neurips专题
Generalized Focal Loss:Focal loss魔改以及预测框概率分布,保涨点 | NeurIPS 2020
为了高效地学习准确的预测框及其分布,论文对Focal loss进行拓展,提出了能够优化连续值目标的Generalized Focal loss,包含Quality Focal loss和Distribution Focal loss两种具体形式。QFL用于学习更好的分类分数和定位质量的联合表示,DFL通过对预测框位置进行general分布建模来提供更多的信息以及准确的预测。从实验结果来看,GF
![[NeurIPS-23] GOHA: Generalizable One-shot 3D Neural Head Avatar](https://img-blog.csdnimg.cn/direct/09eaf0f8743d4a339a2e61f83194003b.png)
[NeurIPS-23] GOHA: Generalizable One-shot 3D Neural Head Avatar
[pdf | proj | code] 本文提出一种基于单图的可驱动虚拟人像重建框架。基于3DMM给粗重建、驱动结果,基于神经辐射场给细粒度平滑结果。 方法 给定源图片I_s和目标图片I_t,希望生成图片I_o具有源图片ID和目标图片表情位姿。本文提出三个分支: 规范分支(canonical branch):生成具有标准表情和位姿的粗3D人像;外观分支(appearance br
The Clock and the Pizza [NeurIPS 2023 oral]
本篇文章发表于NeurIPS 2023 (oral),作者来自于MIT。 文章链接:https://arxiv.org/abs/2306.17844 一、概述 目前,多模态大语言模型的出现为人工智能带来新一轮发展,相关理论也逐渐从纸面走向现实,影响着人们日常生活的方方面面。在享受着技术提供给我们福利的同时,人们也在不断尝试去探索这些模型/算法背后的原理究竟是什么,不禁思考这样几个

计算机常见的六大会议介绍:CVPR/ICCV/ECCV;NeurIPS/ICML/ICLR
计算机常见的六大会议介绍:CVPR/ICCV/ECCV;NeurIPS/ICML/ICLR CVPR、ICCV和ECCV是计算机视觉领域顶级的三个国际会议,而NeurIPS、ICML和ICLR则是机器学习领域最具影响力的三个国际会议。下面是它们的详细介绍: 计算机视觉领域 CVPR (Computer Vision and Pattern Recognition) 主办方:IEEE频率:
NeurIPS 2019 | 17篇论文,详解图的机器学习趋势
