本文主要是介绍Large Language Models for Test-Free Fault Localization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基本信息
这是24年2月发表在ICSE `24会议(CCF A)的一篇文章,作者团队来自美国卡内基梅隆大学。
博客创建者
武松
作者
Aidan Z.H. Yang,Claire Le Goues,Ruben Martins,Vincent J. Hellendoorn
标签
软件错误定位、大语言模型、深度学习、神经网络模型
1 摘要
软件错误定位 (Fault Localization,FL) 旨在自动定位有错误的代码位置,这是许多手动和自动调试任务中的第一步。一般的 FL 技术需要提供测试用例,并且通常需要大量的程序分析、程序检测或数据预处理。近年来涌现出一些将大型语言模型 (Large Language Model,LLM)用于代码相关工作的方法,比如代码生成、代码总结等任务,LLM表现出强大的性能和泛化能力。受此启发,文章研究了 LLM 在语句级别(Statement-level、Line-level)进行错误定位的有效性。文章主要有以下几个贡献:
- 第一种基于大语言模型的错误定位方法,可在没有任何测试信息的情况下定位有缺陷的代码行;
- 第一种能够在语句级别检测代码安全风险的方法;
- 发现错误定位能力随着LLM规模的变大而提高。
1.1 相关工作
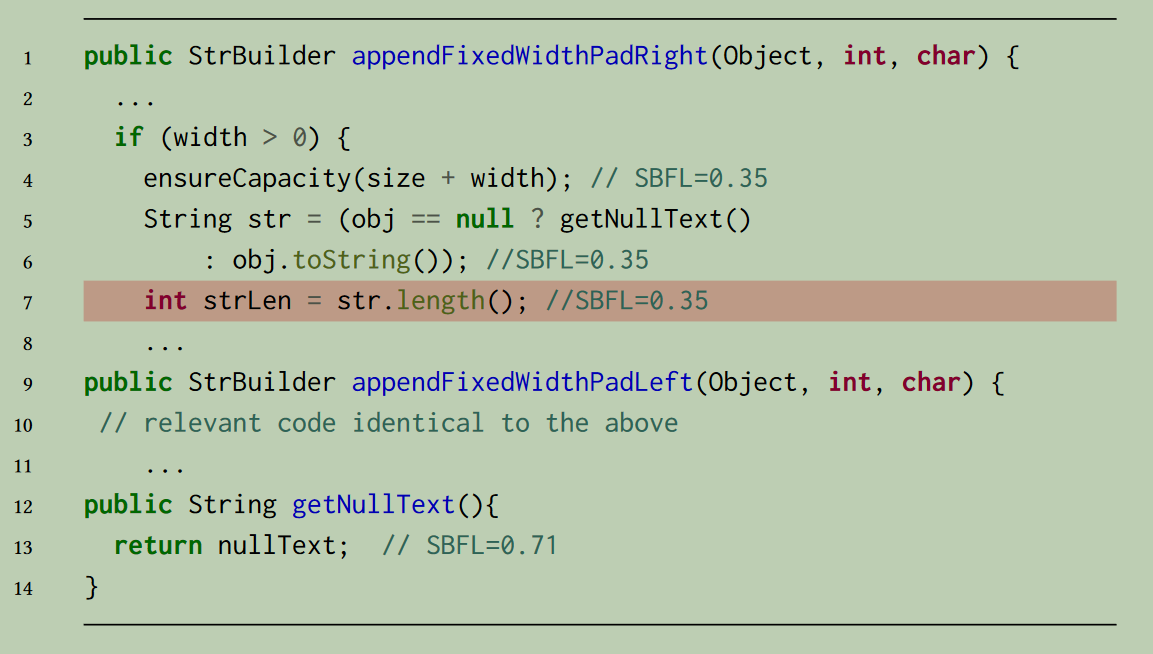
- SBFL:基于频域的错误定位(Spectrum-based FL),利用程序执行多个失败的测试用例的覆盖信息计算语句怀疑度,然后进行排名。某个语句在失败的测试中执行的频率越高,在通过的测试中执行的频率越低,该元素的可疑程度就越高。SBFL存在并列排名的情况,如下图中,if语句块中的代码行实际上不能被覆盖信息区分出差异,因此其怀疑度分数是相同的,而真正出错行第7行则无法被准确定位出来。
