本文主要是介绍分层强化学习 Data-Efficient Hierarchical Reinforcement Learning(HIRO)(NeurIPS 2018),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

\quad 分层的思想在今年已经延伸到机器学习的各个领域中去,包括NLP 以及很多representataion learning。
\quad 近些年,分层强化学习被看作更加复杂环境下的强化学习算法,其主要思想就是将一个大的问题进行分解,思路是依靠一个上层的policy去将整个任务进行分解,然后利用下层的policy去逐步执行。
Code: https://github.com/tensorflow/models/tree/master/research/efficient-hrl
相关资料:
总结性博文:
The Promise of Hierarchical Reinforcement Learning
中文版 强化学习遭遇瓶颈!分层RL将成为突破的希望
研究脉络:
2017年 ICML文章 提出封建网络FeUdal networks FeUdal networks for hierarchical reinforcement learning
2018年NIPS文章 HIRO Data-efficient hierarchical reinforcement learning
2018 AAAI 的文章 Learning Representations in Model-Free Hierarchical Reinforcement Learning
强化学习
HRL旨在通过分解学习的特定部分来减轻学习的复杂性。与分层强化学习的优势相比,强化学习的主要弱点可以被分解如下:
- 样本效率:数据生成常常是瓶颈,当前的RL方法的数据效率较低。使用HRL,子任务和抽象动作可以用于同一域上的不同任务(迁移学习)。
- 扩展:将传统的RL方法应用于具有大的动作或状态空间的问题是不可行的(维数灾难)。HRL的目标是将大问题分解成更小的问题(高效学习)。
- 泛化:训练有素的代理可以解决复杂的任务,但是如果我们希望他们将经验迁移到新的(甚至相似的)环境中,即使最先进的RL算法也会失败(由于过度专业化而导致脆性)。
- 抽象:状态和时间抽象可以简化问题,因为子任务可以通过RL方法(更好的知识表示)得到有效解决。
分层强化学习
强化学习问题存在严重的扩展问题。而分层强化学习(HRL)通过学习在不同程度的时间抽象上进行操作,可以解决这些问题。
为了真正理解学习算法中层次结构的必要性,并且在RL和HRL之间建立联系,我们需要记住我们要解决的问题:马尔科夫决策过程(MDP)。HRL方法学习的策略由多层组成,每层负责在不同程度的时间抽象中进行控制。事实上,HRL的关键创新是扩展可用动作集,使得代理现在不仅可以选择执行基本动作,而且还可以执行宏动作,即低级动作的序列。因此,随着时间的推移,我们必须考虑到决策时刻之间所花费的时间。幸运的是,MDP规划和学习算法可以很容易地扩展以适应HRL。


分层的优点
- 时间上的抽象(Temporal abstraction) :可以考虑持续一段时间的策略
- 迁移/重用性(Transfer/Reusability) :把大问题分解为小问题后,小问题学习到的解决方法可以迁移到别的问题之上
- 有效性/有意义(powerful/meaningful)-状态上的抽象(state abstraction) :当前的状态中与所解决问题无关的状态不会被关注

Option Framework
\quad HRL 中最著名的应该就是选项框架了。

选项是一个由三个元素构成的元组组 o = < I o , π o , β o > o=<I_o,π_o,β_o> o=<Io,πo,βo>:
- I o I_o Io:起始状态。I ⊆ S 表示option的初始状态
- π o π_o πo: π : S × A → [ 0 , 1 ] \pi:S × A → [0, 1] π:S×A→[0,1] 代表策略, 是一个基于状态空间(State space)和动作空间(Action space)的概率分布函数
- β o β_o βo:终止条件。 β:S → [0, 1] 是终止条件,β(s)表示状态 s 有β(s)的概率终止并退出当前option。

