online专题
![[LeetCode] 901. Online Stock Span](/front/images/it_default.gif)
[LeetCode] 901. Online Stock Span
题:https://leetcode.com/problems/online-stock-span/ 题目大意 不断给出元素,求当前元素开始往前的最大子串,且串中每个元素的值都小于等于 该元素。 思路 class stockPair{int price;int day;public stockPair(int price,int day){this.price = price;this.d

HDU 5444 Elven Postman (2015 ACM/ICPC Asia Regional Changchun Online)
【题目链接】:click here~~ 【题目大意】: HDU 5444 题意:在最初为空的二叉树中不断的插入n个数。对于每个数,从根节点开始判断,如果当前节点为空,就插入当前节点,如果当前节点不为空,则小于当前节点的值,插入右子树,否则插入左子树。 接着q次询问,每次询问一个值在二叉树中从根节点开始的查找路径。 3 直接用二叉树模拟整个插入和询问的过程 代码:
Coder-Strike 2014 - Finals (online edition, Div. 1) C. Bug in Code
水题一道,但是卡了一个早上 我本着数据结构去做的,知道用树状数组就是没有想出来维护的方法.... 用树状数组维护,提名 i 次的人有getsum个 注意一点的是,如果怀疑的人是 1 2,然后有一个人是同时提名这两个的,那么这个人就会被算两次 因此我每次用树状数组统计的时候,将同时和第i个人提名的各个人数减1,再统计,然后再恢复(这是一种很麻烦的做法,我是渣渣别介意 #include
Bubble Cup 8 - Finals [Online Mirror] - A.Fibonotci【分段+ST表】
因为 si s_i为近似周期序列,而且告诉你了 m m个位置以及数字。 那么就将序列分成mm段,每一段用一个ST表来维护区间矩阵乘积 然后注意一些细节,比如 m <script type="math/tex" id="MathJax-Element-259">m</script>段分段如果两个不周期位置连续,以及最后一个段等等。 想法还是比价明显的,但是确实不好写…. #include<
codeforces-Coder-Strike 2014 - Finals (online edition, Div. 2)
A. Pasha and Hamsters 模拟 #include <stdio.h>#include <string.h>int l1[101];int l2[101];int main(){memset(l1,0,sizeof (l1));memset(l2,0,sizeof (l2));int n,a,b,i,t;scanf ("%d%d%d",&n,&a,&b);for (i =

Exchange Online P1 AO Sub Add-on to User Exchange Std 部署方案建议
目录 引言 一、Exchange Online P1、AO Sub Add-on 与 Exchange Standard 简介 1.1 Exchange Online P1 1.2 AO Sub Add-on 1.3 Exchange Standard 二、Exchange Online P1 AO Sub Add-on 的主要功能 2.1 高级安全性 2.2 增强的合规性

Deep Sort目标跟踪论文梗概SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC
DeepSort是跟踪算法中非常好用的一个,速度快,准度高。 本文为CVPR2017的跟踪算法。 论文:https://arxiv.org/pdf/1703.07402.pdf 代码:https://github.com/nwojke/deep_sort 摘要 简单在线和实时跟踪Simple Online and Realtime Tracking (SORT)是一种注重简单、高效的多目标跟踪
Aeron:Online Resources
Aeron Wiki 是一个极好的资源,由 Aeron 团队随时更新。 一、Conference Videos Martin Thomson introducing Aeron, Strange Loop, 2014 https://youtu.be/tM4YskS94b0 Todd Montgomery discussing the next steps for Aeron, Go
多个android设备online时,命令行窗口通过adb连接指定设备方法
1. 通过adb devices命令获取所有online设备的serial number。 C:\Users\Administrator>adb devices List of devices attached emulator-5554 device SH0A6PL00243 device 上面表示,当前有两个设备online,第一个emulator-5554是模拟器,后一个
2015 ACM/ICPC Asia Regional Shenyang Online
题目在这里 Shenyang Online1001 Traversal1002 Best Solver1003 Minimum Cut1004 Dividing This Product1005 Excited Database1006 Fang Fang简单题1007 Matches Puzzle Game1008 Hold Your Hand1009 Stability1010 Jesus
2015 ACM/ICPC Asia Regional Changchun Online
弱菜目前只做了9个,5个签到题。题目链接 Changchun Online 1001 Alisha’s Party 简单题,优先队列搞搞就行了。 1002 Ponds 简单题 1003 Aggregated Counting 感觉有点绕的题目,把连续出现相同次数的数字看成一段,最多50w段,然后预处理一下前缀和。 1004 Clock Adjusting 待补 1005 Travel 离线并查集
IndiaHacks 2016 - Online Edition (Div. 1 + Div. 2) E. Bear and Forgotten Tree 2 bfs set 反图的生成树 快速连通块
老规矩,抄一波QSC,自己的写在后面 E. Bear and Forgotten Tree 2 题目连接: http://www.codeforces.com/contest/653/problem/E Description A tree is a connected undirected graph consisting of n vertices and n - 1 edges.

