本文主要是介绍【论文简述】MVSFormer:Multi-View Stereo by Learning Robust Image Features and Temperature-based(TMLR 2023),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、论文简述
1. 第一作者:Chenjie Cao
2. 发表年份:2023
3. 发表期刊:TMLR
4. 关键词:MVS、3D重建、预训练、Vision Transformers
5. 探索动机:正则化并不能完全纠正来自反射或无纹理区域的模糊特征匹配,这些区域具有不可靠的2D图像特征。因此,在特征提取过程中学习良好的代表性特征,对于提高MVS的泛化程度仍具有重要意义。此前很少有工作明确探索了在额外图像数据上预训练的卷积神经网络(cnn)的特征,例如ResNet ,因为这种预训练的CNN在MVS中可能存在一些问题: 1) CNN的底层特征只考虑了有限的感受野,缺乏对图像的整体理解,无法处理反射和无纹理区域;2)CNN的高级特征具有高度的语义抽象,因此适合分类而不是细粒度的视觉特征匹配。实验也验证了预先训练的CNN模型在MVS上没有取得显著改善。
- Such regularization can not completely rectify ambiguous feature matchings from reflections or texture-less regions with unreliable 2D image features. Therefore, it is still of great significance to learn good representative features during the feature extraction to improve the generalization of MVS.
- Few previous efforts have explicitly exploring the features from the Convolutional Neural Networks (CNNs) pre-trained on extra image data, e.g., ResNet (He et al., 2016), as such pre-trained CNNs may have some problems in MVS: 1) low-level features of CNNs only consider limited receptive fields, which lack the holistic image understanding, and fail to tackle with reflections and texture-less areas; 2) high-level features of CNNs are of highly semantic abstract, thus best for the classification rather than the fine-grained visual feature matching. We empirically validate that pre-trained CNN models fail to achieve significant improvement in MVS.
6. 工作目标:是否可以通过其他的2D图像数据集的预训练Vision Transformers (ViTs)显著加强MVS的特征表示学习?优势如下:
- For the issues of reflections and texture-less regions in MVS, ViTs equipped with long-range attention modules can provide global understanding for MVS models rather than the low-level textures.
- The patch-wise feature encoding of ViTs works reasonably well for feature matching. Since the depth prediction is intrinsically a 1D feature matching problem along epipolar lines, ViTs shall be the recipe for learning-based MVS.
7. 核心思想:
- To the best of our knowledge, it is the first work that systematically explores the influence of pre-trained ViTs on MVS. Learning a better feature representation by the feature extractor is important to set up a bridge between 2D vision and 3D MVS tasks.
- We propose a novel ViT enhanced MVS network – MVSFormer, which is further trained with the efficient multi-scale training strategy to be generalized for various resolutions.
- We analyze the merits and limitations of regression and classification-based MVS, and propose a simple but effective way to unify both. Classification-based confidence can filter outliers for the real-world reconstruction. Our temperature-based depth predictions also enjoy superior point cloud metrics.
8. 实验结果:SOTA
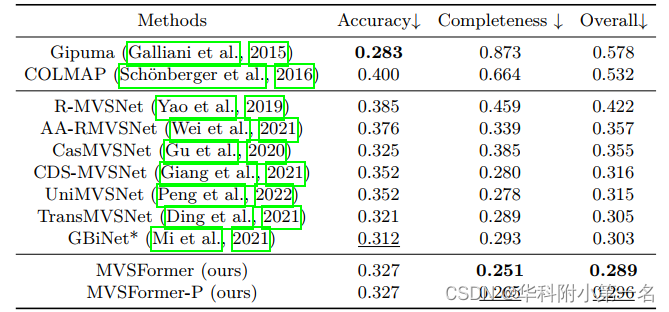
- The proposed Twins-small pre-trained MVSFormer remarkably reduces the overall error of point cloud reconstruction in DTU from 0.312 to 0.289 compared with the CNN-based pre-trained ResNet with competitive computations and all other model settings unchanged.
