本文主要是介绍论文阅读:Correcting Motion Distortion for LIDAR HD-Map Localization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概要
Motivation
整体架构流程
技术细节
小结
论文地址:http://arxiv.org/pdf/2308.13694.pdf
代码地址:https://github.com/mcdermatt/VICET
概要
激光雷达的畸变矫正是一个非常重要的工作。由于扫描式激光雷达传感器需要有限的时间来创建点云,所以一次扫描过程中传感器的运动会导致点云发生畸变,这种现象被称为运动畸变或者卷帘快门。运动畸变校正方法已经存在,但是它们依赖于外部测量或者多次激光雷达扫描上的贝叶斯滤波。本文提出了一种新型算法,其执行快照处理以实现运动畸变校正。
Motivation
- 传统的运动畸变校正方法存在一些局限性,比如依赖于外部测量设备或者贝叶斯滤波器,这些方法可能不够实时或者成本较高。而本文提出的VICET算法通过快照处理技术,直接从当前LIDAR扫描中提取信息,校正运动畸变,不需要额外的设备,因此更具实用性和经济性。
- 提出了一种能够对测量不确定性进行有意义预测的新方法,鲁棒误差边界的计算是自动驾驶乘用车等安全关键导航系统的一个重要方面。
- 通过加入运动畸变补偿来改进NDT算法,以提高配准精度。
整体架构流程
该算法的整体架构流程包括快照处理、初始配准、扩展NDT匹配和优化、校正等关键步骤。首先,通过快照处理技术将当前LIDAR扫描与参考图像进行配准,得到初始的刚性变换估计。然后,利用扩展的NDT算法,同时优化刚性变换和运动失真参数。最后,根据优化后的参数对LIDAR扫描进行校正,以获得准确的校正结果。
考虑放置在矩形房间内的 机械旋转 LIDAR 单元,如图 所示。每次 LIDAR 绕 LIDAR 垂直 (z) 轴旋转 360 ° 时,都会生成 ALIDAR 图像(或扫描)。定义当旋转光束与连接 到 LIDAR 定子的坐标系统中的正 x 方向对齐时开始 LIDAR 扫描,我们将其标记为车身框架。在图中, 激光雷达的起始和结束位置由向量基表示,其中旋转 轴以蓝色显示,扫描起始轴以红色显示。现在考虑三 种情况,一种情况是传感器在扫描期间保持静止(以 标记为 a 的姿势开始和结束),第二种情况其中传感器进行纯平移(从 a 开始并在 b 结束), 第三种情况是传感器同时进行平移和旋转(从 a 开 始并在 c 结束)。