-
MBFL:基于变异的错误定位(Mutation-based FL),来源于软件测试中的变异测试。变异测试的思想是使用测试用例执行变异体,测试用例执行结果与源程序执行结果不同,则称该测试用例被该变异体杀死(killed)。被杀死变异体数量与变异体总数的比值为该测试用例的变异分数,变异分数越高,则说明该测试用例更有效。将变异测试用于软件错误定位,基于思想:错误语句容易通过某种简单的变异方式被修复,变异被修复的比例越大,则该语句为错误语句的概率越高。MBFL的局限性在于有的语句可能无法生成变异体,以及执行效率过低的问题(一个程序要为每个语句生成多个变异体,并且要为每个变异体执行多个测试用例,因此该方法定位一个程序的错误行的复杂度为 O ( n 3 ) O(n^3) O(n3))。
-
MLFL:基于机器学习的错误定位(Mechaine Learning-based FL)。早期的机器学习称为Learning-to-Rank的方法,都基于代码信息和代码测试信息训练机器学习模型并预测语句怀疑度,从而进行排名。最近的深度学习方法将这些信息进一步融合、编码和提取特征,并结合一些其他的模型(如GNN、CNN)提升特征提取的效果。
-
LLMs for code:近年的LLMs通常用于代码表征、代码合成等领域,但由于大模型输出的不确定性,以及无法直接用于错误定位(需要prompt),目前还少由工作将LLM用于错误定位。
2. 方法
2.1 方法架构图
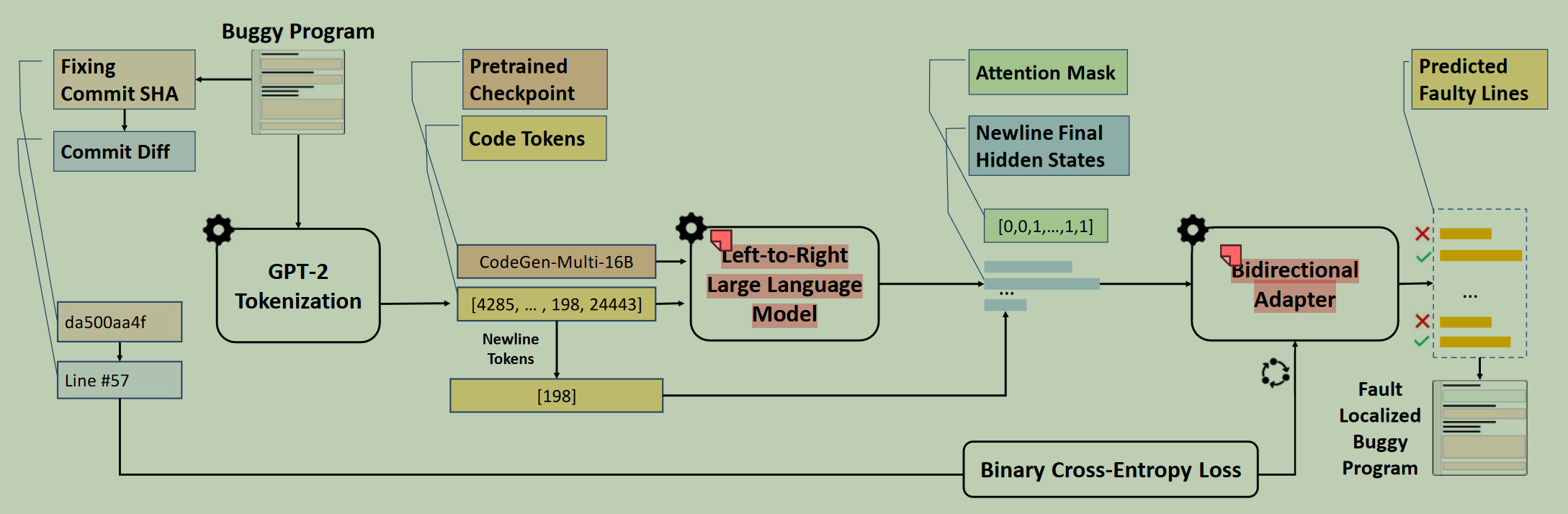
2.2 方法描述
2.2.1 Left-to-right Language Models(即大模型)
如各种用于编程领域的代码生成语言大模型,其模型架构都是基于自回归的自左向右的生成模型,也即decoder-only的transformer结构网络模型。这种模型架构适用于生成任务,例如常见的代码生成模型,如下图所示:

图a中给定一个具有代码上文的片段,以及功能注释,可以让语言模型据此生成接下来的内容。文章方法主要是利用代码生成大模型提取代码特征,由于代码大模型基于大规模代码数据集训练,其已经具备了较好的代码理解能力。因此文章没有对大模型进行微调,直接使用了现有的代码生成大模型: C o d e G e n CodeGen CodeGen,这是目前效果较好的一个代码大模型。
2.2.2 Bidirectional Adapter(双向注意力适配器)
作者认为Left-to-right的代码生成大模型只能与先前的代码进行交互(单向注意力),对代码行之间的语义考虑不够充分,效果不够好。因此在大模型之后增加了几层Transformer encoder层,以进行双向注意力计算,由此使得每个句子可以与前后的句子都能交互信息。整体训练步骤如下图所示:
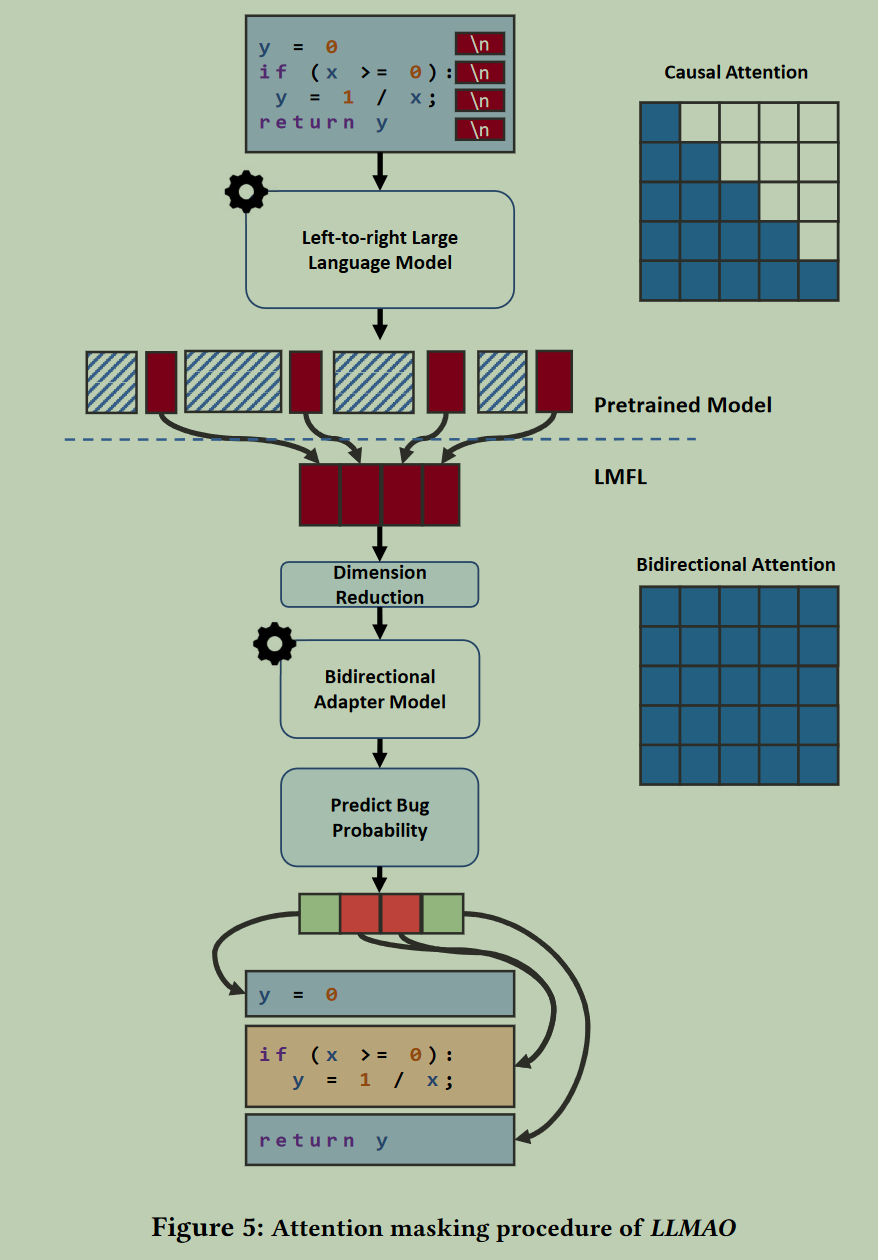
- 首先输入代码文本被序列化为一串代码 t o k e n s tokens tokens,记为 C = [ c 0 , c 1 , . . . , c N ] C = [c0, c1, . . . , cN ] C=[c0,c1,...,cN] 。将代码 t o k e n s tokens tokens输入一个因果预训练(causally pretrained,即left to right)的 Transformer 模型(LLM,CodeGen),以将它们转换为向量表示,这些向量表示的维度为 S ∈ R N × D S∈\mathbb{R}^{N×D} S∈RN×D ,其中 D D D 表示预训练模型的每一个隐层输出的维度(即 d m o d e l d_{model} dmodel )。
- 进而用每一行代码末尾的换行符的向量代表该行代码,此时每一行的向量表示即为 S N L ∈ R M × D = S [ c i = \ n ] S_{NL}∈R^{M×D}=S[c_i=\verb|\| n] SNL∈RM×D=S[ci=\n] ,其中 M M M 表示原始代码中的换行符数量, M M M<< N N N。作者认为该换行符向量可以准确而合理地捕捉到前一句的信息。