来源:深度学习自然语言处理 本文约7400字,建议阅读10+分钟 可高深,也可接地气。 本文来自德国Fraunhofer协会IAIS研究所的研究科学家Michael Galkin,他的研究课题主要是把知识图结合到对话AI中。 必须承认,图的机器学习(Machine Learning on Graphs)已经成为各大AI顶会的热门话题,NeurIPS 当然也不会例外。 在NeurIPS 20

NeurIPS 2023 时空预测论文总结
NeurIPS 2023 时空预测论文总结 欢迎关注公众号“时空探索之旅” 本文总结了NeurIPS 2023 有关时空预测(spatial-temporal forecasting,STF)的文章,包含稀疏性、大模型,气象预测,扩散模型等工作。 1. Sparse Graph Learning from Spatiotemporal Time Series 作者:Andrea Cini,

NeurIPS 2023 Spotlight | VoxDet:基于3D体素表征学习的新颖实例检测器
本文提出基于3D体素表征学习的新颖实例检测器VoxDet。给定目标实例的多视图,VoxDet建立该实例的三维体素表征。在更加杂乱的测试图片上,VoxDet使用体素匹配算法检测目标实例。实验表明,VoxDet中的三维体素表征与匹配比多种二维特征与匹配要更鲁棒、准确与高效。本文已收录于NeurIPS 2023并被选为SpotLight。 论文题目: VoxDet: Voxel Le
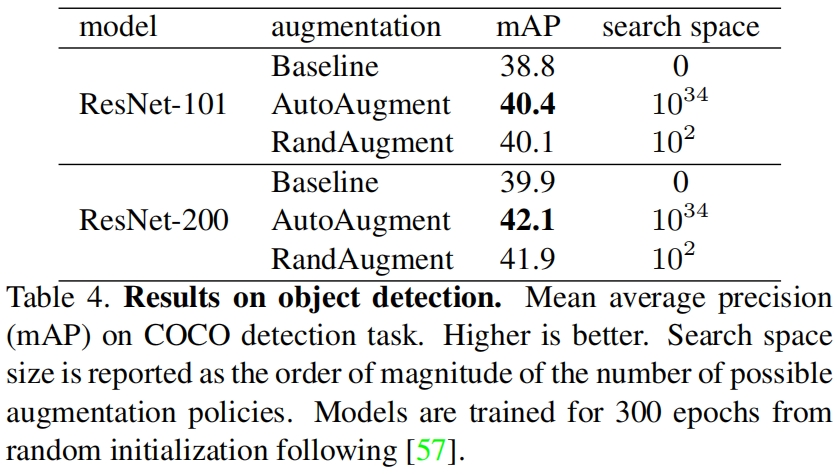
RandAugment(NeurIPS 2020)论文速读
paper:RandAugment: Practical automated data augmentation with a reduced search space third-party implementation:https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/transforms/auto_

NeurIPS 2020-TinyNets-轻量级模型 | Model Rubik‘s Cube: Twisting Resolution, Depth and Width for TinyNets
Mark一下华为诺亚实验室的最新工作 论文地址:https://arxiv.org/pdf/2010.14819.pdf Github地址:https://github.com/huawei-noah/CV-Backbones/tree/main/tinynet Abstract: 为了获得出色的深度神经网络体系结构,在EfficientNets中精心设计了一系列技术。同时扩大分辨率