这三种情况中的每一种都会创建 一个不同的 LIDAR 点云,如下所示:鸟瞰图,位于 标有"原始点云"(红色)的列中。在所有情况 下,点云中间都会出现一个圆圈,反映高程截止 点,模拟 LIDAR 单元无法生成地平线以下 30 ° 以 下的样本。点云是假设起点和终点之间的运动速率 一致而生成的。重要的是,原始图像是扭曲的(静 止情况除外),因此房间的墙壁不会形成完美的正 方形。然而,考虑到平台运动,点可以从主体坐标 系坐标转移到世界坐标系坐标。未扭曲的点云如图 2 所示。 1 作为标记为"失真校正"的一列图像 (蓝色)。重要的是,这些畸变校正图像都恢复了 正确的房间形状,以方形墙为界。在最后一种情况 (a → c)中,出现了缺失数据的楔形,因为 LIDAR 定子顺时针旋转,与 LIDAR 转子逆时针旋 转相反,这样在单次扫描期间无法看到整个房间。对于地图匹配应用,姿态是相对于参考图像进行估 计的。例如,可以通过记录移动激光雷达的一系列 顺序扫描来构建参考图像,以创建马赛克图像或高 清 (HD) 地图。如果在配准到地图之前可以对当前 扫描(在激光雷达的框架中捕获)进行反扭曲(转 换为世界框架),则该配准操作的性能将大大提 高。在图(1)的矩形房间的情况下,地图看起来非 常像静态情况下的扫描 (a → a)。如果在平移 (a → b) 或组合平移和旋转 (a → c) 过程中生成新的 LIDAR 图像,则生成的原始图像(红色)将与相应 的失真校正图像(蓝色)相比,更难与房间地图对 齐。本文的主要焦点是仅使用当前的激光雷达扫描和地 图就可以进行畸变校正。如果 LIDAR 运动未知,那 么我们可以通过将当前图像配准到地图来推断运 动,同时还测试各种反扭曲变换,以确定导致最佳 对准的配准和反扭曲的组合。
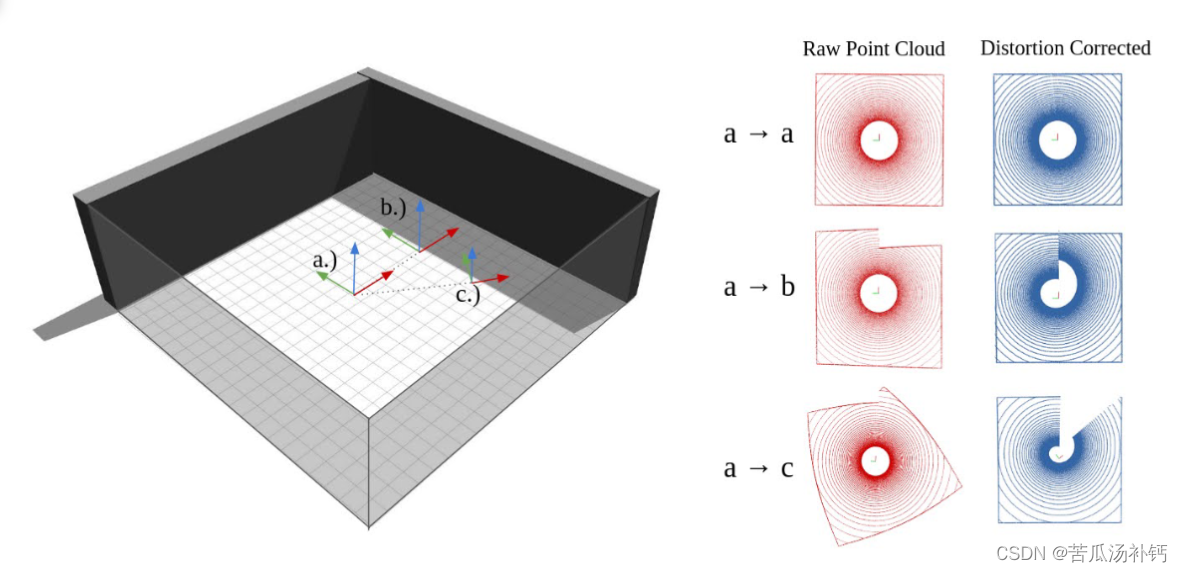
用于研究运动畸变校正的简单测试场景。等距房间视图显示了三个可能的激光雷达位置,标记为a、b和c。
在每个位置上,激光雷达单元的方向由一组正交基向量描述。对于每种配置,假设激光雷达束从红色箭头开始与垂直(蓝色)轴逆时针旋转。在扫描过程中,激光雷达单元可以保持静止(a → a),前向线性运动(a → b),或进行复合平移和旋转(a → c)。在每种情况下,激光雷达束在激光雷达定子的参考系中旋转360度,而定子本身也在移动,导致畸变的原始点云(从上方视角看,用红色表示)。通过补偿定子运动,可以将原始图像转换为固定于房间的坐标系(用蓝色表示),从而恢复出房间的正方形形状。
