本文主要是介绍Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[Paper] Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021)
[Code]saic-mdal/lama
基于傅里叶卷积的分辨率稳健的大型掩码修复

现在的图像修复系统,尽管取得了重大进展,但经常与大面积缺失区域、复杂几何结构和高分辨率图像做斗争。我们发现造成这种情况的主要原因之一是修复网络和损失函数都缺乏有效的感受野。
为缓解这个问题,我们提出了一种称为大蒙版修复(LaMa)的新方法。LaMa基于:1)新的修复网络结构,该网络结构使用快速傅里叶卷积,具有图像范围的感受野;2)高感受野感知损失;3)大型训练掩码,它释放了前两个组件的潜力。我们的修复网络改进了一系列数据集的最新技术,即使在具有挑战性的场景中也能实现出色的性能,例如,完成周期性结构。我们的模型非常好地推广到比训练时看到的分辨率更高的分辨率,并以此竞争基线更低的参数和计算成本实现这一目标。
概述
图像修复问题的解决方案——真实填充缺失部分——既需要“理解”自然图像的大规模结构,也需要进行图像合成。该主题在前深度学习时代 [1, 5, 13] 进行了研究,近年来通过使用深度和宽神经网络 [26, 30, 25] 和对抗性学习 [34, 18, 56、44、57、32、54、61]。
通常的做法是在自动生成的大型数据集上训练修复系统,该数据集是通过随机屏蔽真实图像创建的。复杂的两阶段方法曾经是一种常见的做法,通常涉及中间预测(例如平滑图像 [27、54、61]、边缘 [32、48] 和分割图 [44])。在这项工作中,我们使用最简单的单级网络实现了最先进的结果。
大的有效感受野 [29] 对于理解图像的全局结构并因此解决修复问题至关重要。此外,在大掩码的情况下,即使大但有限的感受野可能不足以访问生成质量修复所需的信息。我们注意到流行的卷积架构可能缺乏足够大的有效感受野。我们仔细干预系统的每一个组件,以缓解问题并释放单阶段解决方案的潜力。具体来说:
1)我们提出了一种基于最近开发的快速傅立叶卷积 [4] 的修复网络。快速傅立叶卷积允许覆盖整个图像的图像范围的感受野,即使在网络的早期层也是如此。我们表明网络受益于感受野的快速增长,实现了更高的质量和参数效率。有趣的是,快速傅立叶卷积中的归纳偏差允许网络推广到训练期间从未见过的高分辨率(图 5、图 6)。这一发现带来了显着的实际好处,因为需要更少的训练数据和计算。
2)我们建议使用基于具有高感受野的语义分割网络的感知损失 [20]。这依赖于以下观察:感受野的缺乏不仅会影响修复网络,还会影响感知损失。损失促进了全局结构和形状的一致性。
