本文主要是介绍Online_Video Moment Localization via Deep Cross-modal Hashing论文阅读1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里写目录标题
- 各类标志
- 局部特征与全局特征
- Bi-TCN
- 待补充
各类标志

未修剪的视频集合
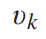
代表第k个视频。
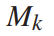
对于第k个视频有多少个查询。
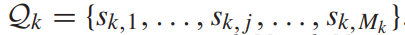
对于一个视频的查询集。
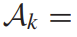
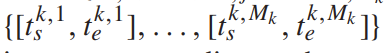
由人员标定的,第k个视频,针对查询集的所有目标片段。
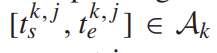
第j个目标片段的开始时间和结束时间。
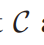
训练好的跨模态哈希网络的出的候选时刻集。
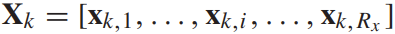
由C3D产生的第k个视频的局部特征集合,Rx是
VEN:

- 采用C3D模型获取局部特征
- 结合Bi-TCN模型,捕获对应的前上下文和后上下文信息来学习局部特征。上图是一个3层Bi-TCN,第k个视频的每个元素经过三层一维的膨胀卷积处理后,将两个方向的上下文进行整合,形成更全面的特征表示。
- 采用一维正则卷积形成候选时刻集
- 应用一个MLP模型获得所有候选集的特征表示
局部特征与全局特征
参考:https://blog.csdn.net/qq_26898461/article/details/49885673
局部特征(local features):

中间一列即为局部特征
- 一些局部才会出现的特征
- 局部:一些能够稳定出现并且具有良好的可区分性的一些点,这样在物体不完全受到遮挡的情况下,一些局部特征依然稳定存在。
- 如上图:一方面:用这些稳定出现的点(局部特征)来代替整幅图像,可以大大降低图像原有携带的大量信息,起到减少计算量的作用。另一方面:当物体受到干扰时,一些冗余的信息(比如颜色变化平缓的部分和直线)即使被遮挡了,我们依然能够从未被遮挡的特征点上还原重要的信息。
全局特征:
- 方差,颜色直方图。如果用户对整个图像的整体感兴趣,而不是前景本身感兴趣的话,全局特征用来描述总是比较合适的。
- 缺点:无法分辨出前景和背景却是全局特征本身就有的劣势,特别是在我们关注的对象受到遮挡等影响的时候,全局特征很有可能就被破坏掉了。
Bi-TCN
输入xk进入有E-1层的Bi-TCN的输出可以表示为:

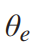
第e层的一维膨胀卷积
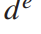
膨胀系数
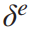
第e层滤波核大小
待补充
- C3D
- 膨胀卷积
- 膨胀系数
- 滤波核大小
- MLP
这篇关于Online_Video Moment Localization via Deep Cross-modal Hashing论文阅读1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









