distillation专题

Similarity-Preserving Knowledge Distillation
Motivation 下图可以发现,语义相似的输入会产生相似的激活。这个非常好理解,这个C维的特征向量可以代表该输入的信息 因此本文根据该观察提出了一个新的蒸馏loss,即一对输入送到teacher中产生的特征向量很相似,那么送到student中产生的特征向量也应该很相似,反义不相似的话同样在student也应该不相似。 该loss被称为Similarity-preserving,这样stu

Revisit Knowledge Distillation: a Teacher-free Framework
Observations 通过几组实验观察到 反转Knowledge Distillation(KD)即利用student来guide teacher的话,teacher的性能依然可以得到提升用一个比student还差的teacher来guide student的话,student的性能依然可以得到提升 因此作者得到以下观点 KD只是一种可学习的label smoothing regula

CVPR2024知识蒸馏Distillation论文49篇速通
Paper1 3D Paintbrush: Local Stylization of 3D Shapes with Cascaded Score Distillation 摘要小结: 我们介绍了3DPaintbrush技术,这是一种通过文本描述自动对网格上的局部语义区域进行纹理贴图的方法。我们的方法直接在网格上操作,生成的纹理图能够无缝集成到标准的图形管线中。我们选择同时生成一个定位图(指定编辑
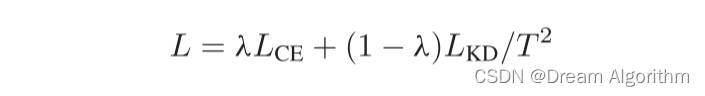
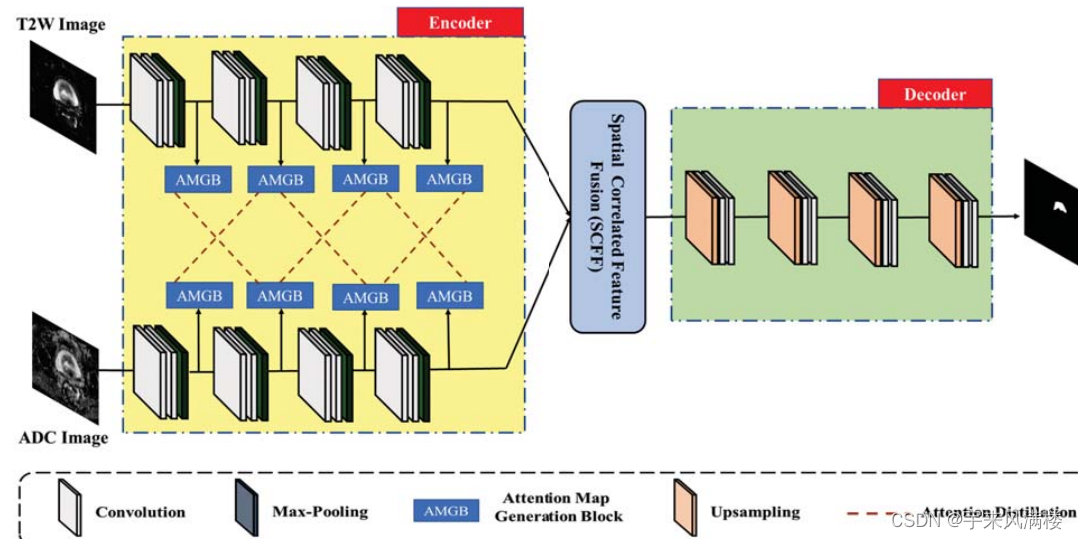
Class-Aware Self-Distillation for Remote SensingImage Scene Classification
这篇文章提出了一种新的蒸馏方式,由于遥感场景图像具有类间相似性和类内多样性的特点,这篇文章试图解决这个问题。通过三个共享权重的分支,同时输入三张图片,其中两张类别相同的图片,一张类别不同但地物特征相似的图片,用x1,x2,x3表示。这样就获得了三个输出,将相同类别的输出和相似类别的输出同时对x1的输出进行蒸馏。过程如下图所示: 蒸馏的目标为增大类内相似性,减小类间相似性,通过构建