3)我们引入了一种极简的训练掩码生成策略,以释放前两个组件的高感受野的潜力。该过程产生宽大的掩码,迫使网络充分利用模型的高感受野和损失函数。
这将我们引向大型掩码修复(LaMa)——一种新颖的单阶段图像修复系统。LaMa的主要组成部分是高感受野架构(1),具有高感受野损失函数(2),以及训练掩码生成的激进算法(3)。我们精心将LaMa与最先进的基线进行比较,并分析每个提议组件的影响。通过评估,我们法向LaMa仅在低分辨率数据上训练后可以推广到高分辨率图像。LaMa可以捕获并生成复杂的周期性结构,并且对大型掩码具有鲁棒性。此外,与竞争基线相比,这是通过显着减少可训练参数和计算成本来实现的。
方法
我们的目标是修复被未知像素 m m m 的二进制掩码掩蔽的彩色图像 x x x,掩蔽图像表示为 x ⨀ m x \bigodot m x⨀m。掩码 m m m与掩码图像 x ⨀ m x \bigodot m x⨀m堆叠,产生一个四通道输入张量$x’=stack( x ⨀ m x \bigodot m x⨀m, m)$。我们使用前馈修复网络 f θ ( ⋅ ) f_θ(·) fθ(⋅),我们也将其称为生成器。取 x ′ x' x′ ,修复网络以全卷积方式处理输入,并生成修复后的三通道彩色图像 x ^ = f θ ( x ′ ) \hat x = f_θ(x') x^=fθ(x′) 。训练是在从真实图像和合成生成的掩码中获得的(图像、掩码)对的数据集上进行的。
早期层中的全局上下文
在具有挑战性的情况下,例如填充大型蒙版,生成适当的修复需要考虑全局背景。因此,我们认为一个好的架构应该尽可能早的在管道中具有尽可能广泛的感受野的单元。传统的全卷积模型,例如 ResNet [14],有效感受野增长缓慢[29]。由于卷积核通常很小(例如 3 × 3),感受野可能不足,尤其是在网络的早期层。因此,网络中的许多层将缺乏全局上下文,并且会浪费计算和参数来创建一个。对于宽掩模,特定位置的生成器的整个感受野可能在掩模内部,因此仅观察丢失的像素。对于高分辨率图像,这个问题变得尤为突出。
快速傅立叶卷积(Fourier convolutions)[4] 是最近提出的允许在早期层中使用全局上下文的方法。傅立叶卷积层基于通道快速傅立叶变换 (FFT) [2],并具有覆盖整个图像的图像范围的感受野。傅立叶卷积层将通道分成两个并行分支:1) 局部分支使用传统卷积,以及 2) 全局分支使用真实 FFT 来考虑全局上下文。实数 FFT 只能应用于实数信号,逆实数 FFT 可确保输出为实数。具体来说,快速傅立叶卷积层采取以下步骤来考虑全局结构:

最后,本地 (1) 和全局 (2) 分支的输出融合在一起。傅立叶卷积的图示在图 2 中可用。
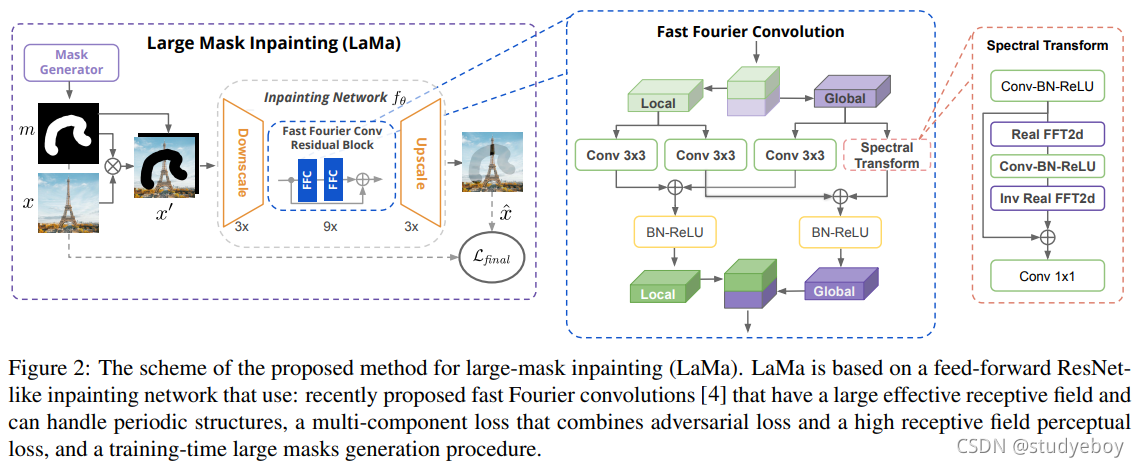