分层强化学习 Data-Efficient Hierarchical Reinforcement Learning(HIRO)(NeurIPS 2018)
\quad 分层的思想在今年已经延伸到机器学习的各个领域中去,包括NLP 以及很多representataion learning。 \quad 近些年,分层强化学习被看作更加复杂环境下的强化学习算法,其主要思想就是将一个大的问题进行分解,思路是依靠一个上层的policy去将整个任务进行分解,然后利用下层的policy去逐步执行。 Code: https://github.com/te

NeurIPS已成为了AI人才招聘的最大盛会,连Hinton都“应聘”过
在一周前美国举行的年度最热门的人工智能大会NeurIPS 2023上,有超过1万名世界顶尖AI研究人员聚集在此。 而除了研究员之外,中国科技公司和华尔街公司是其中最突出的参会者,他们都背负着抢夺AI人才的任务。 大模型人才最受欢迎 随着今年ChatGPT和生成式AI的火爆,大模型相关的AI博士生比以往任何时候都更受欢迎。 许多AI博士生都希望能获得谷歌或OpenAI等AI公司的工作机会,并
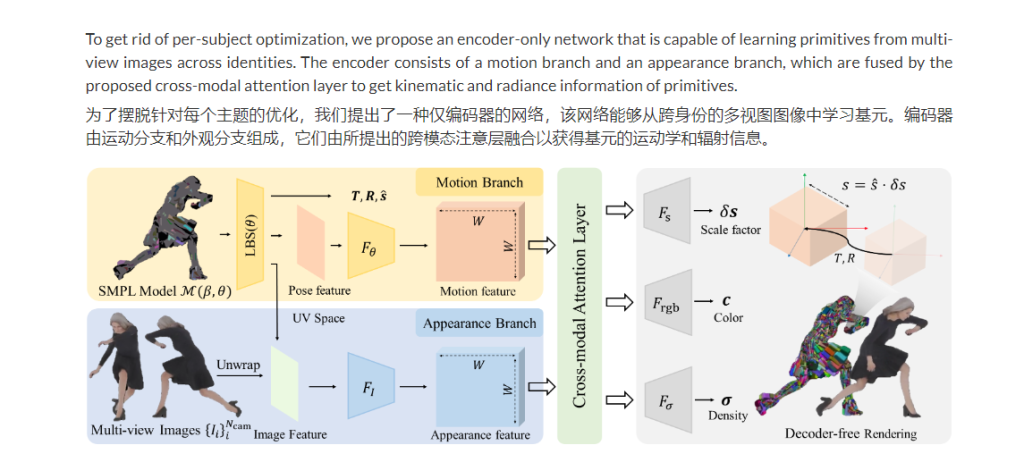
PrimDiffusion:3D 人类生成的体积基元扩散模型NeurIPS 2023
NeurIPS2023 ,这是一种用于 3D 人体生成的体积基元扩散模型,可通过离体拓扑实现明确的姿势、视图和形状控制。 PrimDiffusion 对一组紧凑地代表 3D 人体的基元执行扩散和去噪过程。这种生成建模可以实现明确的姿势、视图和形状控制,并能够在明确定义的深度中对离体拓扑进行建模。此外,他们的方法可以推广到新的姿势,无需后处理,并支持下游以人为中心的任务,如 3D 纹理传输。 将
PrimDiffusion:3D 人类生成的体积基元扩散模型NeurIPS 2023
NeurIPS2023 ,这是一种用于 3D 人体生成的体积基元扩散模型,可通过离体拓扑实现明确的姿势、视图和形状控制。 PrimDiffusion 对一组紧凑地代表 3D 人体的基元执行扩散和去噪过程。这种生成建模可以实现明确的姿势、视图和形状控制,并能够在明确定义的深度中对离体拓扑进行建模。此外,他们的方法可以推广到新的姿势,无需后处理,并支持下游以人为中心的任务,如 3D 纹理传输。 将
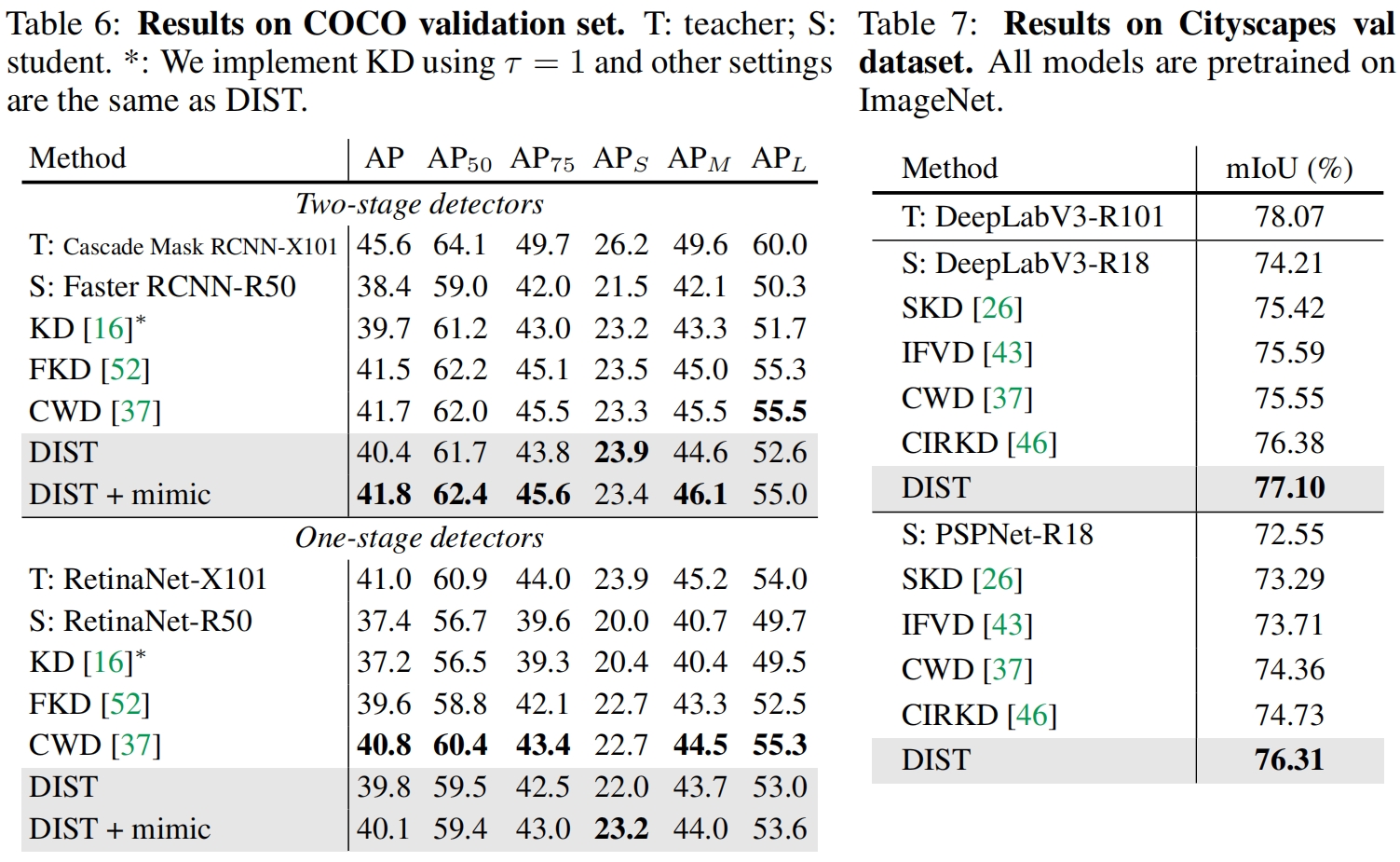