模型蒸馏(distillation)
大size的teacher模型,训练的样本,最后一层softmax之前的logits,当作student模型的训练目标,损失函数是2个向量的距离; 原理:logits包含更多的信息,比label(也就是1-hot vector)的信息量更大; student也可以加上对teacher中间层feature的学习;(模型size不同的话,不好办) 一般是先训练完毕teacher模型,再开始训st
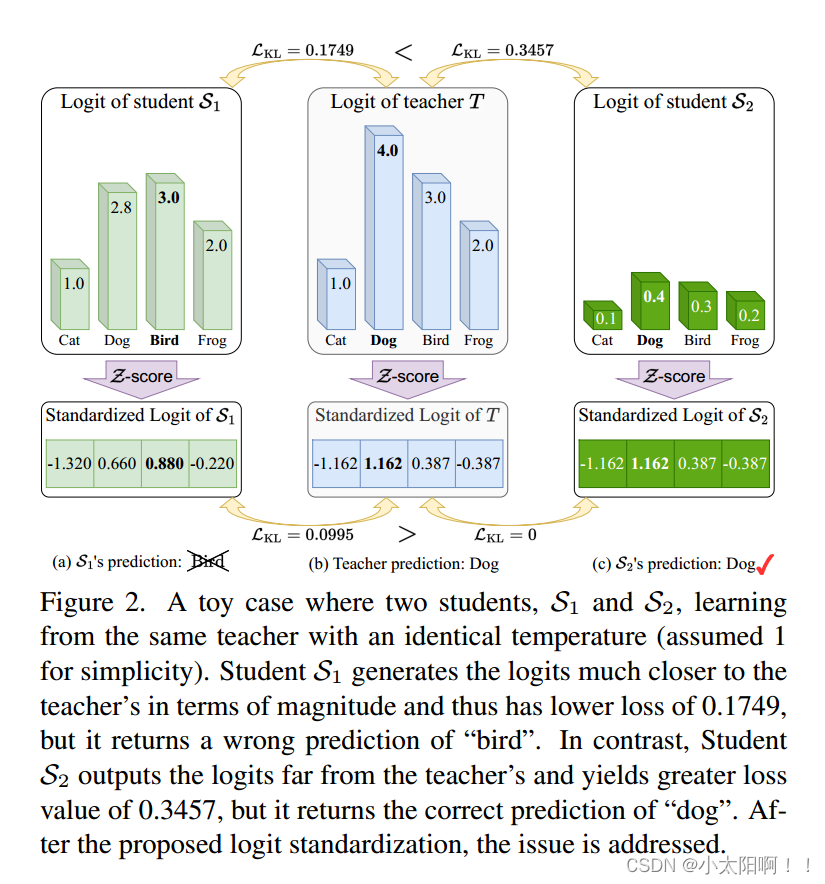
Logit Standardization in Knowledge Distillation 知识蒸馏中的logit标准化
摘要 知识蒸馏涉及使用基于共享温度的softmax函数将软标签从教师转移到学生。然而,教师和学生之间共享温度的假设意味着他们的logits在logit范围和方差方面必须精确匹配。这种副作用限制了学生的表现,考虑到他们之间的能力差异,以及教师天生的logit关系足以让学生学习。为了解决这个问题,我们建议将温度设置为logit的加权标准差,并在应用softmax和KL散度之前进行logit标准化的即
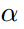
Scale Decoupled Distillation
摘要 Logit知识蒸馏因其实用性在近年来的研究中越来越受到重视。然而,与特征知识蒸馏相比,它的性能往往较差。在本文中,我们认为现有的基于Logit的方法可能是次优的,因为它们只利用了耦合多个语义知识的全局Logit输出。这可能会把模棱两可的知识传递给学生,误导他们学习。为此,我们提出了一种简单而有效的logit知识蒸馏方法,即尺度解耦蒸馏(SOD)。SOD**将全局logit输出解耦为多个局部

【Image captioning】论文阅读九—Self-Distillation for Few-Shot Image Captioning_2022
摘要 大规模图像字幕数据集的开发成本高昂,而大量未配对的图像和文本语料库可能有助于减少手动注释的工作。在本文中,我们研究了只需要少量带注释的图像标题对的少样本图像标题问题。我们提出了一种基于集成的自蒸馏方法,允许使用不成对的图像和字幕来训练图像字幕模型。该集成由多个基础模型组成,在每次迭代中使用不同的数据样本进行训练。为了从未配对的图像中学习,我们使用整体生成多个伪标题,并根据它们的置信水平
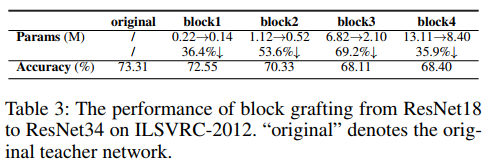
【论文翻译】Progressive Network Grafting for Few-Shot Knowledge Distillation
Progressive Network Grafting for Few-Shot Knowledge Distillation 渐进式网络移植技术在少样本知识提取中的应用 论文地址:https://arxiv.org/pdf/2012.04915v2.pdf 代码地址:https://github.com/zju-vipa/NetGraft 摘要 Knowledge distillat