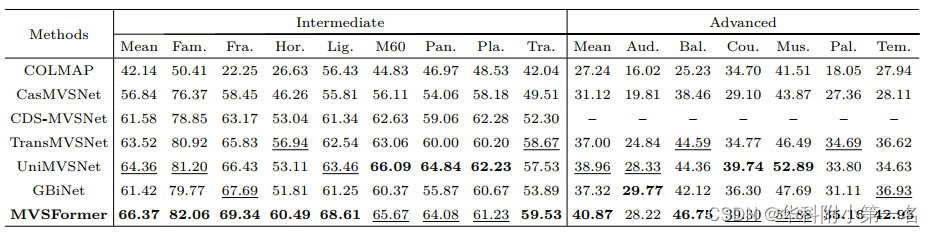
- The proposed methods can achieve the state-of-the-art performance in both DTU dataset and Tanks-and-Temples.
9.论文&代码下载:
https://arxiv.org/pdf/2208.02541.pdf
https://github.com/ewrfcas/MVSFormer
二、实现过程
1. MVSFormer概述
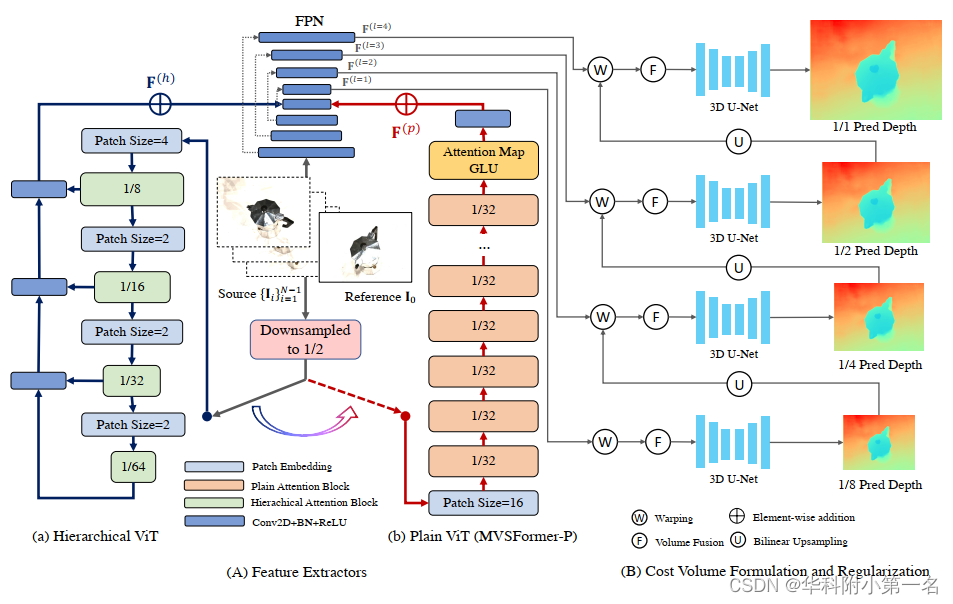
MVSFormer在特征提取中学习特征表示,并通过分层ViT - Twins(图Aa)或普通ViT - DINO(图Ab)进行增强,并采用几种新颖的训练策略,ViTs的输入下采样至1/2分辨率。然后,提出了多阶段代价体公式和正则化(图B)来计算从粗到细深度假设的概率。最后,利用交叉熵损失对MVSFormer进行优化,同时对深度期望进行推断。
预备知识:(1)Twins采用分层-ViT模型进行有监督的预训练,如图(a)所示。为了进一步降低复杂性,Twins采用可分离的局部分组自注意力和全局下采样注意力构造每个注意力块。这种全局和局部设计优于经典的金字塔ViT。(2) DINO通过plain-ViT的自蒸馏以自监督的方式进行预训练,如图(b)所示。DINO的突出特点是其最后一层的注意力映射可以学习特定于类的特征,从而实现无监督对象分割。由于无监督训练和多裁剪策略,DINO的特征表示可以很好地推广到各种环境、照明和分辨率。
2. 特征提取
使用FPN作为主要特征提取器,并使用预训练的ViT进行增强。在MVSFormer中,ViT用于制定全局特征相关性,而FPN致力于学习细节的特征相关性。将参考和源图像输入ViT之前,首先将图像下采样到(H/2, W/2)以节省计算和内存成本。接着用双三次插值调整预训练ViT的绝对位置编码的大小,以适应不同的图像尺度。然后将hierarchical-ViT输出F(h)或plain-ViT输出F(p)直接添加到FPN编码器的最高层特征。如图(A)所示,通过FPN解码器从(H/8, W/8)缩放到原始分辨率(H, W),可以得到从粗到细的特征F(l)l=4。这些特性包含来自ViT和CNN的先验,并将杠杆制定更可靠的代价体。在附录中尝试了其他特征融合策略,但差异可以忽略不计。因此在MVSFormer中采用了简单有效的特征添加方法。
具有可训练的Twins的MVSFormer。Twins作为默认的MVSFormer的主干,具有最好的重建性能。为了不同分辨率的MVSFormer中调优,ViT主干需要满足两个条件,即有效的注意力机制和不同尺度的鲁棒位置编码,Twins很好地解决了这两个问题。除了金字塔结构,Twins中CPE可以从零填充中学习位置线索,并使用适当的CNN归纳偏差打破ViTs的置换等价。如图(b), MVSFormer对4个多尺度特征{Fs}编码,分辨率为原始图像的(1/8,1/16,1/32,1/64)。使用另一个FPN对这些多尺度特征进行上采样。
