clues专题
【论文阅读】Fusing Audio, Visual and Textual Clues for Sentiment Analysis from Multimodal Content
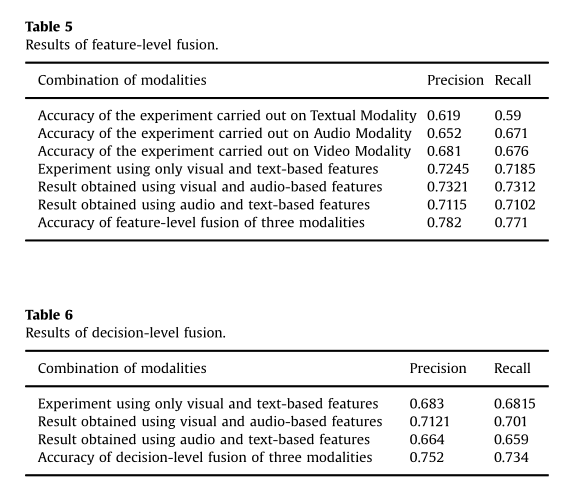
Motivations 随着社交媒体的普及,用户倾向于用视频来表达他们对产品的看法,因此,单单只对文本进行情感识别已经满足不了现在的智能系统,而且视频数据中可能包含更多的线索,视频中的音频数据表达的是说话者的语气,而视觉数据传递的是面部表情,这反过来有助于理解用户的情感状态。 因此作者提出了一种新的多模态情感分析方法,从音频、视觉和文本中提取不同的特征,然后分别采用特征级和决策级两种融合方式来