技术细节
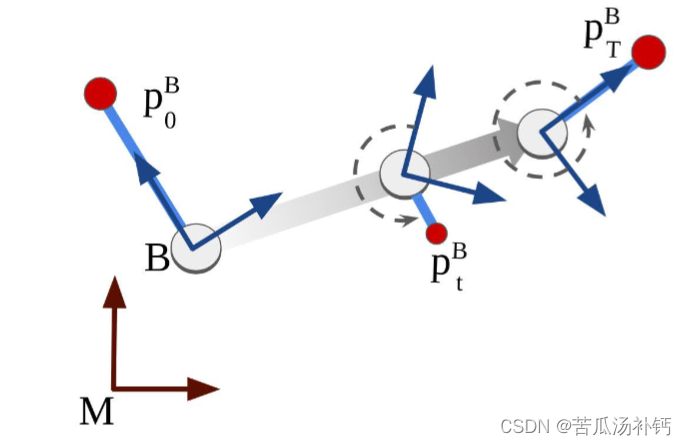
LIDAR 定子(或主体)B 的框架相对于地图框架 M 移 动。出于说明目的,底座以 2D 形式显示(从上方观察)。时 间的进展由灰色阴影箭头表示,激光雷达光束在时间 t = 0 和时 间 t = T 之间扫过一整圈时记录测量结果(红点)。

200 次扫描中每一次的地面实况,叠加在高清地图上
时间戳:可以通过使用光束角度𝜓来近似激光雷达点的时间戳。重要的是不要将记录在不同时间(例如在扫描开始和结束时)的点分组在一起。通过在0°(扫描开始)处定义一个体素边界,然后移除𝜓<0°或𝜓≥360°的偶发异常点来解决混叠问题。
初始化:VICET假设对初始姿态有一个合理的估计。通过首先运行标准的扫描匹配算法(具体为NDT)来获得初始姿态,然后VICET通过补偿运动畸变来改进这个估计。
扩展表面:NDT无法识别墙壁(以及跨越体素边界的其他平面表面)仅在表面法线方向上提供有用信息;为了增强收敛可靠性和准确性,采用ICET 的扩展表面抑制方法。
小结
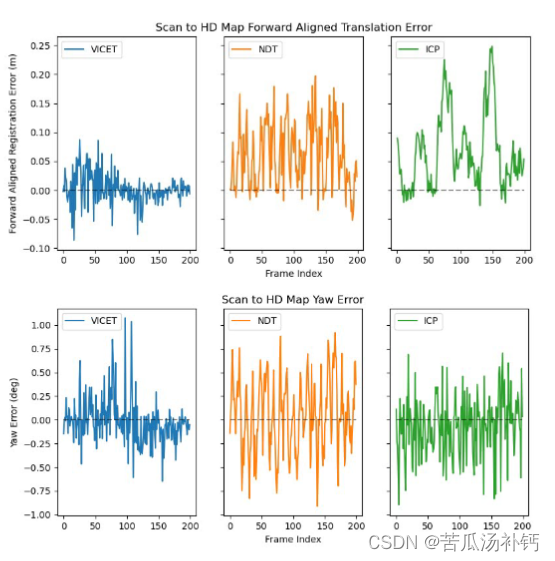
在静态高清地图上注册 200 个原始 LIDAR 扫描时的平移误差(顶部)和偏航误 差(底部)
在本文中,引入了VICET,这是一种求解单帧激光雷达点云的扫描到地图匹配问题的新型算法。VICET求解了12种状态,其中6种状态描述了将扫描与地图对齐的刚体变换,另外6种状态考虑了在创建点云过程中平台运动所造成的畸变。与其它运动畸变方法相比,本文方法仅需要单帧激光雷达扫描,并且不需要外部传感器数据。
通过在现实世界数据上进行实验,本文证明了VICET比传统的NDT和ICP提高了精度,降低了地图匹配的平移偏差(从6.9cm降低到0.27cm,降低了一个数量级),同时减少了一个sigma变化(从5.4cm到2.6cm)。VICET还降低了姿态估计的偏差和方差。这些改进与精密汽车和城市空中交通应用相关。
这篇关于论文阅读:Correcting Motion Distortion for LIDAR HD-Map Localization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