- 对于 CodeGen 模型,16B版本模型的隐层维度 D 的高达 6144。然而由于文章所加入的适配器层仅基于少量数据训练,适配器的维度d远小于D,文章所使用的 d d d 维度为 d ∈ { 256 , 512 , 1024 } d∈{\{}{256,512,1024}{\}} d∈{256,512,1024}。因此为了将CodeGen的维度与适配器对接,使用一个全连接层将二者连接起来。文章中形式化表述为:“将原来的 S N L S_{NL} SNL约简为 R N L ∈ R M × d = S N L W d R_{NL}∈\mathbb{R}^{M×d}=S_{NL}W_d RNL∈RM×d=SNLWd,其中 W d ∈ R D × d W_d∈\mathbb{R}^{D×d} Wd∈RD×d 是一个可学习的权重,相当于一个全连接层”。
- 由此训练获得的适配器最终获得每一行的向量表示 A N L ∈ R M × d A_{NL}∈\mathbb{R}^{M×d} ANL∈RM×d 。适配器使用两层Transformer encoder层。最终使用Sigmoid激活函数将每行的表示向量转换为犯错概率估计值。使用二值交叉熵计算该概率值和ground truth之间的损失,即 L C E = T l n B + ( 1 − T ) l n ( 1 − B ) \mathcal{L}_{CE}=T {\rm{ln}} B+(1-T){\rm{ln}}(1-B) LCE=TlnB+(1−T)ln(1−B) 。
3. 实验
3.1 数据集
- Defects4J V1.2.0:一个 Java 基准数据集,其中包含来自 6 个 Java 项目的 395 个 bug 。对于大多数基准测试,使用 V1.2.0 而不是最新版本 (V2.0.0),以便与大多数先前的 FL 技术在同一数据集上进行比较。