傅立叶卷积的威力 傅立叶卷积是完全可微的,是传统卷积的易于使用的替代品。由于覆盖整个图像的图像范围的感受野,傅立叶卷积允许生成器网络从早期层开始考虑全局上下文,这对于高分辨率图像修复至关重要。这也带来了更高的效率:可训练的参数可用于推理和生成,而不是“等待”信息的缓慢传播。
傅立叶卷积的另一个好处是能够捕捉在人造环境中非常常见的周期性结构,例如 砖、梯子、窗户等(图 4)。有趣的是,在所有频率上共享相同的卷积会使模型朝着尺度协方差方向移动 [4](图 5、6)。
损失函数
修复问题本质上是模棱两可的。对于相同的缺失区域,可能有许多合理的填充物,尤其是当“孔”变宽时。我们将讨论提议损失的组成部分,它们一起可以处理问题的复杂性。
高感受野感知损失
朴素的监督损失要求生成器精确地重建地面实况输入。然而,掩膜外的图像部分通常不包含用于精确重建孔内部分的足够信息。因此,由于对修复内容的多种似是而非的模式进行平均,使用朴素的监督会导致模糊的结果。相比之下,感知损失 [20] 评估通过基础预训练网络 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 从预测图像和目标图像中提取的特征之间的距离。它不需要精确的重建,允许重建图像的变化。大掩码修复的重点转向理解全局结构。因此,我们认为使用感受野快速增长的基础网络是很重要的。我们介绍了使用高感受野基础模型 ϕ H R F ( ⋅ ) \phi_{HRF}(\cdot) ϕHRF(⋅)的高感受野感知损失 (HRF PL):
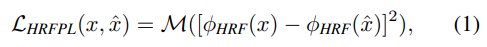
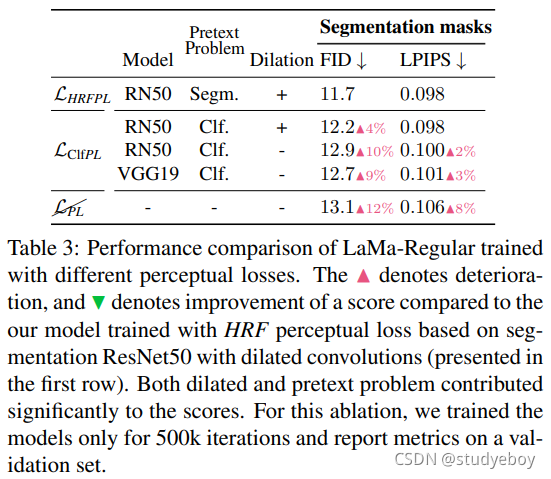
其中 [ ⋅ − ⋅ ] 2 [· - ·] ^2 [⋅−⋅]2 是逐元素操作, M M M 是连续的两阶段平均操作(层内均值的层间均值)。可以使用傅立叶或扩张卷积实现 ϕ H R F ( x ) \phi_{HRF}(x) ϕHRF(x)。如消融研究(表 3)所示,HRF 感知损失似乎是我们的大蒙版修复系统的关键组成部分。
借口问题训练感知损失的基础网络的借口问题很重要。例如,使用分割模型作为感知损失的主干可能有助于关注高级信息,例如 对象及其部分。相反,已知分类模型更多地关注纹理 [10],这会引入对高级信息有害的偏差。
对抗性损失
我们使用对抗性损失来确保修复模型 f θ ( x ′ ) f_θ(x' ) fθ(x′) 生成看起来自然的局部细节。我们定义了一个在局部补丁级别 [19] 上工作的鉴别器 D ξ ( ⋅ ) Dξ(·) Dξ(⋅),区分“真实”和“假”补丁。只有与蒙版区域相交的补丁才会获得“假”标签。由于受监督的 HRF 感知损失,生成器快速学习复制输入图像的已知部分,因此我们将生成图像的已知部分标记为“真实”。最后,我们使用非饱和对抗性损失:

最终的损失函数
在最终的损失中,我们还使用 R 1 = E x ∣ ∣ ∇ D ξ ( x ) ∣ ∣ 2 R_1 = E_x||∇Dξ(x)||^2 R1=Ex∣∣∇Dξ(x)∣∣2 梯度惩罚 [31, 38, 7],以及基于判别器的感知损失或所谓的特征匹配损失——感知损失 鉴别器网络 L D i s c P L L_{DiscPL} LDiscPL [45] 的特征。众所周知, L D i s c P L L_{DiscPL} LDiscPL 可以稳定训练,并且在某些情况下会略微提高性能。
我们修复系统的最终损失函数
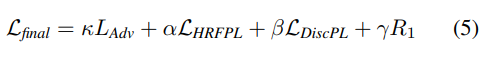
是所讨论的损失的加权和,其中 L A d v L_{Adv} LAdv 和 L D i s c P L L_{DiscPL} LDiscPL 负责生成自然外观的局部细节,而 L H R F P L L_{HRFPL} LHRFPL 负责监督信号和全局结构的一致性。
训练期间生成掩码
我们系统的最后一个组件是掩码生成策略。每个训练示例 x ′ x' x′ 都是来自训练数据集的真实照片,叠加了合成生成的掩码。与数据增强对最终性能有很大影响的判别模型类似,我们发现掩码生成策略显著影响修复系统的性能。
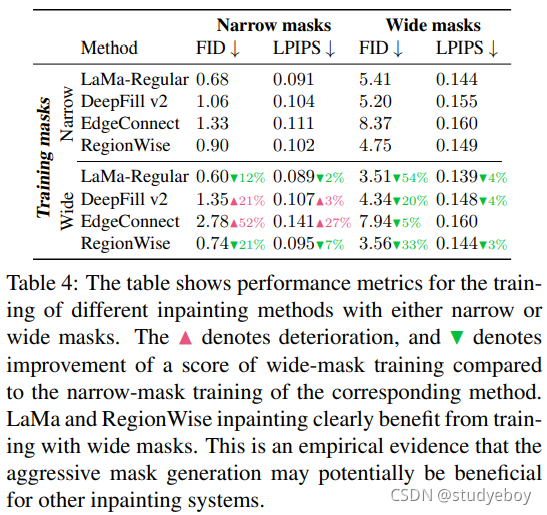
因此,我们选择使用积极的大型掩码生成策略。该策略统一使用来自由高随机宽度(宽掩码)和任意纵横比(框掩码)扩展的多边形链的样本。我们的掩码示例如图3所示。
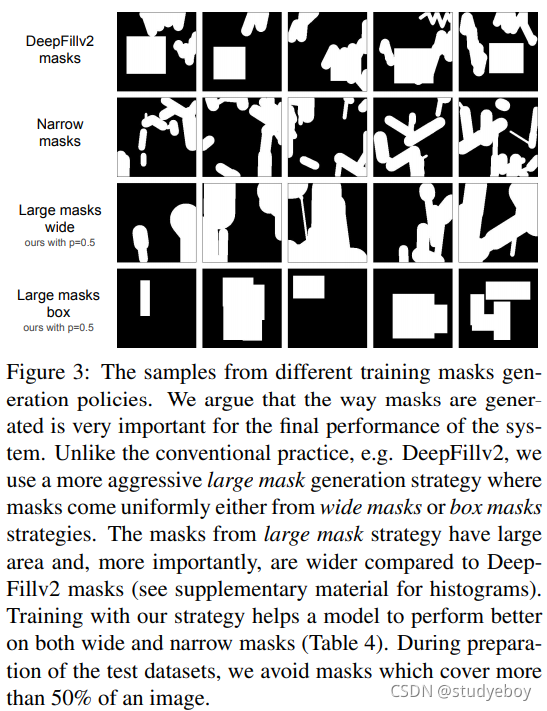
我们针对几种方法测试了大型掩码训练与窄掩码训练的对比,发现使用大型掩码策略进行训练通常会提高窄掩码和宽掩码的性能(表 4)。这表明增加掩码的多样性可能对各种修复系统有益。采样算法在补充材料中提供。
实验
在本节中,我们证明了所提出的技术在标准低分辨率下优于一系列强基线,并且在修补更宽的孔时差异更加明显。然后我们进行消融研究,展示了快速傅立叶卷积、高感受野感知损失和大掩码的重要性。令人惊讶的是,该模型可以推广到从未见过的高分辨率,同时与大多数有竞争力的基线相比,其参数要少得多。
实现细节 对于 LaMa 修复网络,我们使用类似 ResNet 的 [14] 架构,其中包含 3 个下采样块、6-18 个残差块和 3 个上采样块。在我们的模型中,残差块使用快速傅立叶卷积。补充材料中提供了有关鉴别器架构的更多细节。我们使用 Adam [23] 优化器,修复和鉴别器网络的固定学习率分别为 0.001 和 0.0001。除非另有说明,否则所有模型都经过 100 万次迭代训练,批量大小为 30。