本文主要是介绍Temporally Identity-Aware SSD with Attentional LSTM 论文学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多目标跟踪常用的是tracking by detection,这种方法就是将每帧中所有感兴趣的目标物体均检测出来,然后与前一帧检测出来的目标进行关联,从而实现跟踪效果。这种方法的前提就是要拥有一种表现好的目标检测算法还有好的关联方法。
具体流程是:
step1:使用目标检测算法将每帧中感兴趣的目标检测出来,得到对应的(坐标,分类,可信度),假设检测出来的目标个数为M
step2:通过某种方式将step1中的检测结果与上一帧的检测目标(假设目标个数为N)一一关联起来(也就是在M*N的pair中找出最相似的pair)
目标关联方式:
①两帧的两个目标间的欧氏距离(最短则认为是同一个目标),通过匈牙利算法找出最匹配的pair;
②计算两个目标bbox的交并比,越接近于1代表是同一个目标;
③判断目标外观是否相似
关联中可能出现的情况:
①上一帧中N个目标中找到本次检测的目标;
②上一帧的N个目标中未找到本次检测的目标,该目标是新出现的,需要记录下来用于下一次跟踪关联;
③上一帧中存在某个目标,这一帧中没有与之关联的目标,说明该目标可能消失了,需将其移除。
可想而知,这种简单的位置对比关联方式针对目标运动速度太快的情况不适用,容易误判,因此提出基于轨迹预测的跟踪方式,在对比之前,先预测目标的下一帧会出现的位置。也就是说,用下一帧预测的位置和实际检测出来的位置进行对比关联。那么怎么预测目标在下一帧的位置呢?一种是用卡尔曼滤波来预测位置,一种是用根据前几帧拟合出来的曲线预测位置。
匈牙利算法:
匈牙利算法的百度百科定义是:基于Hall定理中充分性证明的思想,部图匹配的最常见算法。????不懂,其实它的核心就是寻找增广路径,求二分图最大匹配的算法。那么二分图又是什么?它可以分成两组点,同一组内的点不能相互连通,只能与另一组点相连。对于视频帧的话这些点相当于图中的目标,连起来的目标就是认为同一目标可能性较大,但是通常这样的结果不能保证每张图都有一对一匹配,可能存在多对一的情况。
那如何保证最终的一对一跟踪结果?正是匈牙利算法要做的事:左边的图依次按照连线匹配右边的图,当右边的目标已经被匹配,将与右边的图匹配的左边的图重新匹配,最后若左边存在图没有匹配对象则放弃匹配。
一些概念:
tubelet:视频目标检测中的边框被称为tubelet,tubelet是一系列候选边框的集合。视频目标检测算法使用tubelet来获得时间上的信息。但是,tubelet的产生一般是基于对每一帧的检测结果,过程非常耗时,产生每一帧中的每一个检测边框都需要0.5s,而一个视频通常有上百帧,每一帧又有上百个检测边框,所以无法在一个可以接受的时间范围内产生足够的候选tubelet。