理解动作原语和选项之间的区别
\quad 一个人可以用上面的例子来理解这个框架的思想,其中选项可以概括为“去走廊”,动作(或原始选项)包括“向北、南、西或东”。选项可以被认为是在更高抽象程层次上的个体动作,因此可以抽象成技能。
底层是一个次级策略:
- 进行环境观测
- 输出动作
- 运行到终止
顶层是用于选择option的高级策略(policy-over-option):
- 进行环境观测
- 输出子策略
- 运行到终止
#################################################################
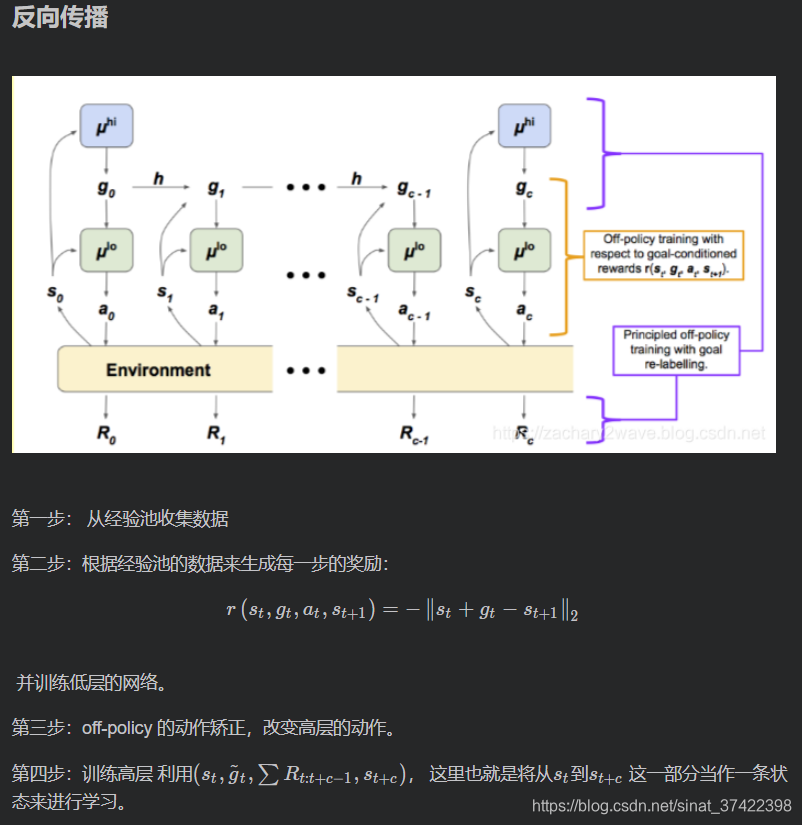
低层策略 生成的action 与环境直接交互,高层策略 在更长的时间步上进行学习。
分层强化学习也存在着3个重要的难点:
- How should one train the lower-level policy to induce semantically distinct behavior? 怎么训练低层策略来感应语义存在不同的行为。
- How should the high-level policy actions be defined?怎么定义高层策略的动作
- How should the multiple policies be trained without incurring an inordinate amount of experience collection?怎么训练多个策略,在不过度收集数据的情况下。
本文 Contribution:
1)成功地将 off-policy 应用在 HRL 的 high-level policy 中。
2)提出了一种 off-policy correction 方法,用于解决 off-policy 在HRL中出现的不稳定问题。
3)由于 off-policy 的引入,提高了 HRL 的数据利用率。
框架


high-level action (or goal) g t ∈ R d s g_t \in \mathbb{R}^{d_s} gt∈Rds
\quad higher-level policy 观察状态,并且通过公它的 policy 重采样 生成一个high-level action (or goal) g t ∈ R d s g_t \in \mathbb{R}^{d_s} gt∈Rds, g t ∽ μ h i g_t \backsim \mu^{hi} gt∽μhi (注意,这里说明子目标不是手工设置的,而是高层policy生成的抽象目标),其中 t ≡ 0 ( m o d c ) t \equiv 0(mod \ c) t≡0(mod c),或者使用一个固定的目标转移函数 g t = h ( s t − 1 , g t − 1 , s t ) g_t = h(s_{t-1},g_{t-1},s_t) gt=h(st−1,gt−1,st) 生成(最简单的情况下可以是 a pass-through function )。
\quad temporal abstraction:higher-level policy μ h i \mu^{hi} μhi 每 c 步更新一次,从而 provides temporal abstraction。



以下摘自:
强化学习 最前沿之Hierarchical reinforcement learning(一)_Dr.Zee的博客-CSDN博客


这篇关于分层强化学习 Data-Efficient Hierarchical Reinforcement Learning(HIRO)(NeurIPS 2018)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








