本文主要是介绍Knowledge Distillation from A Stronger Teacher(NeurIPS 2022)论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paper:Knowledge Distillation from A Stronger Teacher
official implementation:https://github.com/hunto/dist_kd
前言
知识蒸馏通过将教师的知识传递给学生来增强学生模型的性能,我们自然会想到,是否教师的性能越强,蒸馏后学生的性能也会进一步提升?为了了解如何成为一个更强的教师模型以及它们对KD的影响,作者系统地研究了设计和训练深度神经网络的流行策略,并发现:
- 除了扩大模型的尺寸,还可以通过更先进的训练策略例如标签平滑和数据增强来得到一个更强的教师模型。但是,当教师模型更强时,学生模型在KD上的性能会下降,甚至比不用KD从头训练更差。
- 当使用更强的训练策略时,教师和学生模型之间的差异通常会变得更大,这种情况下通过KL散度精确地恢复预测非常有难度并有可能导致KD的失败。
- 保持教师和学生之间的预测关系relation of predictions是有效的,当知识从教师传递到学生,我们真正关心的是教师的偏好(relative ranks of predictions)而不是精确的值。教师和学生之间的预测相关性可以放宽基于KL散度的精确匹配,从而提取本质的关系。
本文的创新点
- 本文提出用皮尔森相关系数(Pearson correlation coefficient)作为一种新的匹配方法代替KL散度。
- 除了预测向量中的类间关系,由于不同实例相对每个类别有不同的相似性,本文还提出蒸馏类内关系,以进一步提高性能。
- 整合上面两点,本文提出了一种新的蒸馏方法,称为DIST,可以从更强的教师中得到更好的蒸馏效果。
方法介绍
如图2所示,作者分别用策略B1和B2训练ResNet-18和ResNet-50,然后用KL散度比较它们的差异,得到如下观察结果:
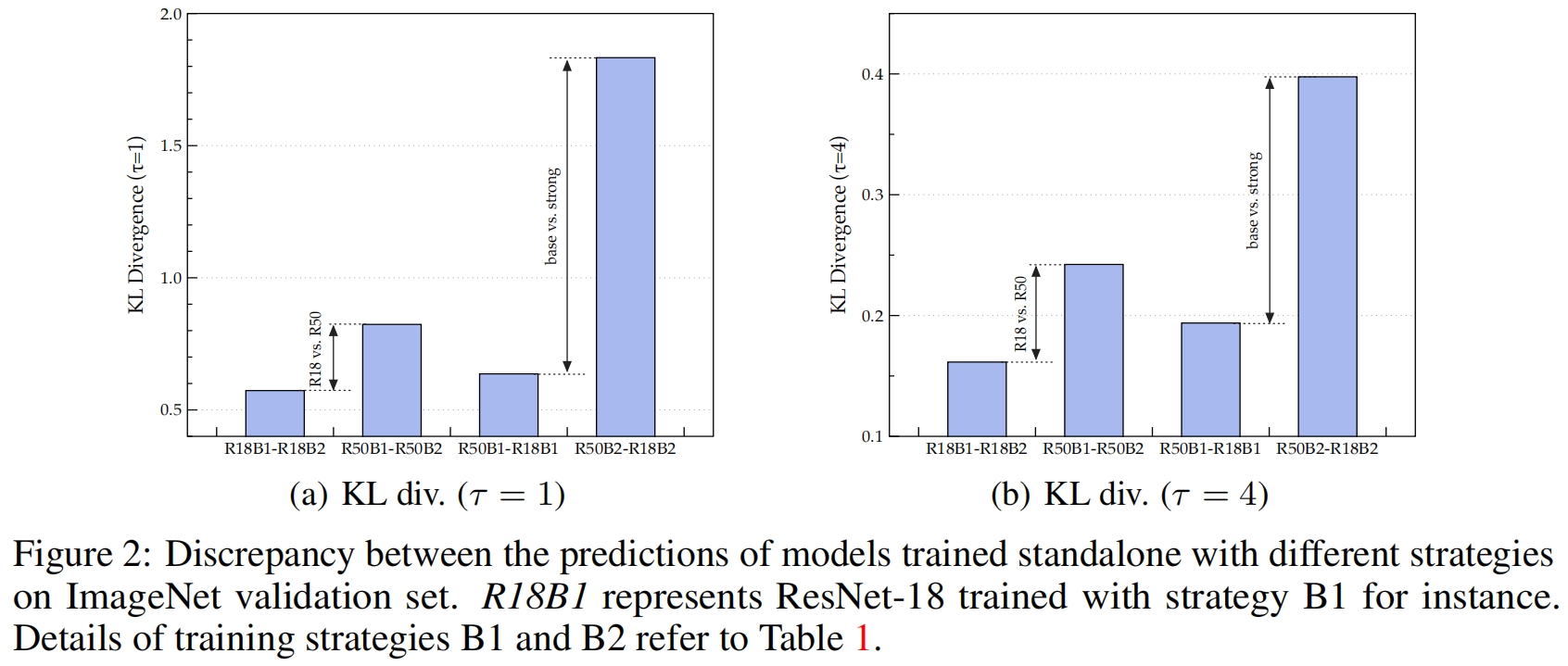
- 与ResNet-50相比,ResNet-18的输出没有太大变化,这意味着表征能力限制了学生的表现,而且随着差异变大,学生要准确匹配教师的产出非常有挑战性。
- 当用更强的策略训练时,教师和学生之间的差异会变大。这说明,当我们采用具有较强训练策略的KD时,KD损失和分类损失之间的偏差会更大,从而干扰学生的训练。
由于教师和学生之间的差异变大,基于KL散度的精确匹配难度也变大了,因此直觉上方法是开发一种更宽松的方式来匹配学生和教师的预测输出。
Relaxed match with relations