在所有实验中,我们使用坐标方向的波束搜索策略选择超参数。该方案导致权重值 κ = 10 , α = 30 , β = 100 , γ = 0.001 κ = 10, α = 30, β = 100, γ = 0.001 κ=10,α=30,β=100,γ=0.001。我们将这些超参数用于所有模型的训练,但损失消融研究中描述的模型除外(如第 3.2 节所示)。在所有情况下,超参数搜索都是在单独的验证子集上执行的。补充材料中提供了有关数据集拆分的更多信息。
数据和指标我们使用 Places [66] 和 CelebAHQ [21] 数据集。我们遵循最近 image2image 文献中的既定做法,并使用学习的感知图像块相似性 (LPIPS) [63] 和 Frechet 初始距离 (FID) [15] 度量。与像素级 L1 和 L2 距离相比,LPIPS 和 FID 更适合在多个自然完成似乎合理时测量大型蒙版修复的性能。实验管道是使用 PyTorch [33]、PyTorchLightning [9] 和 Hydra [49] 实现的。
与基线的比较
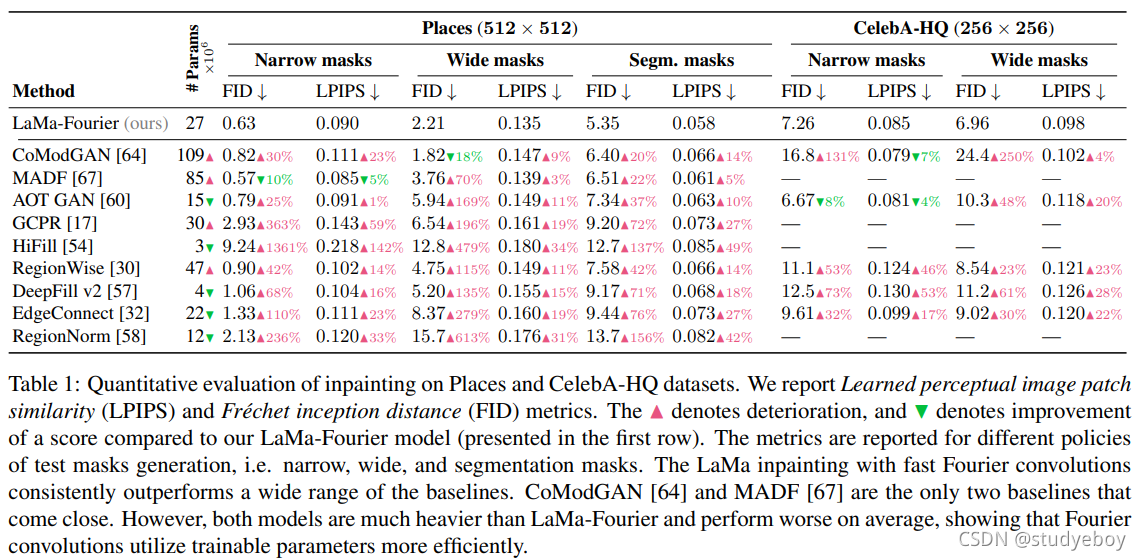
我们将所提出的方法与表 1 中列出的许多强基线进行了比较。仅使用公开可用的预训练模型来计算这些指标。对于每个数据集,我们验证了窄、宽和基于分段的掩码的性能。LaMa 使用快速傅立叶卷积进行修复始终优于大多数基线,同时参数数量少于最强大的竞争对手。仅有的两个竞争基线 CoModGAN [64] 和 MADF [67] 使用 ≈ 4 倍和 ≈ 3 倍以上的参数。对于宽掩码,差异尤其明显。
用户研究 为了减轻所选指标可能存在的偏差,我们进行了一项众包用户研究。用户研究的结果与定量评估密切相关,并表明与其他方法相比,我们的方法产生的修复更可取且不易检测。用户研究的协议和结果在补充材料中提供。
消融研究
该研究的目标是深入了解该方法的不同组成部分的影响。在本节中,我们展示了 Places 数据集的结果; CelebA 数据集的附加结果可在补充材料中找到。
f θ ( ⋅ ) f_θ(·) fθ(⋅) 的感受野 快速傅立叶卷积增加了我们系统的有效感受野。添加快速傅立叶卷积显着提高了宽掩码中修复的 FID 分数(表 2)。当模型应用于比训练时更高的分辨率时,感受野的重要性最为明显。如图 5 所示,在没有傅立叶卷积的情况下,当分辨率增加到超出训练时使用的分辨率时,模型会产生明显的伪影。定量验证了相同的效果(图 6)。傅立叶卷积还可以更好地生成重复结构,例如窗口(图 4)。有趣的是,LaMa-Fourier 仅比 LaMa-Regular 慢 20%,小 40%。
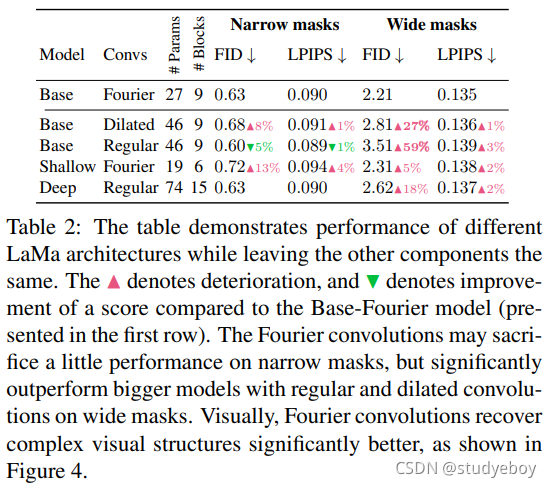


