本文主要是介绍[NeurIPS-23] GOHA: Generalizable One-shot 3D Neural Head Avatar,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

[pdf | proj | code]
- 本文提出一种基于单图的可驱动虚拟人像重建框架。
- 基于3DMM给粗重建、驱动结果,基于神经辐射场给细粒度平滑结果。
方法
- 给定源图片I_s和目标图片I_t,希望生成图片I_o具有源图片ID和目标图片表情位姿。本文提出三个分支:
- 规范分支(canonical branch):生成具有标准表情和位姿的粗3D人像;
- 外观分支(appearance branch):捕捉源图像中的外观细节;
- 表情分支(expression branch):建模并迁移目标图像的表情;
- 整体框架如下:
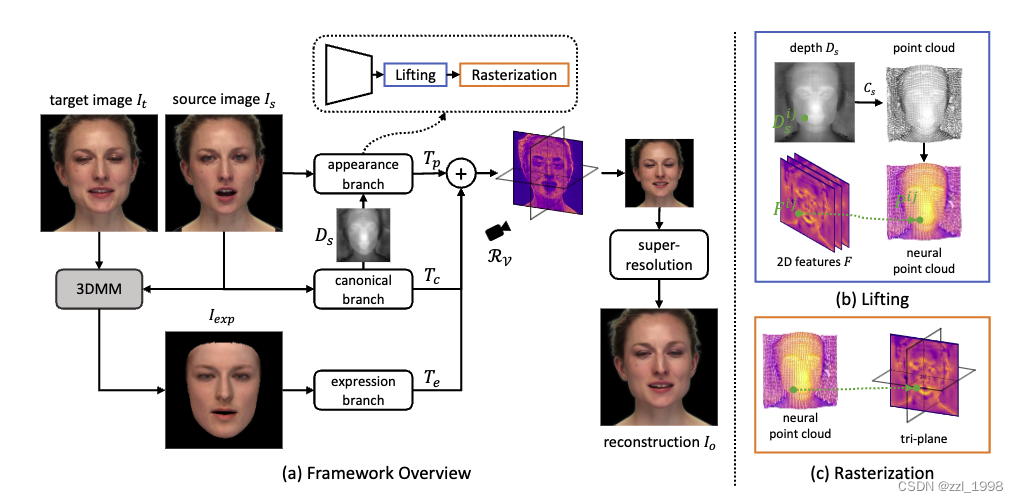
- 从消融实验上看,规范tri-plane T_c保留了源图片ID,表情tri-plane T_e保留了目标图像表情,外观tri-plane T_p保留了外观细节。

基于规范分支的粗建模
- 编码器E_c(Fine-tune SegFormer)将源图片I_s映射为tri-plane T_c。
- 通过3DMM对源图像建粗模,渲染具有标准表情和姿态的图像I_neu和掩码M_neu;
- 训练目标是3DMM粗模渲染图像I_neu和T_c渲染图像I_c的L1和LPIPS损失,具体如下:

基于外观分支的细节建模

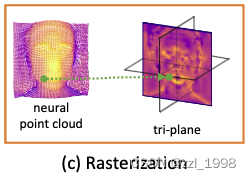
- 通过T_c拿到渲染图像对应的深度图;
- 通过编码器E_p得到源图像的2D特征,每个像素具有32维特征;
- 升维(Lifting):通过深度图将2D特征反投影至3D;
- 光栅化(Rasterization):将3D点云转换为tri-plane T_p。对T_p任意平面上的一点,计算其最近的点云,并将该点云特征赋值给平面上一点。
基于表情分支的表情建模
- 基于源图像的3DMM粗模 + 目标图像的表情,渲染得到正面视角图像I_exp。
- 通过编码器E_e,得到表情tri-plane T_e
训练
- 两阶段训练,第一阶段不包括超分模块,使用重建损失训练:
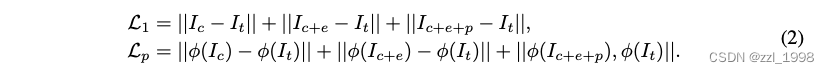
- 第二阶段冻结其他部分,fine-tune超分模块,使用第一阶段损失和对抗损失。
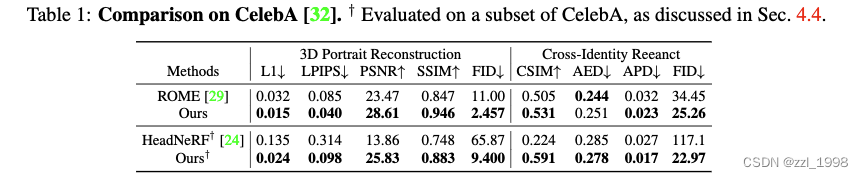
实验

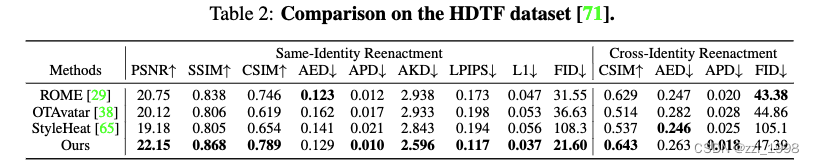



这篇关于[NeurIPS-23] GOHA: Generalizable One-shot 3D Neural Head Avatar的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