- Defects4J V2.0.0:一个 Java 基准数据集,与 Defects4J V1.2.0 [21] 相比存在其他错误。这个数据集是为了证明我们的方法可以推广到其他未参与训练的数据集上。
- BugsInPy:一个 Python 基准测试,其中包含来自 17 个不同项目的 493 个错误。
- Devign:一个来自两个开源项目的 5,260 个 C 语言的benchmark。最初的Devign数据集包含来自四个不同项目的15,512个安全漏洞。
所有数据集都包含与每个故障相对应的修复提交。遵循先前的方法,文章将错误语句识别为在与每次提交相关的 git diff 中更改的语句。
3.2 基准方法
- DeepFL:通过简单的多层神经网络融合多种测试信息提取代码行的表征然后预测错误概率;
- DeepRL4FL:通过CNN融合多种测试信息、代码执行信息和代码表示信息;
- TRANSFER-FL:也是融合多种测试信息和语义信息然后MLP做分类,但引入了迁移学习的概念,构建开源代码数据集训练语义提取器,然后用于错误定位代码的语义信息提取;
- SBFL(Ochiai)。
3.3 评价指标
- Top-N:测量在前 N 个位置 (N=1, 3, 5) 内至少有一个故障单元的故障数量。
- AUC面积(Area Under the ROC Curve,AUC):即ROC 曲线下的面积,用于测试模型的有效性。AUC 是介于 0 和 1 之间的数字,越接近1越好。
3.4 结果分析
3.4.1 对比实验
由于文章针对语句级别(statement-level)的错误定位,而DeepFL是方法级别(method-level)的,因此遵循先前方法,DeepFL选取只利用覆盖信息和变异信息的版本进行对比。对比实验仅在Defects4J V1.2.0数据集上开展,针对java语言。
文章没有对比MBFL方法,原因可能是因为有的代码行无法进行变异。
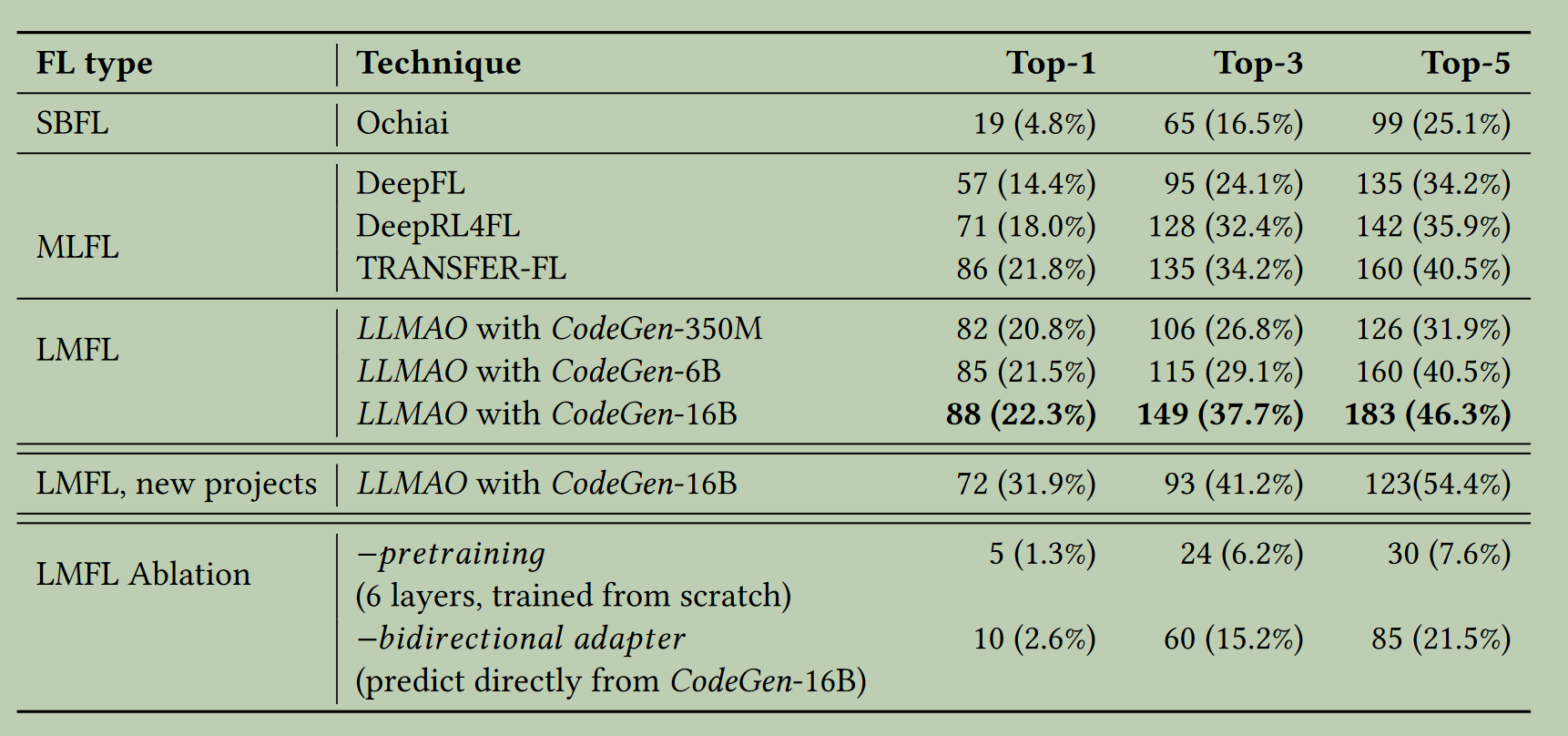
实验结果显示该方法超越了之前的所有深度学习方法,以及SBFL方法。