Knowledge Distillation from A Stronger Teacher(NeurIPS 2022)论文解读
paper:Knowledge Distillation from A Stronger Teacher official implementation:https://github.com/hunto/dist_kd 前言 知识蒸馏通过将教师的知识传递给学生来增强学生模型的性能,我们自然会想到,是否教师的性能越强,蒸馏后学生的性能也会进一步提升?为了了解如何成为一个更强的教师模型以及它们

论文分享 | NeurIPS 2023 使用大语言模型进行超参数优化
文章目录 一、前言二、主要内容1. 引言2. 方法3. 结果 三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 Foundation Models for Decision Making Workshop at NeurIPS 2023:Using Large Language Models for Hyper
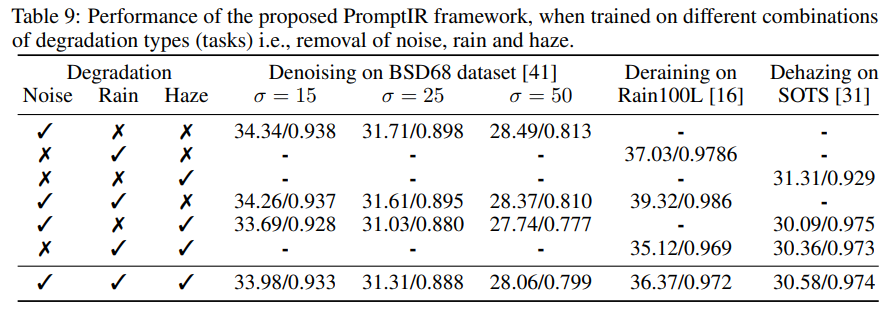
【NeurIPS 2023】PromptIR: Prompting for All-in-One Blind Image Restoration
PromptIR: Prompting for All-in-One Blind Image Restoration, NeurIPS 2023 论文:https://arxiv.org/abs/2306.13090 代码:https://github.com/va1shn9v/promptir 解读:即插即用系列 | PromptIR:MBZUAI提出一种基于Prompt的全能图像恢复网络

【半监督图像分割 2022 NeurIPS】GTA-Seg
文章目录 【半监督图像分割 2022 NeurIPS】GTA-Seg摘要1. 简介2. 相关工作2.1 语义分割2.2 半监督2.3 半监督分割 3. 方法3.1 准备工作3.2 温文尔雅的助教 4. 实验4.1 数据集4.2 实现细节4.3 实验结果4.4 分析 5. 总结 【半监督图像分割 2022 NeurIPS】GTA-Seg 论文题目:Semi-Supervised
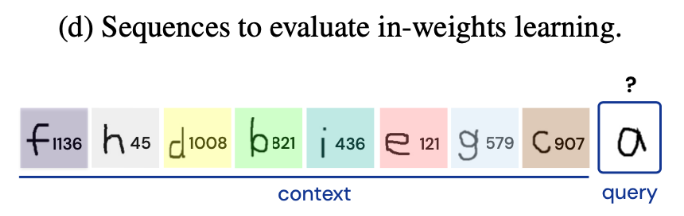
NeurIPS 2022|DeepMind最新研究:大模型背后的ICL可能与数据分布密切相关