SSD目标跟踪:SSD目标跟踪是在Yolo上的改进,和Yolo一样属于one-stage方法的一种,和Yolo相比,SSD将最后的全连层换为卷积层,SSD利用了多尺度特征图,是在原图上进行密集型采样的方法。在特征图上的每个单元生成多个先验框(不同长宽比),对于每个先验框,SSD的输出有两个:一个边界框的位置、所属各个类别的置信度或者评分(置信度个数包含背景和类),最后先验框的类别由最高置信度值决定,然后真实的预测框位置由先验框和边界框共同决定。由于一个位置有多个先验框,每个先验框对应一个边界框,因此,一帧图片会生成多个边界框,所以称为密集型采样。
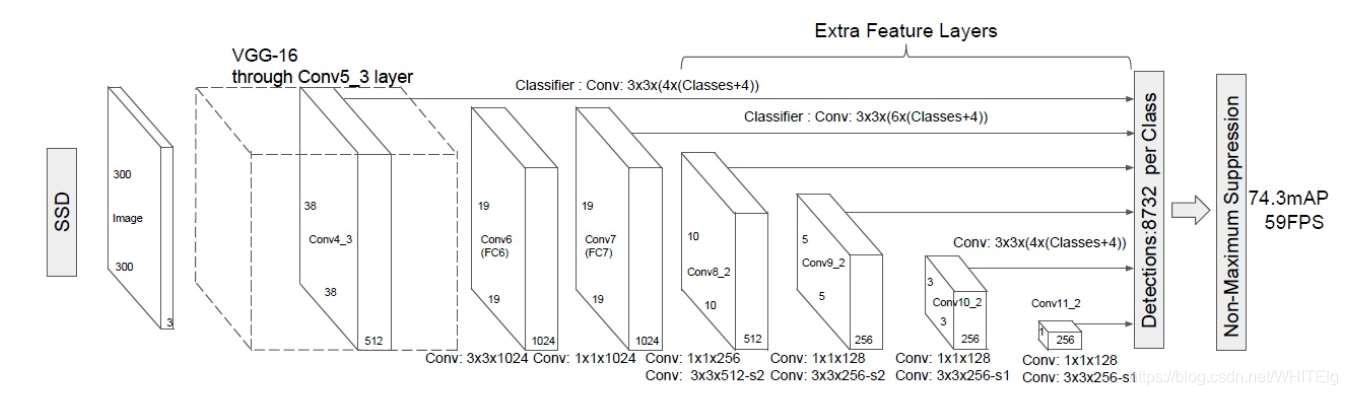
网络共提取了6个特征图 ,但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加。
检测值包含两个部分:类别置信度和边界框位置,各采用一次3*3卷积来进行完成。令n为该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为n*c ,而边界框位置需要的卷积核数量为n*4
如下图是一个5*5特征图的检测过程:

ground truth与先验框的匹配原则:
原则一:对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。但这样的结果使得匹配到的先验框(该先验框对应的预测框称为正样本)的数量远小于未匹配到的先验框(该先验框对应预测框称为负样本)的数量。
原则二:对于剩余的未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配(注意:一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框交并比大于阈值,那么先验框只与IOU最大的那个ground truth进行匹配。
一般原则二在原则一后执行。
SSD误差函数:
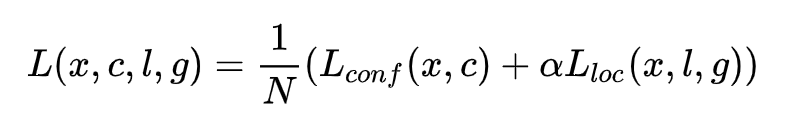
其中:N为正样本数目


预测过程:
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
文章!
Temporally Identity-Aware SSD with Attentional LSTM,18年的文章,文章链接:https://arxiv.org/abs/1803.00197,针对当前目标检测和视频追踪越来越紧密联系起来,试图用目标跟踪的方法解决视频追踪,用到的是SSD方法(目标检测中的two-stage方法,如R-CNN系算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,two-stage方法的优势是准确度高;one-stage方法,如Yolo和SSD,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快),大致的是使用TSSD+OTA实现视频目标的检测和识别。其中在TSSD中用到HL-TU和attention-convLSTM,将多尺度特征利用起来进行整合。HL-TU将SSD的六个尺度特征按通道数和金字塔层级分成两组,分别是low-level和high-level,这两组特征分别对应两个时间单元,也就是分别对应AC-LSTM。