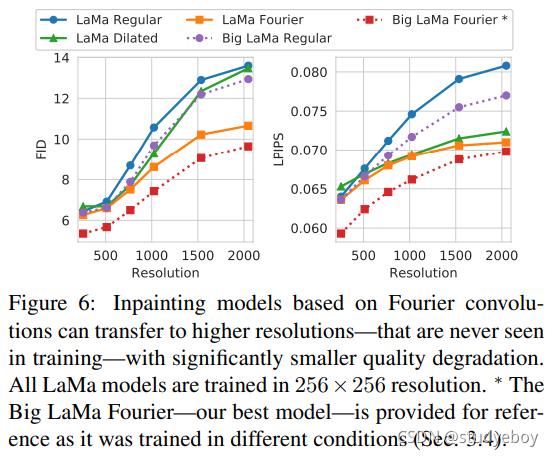
扩张卷积 [55, 3] 是允许感受野更快增长的替代选项。与傅立叶类似,扩张卷积也提高了我们的修复系统的性能。这进一步支持了我们关于图像修复的有效感受野快速增长的重要性的假设。然而,扩张卷积具有更严格的感受野,并且严重依赖于尺度,导致对更高分辨率的泛化能力较差(图 6)。扩张卷积在大多数框架中被广泛实现,当资源有限时,可以作为傅立叶卷积的实际替代品,例如 在移动设备上。我们在补充材料中提供了有关 LaMa-Dilated 架构的更多详细信息。
损失 我们验证了感知损失的高感受野设计——用扩张卷积实现——确实提高了修复的质量(表 3)。对于损失的每个变体,我们搜索权重系数以确保公平评估。除了使用膨胀层之外的设计选择似乎很重要。在我们的例子中,与分类网络相比,分割网络似乎是更好的感知损失基础模型。
掩码生成 更宽的训练掩码改善了 LaMa(我们的)和 RegionWise [30](表 4)的宽孔和窄孔的修复。然而,更宽的掩码可能会使结果更糟,DeepFill v2 [57] 和 EdgeConnect [32] 在窄掩码上就是这种情况。我们假设这种差异是由特定的设计选择(例如生成器的高感受野或损失函数)引起的,这些选择使方法或多或少适合同时修复窄和宽掩码。
推广到更高分辨率
直接以高分辨率进行训练速度慢且计算成本高。尽管如此,大多数现实世界的图像编辑场景都需要模型在高分辨率数据上运行良好。因此,我们在更大的图像上评估我们的模型,这些模型是使用来自 512 × 512 图像的 256 × 256 裁剪进行训练的。我们以完全卷积的方式应用模型,即在没有任何补丁操作的情况下单次处理完整图像。
傅立叶卷积可以比常规卷积更好地转移到更高的分辨率(图 6)。我们假设傅立叶卷积在不同的尺度上更加稳健,因为 1) 高全图像感受野,2) 在尺度变化后保留频谱的低频,3) 频率中 1×1 卷积的固有尺度协方差领域。虽然所有模型都相当好地泛化到 512 × 512 分辨率,但与所有其他模型相比,启用傅立叶的模型在 1536 × 1536 分辨率下保持了更高的质量和一致性(图 5)。我们要注意的是,与竞争基线相比,傅立叶卷积以明显更低的参数成本实现了这一点。
预告模型:Big LaMa
为了验证我们的方法对真实高分辨率图像的可扩展性和适用性,我们训练了一个具有更多资源的大型修复 Big LaMa 模型。Big LaMa 与我们的标准模型在三个方面不同:生成器网络的深度; 训练数据集; 和批次的大小。它有 18 个残差块,全部基于快速傅立叶卷积,产生 51M 个参数。该模型是在来自 Places-Challenge 数据集 [66] 的 450 万张图像的子集上训练的。正如我们的标准基本模型一样,Big LaMa只在大约 512×512 图像的低分辨率 256×256 作物上进行训练。Big LaMa 使用更大的批次大小 120(而不是标准模型的 30)。虽然我们认为这个模型相对较大,但它仍然比一些基线小。它在八个 NVidia V100 GPU 上进行了大约 240 小时的训练。Big LaMa 模型的修复示例如图 1 和图 5 所示。