预测得分表示教师对所有类别的confidence,为了让教师和学生之间以一种更宽松的方式匹配,我们需要考虑教师模型的输出中我们真正关心的是什么。实际上在推理过程中,我们真正关心的是它们的relation,即预测的相对顺序,而不是具体的概率值。
对于某个距离度量 \(d(\cdot,\cdot)\),\(\mathbb{R}^{C}\times \mathbb{R}^{C}\to \mathbb{R}^{
+}\),精确匹配可以表述为只有 \(a=b\) 时 \(d(a,b)=0\)。
对于一个宽松的匹配,我们可以引入额外的映射 \(\phi(\cdot)\) 和 \(\psi(\cdot)\),从而有
![]()
这里 \(d(a,b)=0\) 不要求 \(a\) 和 \(b\) 一定相等,但是映射 \(\phi(\cdot)\) 和 \(\psi(\cdot)\) 应该是isotone的且不影响预测向量的语义信息和推理结果。一个简单有效的选择是正线性变换
![]()
其中 \(m_{1},m_{2},n_{1},n_{2}\) 都是常量且 \(m_{1}\times m_{2}>0\)。为了满足式(5),我们可以使用广泛使用的皮尔森距离
![]()
其中 \(\rho_{p}(u,v)\) 是两个随机变量 \(u,v\) 的皮尔森相关系数

其中 \(Conv(u,v)\) 是 \(u,v\) 的协方差,\(\bar{u}\) 和 \(Std(u)\) 分别是 \(u\) 的均值和标准差。
