本文主要是介绍基于GAN的小目标检测算法总结(3)——《Better to Follow, Follow to Be Better: Towards Precise Supervision ......》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于GAN的小目标检测算法总结(3)——《Better to Follow, Follow to Be Better: Towards Precise Supervision of Feature Super-Resolution》
- 1.前言
- 2.算法简介
- 2.1 核心idea
- 2.1.1 为什么使用feature-level的超分?
- 2.1.2 低分特征和高分目标特征的相对感受野匹配问题
- 2.2网络组成
- 2.2.1 base detector
- 2.2.2 SR feature generator(SR特征生成器)
- 2.2.3 SR feature discriminator(SR特征判别器)
- 2.2.4 SR target extractor(SR目标特征提取器)
- 2.2.5 small predictor
- 2.3训练过程
- 3.一点看法
1.前言
这里是基于GAN的小目标检测算法系列文章的第3篇,本文介绍2019年的ICCV论文《Better to Follow, Follow to Be Better: Towards Precise Supervision of Feature Super-Resolution》,终于到这一篇了,这篇论文在观感上比前两篇好多了,并且相比前两篇,实验结果的提升也更明显一点,虽然计算量还是有所增加,但不如前两篇增加的那么多。总之这是一篇比较值得一读的基于GAN小目标检测的论文。
由于论文名字太长,这里我把论文的方法叫做TSP,注意,目前对本文方法的简称还没有主流的叫法,只是我这里为了方便而已。
2.算法简介
2.1 核心idea
利用特征层级的超分辨率技术(super-resolution,SR,注意,这里虽然说使用了SR技术,但其实shape没有变大,具体见2.2.2节,和Perpetual GAN一样),增强小目标的特征。本文发现满足以下两个条件可以提高性能:
1>利用合适的高分目标特征作为训练SR网络的监督信号;(这不是废话吗?监督信号不合适,怎么可能训练的好SR网络?这里的合适,我认为指的是,不能用Perpetual GAN那种非直接监督的方法,也不能直接用提取低分特征的网络去提取高分特征,因为存在感受野匹配的问题)
2>输入低分辨率特征和目标高分辨率特征是一个训练对,要让这个训练对的相对感受野相匹配。
本文提出了新的用超分进行小目标检测的方法,主要贡献可以归纳为以下3点:
(1)使用feature-level的SR方法,考虑了context对检测的精度提升影响;
(2)训练SR网络时使用直接监督信号(HR目标特征),避免了间接监督导致的不稳定、超分质量低等问题。比如Perpetual GAN就是使用的间接监督;
(3)高分目标特征与低分特征的感受野匹配问题,这也是本文的最核心的贡献,2.1.2节详述这个问题。
本文的方法可以和任何proposal-based with feature pooling的算法(二阶段检测算法)结合,本文是基于Faster RCNN。
2.1.1 为什么使用feature-level的超分?
对整张图像或整个特征图进行超分计算量太大,因此Perpetual GAN是对RoI特征进行feature-level的超分,而MTGAN是对RoI图像进行image-level的超分。而MTGAN只关注RoI图像区域,没有考虑到context的影响,而context对目标检测是有用的,尤其是小目标的检测。
为了引入context信息、提高小目标检测精度,本文使用feature-level的超分(和perpetual GAN一样),因为RoI区域特征由大感受野的连续卷积计算提取得到,能够提取到一部分context信息。
此外,特征层级超分还有一个非常明显的优点:计算量小,图像层级超分后还需要对图像进行特征提取(比如MTGAN,其获得超分图像后采用ResNet50重新提取特征,然后进行检测,计算量比较大非常大),而特征层级超分后就直接获得了超分特征,不需要重新提取特征。
2.1.2 低分特征和高分目标特征的相对感受野匹配问题

一个易于想到的获得高分目标特征的方法就是:使用LR特征提取网络,在大图像上提取HR特征,然后按照gt box将RoI区域裁剪出来,作为SR网络的监督信号。但作者指出,这种HR目标特征不好,因为这样HR特征和LR特征的相对感受野不一样。
首先明确一点,使用同一个网络提取LR特征和HR特征,则特征图上一个特征点的绝对感受野大小是一样的,相对感受野是绝对感受野的大小除以图像的面积,也就是感受野覆盖面积占全图面积的百分比。很显然,低分图像小,高分图像大,那LR特征的相对感受野就比HR特征大。
为了更明确相对感受野的含义,我们举例来讲,假设LR特征的一个特征点能够覆盖低分图像上50%的面积,那HR特征的一个特征点可能只能覆盖30%的面积,30%的面积可能只能刚好覆盖一个目标,而50%能覆盖整个目标+一点context,也就是LR特征的感受野大、HR特征感受野小,这就是相对感受野不匹配的问题。
为了使得相对感受野更加匹配,需要扩大HR特征提取网络的绝对感受野,本文的方法是设计一个单独的HR目标特征提取网络,其与LR特征提取网络共享参数、降低参数量,但是把卷积层替换为空洞卷积以扩大感受野。
注意:作者好像并没有通过严格的计算,让HR特征和LR特征的感受野完全一样,只是单纯的、定性的增加HR网络的感受野,那这样可能存在感受野仍然不匹配的问题,或者HR的感受野还不够大,或者HR感受野太大了。
2.2网络组成

