convolutions专题

【图像分割】DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation
DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation 论文链接:http://arxiv.org/abs/2406.03702 代码链接:https://github.com/takaniwa/DSNet 一、摘要 重新审视了现代卷积神经网络(CNNs)中的atrous卷积的设计,并证明了使用大内核

CNN初探(三)------Going Deeper with Convolutions
Hebbian principle(赫布理论) Cells that fire together, wire together 描述突触可塑性的原理, 即突触前神经元向突触后神经元的持续重复的刺激可以导致突触传递效能的增加。 简述信息 GoogLeNet相较于2012年Krizhevsky提出的网络结构,减少到了1/12的参数,并且更加精确。对于大多数实验,模型被设计为在推断时间保持1.5
Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
本文的目的是输入一个image pair 然后得到他们的匹配 内存消耗大,推理时间长,对应关系局部性差。我们提出的修改可以减少10倍以上的内存占用和执行时间,并且效果相当。这是通过对包含试探性匹配的相关张量进行稀疏化,然后使用子流形稀疏卷积对其进行4D CNN后续处理来实现的。通过以更高的分辨率处理输入图像(这是可能的,因为减少了内存占用),以及通过一个新的两级对应重定位模块,定位精度显著

Iterative Visual Reasoning Beyond Convolutions代码运行
代码地址:https://github.com/endernewton/iter-reason 论文:Iterative Visual Reasoning Beyond Convolutions 注意:作者公布的源码里面没有全局推理模块这个有点坑。所以我只是在我的环境下把代码调通了然后并没有继续训练下去。 环境:python3.5+tensorflow1.10+cuda9.0 遇到的问题:g
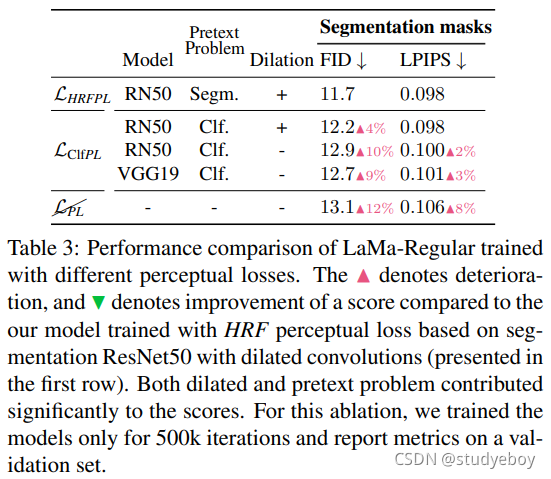
Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021)
[Paper] Resolution-robust Large Mask Inpainting with Fourier Convolutions(2021) [Code]saic-mdal/lama 基于傅里叶卷积的分辨率稳健的大型掩码修复 现在的图像修复系统,尽管取得了重大进展,但经常与大面积缺失区域、复杂几何结构和高分辨率图像做斗争。我们发现造成这种情况的主要原因之一是修复网络和损失函

Padding\Valid convolutions\Same convolutions
整理并翻译自吴恩达深度学习系列视频:卷积神经网络1.4。 Padding 在对一张6X6图片进行卷积后,它变成了一张4X4的图片。直接卷积有以下2个缺点: Shrinking the output(缩小输出图像大小)Throw away info from edge(相对于中间经过多次卷积计算的部分,图像边缘信息被抛弃了) 为了解决这一点问题,我们可以在图像的边缘填充(paddin
论文学习笔记(四)ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
『写在前面』 2018上半年出品的语义分割轻量级网络。 论文出处:ECCV 2018 作者机构:Sachin Mehta等,University of Washington 原文链接:https://arxiv.org/abs/1803.06815v2 相关repo:https://github.com/sacmehta/ESPNet 目录 摘要 1 介绍 2 相关工作 关于卷

轻量化网络(四)Xception: Deep Learning with Depthwise Separable Convolutions
论文链接 Pytorch实现 Tensorflow实现 Xception是2017年由Keras作者和谷歌著名人工智能专家Francois Chollet提出,是在 Inception modules 进行改进。Xception和Inception V3相比,网络参数并没有增加,只是更加合理得使用了参数导致了性能的提升。 一、The Inception hypothesis 在Figure 1中

文献阅读:Long-Term Temporal Convolutions(LTC)for Action Recognition
文献阅读:Long-Term Temporal Convolutions(LTC)for Action Recognition IEEE Transactions on Pattern Analysis and Machine Intelligence 2018 task 动作识别,Action recognition, video analysis, representation lear

SCNet论文详解:Improving Convolutional Networks with Self-calibrated Convolutions
《Improving Convolutional Networks with Self-calibrated Convolutions》是2020年CVPR的论文,作者来自于南开大学程明明团队。最近各种卷积注意力组合的模块工作层出不穷,性能涨点明显,包括之前的Res2Net、李沐团队的ResNeSt,应该是近期的热点方向。 论文地址:http://mftp.mmcheng.net/Papers/
CVPR2020 Improving Convolutional Networks with Self-Calibrated Convolutions论文详解 SC-Net 注意力机制
论文:http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf 代码:https://github.com/MCG-NKU/SCNet 《Improving Convolutional Networks with Self-calibrated Convolutions》 CVPR2020 南开大学程明明团队(将多尺度引入Resnet中的Res2Net)

Improving Convolutional Networks with Self-Calibrated Convolutions 自卷积模块
在2020 cvpr 上面我又看到一篇挺好的文章,这里分享给大家。这个文章是Improving Convolutional Networks with Self-Calibrated Convolutions。这是一个即插即用的一个模块,挺好的。这个模块主要是用来增大网络的感受野的。另外这个模块也可以不需要增加太多的参数就可以获得这个效果。整体还是比较有效的。 整篇 论文 的核心大概就是这幅
![论文阅读——CondConv: Conditionally Parameterized Convolutions for Efficient Inference[2019-NIPS]](https://img-blog.csdnimg.cn/6bac894cb64344ba9a1ca6bae27b10bc.png)
论文阅读——CondConv: Conditionally Parameterized Convolutions for Efficient Inference[2019-NIPS]
原文及代码链接:CondConv: Conditionally Parameterized Convolutions for Efficient Inference | Papers With Code 条件参数化卷积(CondConv),其实质就是将每个样本的卷积核用一组卷积核的线性组合来代替。权重α由r(x)得到,主要包括全局平均池化、全连接层、Sigmoid激活函数三个操作。 在测试过