这样我们就可以把relation定义为correlation,原始KD中的精确匹配条件可以放宽,并通过最大化线性相关来保持教师和学生在每个实例的概率分布的relation,称之为类间关系inter-class relation。对于每对预测向量 \(\mathbf{Y}^{(s)}_{i,:}\) 和 \(\mathbf{Y}^{(t)}_{i,:}\),类间损失如下

Better distillation with intre-relations
除了类间关系,即每个实例中多个类别之间的关系。多个实例在一个类别中的预测得分也是有用的信息。这个分数反映了多个实例与一个类别的相似性。比如,假设我们有三张分别包含猫、狗、飞机的图像,它们在猫这个类别上的预测分数分别为 \(e,f,g\),一般来说它们的关系应该是 \(e>f>g\),这种知识也可以传递给学生。即使是属于同一类别的不同图像,语义相似性的类内方差也是有用的信息,它表明教师的偏好,对于这个类别哪一张图像的置信度更高。
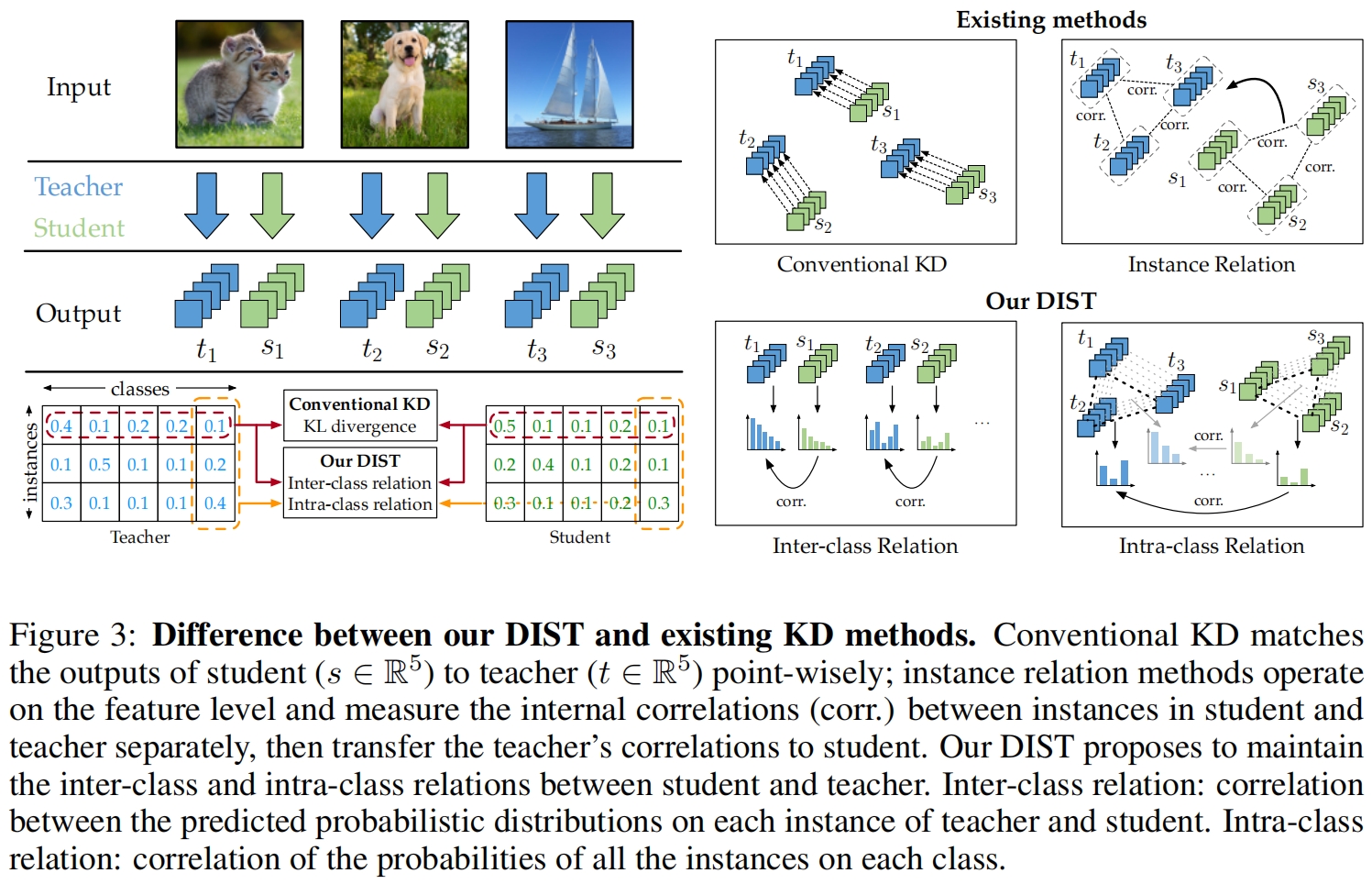
定义预测矩阵 \(\mathbf{Y}^{(s)}\) 和 \(\mathbf{Y}^{(t)}\),每一行表示为 \(\mathbf{Y}^{(s)}_{i,:}\) 和 \(\mathbf{Y}^{(t)}_{i,:}\),那么如图3所示,上述的类间关系就是沿行最大化相关性,相反,这里的类内关系就是沿列最大化相关性
