为GPT-2奠定了基础,后者专门研究通过零样本转移探索语言模型的任务学习能力。
3.1.2 使用CLIP进行零样本转移
CLIP预训练的目标是预测图像和文本片段在其数据集中是否配对。为了进行零样本分类,对于每个数据集,使用数据集中所有类别的名称作为潜在的文本配对集,并预测根据CLIP最可能的(图像,文本)配对。更具体地说,首先通过各自的编码器计算图像的特征嵌入和一组可能文本的特征嵌入。然后计算这些嵌入的余弦相似度,通过温度参数τ进行缩放,并通过softmax标准化成一个概率分布。需要注意的是,这一预测层是一个多项逻辑回归分类器,具有L2标准化的输入、L2标准化的权重、无偏置和温度缩放。从这个角度解释时,图像编码器是计算图像特征表示的计算机视觉主干,而文本编码器是一个超网络,基于指定类别所代表的视觉概念的文本生成线性分类器的权重。CLIP预训练的每一步都可以视为优化随机创建的代理的性能,这一代理对应一个计算机视觉数据集,该数据集每个类别有1个样本,总共有32,768个类别,通过自然语言描述定义。对于零样本评估,作者在文本编码器计算出零样本分类器后将其缓存,并在所有后续预测中重用它。这允许在数据集的所有预测中分摊生成它的成本。
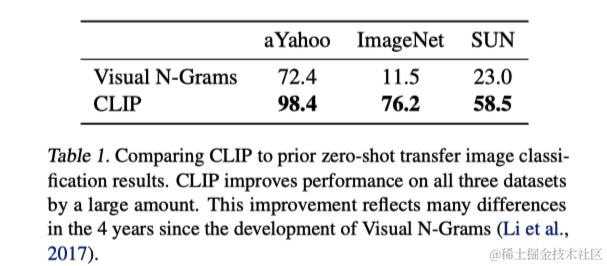
3.1.3 与Visual N-Grams的初次对比
作者将CLIP模型与Visual N-Grams进行了比较。CLIP显著提高了在ImageNet上的准确率,从11.5%提升至76.2%,并且达到了与原始ResNet-50相同的性能,尽管CLIP模型没有使用任何预先标注的训练样本。此外,CLIP模型在前5准确率上达到了95%,与Inception-V4相匹配。这一结果显示了CLIP在零样本学习环境下与完全监督学习模型相媲美的能力,突显了其作为一种灵活且实用的零样本视觉分类器的潜力。