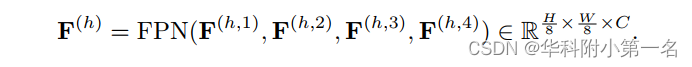
得益于高效的注意力设计,可以在各种分辨率下在训练阶段以相对较低的学习率对预训练的Twins进行微调。
具有frozen DINO的MVSFormer。还探索了基于plain-ViT和普通注意力的MVSFormer,即MVSFormer-P。因此,与常规的MVS FPN训练相比,替代的MVSFormer-P只需要更多的内存开销,并实现与完整的可训练MVSFormer可竞争的结果。
3. 高效的多尺度训练
尽管ViT很厉害,但缺少平移不变性和局部性使其很难处理各种分辨率的输入。不过,大多数MVS任务都测试不同的高分辨率(HR)(从1200×1600到1080×1920)。基于CNN的方法可以通过动态核和随机裁剪在很大程度上解决这一问题。最重要的是,CNN可以处理任意大小的输入,这得益于归纳偏差,即转移等价性和局部性。对于MVSFormer中的可训练Twins,相同分辨率的训练容易过拟合一个输入大小,无法推广到HR情况。
因此,用多尺度训练重新定义了学习特征,这些特征源于基于ViT的检测任务。特别是,为了高效的多尺度训练,必须保证1)每批图像的大小应该是相同的;2)根据图像大小动态改变批大小,目的是充分利用有限的内存。具体来说,用从512到1280的动态分辨率训练我们的模型,纵横比是从0.8到0.67的随机采样。在梯度累积的辅助下,我们保留最大批大小的多尺度训练,而不是用最小批大小来妥协。梯度积累将一个批量划分为几个子批量,并积累它们的梯度来更新模型。所有实例在每个epoch开始时随机分组到不同的分辨率和子批量大小中。请注意,较大的图像应该具有较小的子批大小,以平衡内存成本,反之亦然。用更大的批大小进行训练有助于更快地收敛,降低方差,并为BatchNorm层提供更好的性能。因此,梯度累积显著提高了MVSFormer的多尺度训练效率。我们发现,从512到1280的动态训练大小足以将MVSFormer推广到至少2K分辨率的tank and temples 数据集。
4. 相关体构建
代价体和正则化的经与本文的想法是正交的,因为本文的主要焦点是更好的MVS特征提取。代价体构建采用了分组相关体。还训练了一个2D CNN,通过标准化相关的熵来学习每个源视图的像素权重可见性。N−1个源特征相关性可以与它们的可见性相融合:

经过3D U-Net正则化后,每一阶段输出3D代价体C∈D×H×W。
5. 基于温度的深度预测
回归深度Dreg和分类深度Dcla:
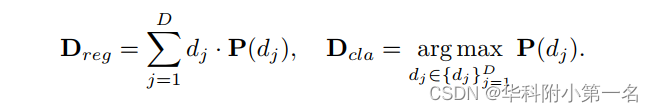
Dreg用L1损失和真实深度优化,Dcla用具有one-hot真实深度体的交叉熵(CE)优化。
REGs存在过拟合问题,导致深度预测模糊,而CLA更鲁棒,但无法实现准确的深度结果。相比之下,经验发现了一个不同的结论:来自CLA的置信度图优于REGs;这一点不应被忽视,特别是对于广泛使用的多级MVS模型。特别是,由于反射、遮挡或缺少可靠的源视图,MVS网络不能确保所有预测的深度图都是正确的。因此,提供可靠的置信度(不确定性)深度图对于MVS重建的良好点云也很重要。如图(a)所示,在阶段-2,3,4中,即使超出范围深度假设,REGs也保持高置信值。REGs很难在不损害其他正确深度点的情况下过滤异常值。由于CE不能处理超出范围的深度标签,因此在训练中掩盖所有深度异常值。作者还尝试了优化带有mask的L1损失的MVS,但其性能不如常规回归。
