本文主要是介绍《论文阅读》Deep Online Correction for Monocular Visual Odometry,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
留个笔记自用
Deep Online Correction for Monocular Visual Odometry
做什么
Monocular Visual Odometry单目视觉里程计
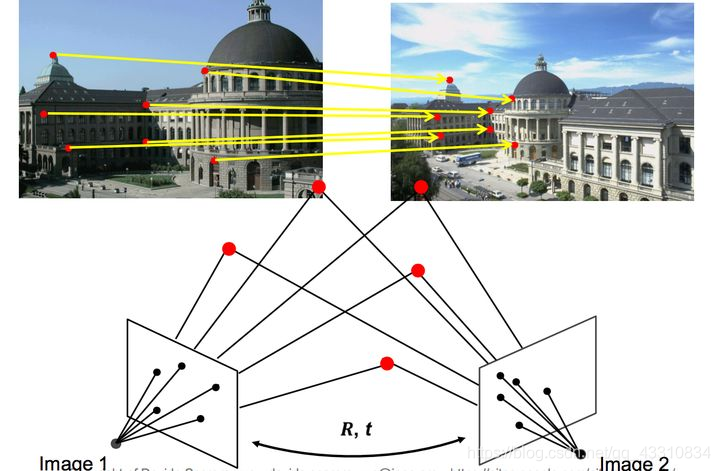
相机在运动过程中连续两帧之间会存在overlap,即会同时观测到三维世界中的某些场景以及特征点。而这些场景特征点会投射到2D图片上,通过图片的对齐或者特征的匹配,可以找到前后图片上特点或patch的对应关系。利用相机的成像几何模型(包括相机参数)以及约束,可以求出两帧之间的运动信息(旋转矩阵R和平移t)。这样我们就可以得到一系列的相机相对变化矩阵,从而可以推出相机的姿态信息。
做了什么

DOC完全依赖深度学习框架,但是不同于在线学习不需要计算神经网络参数的梯度传播,并且能效果较好地实现深度校正
怎么做

DOC框架的核心思想是通过基于梯度传播最小化光度误差来直接优化相对姿态,不依赖传统框架,只需要计算6自由度姿态的梯度就可以,也就是图上的位姿转换Tii-1也就是第i-1帧到第i帧的位姿转换。
整体框架分为是哪个部分,Depth-CNN深度部分、Pose-CNN位姿部分、Warp校正部分
首先是Depth-CNN部分和Pose-CNN部分

这里的Depth-CNN和Pose-CNN用的是相似的结构,用的都是Unet类似的结构,前者是endoer-decoder形状的,后者则是encoder后接Linear
Depth-CNN以单帧RGB图像作为输入,输出深度图,Pose-CNN以两帧连续图像作为输入,输出位姿转换
这里说借鉴的方法是Monodepth2,一个点云深度估计网络,也是估计深度和位姿的
至此得到了初始的深度图和位姿转换,接下来就是优化,就是文章的题目Deep Online Correction(DOC深度在线校正框架),也就是框架的第三部分
第三部分warp校正部分提供了两种情况可选,两帧优化和三帧优化

首先是两帧优化情况
给定两帧图像Ii-1和Ii,通过前面两个部分能得到各自的深度图Di-1和Di,还有两者的位姿转换Tii-1,DOC接下来通过最小化总光度误差来优化
定义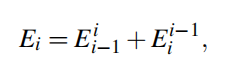
这里EI表示第i步的光度误差,Ei-1i和Eii-1的意思分别是前向误差和反向误差,也就是i-1帧到i帧的误差和i帧到i-1帧的误差,然后定义两个误差为
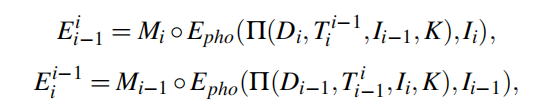
两个的构造方式比较相似
这里的Π是一个函数,作用是warp,它输入深度图D,位姿转换T,图像帧I,相机固有属性K,以这些合成一个新的视图I’’
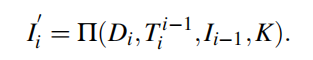
这里说这个函数在经典论文《Spatial Transformer Networks》中有用到过,但其实我并没有找到
然后是EPHO
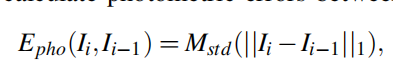
这里的意思就是根据两张图像得到它们的光度误差,跟前面的总光度误差不一样,这里是分至于向前和向后的图像间的光度误差,I就是图片帧
然后是定义Mstd
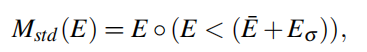
这里的含义就是一个离群点剥离器,E-是平均,Eσ是标准差,两者都是针对E的,代入前面也就是两个图像,前面的做法是将两张图直接相减,这里的意思就是在差度图上所有点求一个平均和标准差,去掉一些不合理的利群点
回到最开始的式子
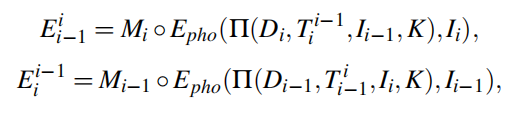
至此得到了 ◦符号后面的所有结果
然后是前面的M,这里就是一个mask的作用,是由两种mask组成的,一个是occlusion mask遮挡Mo,一个是explainability mask解释Me,大M是由这两个M直接相乘得到,也就是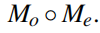
首先是遮挡Mask
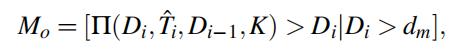
这里又用到了前面的那个函数Π,也就是得到一张新的视图,区别是后面的图像帧输入也换成了上一帧的深度图,这里意思就是用这种阈值D的方式去除一些不合理的遮挡情况
然后是解释Mask,这里没给出公式,但有提到是通过CNN也就是前面的那俩部分得到的
最后总结一下这两个mask的作用

遮挡Mask在图一和图二中有展示,能较好的去掉由遮挡产生的两个明显同一个的交通棒,然后是解释性误差,这些能减少屋顶和植被这种高频光度误差
至此得到了前后误差,也就是第i帧的光度误差,有了这个误差就可以用优化器去进行优化了
然后是第二种情况,三帧优化情况
也就是输入是前中后三帧图像作为输入,这里也是一样设计了一个总能量误差
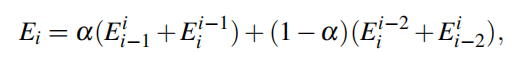
显然这里的设计方式跟前面两帧的前后光度误差是类似的

这就是整个DOC框架的过程了,整体输入是图片序列I,希望输出是优化位姿T,第一步就是通过前两个部分Pose-CNN和Depth-CNN得到深度D和初始位姿转换T,然后开始进行一个优化工作,通过函数Π将I-1图像帧转换到i帧上,计算一个向前光度误差,然后反过来计算一个向后光度误差,相加得到总误差后用Adam去进行前面初始位姿的优化

总结
1.不仅是用自监督的方式训练网络,而且构造的这个在线校正模块不更新网络参数,仅做位姿优化,这个会更高效
2.整体来说这种初始化再优化的思路可以参考,并且可以在warp部分做改进,达到一种循环迭代的效果
这篇关于《论文阅读》Deep Online Correction for Monocular Visual Odometry的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









