本文主要是介绍【论文阅读】Fusing Audio, Visual and Textual Clues for Sentiment Analysis from Multimodal Content,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Motivations
随着社交媒体的普及,用户倾向于用视频来表达他们对产品的看法,因此,单单只对文本进行情感识别已经满足不了现在的智能系统,而且视频数据中可能包含更多的线索,视频中的音频数据表达的是说话者的语气,而视觉数据传递的是面部表情,这反过来有助于理解用户的情感状态。
因此作者提出了一种新的多模态情感分析方法,从音频、视觉和文本中提取不同的特征,然后分别采用特征级和决策级两种融合方式来对不同模态的特征进行融合。并且使用了几种基于监督学习的分类器来完成情感分类任务。
作者的目标就是构建一下如下图所示的通用的多模态情感分析系统。输入视频、文本、音频数据信息,然后在Cognitive Module中提取不同模态的特征,然后对特征向量进行融合,输入到Motor Module中,得到最终的多模态情感预测结果。
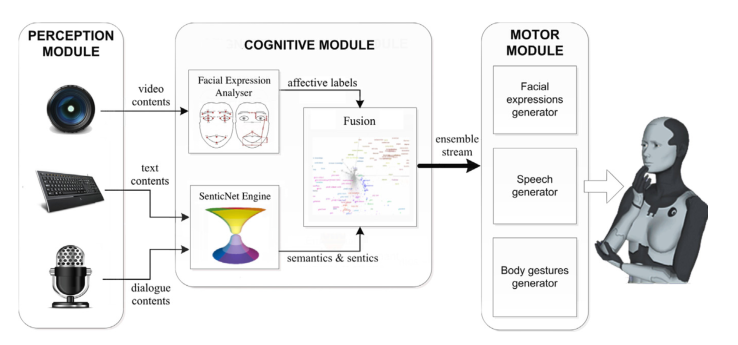
Introduction
本文将情感分为积极、消极和中性三类,在本文中,讨论了从不同的模态中提取特征的过程,以及如何使用它们来构建一个新的多模态情感分析框架。实验时,采用了几种基于监督学习的分类器来完成情感分类任务,并且发现使用ELM(极限学习机)获得了最好的性能。
情感分析早已在信号处理和人工智能技术中应用比较广泛,对于文本、音频、视频这三种信息来源,目前大多数情感分析系统仅仅处理单一的信息源,此外,已知所有这些系统在满足健壮性、准确性和总体性能需求方面都存在局限性,这反过来大大限制了这些系统在现实应用中的有用性。
人类交流和表达情感和情感的方式可以被表达为多模态。文本、音频和视觉模式同时被认知地利用,从而能够有效地提取在交流过程中传递的语义和情感信息。视频数据中会包含更多的线索,以识别意见持有人与产品有关的情绪。视频中的音频数据表达的是说话者的语气,而视觉数据传递的是面部表情,这反过来有助于理解用户的情感状态。
Methods
首先,对YouTube数据集进行处理,将视频分割成几个片段,然后将视频转化为图像,对图像进行人脸特征提取就能够得到视觉模态的特征向量。
另外,音频数据和文本数据来自于视频片段的音频信号和文本转录,得到数据后,采用不同的方法来提取音频模态特征和文本模态特征。
针对本文采用基于提取概念的特征提取方法,主要就是根据句子的语法、词性、句子的形态来提取句子中的几个单词。
特征级融合
通过连接所有三种模式的特征向量来实现特征级融合,形成一个单一的长特征向量。这种简单的方法具有相对简单的优点,但具有很高的精度。我们将每个模态的特征向量拼接成一个单一的特征向量流。然后利用该特征向量对每个视频片段进行情感分类。为了估计准确性,我们使用十倍交叉验证。
决策级融合
我们对每个模态使用单独的分类器。每个分类器的输出作为一个分类评分。特别地,我们从每个分类器中获得了每个情感类的概率得分。
Experimental Results
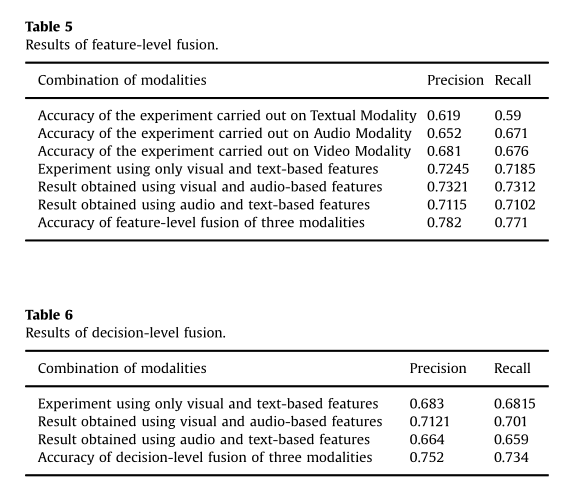
首先介绍一下作者对于不同分类器的的比较,可以得到使用ELM的性能是最好的,因此在下面的实验中,是使用ELM得出的结果。
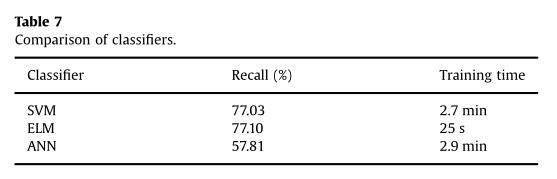
表5是采用特征级融合得到的结果,分别验证了T、A、V、T+V、V+A、T+A和T+A+V取得的性能,我们可以看到,不管是双模态还是三模态的融合,其性能都要比单模态的优秀,而三模态融合取得了最好的效果。
表6是采用决策级融合得到的结果,验证了 T+V、V+A、T+A和T+A+V取得的效果,在这些结果中,也是三模态融合取得的效果最好。
总结
本文作为多模态情感识别领域中一篇比较早发表的文章,为我们后续研究多模态提供了很多很好的思路,但是作者研究的多模态情感分析系统是面向对话级数据集的,可能会存在一些应用方面的瓶颈。
本文注重于使用各种有效的方法从不同模态中提取特征,尤其是使用基于语义计算来对文本特征进行特征提取,大大的提高系统的性能,这也为我们提供了未来的一个方向,可以通过研究更有效的方法来对多模态信息源进行特征提取,这样能够优化模型性能。
这篇关于【论文阅读】Fusing Audio, Visual and Textual Clues for Sentiment Analysis from Multimodal Content的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