Decoupled Knowledge Distillation解耦知识蒸馏
Decoupled Knowledge Distillation解耦知识蒸馏 现有的蒸馏方法主要是基于从中间层提取深层特征,而忽略了Logit蒸馏的重要性。为了给logit蒸馏研究提供一个新的视角,我们将经典的KD损失重新表述为两部分,即目标类知识蒸馏(TCKD)和非目标类知识蒸馏(NCKD)。我们实证研究并证明了两部分的效果:TCKD转移了关于训练样本“难度”的知识,而NCKD是logit蒸馏
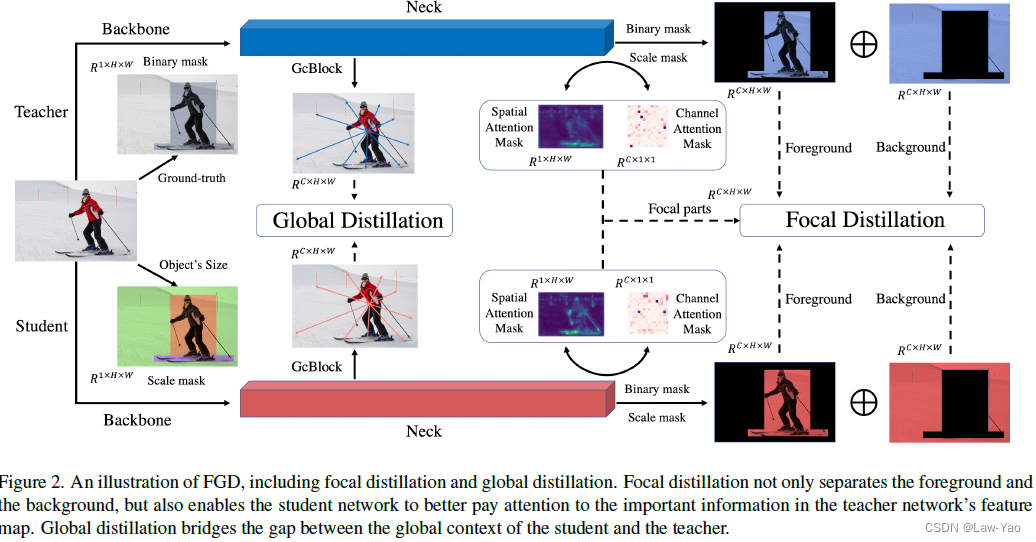
Focal and Global Knowledge Distillation——目标检测网络的知识蒸馏
Paper地址:https://arxiv.org/abs/2111.11837 GitHub链接:https://github.com/yzd-v/FGD 方法 FGKD(Focal and Global Knowledge Distillation)通过Focal distillation与Global distillation的结合,兼顾了Instance-level信息、Sp
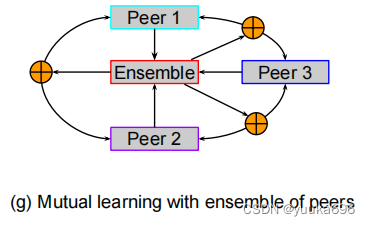
多教师知识蒸馏综述-分类(Knowledge Distillation and Student-Teacher Learning for Visual Intelligence)
Overall:学生可以从多个教师那里学到更好的知识,比一个教师的信息更丰富、更有指导意义 文章目录 前言一、Distillation from the ensemble of logits二、Distillation from the ensemble of features三、Distillation by unifying data sources四、 From a single t
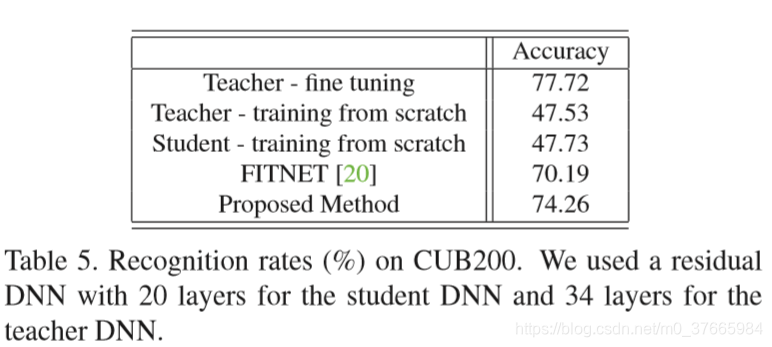
A Gift from Knowledge Distillation: Fast Optimization,Network Minimization and Transfer Learning论文初读
目录 摘要 引言 相关工作 知识迁移 快速优化 迁移学习 方法 提出观点 数学表达式 FSP Matrix的损失 学习步骤 实验 快速优化 性能的提升 迁移学习 结论 摘要 提出了将蒸馏的知识看作成一种解决问题的流,它是在不同层之间的feature通过内积计算得到的 这个方法有三个好处: student网络可以