下图显示的是模型两个部分的跟踪效果
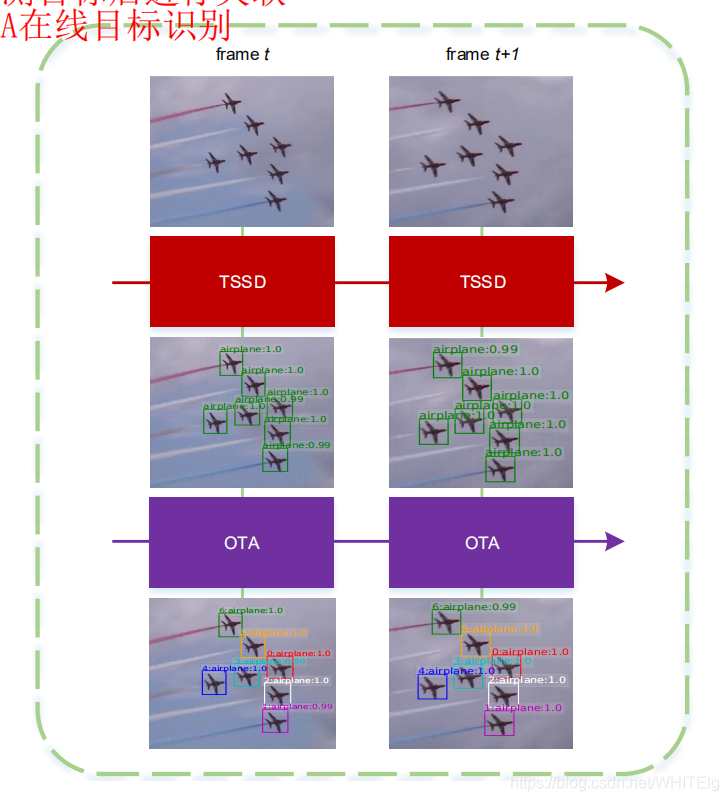
也就是:TSSD用来检测目标,OTA用来识别目标
较详细的模型如下图:
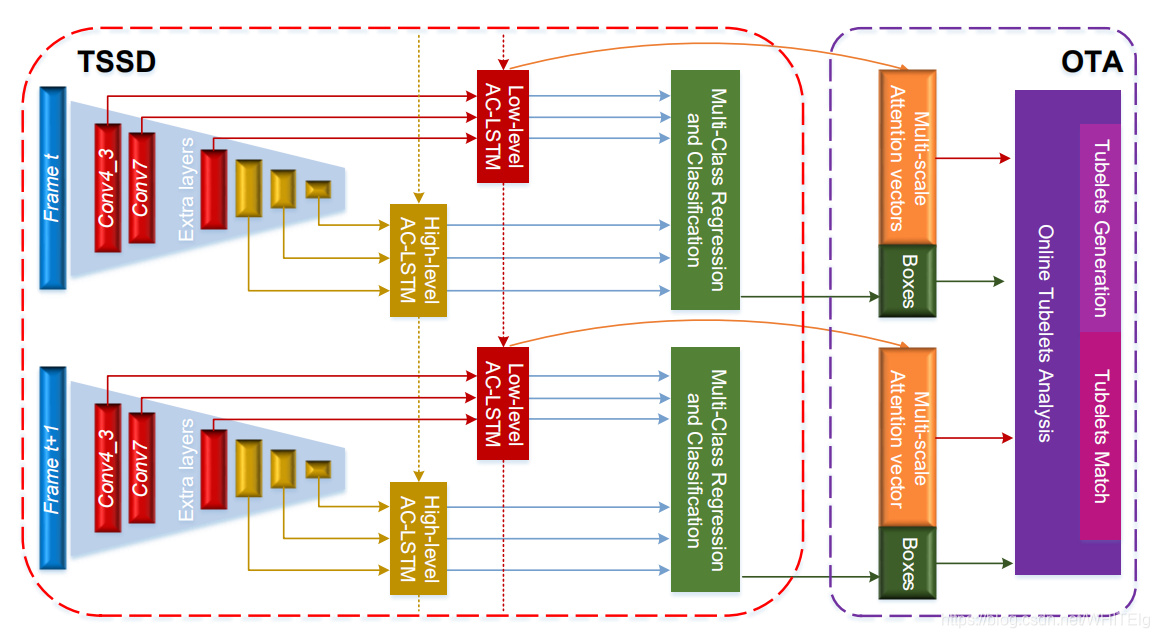
TSSD模块
为什么要引进attention机制呢?当ConvLSTM处理背景或小规模多尺度特征映射时,效率很低。例如,如果一个对象太小,它的检测将由Conv4 3提供,其中与小对象相关的特性远远小于背景。此外,所有的高层次特征图都可以被认为是无用的,应该加以抑制,以避免假阳性。因此attention机制是用来将输入到卷积LSTM的某尺度的feature map与一个三层卷积得到的attention map作用,将对目标有用的feature map 提取出来。以低层时间单元为例,AC-LSTM内部结构如下图:
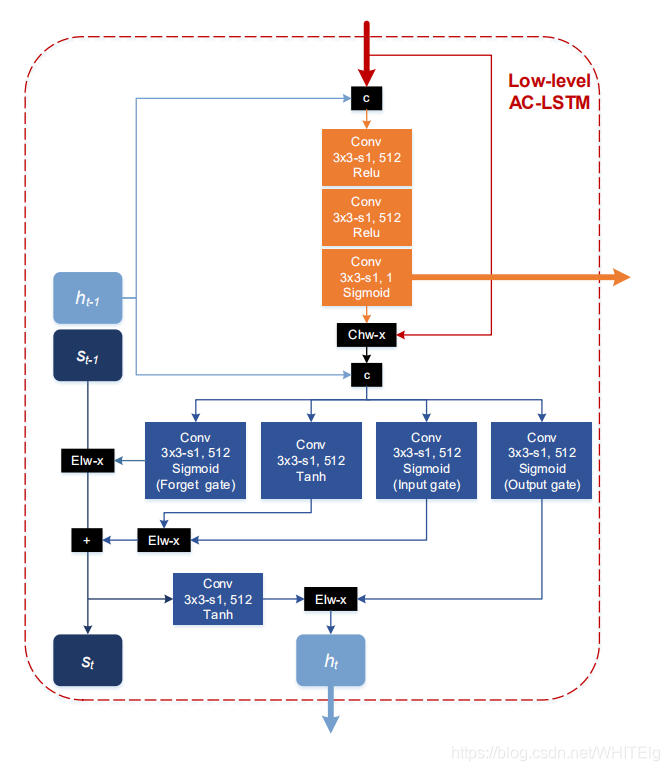
注:C表示连接;Chw-x表示通道乘法;Elw-x表示元素乘法
attention机制的输入是:输入某个尺寸的feature map、上一时刻的短时记忆,当前feature map的每个通道与该attention map逐像素相乘,得到attention-aware feature。然后attention-aware feature作为卷积LSTM的输入,LSTM公式没有改变,仅是将权重与输入的操作换成卷积操作,也就是将权重矩阵当成卷积核。总之,AC-LSTM的作用是背景抑制和尺寸抑制
在TSSD内部存在两次时间信息传输:
①时间注意力模型为conv-LSTM挑选关注目标特征的输入;
②conv-LSTM提供给注意力模型以时间信息来提高关注准确性
有一点需要注意:attention模块和输入门扮演不同的角色,尽管它们都可以知道有用的特性。在背景抑制和尺度抑制方面,attention模块对每个二维map的空间位置进行处理,而输入门可以对通道沿线的三维特征进行处理,以保存有区别的数据。我觉得大概意思就是说输入门不能起到抑制作用,只能将输入和记忆单元不一样的数据保存下来。
OTA模块
OTA利用的是:孪生网络将两个目标映射到一个度量空间,其中映射的特征总是对每个目标有区别的。检测器中的特征不适合识别,因为它们总是包含类内相似的信息。但在框架中有一种独立于类别的特性,即,注意力图。注意力图并没有区分每个类,而是在不同的视觉尺度上描述了对象的突出度。从而创造性地利用注意空间作为度量指标,实现快速数据关联。
在attention机制中,关键的是,物体的突出度彼此不同,而注意力机制能够捕捉到这种微妙的区别。因此,将TSSD模块中经上采样后的attention map展开成147维的attention向量,通过计算两个向量之间的余弦距离作为相似度度量。(余弦距离,也为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量)计算公式如下:
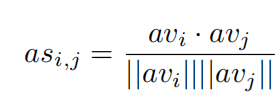
视频中的识别可以利用更多的时间一致性,所以也在OTA中使用IoU ,由于在tubelet中含有多个目标,因此tubelets中的
tub与目标obj(这里的obj指的是这一帧的检测结果)的相似性S(相似性用作计算目标是否存在匹配id)可以由下式计算:
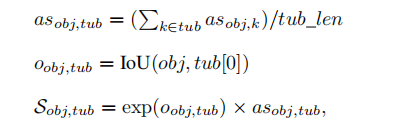 (7)
(7)
其中tub[0]表示一类目标中的最近目标。定义,
分别表示tubelet生成分数(检测器的置信度阈值)和匹配阈值。假设每个检测到的对象被描述为obj[conf,loc, av],并且每个不同类的tubelets集合表示为tubs(cls),提供每个tubelet为tub(id、obj)。OTA算法在算法1中,这里
表示一个对象识别id, id = -1表示未生成匹配标识(背景),len(·)计算元素的数量。

将未生成匹配id的目标置信度值与tubelet生成分数比较大小,若置信度值较大,则为该目标匹配一个新的id。模型结果如下图:检测结果表示为“ID:class:score”

模型损失函数
模型的损失由四部分组成:定位损失localization loss, 置信度损失confifidence loss , 注意力损失attention loss和关联损失association loss。其中定位损失和置信度损失的定义通常根据SSD算法构造。
①对于注意力损失attention loss:使用交叉熵函数,先构造一个ground truth attention map,在这个map中,在ground truth
框的位置元素为1,其余地方元素为0。对于多预测框图像,生成六个尺寸的特征图,分别生成六个尺寸的attention map。将六个attention map都双线性上采样到原图像大小,这样就可以求他们和ground truth attention map的损失了,公式如下:
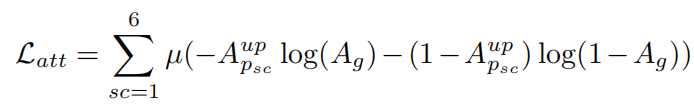
②对于关联损失association loss:首先计算NMS后的每个类别的最高k个预测分数,然后将它们相加,生成一个类别判别分数表(sl)。在连续的几帧中,分数列表应该保持较小的波动。
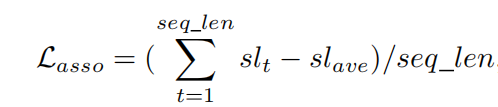
其中:sl_t表示t时刻的类别分数表,sl_ave表示所有时刻类别分数表的均值。
训练
网络使用的SSD模型是已经训练好的模型,在已经训练好的SSD模型基础上训练TSSD模型,训练时仅仅分类和回归参数可以改变,其余参数不变。
这篇关于Temporally Identity-Aware SSD with Attentional LSTM 论文学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