3.4.2 cross-project验证(对新的项目代码的泛化性)
前面的对比实验测试集和训练集数据来自同一数据集,其分布相同,采用项目内的交叉验证。而cross-project验证将在未见过的项目上进行测试,性能都会较前者有所降低。cross-project验证在Defects4J V2.0.0数据集上进行,因为Defects4J V2.0.0包括了Defects4J V1.2.0没有涵盖的新的项目代码。
文中说明对比之前的深度学习方法DeepRL4FL和TRANSFER-FL,包括GRACE,性能都有所下降。从图3.1可以看出(new projects),本文方法也有相当程度的下降。但文中表明本文方法优势在于无需为新的项目重新训练模型,而其他模型的交叉验证要么重新训练了模型,要么只能在方法级别定位错误,因此本文方法泛化能力好更,计算成本更低。
3.4.3 消融实验结果
从上图的Ablation部分可以看出,大模型的预训练以及本文所加入的适配器起到了重要作用。
另外,未加入适配器的CodeGen尽管是一个生成模型(目标并非针对于文本理解任务),但其也具有相当于SBFL水平的代码错误理解能力,效果与SBFL相当(仅训练一层MLP接在大模型的输出用于分类)。但对比加入适配器后效果大大提升,说明所加入的双向适配器的有效性,也进一步证明作者考虑到的双向注意力的重要性。
3.4.4 对其他语言和领域的泛化性(generalization)
作者还评估了该方法在不同语言(other languages)和不同领域(other domains)上的错误定位能力,主要是在python数据集BugsInPy,以及C语言的风险预测Devign数据集上进行。其中,BugsInPy用于验证该方法对不同语言的泛化性,Devign用于验证对新的领域数据集上的泛化性,因为Devign是一个进行风险监测的数据集,没有测试信息作为数据输入,因此先前的基于测试信息的方法就不能适用了。

实验结果:
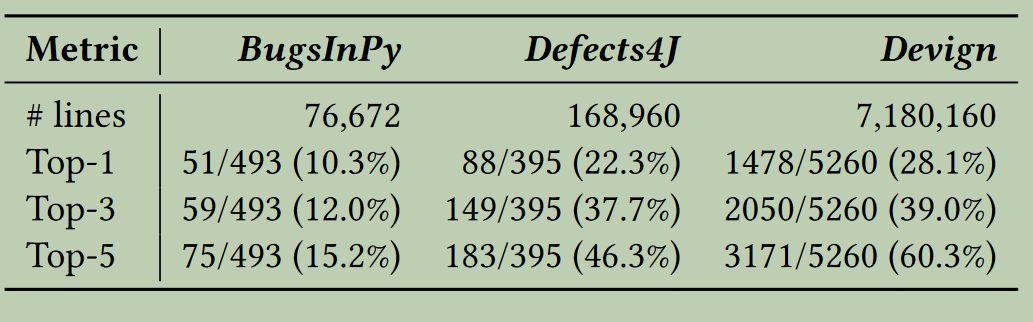