浅谈知识蒸馏(Knowledge Distillation)
浅谈知识蒸馏(Knowledge Distillation) 前言: 在实验室做算法研究时,我们最看重的一般是模型精度,因为精度是我们模型有效性的最直接证明。而在公司做研发时,除了算法精度,我们还很关注模型的大小和内存占用。因为实验室模型一般运行在服务器上,很少有运算资源不足的情况,但是公司研发的算法功能最终都是要部署到实际的产品上的,像手机或者小型计算平台,其运算资源是很有限的。所以算法工程
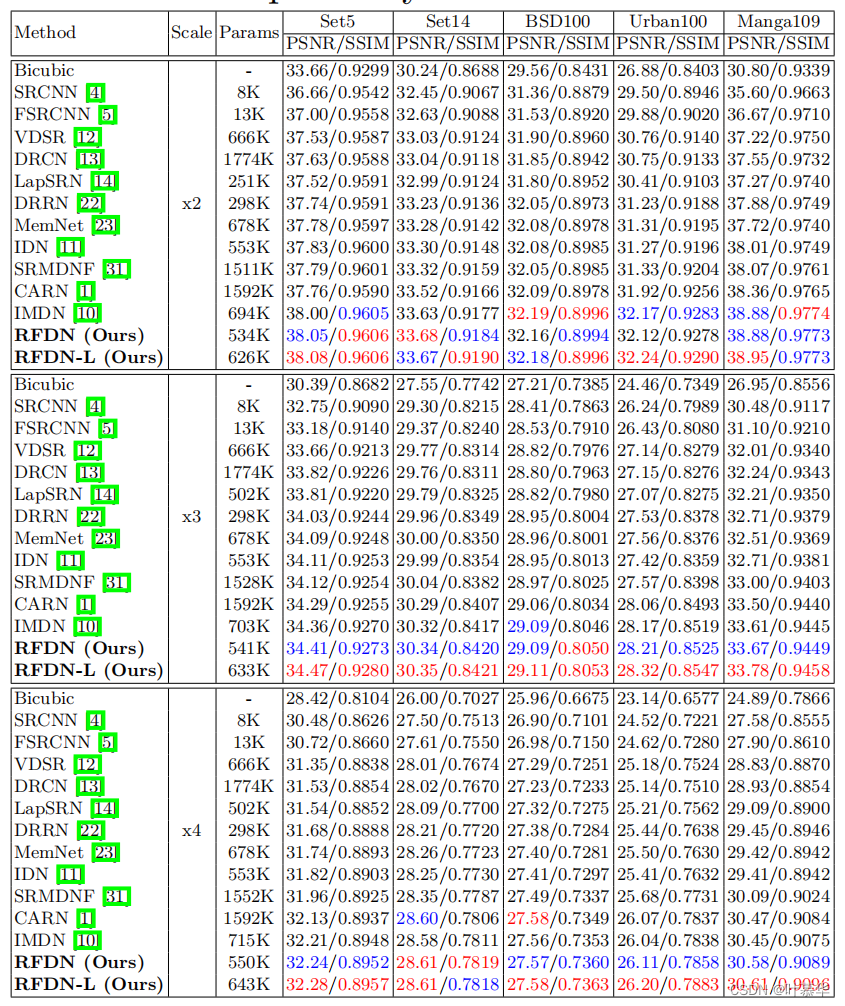
阅读RFDN-Residual Feature Distillation Network for Lightweight Image Super-Resolution
Residual Feature Distillation Network for Lightweight Image Super-Resolution Abstract. 单图像超分辨率(SISR)的最新进展探索了卷积神经网络(CNN)的力量,以获得更好的性能。尽管基于cnn的方法取得了巨大的成功,但为了解决高计算量的问题,人们提出了各种快速和轻量级的CNN模型。信息蒸馏网络是目前最先进的方法