NeurIPS 2022|DeepMind最新研究:大模型背后的ICL可能与数据分布密切相关 大模型自然语言处理机器学习 传统的文本语言模型倾向于两阶段的训练模式,即首先在大规模语料库上进行预训练,然后在目标下游任务上进行微调,这种方式会受数据标注质量和过拟合等多方面的影响。最近兴起并流行的大型语言模型(large language models,LLMs)已经克服了这类问题,并且会展现出惊人

NeurIPS 2022 | 序列(推荐)模型分布外泛化:因果视角与求解
©作者 | 杨晨晓 单位 | 上海交通大学 论文题目: Towards Out-of-Distribution Sequential Event Prediction: A Causal Treatment 作者信息: 杨晨晓(上海交大),吴齐天(上海交大),Qingsong Wen(阿里达摩院),Zhiqiang Zhou(阿里达摩院),Liang Sun(阿里达摩院),严骏驰(上海交大

NeurIPS 2023 | 基于多模态统一表达的跨模态泛化
©PaperWeekly 原创 · 作者 | 夏炎 学校 | 浙江大学 研究方向 | 多模态 论文标题: Achieving Cross Modal Generalization with Multimodal Unified Representation 模型&代码地址: https://github.com/haihuangcode/CMG 在本文中,我们提出了跨模态泛化任务,旨
读不懂NeurIPS 2018的艰深论文?我们已经为你划好了重点
AI的火爆,让今天在加拿大蒙特利尔开幕的第32届神经信息处理系统大会(NeurIPS 2018),就成为了各国研究组织和企业刷存在感的香饽饽。 有多火呢? 据说,今年的参会人数有9000人,大会门票在11分钟内被一抢而空。官方自己都吐槽,只比碧昂丝演唱会卖的慢一点。 之所以一票难求,还是因为到场的学术界、产业界大佬太多。谷歌、亚马逊、Facebook、微软是不会缺席的,华为
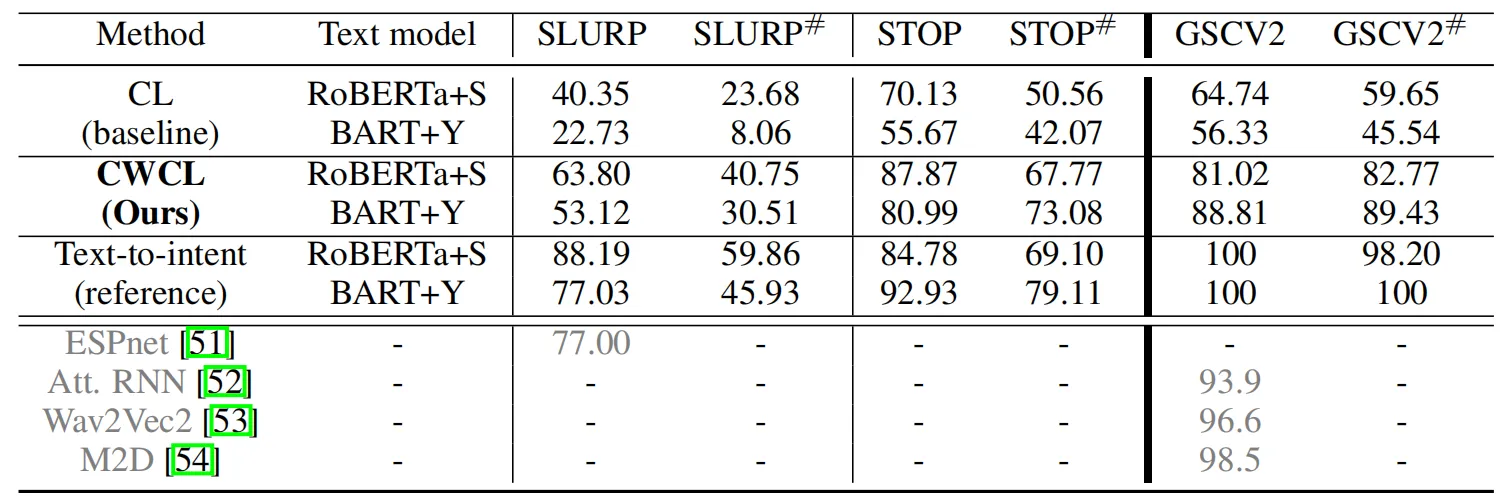
NeurIPS 2023 | 对比损失深度刨析!三星研究院提出全新连续性对比损失CMCL
论文名称: CWCL: Cross-Modal Transfer with Continuously Weighted Contrastive Loss 论文链接: https://arxiv.org/abs/2309.14580 一些通过大规模预训练的跨模态表示对齐模型(例如CLIP和LiT)往往能够展示出非常强大的跨领域zero-shot能力,这种能力是我们通向通用人工智能的重
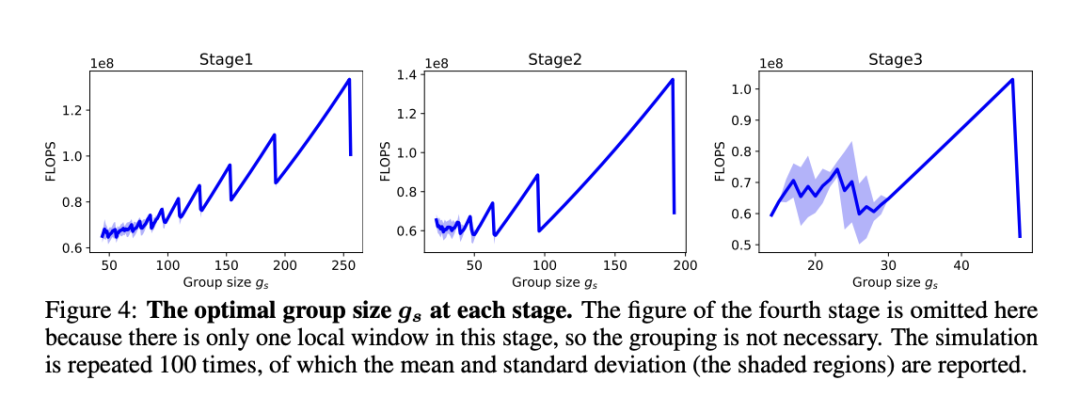
NeurIPS 2022 | 改进何恺明的MAE!GreenMIM:将Swin与MAE结合,训练速度大大提升!