此外,CLIP也在其他两个数据集上表现优于视觉N-Grams。在aYahoo数据集上,CLIP减少了95%的错误率,在SUN数据集上,其准确率是视觉N-Grams的两倍以上。作者还扩展了评估范围,包括超过30个数据集和与50多个现有计算机视觉系统的比较,以更全面地测试并展示CLIP的性能。
3.1.4 提示工程与集成
CLIP模型通过预测图像和文本片段是否配对来进行训练,这一能力使其能够进行零样本分类。在实践中,通过计算图像和潜在文本配对的特征嵌入及其余弦相似度,然后将这些相似度转化为概率分布,来预测最可能的(图像,文本)配对。
作者引入了“提示工程”和模型集成的概念来增强零样本转移性能。通过使用结构化的提示,如“A photo of a {label}.”,CLIP能更准确地识别图像内容,这在诸如ImageNet这样的基准测试中显著提高了准确率。例如,在Oxford-IIIT Pets数据集上使用特定的宠物类型提示或在FGVC Aircraft上使用特定的飞机类型提示都显示出了性能提升。
templates = ['a photo of a {}.','a blurry photo of a {}.','a black and white photo of a {}.','a low contrast photo of a {}.','a high contrast photo of a {}.','a bad photo of a {}.','a good photo of a {}.','a photo of a small {}.','a photo of a big {}.','a photo of the {}.','a blurry photo of the {}.','a black and white photo