Training Region-based Object Detectors with Online Hard Example Mining(CVPR2016 Oral)
转载自:http://zhangliliang.com/2016/04/13/paper-note-ohem/ Training Region-based Object Detectors with Online Hard Example Mining是CMU实验室和rbg大神合作的paper,cvpr16的oral,来源见这里:http://arxiv.org/pdf/1604.03540
[LeetCode] Online Judge-开始我的编程小训练
最近刷知乎的缘故,当时发现了一个提升编程思路的网站LeetCode。然而我是过了两个星期后才真正的点进去了解。。。允许我再次膜拜一下知乎里面的大婶们,因为在大学里的四年没做过Online Judge里面的题目,对Online Judge的了解少之甚少(除了ACM)。 根据这几天对LeetCode的了解,总结一下: 1、注册后才可以在线测试; 2、部分题目是不需要缴费的; 3、提供多种编程技
HDU 5014 Number Sequence(2014 ACM/ICPC Asia Regional Xi'an Online) 题解
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5014 Number Sequence Problem Description There is a special number sequence which has n+1 integers. For each number in sequence, we have two ru

O2O:Offline–Online Actor–Critic
IEEE TAI 2024 paper 加权TD3_BC Method 离线阶段,算法基于TD3_BC,同时加上基于Q函数的权重函数,一定程度上避免了过估计 J o f f l i n e ( θ ) = E ( s , a ) ∼ B [ ζ Q ϕ ( s , π θ ( s ) ) ] − ∥ π θ ( s ) − a ∥ 2 \begin{aligned}J_{\mathrm{of
hdu 5025 Saving Tang Monk[状态压缩bfs]( 2014 ACM/ICPC Asia Regional Guangzhou Online)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5025 比赛的时候自己也在写这个。。但是,最后没有写出来。。不是自己写不出来。。只是,当时,思路已经很是混乱了。。表示心情很是糟糕。。其他队也已经a了。也没有心情写了。。很显然,自己比赛时的心态有待改观。。特别是正式的比赛中,心情应该比较平静。。。 题目意思: 孙悟空要救唐三藏,每杀一个蛇需要额外+
Hdu 5038 Grade(2014 ACM/ICPC Asia Regional Beijing Online 1007)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5038 题目的意思, 给你公式,求出每个蘑菇的grade,求这些grade的众数。。Mode,众数,表示英语又被鄙视了。 表示,自己很弱,不知道众数的定义。。。 百度之。。。 一般来说,一组数据中,出现次数最多的数就叫这组数据的众数。 例如:1,2,3,3,4的众数是3。
Hdu 5015 233 Matrix[矩阵](2014 ACM/ICPC Asia Regional Xi'an Online )
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5015 题目的意思是: n*m的矩阵 n<= 10, m <= 10^9。。求第n行m列的元素。。 第0行第0个元素为空的,第一个位233,第二个2333,23333,23333......等等。 第0列第一个为a1,第二个为a2,第三个为a3.......等等。。 然后就需要计算出个矩阵的第
Hud 5024 Wang Xifeng's Little Plot(2014 ACM/ICPC Asia Regional Guangzhou Online)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5024 题目的意思就是 :找只能拐一个90度的弯的最长路。。直接模拟就好。。 记得网赛的时候,对这个题的题意还是比较有争议的。。。 贴下最主要的题意:if there was a turn, that turn must be ninety degree. 如果有弯,那必须是90度的弯。。这一点