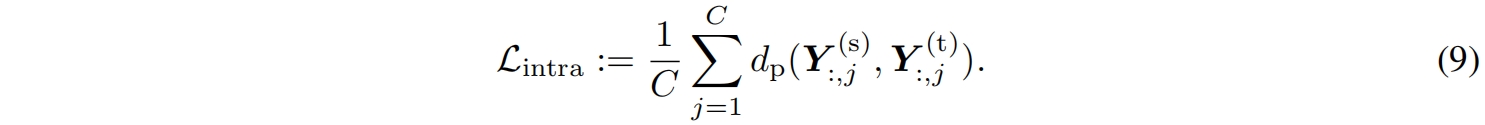
最终完整的损失函数包括分类损失、类间蒸馏损失、类内蒸馏损失
![]()
实现代码

实验结果
如表2所示,在ImageNet上本文的方法大大优于之前的蒸馏方法,并且本文的方法是基于logits的,计算成本和原始KD相似,但效果却要比其它精心设计的基于feature和基于relation的方法更好。

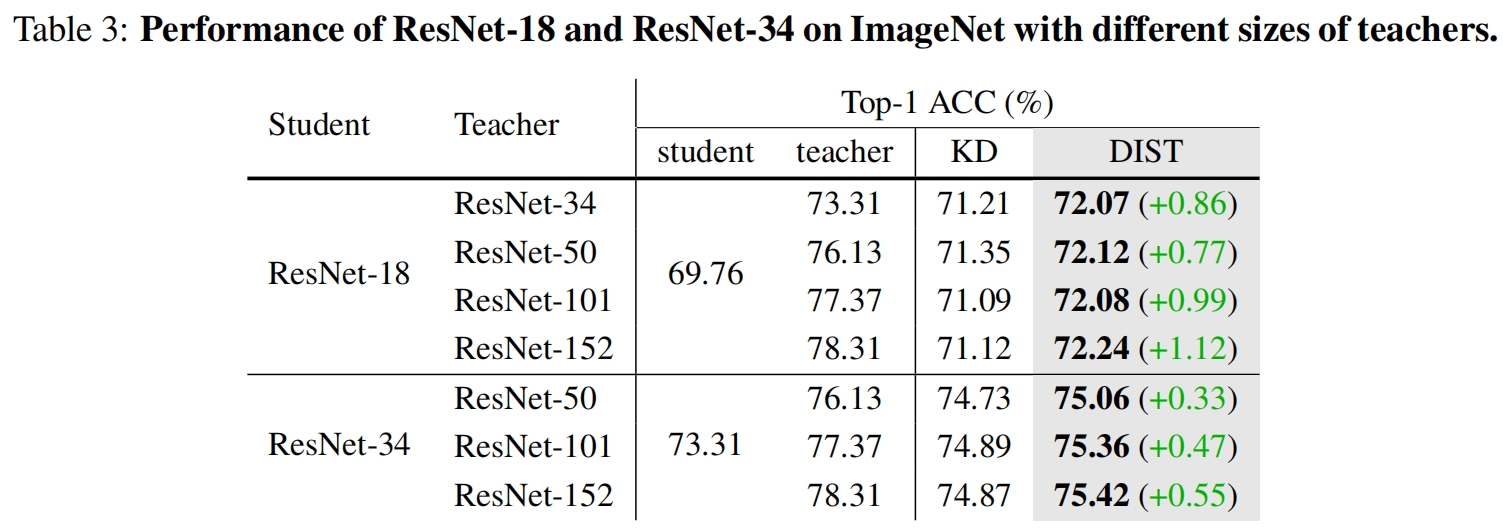
由于更强的教师来自于更大尺寸的模型和更强的训练策略。这里首先比较在不同尺寸的resnet上本文提出的DIST与原始KD的效果。如表3所示,当教师变得更大时,学生ResNet-18的性能甚至比ResNet-50当教师时更差。而本文提出的DIST,则随着教师的尺寸越来越大,学生的性能越来越强。
如表4所示,在更强的训练策略下,本文提出的DIST在不同结构的学生模型上,效果都优于其它蒸馏方法。

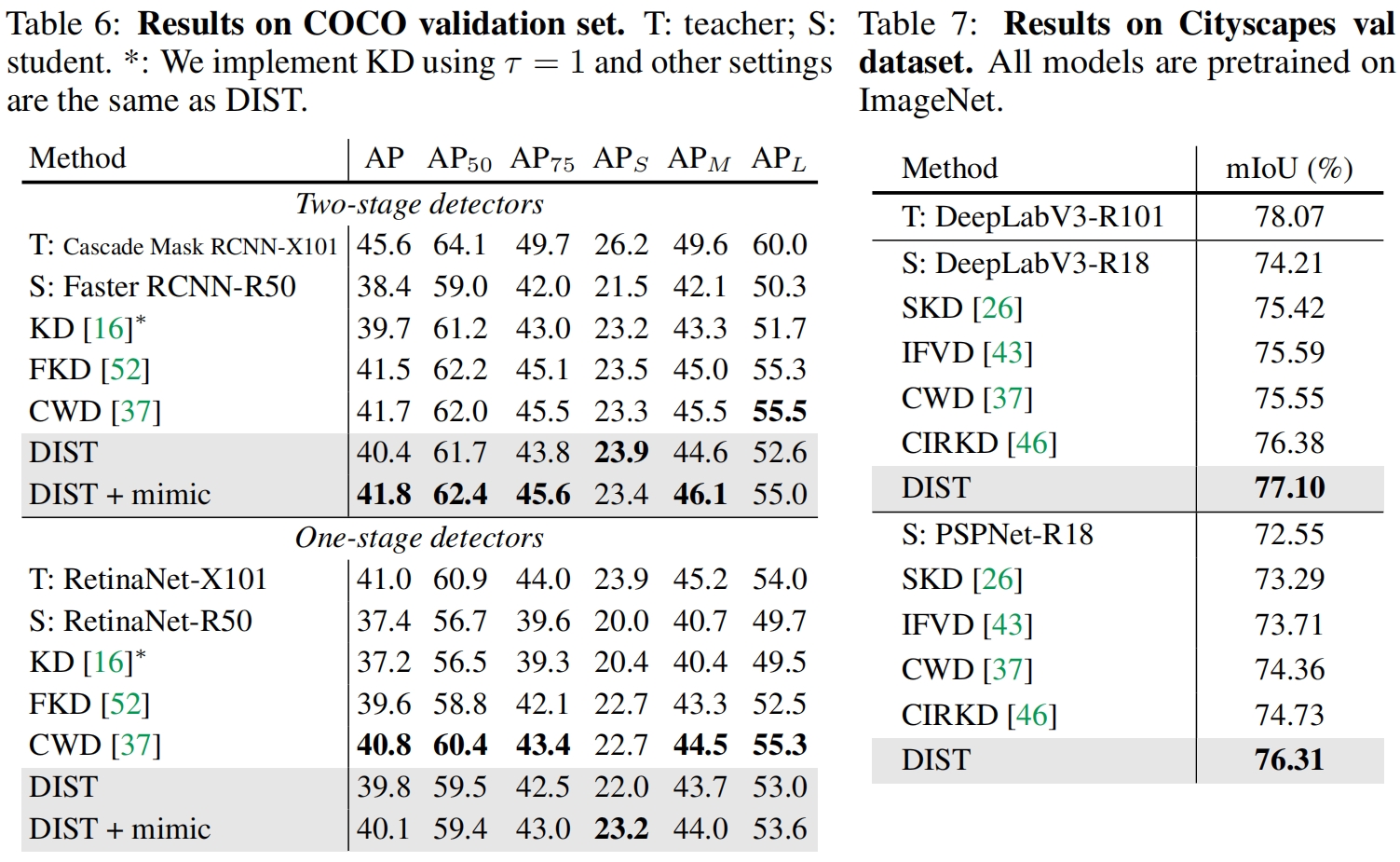
在下游任务如目标检测和语义分割中,如表6、7所示,DIST的效果也都更好。
这篇关于Knowledge Distillation from A Stronger Teacher(NeurIPS 2022)论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