of the {}.','a low contrast photo of the {}.','a high contrast photo of the {}.','a bad photo of the {}.','a good photo of the {}.','a photo of the small {}.','a photo of the big {}.',
]
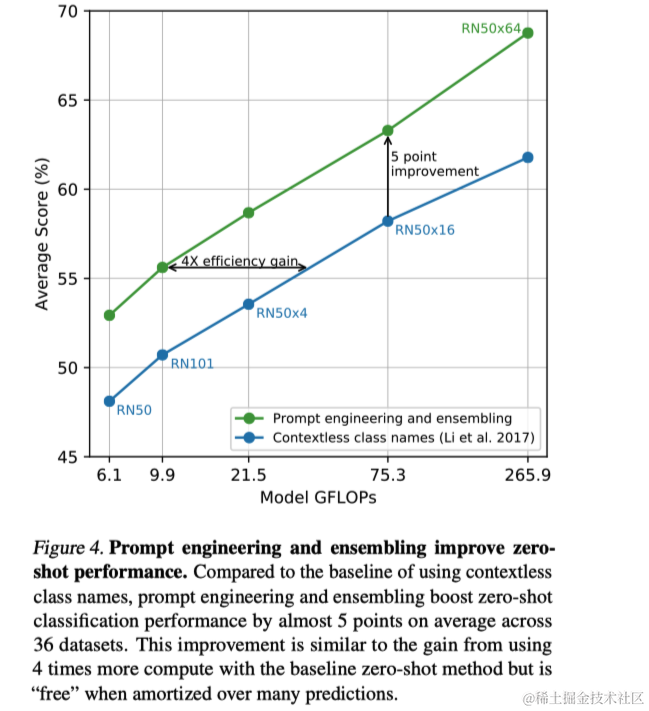
作者还实验了通过不同上下文提示计算多个零样本分类器的集成方法,以进一步提升性能。这种集成方法在嵌入空间而不是概率空间上构建,允许在多个预测中分摊生成的计算成本。例如,在ImageNet上,通过集成80种不同的上下文(如上面所示的CIFAR-100的模板列表)提示,CLIP的性能额外提高了3.5%。总体而言,提示工程和集成将ImageNet的准确率提高了近5%。这种方法不仅提高了模型的鲁棒性,还增强了其在不同数据集上的泛化能力。
3.1.5 零样本CLIP性能分析
由于计算机视觉中任务无关的零样本分类器研究不足,CLIP为深入理解这类模型提供了有前景的机会。本节对CLIP零样本分类器的多种属性进行了分析。
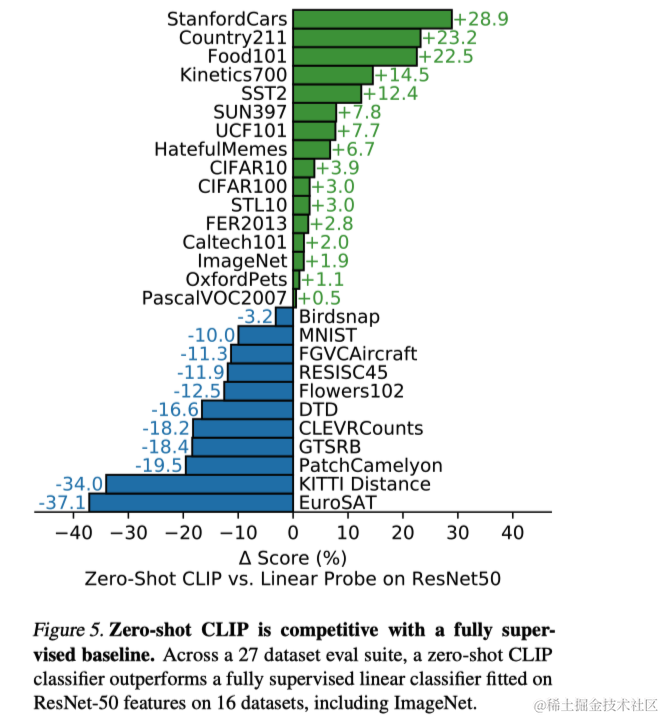
首先评估了零样本分类器的性能,并将其与在规范的ResNet-50特征上拟合的一个完全监督、规则化的逻辑回归分类器的基线性能进行了比较。CLIP在27个数据集中的16个上表现更好。在细粒度分类任务中,CLIP的表现有显著差异,例如,在Stanford Cars和Food101上,CLIP的表现超过了基线逻辑回归超过20%;而在Flowers102和FGVCAircraft上,则低于10%以上。在通用对象分类数据集(如ImageNet和CIFAR系列)上,零样本CLIP普遍表现略优。