CVPR2021 General Instance Distillation for Object Detection
动机 知识蒸馏是一种有效的模型压缩方法。这种方法可以使轻量级的学生模型从较大的教师模型中获取有效知识。 目标附近的特征区域有相当多的信息,这对于知识蒸馏是有用的。然而,不仅目标附近的特征区域,而且即使是来自背景区域的判别块也有意义的知识。 为了应对检测任务中前景和背景区域的不均衡,之前的蒸馏检测方法都需要精心设计正例与负例之间的比例,并且仅蒸馏与GT相关的区域可能会忽略背景中潜在的信息区域。

知识蒸馏(Knowledge Distillation) 经典之作
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法,由于其简单,有效,在工业界被广泛应用。这一技术的理论来自于2015年Hinton发表的一篇神作: 论文链接arxiv.org Knowledge Distillation,简称KD,顾名思义,就是将已经训练好的模型包含的知识(”Knowledge”),蒸馏("Distill")提取到另一个模型里面去。今天,我们就来简单读
Knowledge Distillation from A Stronger Teacher(NeurIPS 2022)论文解读
paper:Knowledge Distillation from A Stronger Teacher official implementation:https://github.com/hunto/dist_kd 前言 知识蒸馏通过将教师的知识传递给学生来增强学生模型的性能,我们自然会想到,是否教师的性能越强,蒸馏后学生的性能也会进一步提升?为了了解如何成为一个更强的教师模型以及它们

PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient阅读笔记
(一) Title 论文地址:https://arxiv.org/abs/2207.02039 (二) Summary 研究背景: 在目标检测任务中KD发挥着压缩模型的作用,但是对于heterogeneous detectors(异构)之间的蒸馏仍然lack of study。 本文的主要工作 来自异构教师的FPN feature能够帮助具有不同detect head和label ass
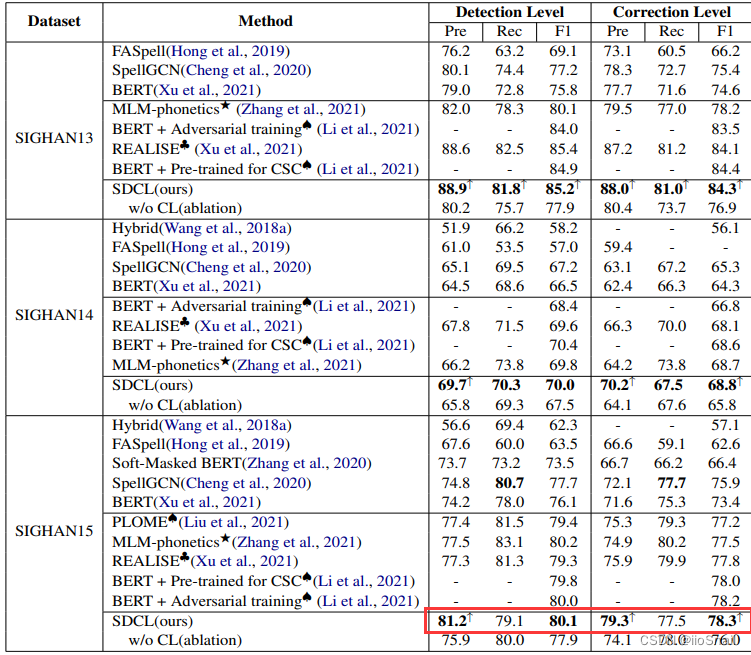
【论文笔记】SDCL: Self-Distillation Contrastive Learning for Chinese Spell Checking
文章目录 论文信息Abstract1. Introduction2. Methodology2.1 The Main Model2.2 Contrastive Loss2.3 Implementation Details(Hyperparameters) 3. Experiments代码实现个人总结值得借鉴的地方 论文信息 论文地址:https://arxiv.org/pdf/
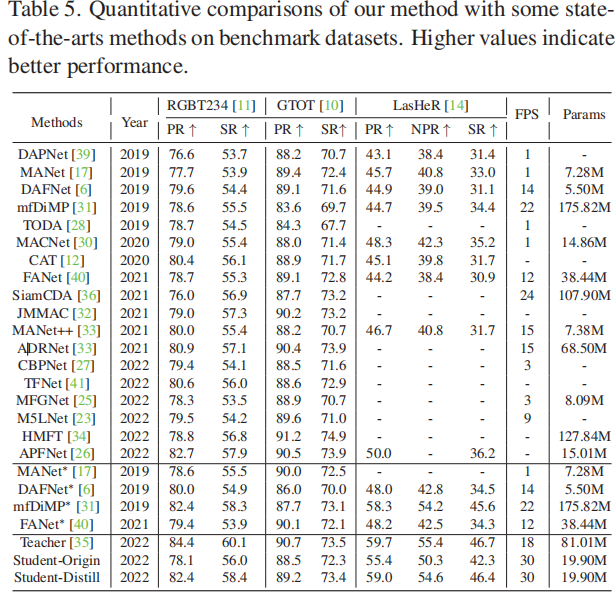
Efficient RGB-T Tracking via Cross-Modality Distillation
摘要 目前大多数RGB-T跟踪器采用双流结构来提取单个RGB和热红外特征,并采用复杂的融合策略来实现多模态特征融合,这需要大量的参数,阻碍了它们的实际应用。另一方面,一个紧凑的RGB-T跟踪器可能具有计算效率,但由于特征表示性能的减弱,会遇到不可忽视的性能下降。为了解决这种情况,提出了一种跨模态蒸馏框架来弥合紧凑跟踪器和强大跟踪器之间的性能差距。本文提出了一种特定公共特征蒸馏模块,将模态公共
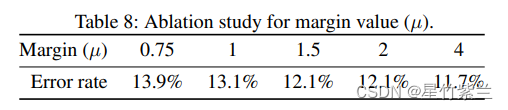
【知识蒸馏2018】Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
【知识蒸馏2018】Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons 论文: https://arxiv.org/pdf/1811.03233.pdf 目录 一 主要思想:二 问题来源及推导模型:1. 问题及推导2.补充: 三 实验结果: 一 主要思想:
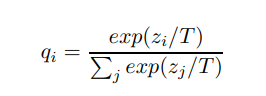
简单了解Knowledge distillation知识蒸馏
论文:Distilling the Knowledge in a Neural Network 一、什么是知识蒸馏,为什么要使用知识蒸馏? 知识蒸馏就是把一个大模型的知识迁移到小模型上,因为大模型虽然能达到较高的精度,但它的训练往往需要大量的资源和时间,小模型的训练需要的资源少,训练速度快,但它的精度往往不如大模型。显然,不是每个人都拥有足够的资源训练大模型,为了使用更少的资源、更快的速度,并且精