相关工作
图像修复的早期数据驱动方法依赖于基于补丁的 [5] 和基于最近邻的 [13] 生成。深度学习的进步使得数据驱动的图像修复方法变得更加流行。因此,[34] 是最早使用卷积神经网络的作品之一,该网络具有以对抗方式训练的编码器-解码器架构 [11]。迄今为止,这种方法仍然普遍用于深度修复。完成网络的另一组流行选择是基于 U-Net [37] 的架构,例如 [26, 50, 59, 27]。一个常见的问题是网络掌握本地和全局环境的能力。为此,[18] 提议结合扩张卷积 [55] 来扩大感受野; 此外,两个鉴别器应该分别鼓励全局和局部一致性。在[46]中,建议在具有不同感受野的完成网络中使用分支。为了从空间遥远的补丁中借用信息,[56] 提出了上下文注意层。[28, 47, 65] 中提出了替代注意力机制。我们的研究证实了在远程位置之间有效传播信息的重要性。我们方法的一种变体也严重依赖于扩张的卷积块,正如最近在 [41] 中为匹配任务提出的那样。作为更好的替代方案,我们提出了一种基于频域变换(快速傅立叶卷积)的不同机制,最近在 [4] 中为识别任务提出了这种机制。这也符合最近在计算机视觉中使用 Transformers 的趋势 [6, 8] 并将傅立叶变换视为自我注意 [24, 35] 的轻量级替代品。在更全局的层面上,[56] 引入了一个从粗到细的框架,它涉及两个网络。在他们的方法中,第一个网络在孔洞中完成粗略的全局结构,而第二个网络然后使用它作为指导来细化局部细节。这种遵循相对古老的结构-纹理分解思想的两阶段方法 [1] 在随后的工作中变得普遍。一些研究 [40, 42] 修改了框架,以便并行而不是顺序获得粗略和精细的结果组件。一些工作提出了使用其他结构类型的完成作为中间步骤的两阶段方法:[32] 中的显着边缘,[44] 中的语义分割图,[48] 中的前景对象轮廓,[52] 中的梯度图,以及 [36] 中保留边缘的平滑图像。另一个趋势是渐进式方法 [62, 12, 25, 61]。与所有这些最近的工作相比,我们的研究有效地提倡使用更简单的单级系统。我们表明,通过适当的设计选择,单阶段方法会产生非常好的结果。
为了处理不规则的掩码,一些作品使用了修改的卷积层,如部分 [26]、门控 [57]、轻量级门控 [54] 和区域 [30] 卷积。其他工作考虑了生成用于训练修复网络的掩码,包括随机孔 [18]、自由形式的笔触 [57] 和对象形状的掩码 [54、61]。我们发现,只要训练掩码的轮廓足够多样化,掩码生成的确切方式并不像掩码的宽度那么重要。