共5个部分:base detector(包括large predictor)、SR feature generator、SR feature discriminator、SR target extractor、small predictor,其中后4个部分是本文提出来的。
2.2.1 base detector
本文使用的是faster RCNN,不再详述。
2.2.2 SR feature generator(SR特征生成器)

上图为论文中的SR feature generator
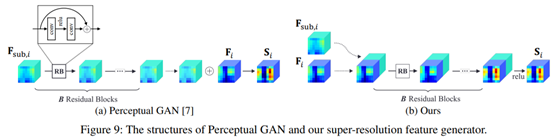
上图为Project的补充材料中的SR feature generator
SR feature generator用来对小目标的特征进行超分。
(1)网络结构
残差网络,如上面两幅图所示,很明显,没有反卷积等上采样操作,因此虽然名义上是SR网络,但输入输出的特征图的shape没有变化。
(2)损失函数
SR feature generator使用MSE损失+对抗损失+small predictor检测损失,有三个监督信号,如下:
1>SR target extractor的真实高分特征,作为直接监督信号,使用MSE损失;
2>SR feature discriminator,使得SR生成器的特征和真实高分特征分辨不出来,由此使得SR feature generator的超分特征更加真实,使用对抗损失;
3>Small predictor,检测小目标,包括分类+回归损失,使得SR feature generator的超分特征更有利于检测任务。
(3)生成器输入
2x下采样的图像输入backbone网络和RoI pooling得到小proposal特征,包括浅层的特征(分辨率高、细节信息多)和base特征两部分;
具体流程:浅层和base层经过RoI pooling后的proposals特征进行concatenate在一起,送入生成器,只取输出特征图中和base层通道对应的通道部分,作为最终的SR特征。
(4)生成器输出标签
原始图像送入SR target extractor获得输出并经过RoI pooling后,得到proposal特征(和2x下采样图像特征的相对感受野接近)。
2.2.3 SR feature discriminator(SR特征判别器)
用来区分输入是SR target extractor高分特征还是生成器的超分特征,三个全连接层,只有对抗损失。
2.2.4 SR target extractor(SR目标特征提取器)
获得SR feature generator所需的直接监督信号(HR目标特征),直接使用高分图像的HR特征图的RoI区域不合适,因为存在相对感受野匹配的问题。SR feature generator的网络结构的设计主要有两个特点:参数共享、相对感受野匹配。
(1)参数共享
SR target extractor和base detector的backbone共享相同的参数,因为对相同的输入,SR target extractor和backbone在通道维度不能产生不同的特征。对这句话不太理解,这里把原文贴下来,欢迎大家讨论并批评指正。


我认为这里和backbone共享参数原因,就是降低计算量。此外,由于和basedetector的backbone共享参数,因此SR target extractor不需要训练。
(2)相对感受野匹配
通过提高网络的绝对感受野,来提高相对感受野。
1)对池化层,增加filter的size就可以扩大感受野。
2)对卷积层,增加filter大小会增加参数,就没办法参数共享了,因此使用空洞卷积。本文使用的是空洞率为2的卷积,并且对于stride>1的卷积,比如stride=2,如果改成stride=2的、空洞率为2的空洞卷积,会对部分像素失去采样,因此使用stride=1的空洞卷积+max_pool size 2。
总结:论文中有很多地方的表述很奇怪,比如:

我的理解如下:需要设计SR target extractor,使得不管使用backbone哪一层,都要覆盖相同的感受野。但其实论文的做法只是增加网络的感受野,没有通过严格的计算让低分特征和高分特征的感受野严格一致。可能我的理解有问题,欢迎大家批评指正。
2.2.5 small predictor
small predictor,网络结构和base detector的large predictor的一样,但是只用来检测SR生成器的小proposals的超分特征。训练用检测损失。
2.3训练过程
训练分阶段进行。
(1)图像输入backbone,并进行RoI pooling,获得统一shape的proposals特征;
(2)大的proposal 的特征送入large predictor;
(3)小的proposal的特征送入SR网络进行超分,得到的超分特征送入small predictor。
3.一点看法
我个人认为,这篇论文总结了很多Perpetual GAN和MTGAN的优缺点,用feature-level的SR方法避免了MTGAN的庞大计算量,并很精准的抓住了perpetual GAN的SR网络没有直接监督信号的问题,此外还敏锐的观察到了LR特征和HR目标特征相对感受野不匹配的问题,idea很好!实验结果也比较有说服力(实验结果比perpetual GAN和MTGAN漂亮多了),算是一篇比较不错的用GAN来做小目标检测的方法,但是存在几个问题。
(1)它的baseline ResNet-50 Faster RCNN在COCO上只有29.5mAP,感觉有点低,不知道2019年的Faster RCNN有没有这么低,反正2021年的mmdetection上有37.4mAP。

(2)它的SR网络实际上没有提高特征的shape,因为送入生成器的LR特征都是经过RoI pooling统一shape的,而目标特征标签也是经过RoI pooling的。
(3)整个流程在base detector的基础上,增加了SR网络的前向传播和small predictor的前向传播,计算量还是有所增加的。
(4)是否解决了感受野匹配问题?
作者好像并没有通过严格的计算,让HR特征和LR特征的感受野完全一样,只是单纯的使用空洞卷积增加了HR网络的感受野,那这样可能存在感受野仍然不匹配的问题,或者HR特征的感受野还不够大,或者HR特征的感受野太大了。
这篇关于基于GAN的小目标检测算法总结(3)——《Better to Follow, Follow to Be Better: Towards Precise Supervision ......》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