然而,CLIP在一些专门的、复杂的或抽象的任务上表现不足,例如卫星图像分类和淋巴结肿瘤检测。这些结果表明CLIP在处理更复杂任务时的能力有限。研究者指出,与少样本转移相比,零样本转移的评价可能不足以反映学习者面对全新任务时的能力,尤其是那些人类几乎没有先验经验的任务。
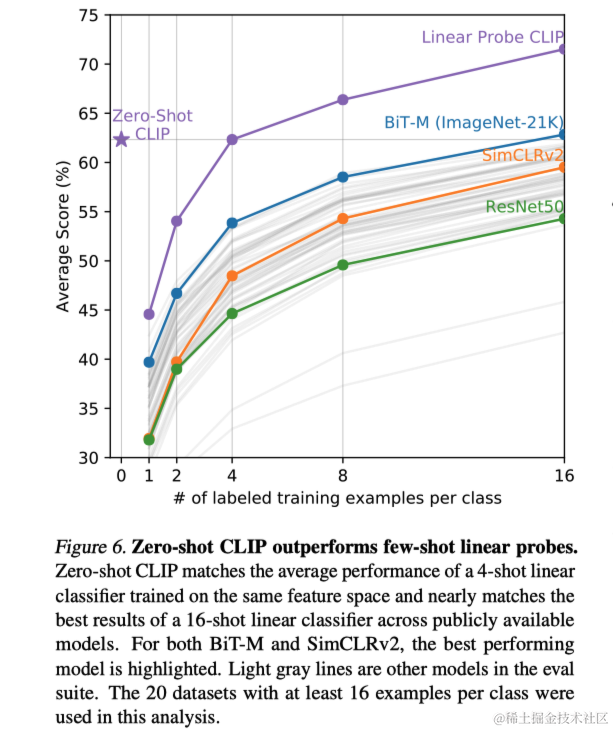
此外,通过将零样本CLIP与多个图像模型特征上的少样本逻辑回归进行比较,本文发现零样本CLIP与4样本逻辑回归的性能相当。这可能是因为CLIP的零样本分类器是通过自然语言生成的,可以直接指定视觉概念,而传统的监督学习需要从训练示例中间接推断概念。作者还探讨了使用CLIP的零样本分类器作为少样本分类器权重的先验的可能性,但发现在超参数优化中常常倾向于将零样本分类器作为结果,这指出了未来研究方向的一个潜在领域。
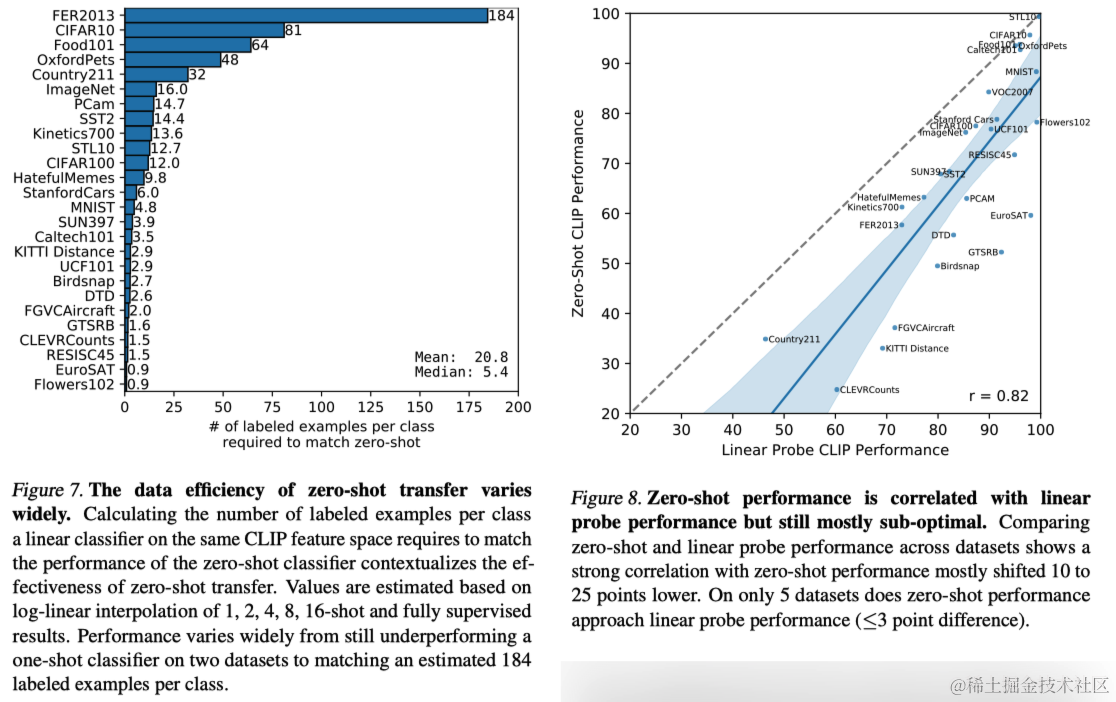
随后,作者进一步比较了零样本CLIP与在不同数据集上训练的完全监督线性分类器的表现,发现虽然零样本分类器的性能通常低于完全监督分类器10%到25%,但在一些数据集上,例如STL10和CIFAR10,零样本CLIP的表现几乎达到了完全监督的水平,显示出其在高质量底层表示任务中的零样本转移潜力。这表明,尽管CLIP的任务学习和零样本转移能力还有很大的提升空间,但它在连接底层表示和任务学习方面表现出了一致性。
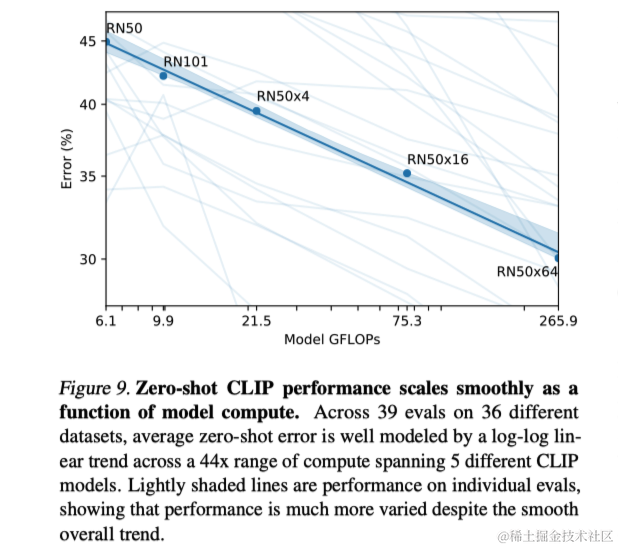
最后,CLIP模型的零样本性能显示出随着模型计算增加而改进的趋势,这与GPT模型系列的发现一致。作者认为,深入探索零样本和少样本学习方法的结合,有望进一步提升CLIP及类似模型的性能。
3.2 学习表示