使用DMAD(Learning Efficient GANs using Differentiable Masks and co-Attention Distillation)训练并测试自己的数据
论文:Learning Efficient GANs using Differentiable Masks and co-Attention Distillation 代码:DMAD 最近在做毕设,翻GitHub时看到原作者的repo,就尝试拿来跑一下自己的数据。结果一上来就报错(除了一些通用性比较高的repo外,很多都会遇到这种问题),解决了半天的环境问题,遇到下面这个错
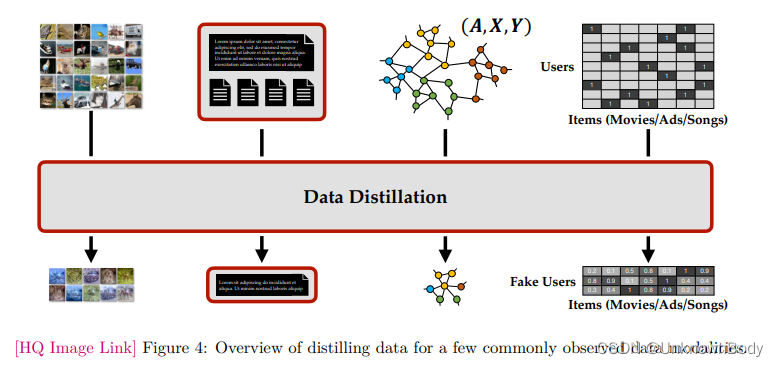
Data Distillation: A Survey
本文是蒸馏学习综述系列的第二篇文章,Data Distillation: A Survey的一个翻译 数据蒸馏:综述 摘要1 引言2 数据蒸馏框架2.1 元模型匹配的数据蒸馏2.2 梯度匹配的数据蒸馏2.3 轨迹匹配的数据蒸馏2.4 分布匹配的数据蒸馏2.5 因式分解的数据蒸馏 3 数据模态4 应用5 挑战与未来方向 摘要 深度学习的普及导致了大量海量、多样的数据集的管理。尽管在