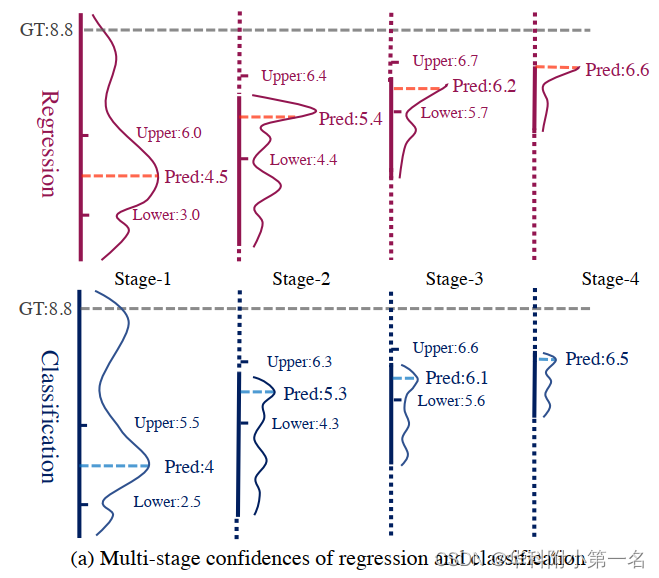
回归分类的多阶段置信度。在阶段1中,基于回归和基于分类的方法的深度范围都遗漏了真实深度(8.8)。回归仍然为深度上限提供了高概率。
虽然CLA在MVS中具有许多良好的性能,但在早期的实验中,REGs在深度和点云方面的性能优于CLAs。因此,我们针对不准确的深度预测。统一焦点损失(UFL)将CE视为多重二元交叉熵(BCE)。focal loss采用若干超参数控制解决BCE中的不平衡问题。不同于UFL,本文提出了一种简单的方法来统一REGs和CLAs,它只调整推理过程,而不需要重新训练模型。本文首先在softmax之前将代价体C乘以temperature t,并将D reg重写为temperature-based的深度期望Dtmp为
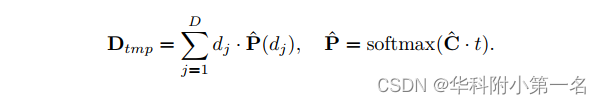
显然,当t =∞或t = 1时,Dtmp分别等价于Dcla或Dreg。其核心思想是在推理过程中调整t以统一REGs和CLAs。对于低分辨率的早期阶段,设置更大的t,使模型作为CLA工作,以获得更好的全局分辨能力。对于高分辨率的后期阶段,我们的模型倾向于使用较低的t作为REG来平滑局部细节。在实践中,我们设{t1, t2, t3, t4} ={5, 2.5, 1.5, 1},并获得比分类(t =∞)、回归(t = 1)和其他t设置更好的性能。注意Dtmp只在测试期间使用,因为用CE优化的屏蔽CLA对于MVS学习来说足够鲁棒。因此,MVSFormer在训练阶段采用Dcla。尽管在测试过程中调整t可能会受到训练阶段和测试阶段之间差异的影响,但只是倾向于在后面的阶段回归,只有深度附近的一些假设。而且t设置对于各种数据集都具有足够的广泛性和有效性。
6. 实验
6.1. 数据集
DTU,Tanks-and-Temples,ETH3D
5.2. 实现细节
MVSFormer通过32-16-8-4深度假设的4个粗到细阶段的视图数N = 5来训练。对于多尺度训练,根据512到1280的尺度,动态地将8个子批改为2个子批,最大批大小为8。由于混合精度,MVSFormer在DTU和BlendedMVS中训练10个epoch分别只需要大约22和15个小时,使用两个V100 32GB Tesla GPUs。
6.1. 与先进技术的比较
SOTA

这篇关于【论文简述】MVSFormer:Multi-View Stereo by Learning Robust Image Features and Temperature-based(TMLR 2023)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






