本文主要是介绍AAAI-2024 | Mono3DVG:首个基于单目RGB图像实现3D Visual Grounding的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注公众号,发现CV技术之美
本文分享论文Mono3DVG: 3D Visual Grounding in Monocular Images,该论文已被 AAAI 2024 接收,数据集和代码已开源。
详细信息如下:

单位:西北工业大学光电与智能研究院iOPEN、慕尼黑工业大学
论文链接:https://arxiv.org/abs/2312.08022
项目链接:https://github.com/ZhanYang-nwpu/Mono3DVG
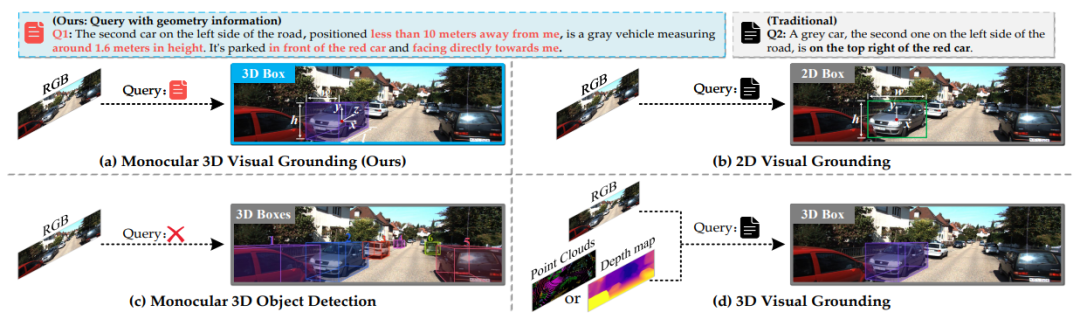
动机
对于智能系统和机器人而言,基于自然语言来理解真实3D场景中的物体是人机交互的一项重要能力。然而,现有的2D Visual Grounding无法捕捉指代物体的真实3D范围。3D Visual Grounding又需要激光雷达或RGB-D传感器,由于昂贵的成本和设备限制,极大地限制了其应用场景。单目3D目标检测成本低、适用性强,但无法定位特定目标。本文提出一种新的任务,用具有外观和模糊的几何信息的语言描述在单目RGB图像中实现3D Visual Grounding。
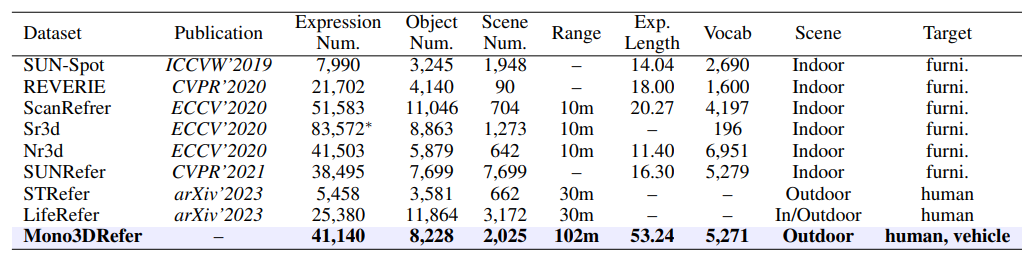
数据集
为解决Mono3DVG任务,本文创建了Mono3DRefer数据集。这是第一个在VG任务中利用ChatGPT生成自然语言描述的数据集。数据收集pipeline如下图:

本文梳理了3DVG领域中相关的数据集信息,整理如下:

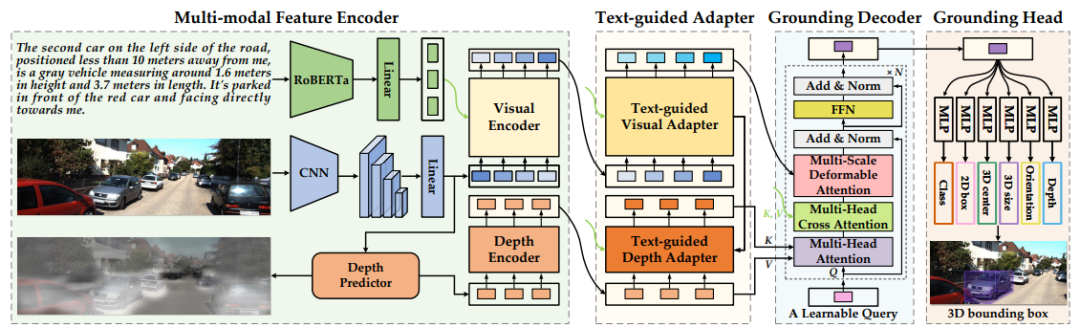
方法
为了利用具有外观和几何空间信息的自然语言进行推理,本文提出一种新的基于transformer的端到端方法,即Mono3DVG-TR。具体由多模态特征编码器、双文本引导适配器、Grounding解码器和Grounding头组成。
首先,采用RoBERTa和ResNet-50提取文本和多尺度视觉特征;并利用深度预测器显式地学习几何空间特征。其次,为了细化指代对象的多尺度视觉特征和几何空间特征,本文提出一种双文本引导适配器来;它可以进行基于像素注意力的文本引导特征学习,根据文本特征细化视觉特征和几何空间特征。接下来,可学习的query令牌首先聚合几何空间特征,然后通过文本嵌入增强文本相关的几何空间特征,最后从多尺度视觉特征中收集外观信息。
通过堆叠深度-文本-视觉注意力将对象级的几何线索和视觉外观融合到query令牌中,充分实现文本引导的解码。最终将query令牌输入到多个MLP中预测目标的3D空间坐标。
实验结果
数据集整体的结果如下所示:
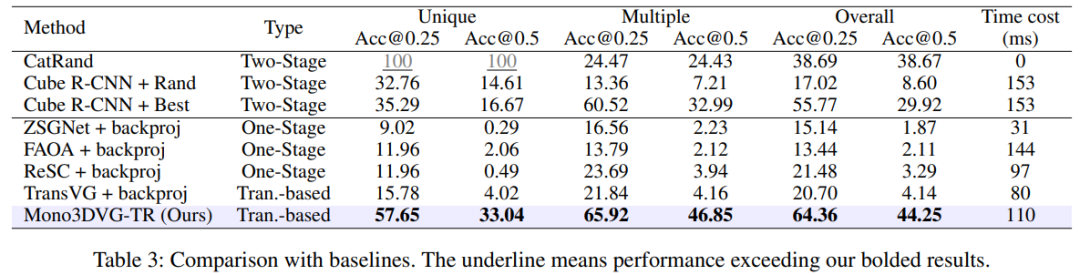
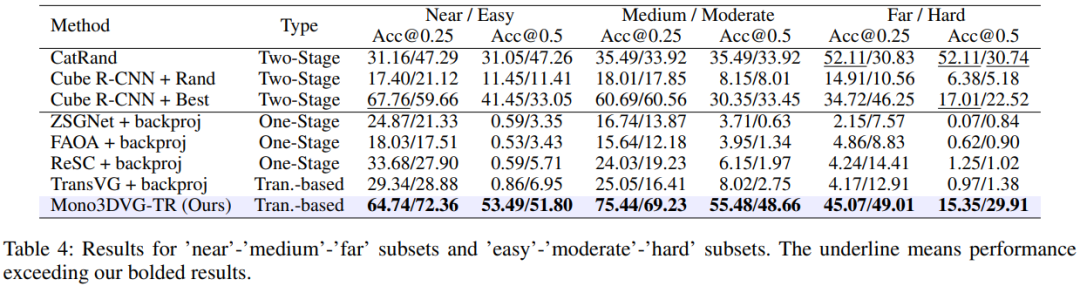
为了深入研究该任务的挑战,本文按照目标的距离远近程度和检测困难度划分了“近-中-远”和“易-中-难”两组子集,实验结果如下:
可视化结果如下:

针对Mono3DVG-TR方法中不同模块的可视化结果:

经过研究发现,在带有几何空间信息的Mono3DRefer数据集上训练的模型,可以直接在不带有几何空间信息的传统自然语言描述情况下使用,大大提高了该任务的适用性。详细结果见原文附件。
总结
我们相信Mono3DVG可以广泛应用,因为它不需要严格的设备条件,如RGB-D传感器,激光雷达或工业相机。可部署的应用场景广泛,比如无人机、监控系统、智能汽车、机器人等配备摄像头的设备。
更多细节请参考原文!
本文为粉丝投稿。

END
欢迎加入「三维视觉」交流群👇备注:3D

这篇关于AAAI-2024 | Mono3DVG:首个基于单目RGB图像实现3D Visual Grounding的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