提出了许多损失来训练修复网络。通常,使用像素级(例如 l 1 l1 l1、 l 2 l2 l2)和对抗性损失。一些方法将空间折扣加权策略应用于像素损失 [34, 53, 56]。使用简单的卷积鉴别器 [34, 52] 或 PatchGAN 鉴别器 [18, 59, 36, 28] 来实现对抗性损失。其他流行的选择是使用梯度惩罚判别器 [56, 54] 和谱归一化判别器 [32, 57, 27, 61] 的 Wasserstein 对抗性损失。继之前的工作 [31, 22] 之后,我们在我们的系统中使用了 r1-gradient 惩罚补丁鉴别器。感知损失也很常见,通常使用 VGG-16 [26, 47, 25, 27] 或 VGG-19 [51, 43, 32, 52] 主干在 ImageNet 分类 [39] 上进行预训练。与这些作品相比,我们发现这种感知损失对于图像修复来说是次优的,并提出了一个更好的预训练网络来提取感知特征。此外,修复框架通常包含样式 [26, 30, 30, 47, 32, 25] 和特征匹配 [51, 44, 32, 16] 损失。后者也在我们的系统中使用。
讨论
在这项研究中,我们研究了使用简单的单阶段架构进行大掩模修复。我们已经证明,在适当选择框架、损失函数和掩码生成策略的情况下,这种单阶段修复方法非常具有竞争力,可以推动图像修复的最新发展。所提出的方法在生成重复的视觉结构方面可以说是很好的(图 1、4),这似乎是许多修复方法的问题。然而,当涉及强烈的透视扭曲时,LaMa通常会挣扎(见补充材料)。我们要注意的是,对于来自 Internet 的不属于数据集的复杂图像,通常就是这种情况。傅立叶卷积是否可以解释周期信号的这些变形仍然是一个问题。 有趣的是,傅立叶卷积层允许该方法推广到从未见过的高分辨率,并且与最先进的基线相比,参数效率更高。傅立叶或扩张卷积不是接收高感受野的唯一选择。例如,使用视觉转换器 [6] 可以获得高感受野,这也是未来研究的一个令人兴奋的话题。我们相信具有大感受野的模型将为开发高效的高分辨率计算机视觉模型开辟新的机遇。
这篇关于Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[SWPUCTF 2021 新生赛]web方向(一到六题) 解题思路,实操解析,解题软件使用,解题方法教程](https://i-blog.csdnimg.cn/direct/bcfaab8e5a68426b8abfa71b5124a20d.png)

![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)