ArcGIS Online试用 (2)
一、时态数据介绍 时态数据是表示某个时间点的状态的数据,如 1990 年香港的土地利用模式或 2009 年 7 月 1 日檀香山的总降雨量。通过收集时态数据可分析天气模式和其他环境变量、监视交通状况、研究人口统计趋势等等。可从许多来源获取时态数据,从手动输入的数据到使用观测传感器收集或模拟模型生成的数据,均可作为来源。以下是时态数据的一些示例。 在 ArcGIS 中,可以使用各种不同格式(

ArcGIS Online试用 (1)
一、ArcGIS Online概览 在了解ArcGIS Online之前,让我们回顾一下整个ArcGIS的产品体系结构。ArcGIS是一个完整综合的GIS平台包含了传统的桌面产品、服务器端产品、支持智能技术的移动产品以及最后的Online产品。这四大部分构成了完整的ArcGIS平台,能满足我们基本所有的GIS平台需求。ArcGIS产品体系结构如下图所示: ArcGIS Online 是用于
HBase region is not online 问题修复
一年多没有搞HBase了,回想前年和营神一起战斗的日子,~~~。今天线上遇到下面一个问题: hbase(main):002:0> get 'mynamespace:user_basic_info','BAC3510A922CF026500874EA3975E123'COLUMN CELL ERROR: org.apache.hadoop.hbase.NotServingRegionExcept
表空间的状态(一) - ONLINE和OFFLINE
前几天问一个表空间状态的问题,也暴露了自己基础知识的薄弱,之所以总结如下两篇博文,主要还是让自己静下心来,补一下相关知识点,并通过实践强化自己的理解。 主要参考: 《11g Concept》 《11g Administrator's Guide》 表空间的ONLINE和OFFLINE状态 1. 只要数据库处于OPEN状态,除了SYSTEM表空间外的其他表空间,都可以将其置为onlin
MySQL中的Online DDL
杨建荣的学习笔记 2016-12-05 23:20 记得有一天快下班的时候,一位开发同事找到我说,需要对一个表做变更,数据量据说有上千万,而当时是使用的MySQL版本是5.5,这可如何是好,对于在线业务要求高的情况下,这种需求真是让人头疼。 而在早期的版本中,这种问题就更让人无语了。在Oracle中这个问题解决的较早,当然在很多技术实现细节上,Oracle和MySQL还是蛮大的差距
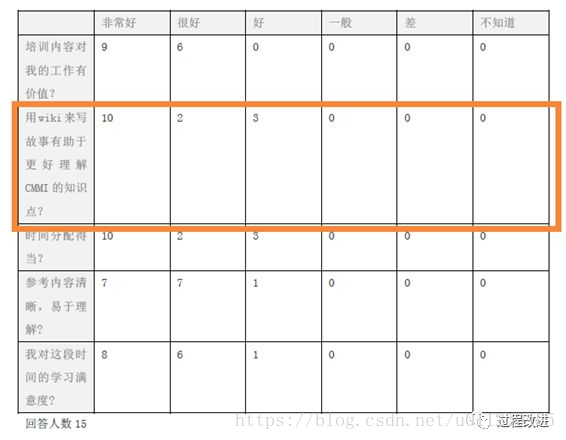
怎样有效ONLINE学习
这段时间收到很多反馈 ——培训市场缺口很大。 与一位杭州软件公司总监面谈后,也验证了这个发展趋势。 他说现在公司内的管理层,都在思考如何把大量的培训课做成在线形式,尤其公司本身有很多内部讲师,有自己的大学。第一步就是把这些本来面对面线下培训转为线上。 他问我:有没有这方面的想法? 1 他们提倡在线培训的原因: 越来越多公司意识到员工培训的重要性,老板也赞同员工(知识工作者)必须不