本文主要是介绍[深度估计]RIDERS: Radar-Infrared Depth Estimation for Robust Sensing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RIDERS: 恶劣天气及环境下鲁棒的密集深度估计
论文链接:https://arxiv.org/pdf/2402.02067.pdf
作者单位:浙江大学, 慕尼黑工业大学
代码链接:https://github.com/MMOCKING/RIDERS
1. 摘要(Abstract)
恶劣的天气条件, 包括雾霾、灰尘、雨雪和黑暗, 给准确的密集深度估计带来了巨大挑战。对于依赖于短电磁波传感器(如可见光谱相机和近红外激光雷达)的传统深度估计方法而言,在这种环境中容易受到衍射噪声和遮挡的影响。
为了从根本上解决这个问题, 作者提出了一种新颖的方法, 通过融合毫米波雷达和单目红外热成像相机实现鲁棒的度量深度估计,这两种传感器能够穿透大气颗粒, 并且不受照明条件的影响。

- 图左:所提出方法可以提供超出可见光谱的高质量深度估计
- 图右:毫米波雷达和红外热感相机的工作波长比激光雷达和RGB相机更长,可以穿透大气粒 子。
文章主要贡献:
- 1.提出第一个集成毫米波雷达和热感相机的密集深度估计方法,在烟雾和低光照等不利条件下具有无与伦比的深度感知鲁棒性。
- 2.提出一种新的度量密集深度估计框架,有效融合异质雷达和热数据。所提出的三阶段框架包括单目估计和全局对齐、准密集雷达增强和密集尺度学习,最终从稀疏和噪声长波数据中恢复密集深度。
- 3.所提方法在公开的NTU数据集和自采集的ZJU- Multispectrum数据集上SOTA
- 4.ZJU-Multispectrum数据集:包含具有挑 战性的场景,包括4D雷达,热相机,RGB相机数据 和3D激光雷达的参考深度
2. 相关工作(Related Work)
2.1. 单目红外+图像的深度
红外光谱波段对恶劣天气和光照条件表现出高水平的鲁棒性。然而,红外图像缺乏纹理信息,显得更加模糊
现有方法:
- 1.试图将可见光谱的知识转移到热深度估计任务中:[缺点:RGB图像和热图像需要密切的匹配]
- 多光谱传输网络(MTN):用来自RGB图像的色度线索进行训练的,能够从单 目热图像中进行稳定的深度预测
- Lu:使用基于cyclegan的生成器将RGB图像转换为假热图像,创建 一个用于监督视差预测的热相机立体对(An alternative of lidar in nighttime: Unsupervised depth estimation based on single thermal image)
- 2.不需要配对多光谱数据的方法:
- Shin:提出了一种不需要配对多光谱数据 的方法。他们的网络由特定模态的特征提取器和模态无关解码器。他们训练网络以实现特征级对抗适应,最小化RGB和热特征之间的差距 (Joint self-supervised learning and adversarial adaptation for monocular depth estimation from thermal image)
- ThermalMonoDepth:是一种自监督深度估计方法,无需额外的RGB参与训练。 引入时间一致的图像映射方法重组热辐射值并保证时间 一致性,最大化热图像深度估计的自监督
- 条件随机场方法:提出了一种统一的深度网络,从条件随机场方法的 角度有效地连接了单目热深度和立体热深度任务(Deep Depth Estimation From Thermal Image)
2.2. 雷达-相机融合深度
- 主要针对车辆目标,没有将所有雷达点与较大的图像区域完全关联,导致深度精度较低
- Radar-2- pixel, R2P:利用径向多普勒速度和来 自图像的诱导光流将雷达点与相应的像素区域相关联, 从而能够合成全速度信息
- R4dyn:创造性地将雷达作为弱监督信号纳入自监 督框架,并将雷达作为额外的输入以增强鲁棒性
这些方法直接对多模态输入进行编码并学习目标深度。 然而,直接编码和级联固有的模糊雷达深度和图像会混淆学习,导致估计深度出现混叠和其他不良的伪影
3. 文章主体

单目深度预测与尺度对齐
- 1.单目深度预测:在RGB图像上训练的单目深度预测模型,直接在热图像上训练
- 2.全局尺度对齐: 为了提高在前进阶段SML细化像素尺度的效率,我们使用全局缩放因子 s ^ g \hat{s}_g s^g将无尺度单目深 度预测 d ^ m \hat{\mathbf{d}}_m d^m与雷达点的深度P对齐,从而生成全局对齐深度 d ^ g a \hat{\mathbf{d}}_{ga} d^ga