本节在模型提取的表示上拟合线性分类器并测量其在各种数据集上的性能而不是全量微调。
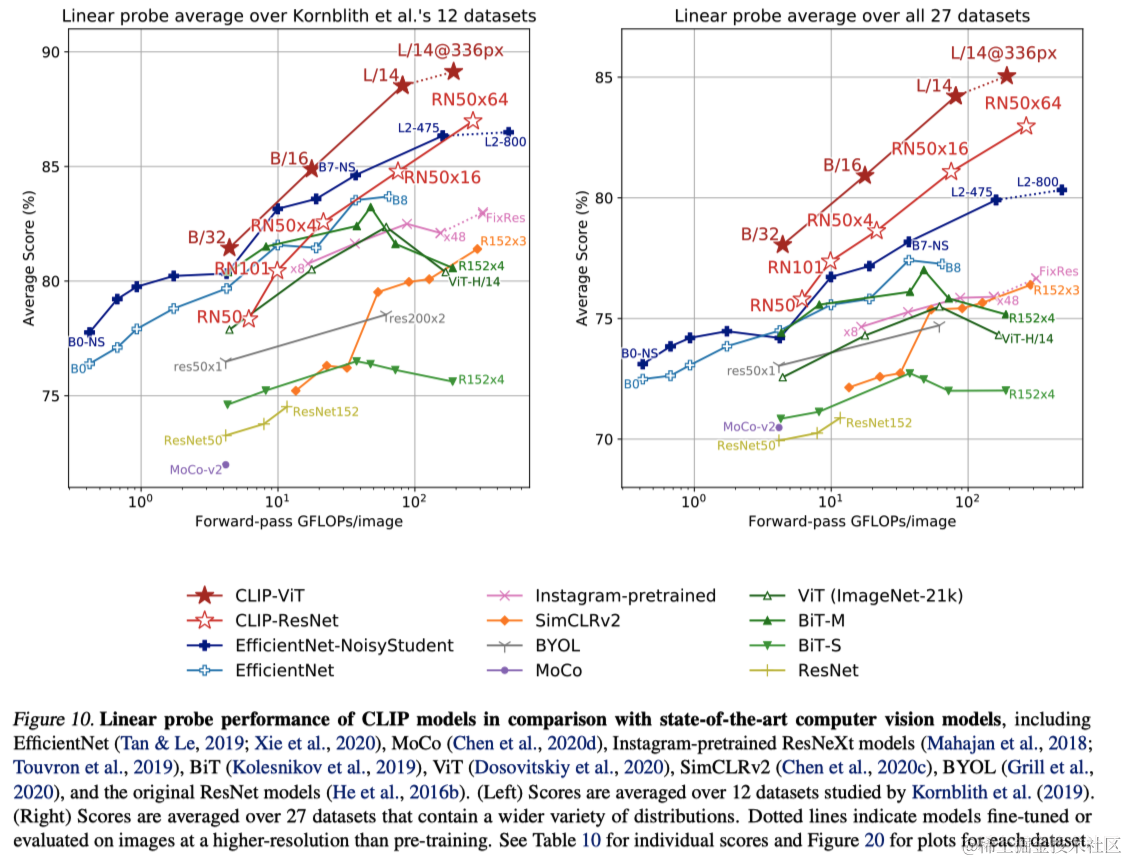
图10总结了实验发现。虽然小型CLIP模型如ResNet-50和ResNet-101比在ImageNet-1K(BiT-S和原始模型)上训练的其他ResNets表现更好,但它们在ImageNet-21K上训练的ResNets(BiT-M)表现不佳。这些小型CLIP模型在具有类似计算需求的EfficientNet系列模型上也表现不佳。然而,使用CLIP训练的模型可以很好地扩展,训练的最大模型(ResNet-50x64)在总体得分和计算效率上略胜于表现最佳的现有模型(一个Noisy Student EfficientNet-L2)。作者还发现CLIP的ViT比CLIP的ResNets计算效率高约3倍,这使能够在计算预算内达到更高的总体性能。这些结果在质量上复现了Dosovitskiy等人(2020年)的发现,后者报告称在足够大的
数据集上训练时,ViT比卷积网络更具计算效率。最佳整体模型是在本文的数据集上以336像素的更高分辨率微调一个额外的Epoch的ViT-L/14。这个模型在这个评估基准上的平均得分比最佳现有模型高出2.6%。
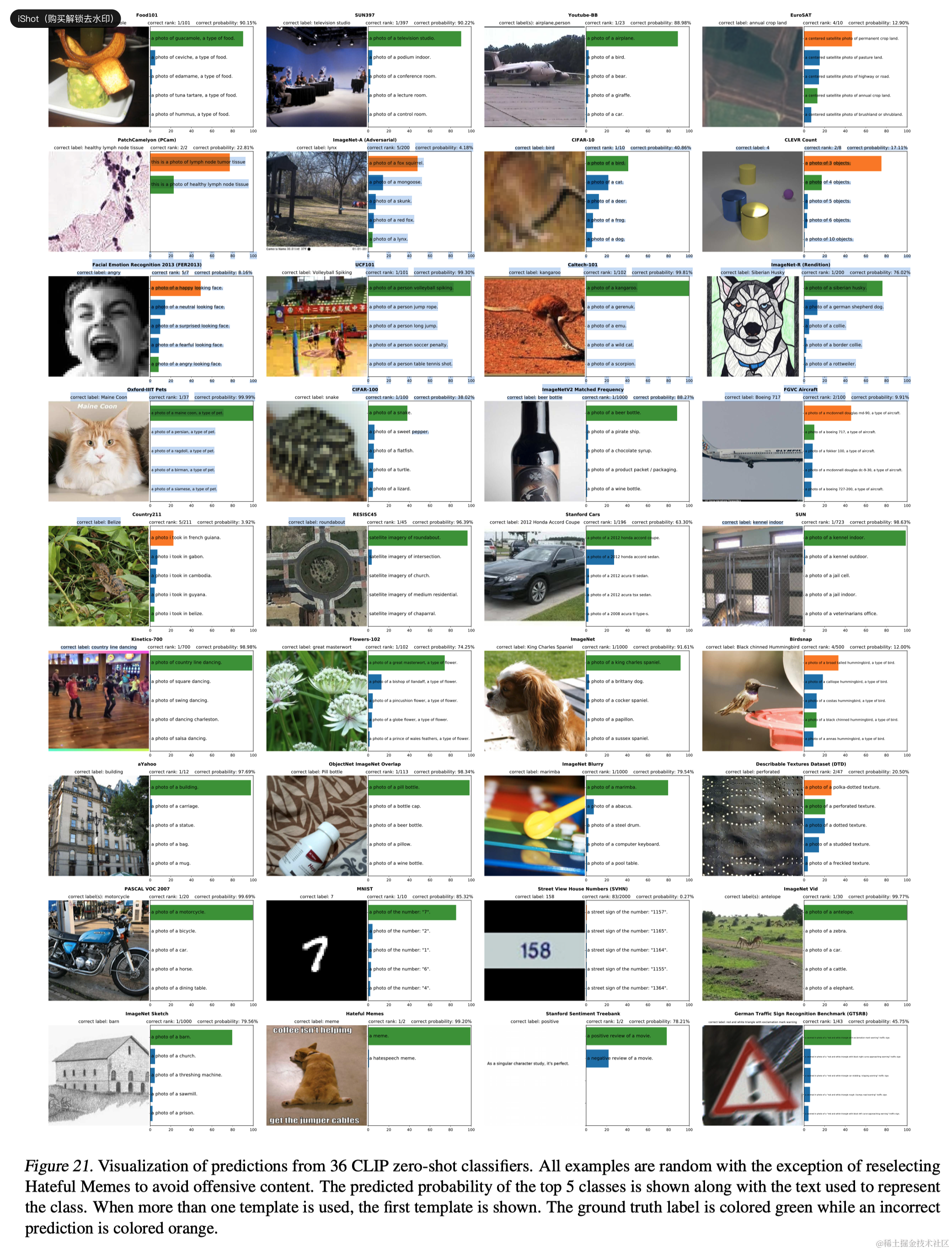
CLIP模型学习了比以往在单一计算机视觉模型中训练端到端从随机初始化开始所展示的更广泛的任务集。这些任务包括地理定位、光学字符识别、面部情感识别和动作识别。在这个更广泛的评估上,所有规模的CLIP模型在计算效率方面都超过了所有评估的系统。最佳模型的平均得分提高从2.6%增加到5%。作者还发现自监督系统在更广泛的评估上表现更好。例如,虽然SimCLRv2在Kornblith等人的12个数据集上平均表现仍然不如BiT-M,但在27个数据集评估套件上,SimCLRv2表现优于BiT-M。这些发现表明,继续扩展任务多样性和覆盖范围以更好地理解系统的“一般”性能是有价值的。