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 点击进入—> CV 微信技术交流群 杨净 发自 凹非寺转载自:量子位(QbitAI) 自何恺明MAE横空出世以来,MIM(Masked Image Modeling)这一自监督预训练表征越来越引发关注。 但与此同时, 研究人员也不得不思考它的局限性。 MAE论文中只尝试了使用原版ViT架构作为编码器,而表现更好的分层设计结构
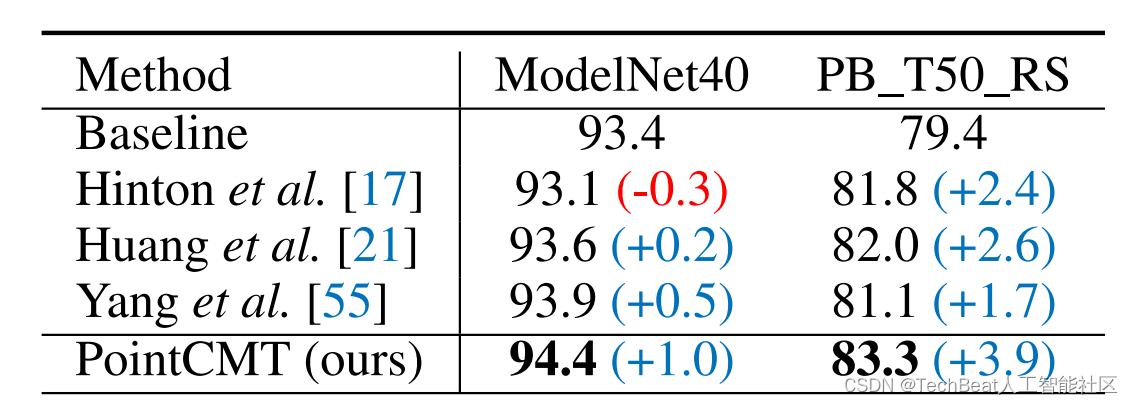
NeurIPS 2022 | 涨点神器!利用图像辅助三维点云分析的训练新范式
原文链接:https://www.techbeat.net/article-info?id=4212 作者:颜旭 点云作为一种基本的三维表征形式,活跃在自动驾驶、机器人感知等多种任务上。尽管三维点云分析在近年来取得了良好的发展,但由于点云其本身往往是无序、无纹理以及稀疏的存在,故基于单模态的点云分析正逐渐走向瓶颈。为了获得具备更强辨识能力的表征,有些方法引入了额外的二维图像信息(例如纹理、
![[论文阅读] 2019 NeurIPS - Generative modeling by estimating gradients of the data distribution](https://zhangruiyuan.oss-cn-hangzhou.aliyuncs.com/picGo/images/image-20211215211224364.png)
[论文阅读] 2019 NeurIPS - Generative modeling by estimating gradients of the data distribution
📑[阅读笔记]Generative modeling by estimating gradients of the data distribution 本文创造性的使用积分函数来学习训练数据的分布,并提出sliced score matching解决了传统score matching中存在的性能问题。 🙋♂️张同学 📧zhangruiyuan@zju.edu.cn 有问题请联系我~
【NeurIPS 2023】多模态联合视频生成大模型CoDi
Diffusion Models视频生成-博客汇总 前言:目前视频生成的大部分工作都是只能生成无声音的视频,距离真正可用的视频还有不小的差距。CoDi提出了一种并行多模态生成的大模型,可以同时生成带有音频的视频,距离真正的视频生成更近了一步。相信在不远的将来,可以AI生成的模型可以无缝平替抖音等平台的短视频。这篇博客详细解读一下这篇论文《Any-to-Any Generation via