准密集雷达增强
-
1.网络体系结构:本文使用了一个基于transformer的 雷达-相机数据关联网络(简称RC-Net),它可以预测雷达- 像素关联的置信度
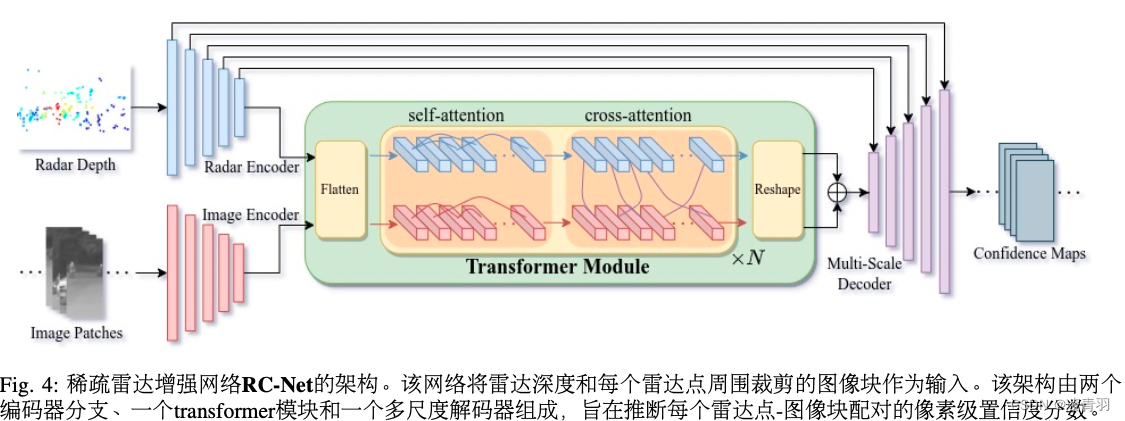
-
2.跨模态关联的置信度:对于雷达点 p i p_i pi和其投影附近裁剪的图像块 Z i ∈ R C × H × W Z_i ∈ R^{C×H×W} Zi∈RC×H×W ,我们利用RC-Net h θ h_θ hθ生成置信图 y i = h θ ( Z i , p i ) ∈ [ 0 , 1 ] H × W y^i = h_θ(Z_i,p_i) ∈ [0,1]^{H×W} yi=hθ(Zi,pi)∈[0,1]H×W,表示 Z i Z_i Zi中的像素是否对应于 p i p_i pi的概率。使用雷达点云P中的所有k点,正向传递为单个雷达点生成k置信图。因此, I ( u ∈ [ 0 , W 0 − 1 ] , v ∈ [ 0 , H 0 − 1 ] ) I(u∈[0,W_0−1],v∈[0,H_0−1]) I(u∈[0,W0−1],v∈[0,H0−1])内的每个像素 x u v x_{uv} xuv都有 n ∈ [ 0 , k ] n ∈ [0,k] n∈[0,k]相关的雷达候选点。通过选择高于阈值的置信度分数,我们可以识别像素 x u v x_{uv} xuv的潜在关联雷达点 P μ P_μ Pμ。 然后,我们通过使用其归一化置信度分数作为权重对所有 P μ P_μ Pμ深度进行加权平均来计算像素的深度 x u v x_{uv} xuv,从而产生一个准稠密深度图 d q d^q dq。

尺度学习器细化密集深度局部尺度
我们构建了一个基于MiDaS-small架构的比例尺地图学习器(SML)网 络。SML旨在为ˆzga学习一个像素级的密集比例尺地图,从而完成准密集比例尺地图并细化 z g a z_{ga} zga的度量精 度 。SML需 要连接I、 z g a z_{ga} zga和 1 / ˆ s q 1/ˆs_{q} 1/ˆsq作 为 输 入 。 s q s_q sq中的空部件被1填满。SML对密集尺度残差图r进行回归,其中值可以为负。最终的比例尺地图导出为 1 / s = R e L U ( 1 + r ) 1/s = ReLU(1 + r) 1/s=ReLU(1+r),最终的度量深度估计计算为 d = s / z g a d = s/z_{ga} d=s/zga。
4. 实验效果







这篇关于[深度估计]RIDERS: Radar-Infrared Depth Estimation for Robust Sensing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