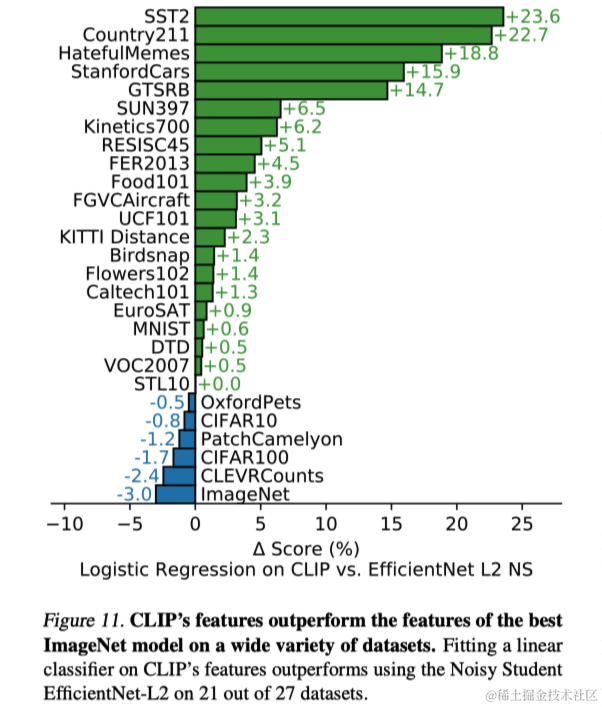
除了上述的综合分析外,作者还在图11中可视化了最佳CLIP模型和本文评估数据集中最佳模型在所有27个数据集上的性能差异,CLIP在27个数据集中的21个上优于Noisy Student EfficientNet-L2。
3.3 自然分布变化下的鲁棒性
在2015年,研究人员宣布深度学习模型在ImageNet测试集上超越了人类表现。然而,随后的研究发现这些模型仍然会犯许多简单的错误,并且在新的基准测试中,这些系统的性能通常远低于它们在ImageNet上的准确率和人类的准确率。这种差异背后的原因可能是深度学习模型极其擅长于发现训练数据集中存在的相关性和模式,这些模式并不适用于其他分布,导致在其他数据集上表现下降。
Taori等人的研究深入探讨了这一行为,特别是评估ImageNet模型在自然分布变化下的表现。他们发现,尽管某些技术被证明可以提高对合成分布变化的表现,但它们通常不能在自然分布上取得一致的改进。通过研究7种不同的自然分布变化,研究发现ImageNet模型的准确率大大低于ImageNet验证集的预期表现。
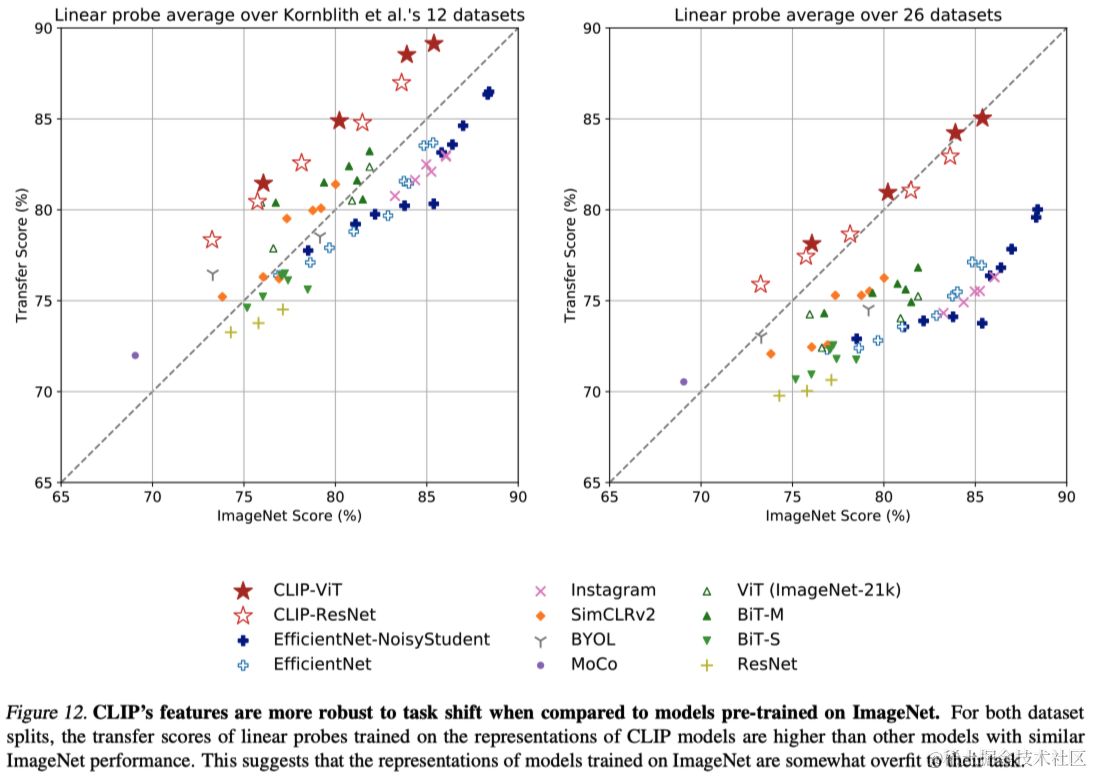
该研究提出,鲁棒性分析应区分有效鲁棒性和相对鲁棒性。有效鲁棒性是指在分布变化下准确率的改进,超出了根据分布内和分布外准确率已知关系的预期。相对鲁棒性则是指在分布外准确率的任何提高。文章还讨论了零样本模型应该具有更高的有效鲁棒性,因为它们没有在特定分布上训练,因此不太可能利用仅在特定分布上有效的虚假相关性和模式。