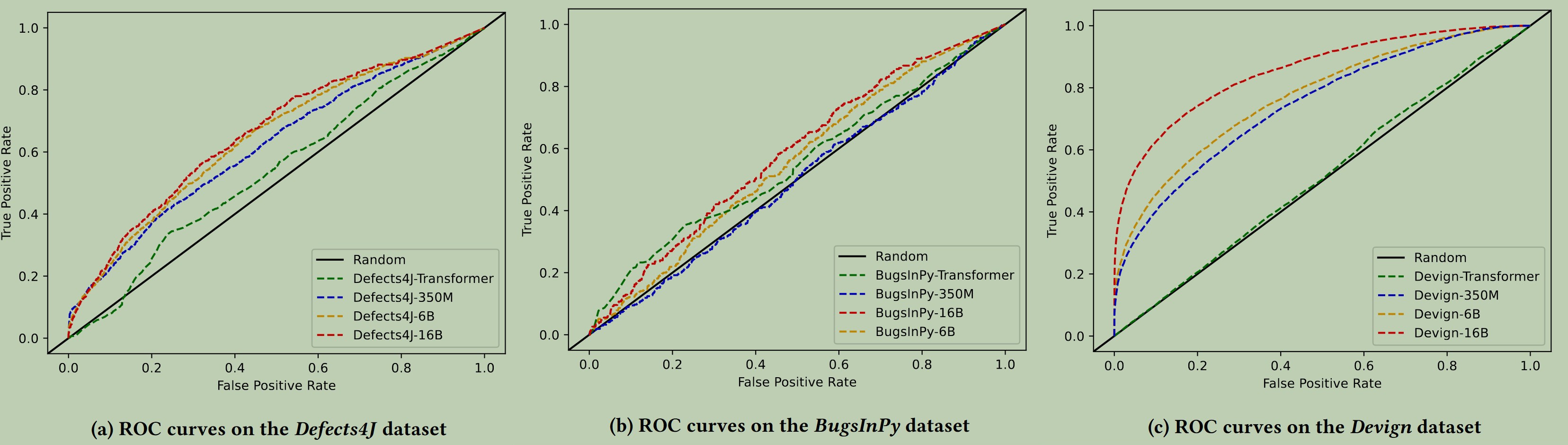
实验结果表明:
- LLMAO能泛化到其他的语言数据集上;
- LLMAO的性能随着训练数据集大小的增加而提高;
- LLMAO对于在测试用例不可用的 C 语言中查找安全漏洞特别有效;
- LLMAO的性能随着CodeGen模型规模大小的增加而提高。
4. 总结
4.1 亮点
- 利用了大模型的代码理解能力,并加入具有双向注意力的Tansformer层解决代码生成大模型的单向注意力在代码山下文理解上的局限性,相当于验证了双向注意力在该任务上的重要性;
- 解决了传统方法和一般深度学习方法对测试信息的依赖(test-free),降低了数据预处理的成本。说明了代码理解角度直接进行错误定位是可行的。
4.2 不足
- 在方法对比上没有对比传统方法MBFL;
- 缺乏可解释性。
4.3 启发
- 大模型是可以利用的,提取程序语义信息,基于程序和问题理解,进行错误定位。
5. 相关知识链接
- 论文链接
- 代码链接
- BibTex
@inproceedings{yang2024large,title={Large language models for test-free fault localization},author={Yang, Aidan ZH and Le Goues, Claire and Martins, Ruben and Hellendoorn, Vincent},booktitle={Proceedings of the 46th IEEE/ACM International Conference on Software Engineering},pages={1--12},year={2024}
}
这篇关于Large Language Models for Test-Free Fault Localization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





