textual专题

生成式人工智能 - 文本反转(Textual Inversion):一种微调稳定扩散模型的方法
一、简述 大型文本到图像稳定扩散模型已经展示了前所未有的能力,可以使用文本提示合成新场景。这些文本到图像模型提供了通过自然语言指导创作的自由。然而,它们的使用受到用户描述特定或独特场景、艺术创作或新实体产品的能力的限制。很多时候,用户被限制行使她的艺术自由来生成特定独特或新概念的图像。此外,使用新数据集为每个新概念重新训练模型非常困难且成本高昂。 论文《一张图片

Textual Inversion:使用文本反转个性化文本到图像的生成
系列文章目录 DreamBooth:个性化的文本到图像扩散模型 文章目录 系列文章目录一、研究动机二、模型方法1、潜在扩散模型2、文本嵌入3、文本反演 三、Textual Inversion与dreambooth的对比四、Textual Inversion效果1、图像变化2、文本引导合成3、风格迁移 Textual Inversion模型:将独特的对象注入新场景,将它

Textual Inversion、DreamBooth、LoRA、InstantID:从低成本进化到零成本实现IP专属的AI绘画模型
2023年7月份国内有一款定制写真AI工具爆火。一款名为妙鸭相机的AI写真小程序,成功在C端消费者群体中出圈,并在微信、微博和小红书等平台迅速走红,小红书上的话题Tag获得了330多万的浏览量,相关微信指数飙升到了1800万以上。 其他能够提供类似功能例如:LensaAI,Midjourney,DALL-E3,Stable Diffusion,Tiamat。只不过LensaAI和妙鸭相机对于定制

EMNLP 2020 Beyond Instructional Videos: Probing for More Diverse Visual-Textual Grounding on YouTube
动机 从无标签的网络视频中进行预训练已经迅速成为在许多视频待处理任务中实际获得高性能的的手段。通过预测语音内容和自动语音识别(ASR) token之间的grounded关系来学习特征。然而,先前的训练前工作仅限于教学录像;作者希望这个领域是相对“容易”的:在教学视频中,演讲者通常会引用文字描述的目标/动作。即期望视频帧和ASR token中的语义信息在教学视频中可以很容易地关联起来。相似模型是否

Python文本用户界面进化:探索Textual框架,编程新境界
更多Python学习内容:ipengtao.com 文本用户界面(TUI)在很多应用中扮演着重要的角色,尤其是在需要在终端中运行的应用程序中。Python作为一门强大的编程语言,提供了多种工具和库来构建文本用户界面。在本文中,将深入探讨Textual,一个Python文本用户界面框架,帮助大家创建交互式终端应用。 Textual概览 Textual是一个基于Python的TUI框架,它使开发者
Textual Inversion on diffusers
Textual Inversion on diffusers 参考自官方文档:https://huggingface.co/docs/diffusers/training/textual_inversion_inference、https://huggingface.co/docs/diffusers/training/text_inversion?installation=PyTorch
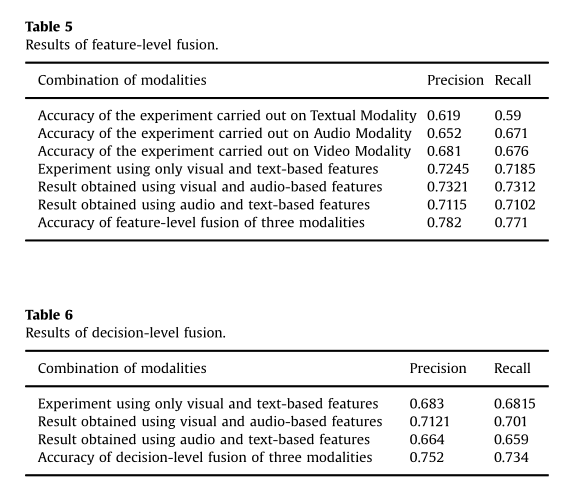
【论文阅读】Fusing Audio, Visual and Textual Clues for Sentiment Analysis from Multimodal Content
Motivations 随着社交媒体的普及,用户倾向于用视频来表达他们对产品的看法,因此,单单只对文本进行情感识别已经满足不了现在的智能系统,而且视频数据中可能包含更多的线索,视频中的音频数据表达的是说话者的语气,而视觉数据传递的是面部表情,这反过来有助于理解用户的情感状态。 因此作者提出了一种新的多模态情感分析方法,从音频、视觉和文本中提取不同的特征,然后分别采用特征级和决策级两种融合方式来