图13中比较了零样本CLIP与现有ImageNet模型在自然分布变化下的表现。所有零样本CLIP模型都大幅提高了有效鲁棒性,并将ImageNet准确率与分布变化下的准确率之间的差距减少了高达75%。

尽管CLIP模型在提高有效鲁棒性方面表现出色,这并不一定意味着在ImageNet上的监督学习造成了鲁棒性差距。CLIP的大规模和多样化的预训练数据集以及使用自然语言监督可能是造成这些模型更为鲁棒的原因。研究还试图通过将CLIP模型适应ImageNet分布来缩小这种差距,但发现虽然这提高了其在ImageNet上的准确率,但在分布变化下的平均准确率略有下降。图14中可视化了从零样本分类器到性能变化的情况。
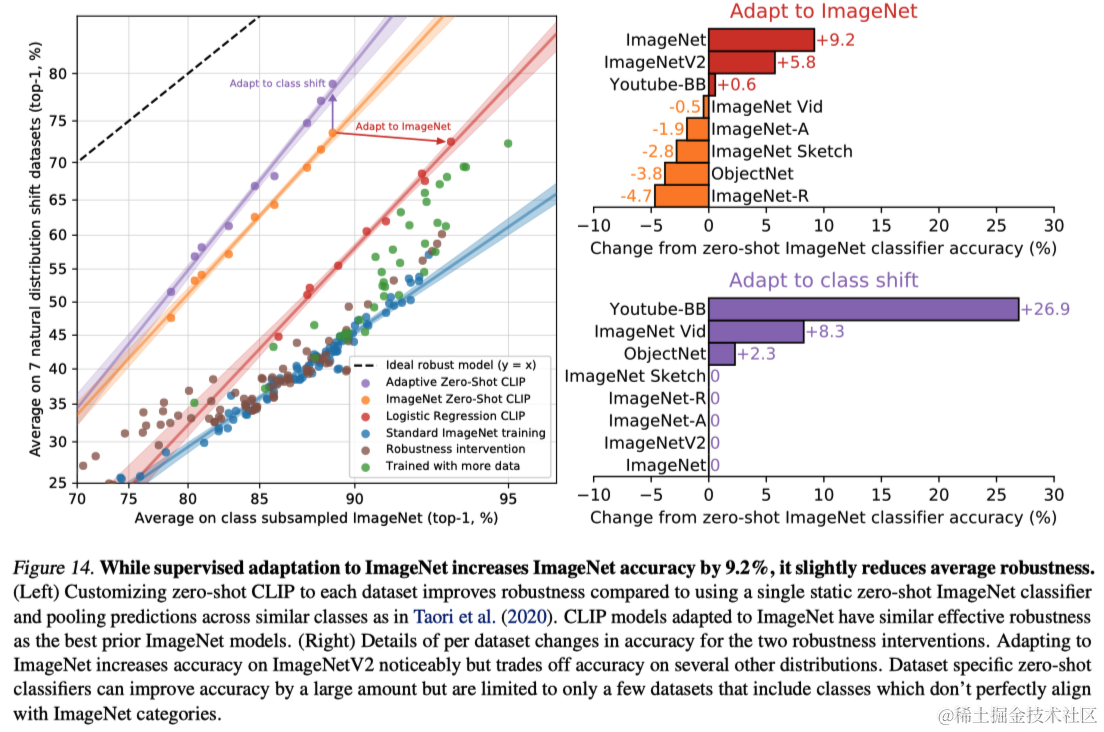
这些结果表明,向大规模任务和数据集不可知的预训练转变,并重视在广泛评估套件上的零样本和少样本基准测试,可以促进更鲁棒系统的开发,并提供更准确的性能评估。研究者们对于这些结果是否同样适用于NLP领域的零样本模型,如GPT系列,持开放态度,尽管目前的研究显示,在情感分析等任务上预训练的相对鲁棒性有所提高,但在自然分布变化下问答模型的有效鲁棒性改进证据仍不足。
4 与人类性能的比较
为更好了解人类在与CLIP类似的评估环境中的表现,本文评估了人类表现,希望了解人类在这些任务中的零样本性能有多强,以及如果向他们展示一两个图像样本,人类的性能会提高多少。这可以帮助比较人类和CLIP的任务难度,并识别它们之间的相关性和差异。
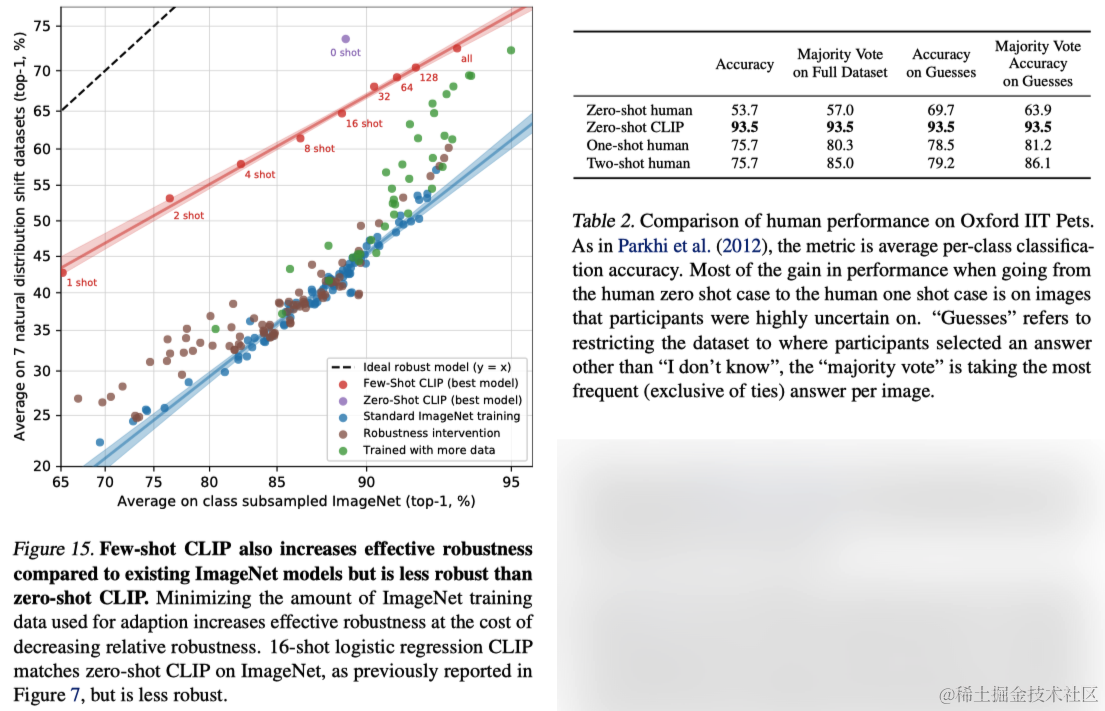
作者让五名不同的人查看了Oxford IIT Pets数据集测试集中的3669张图片,并选择哪一种猫或狗的品种最符合图片。在零样本情况下,参与者没有获得任何品种的示例,并被要求尽其所能进行标记,不得进行互联网搜索。在一和二样本实验中,参与者获得了每个品种的一个和两个样本图片。
人类在没有样本的情况下的表现平均为54%,但在每个类别仅有一个训练示例的情况下提高到了76%,而从一个样本到两个样本的边际增益很小。从零样本到一样本的准确率提高几乎完全发生在人类不确定的图像上。这表明人类“知道他们不知道什么”,并且能够根据单个示例更新他们对最不确定图像的先验。鉴于此,尽管CLIP对零样本性能是一个有前途的训练策略(图5),并且在自然分布偏移的测试中表现良好(图13),但人类从几个示例中学习与本文中的少样本方法之间存在很大差异。
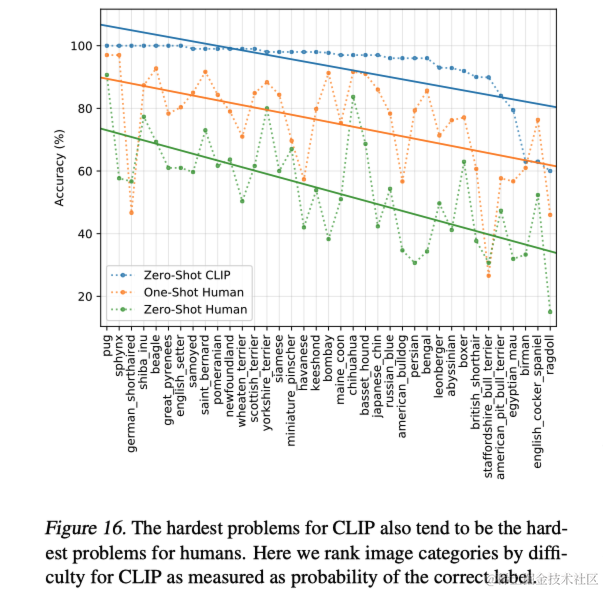
人类准确率与CLIP的零样本准确率的对比见(图16),可以看到CLIP最困难的问题对人类来说也是困难的。在错误一致的程度上,作者假设是这至少由两个因素导致的:数据集中的噪声(包括错误标记的图像)和对人类和模型来说都很难的分布外图像。
5-8 数据集重叠、影响、局限与相关工作
略
9 总结
本文探索了是否可以将自然语言处理中任务无关的网络规模预训练的成功转移到其他领域。作者发现采用这种方法在计算机视觉领域产生了类似的行为,并讨论了这一研究方向的社会影响。为了优化它们的训练目标,CLIP模型学习在预训练期间执行多种任务。然后,可以通过自然语言提示利用这种任务学习,实现对许多现有数据集的零样本转移。在足够的规模下,这种方法的表现可以与特定任务的监督模型竞争,尽管仍有很大的改进空间。
这篇关于CLIP论文笔记:Learning Transferable Visual Models From Natural Language Supervision的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








