Cross-Modal Self-Attention Distillation for Prostate Cancer Segmentation
2023-10-28 23:04
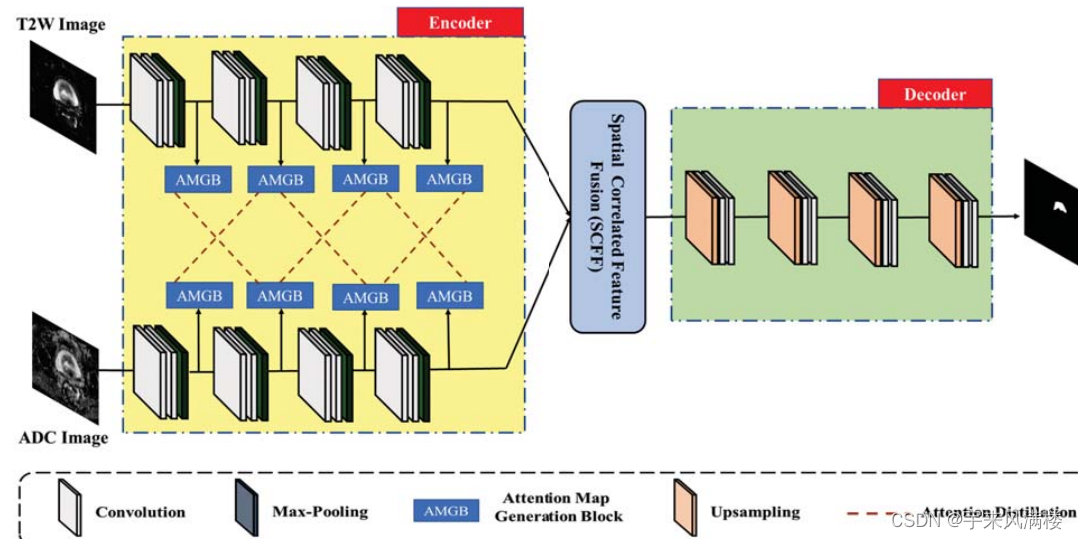
http://www.chinasem.cn/article/296556。
23002807@qq.com
相关文章

cross-plateform 跨平台应用程序-03-如果只选择一个框架,应该选择哪一个?
跨平台系列 cross-plateform 跨平台应用程序-01-概览 cross-plateform 跨平台应用程序-02-有哪些主流技术栈? cross-plateform 跨平台应用程序-03-如果只选择一个框架,应该选择哪一个? cross-plateform 跨平台应用程序-04-React Native 介绍 cross-plateform 跨平台应用程序-05-Flutte

什么是 Flash Attention
Flash Attention 是 由 Tri Dao 和 Dan Fu 等人在2022年的论文 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness 中 提出的, 论文可以从 https://arxiv.org/abs/2205.14135 页面下载,点击 View PDF 就可以下载。 下面我

图神经网络框架DGL实现Graph Attention Network (GAT)笔记
参考列表: [1]深入理解图注意力机制 [2]DGL官方学习教程一 ——基础操作&消息传递 [3]Cora数据集介绍+python读取 一、DGL实现GAT分类机器学习论文 程序摘自[1],该程序实现了利用图神经网络框架——DGL,实现图注意网络(GAT)。应用demo为对机器学习论文数据集——Cora,对论文所属类别进行分类。(下图摘自[3]) 1. 程序 Ubuntu:18.04

时序预测|变分模态分解-双向时域卷积-双向门控单元-注意力机制多变量时间序列预测VMD-BiTCN-BiGRU-Attention
时序预测|变分模态分解-双向时域卷积-双向门控单元-注意力机制多变量时间序列预测VMD-BiTCN-BiGRU-Attention 文章目录 一、基本原理1. 变分模态分解(VMD)2. 双向时域卷积(BiTCN)3. 双向门控单元(BiGRU)4. 注意力机制(Attention)总结流程 二、实验结果三、核心代码四、代码获取五、总结 时序预测|变分模态分解-双向时域卷积

经验笔记:跨站脚本攻击(Cross-Site Scripting,简称XSS)
跨站脚本攻击(Cross-Site Scripting,简称XSS)经验笔记 跨站脚本攻击(XSS:Cross-Site Scripting)是一种常见的Web应用程序安全漏洞,它允许攻击者将恶意脚本注入到看起来来自可信网站的网页上。当其他用户浏览该页面时,嵌入的脚本就会被执行,从而可能对用户的数据安全构成威胁。XSS攻击通常发生在Web应用程序未能充分过滤用户提交的数据时,导致恶意脚本得以传递

阅读笔记--Guiding Attention in End-to-End Driving Models
作者:Diego Porres1, Yi Xiao1, Gabriel Villalonga1, Alexandre Levy1, Antonio M. L ́ opez1,2 出版时间:arXiv:2405.00242v1 [cs.CV] 30 Apr 2024 这篇论文研究了如何引导基于视觉的端到端自动驾驶模型的注意力,以提高它们的驾驶质量和获得更直观的激活图。 摘 要 介绍

基于 BiLSTM+Attention 实现降雨预测多变量时序分类——明日是否降雨
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。 降雨预测作为气象学和水文学领域的重要研究课题,对于农业、城市规划、

Show,Attend and Tell: Neural Image Caption Generation with Visual Attention
简单的翻译阅读了一下 Abstract 受机器翻译和对象检测领域最新工作的启发,我们引入了一种基于注意力的模型,该模型可以自动学习描述图像的内容。我们描述了如何使用标准的反向传播技术,以确定性的方式训练模型,并通过最大化变分下界随机地训练模型。我们还通过可视化展示了模型如何能够自动学习将注视固定在显着对象上,同时在输出序列中生成相应的单词。我们通过三个基准数据集(Flickr9k,Flickr

深入理解推荐系统:推荐系统中的attention机制
什么是attention机制、在推荐模型中的应用(会介绍相关模型,AFM/DIN/DIEN/DST)和参考文献 什么是attention机制 Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,在计算attention时主要分为三步 第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
[LeetCode] 238. Product of Array Except Self
题:https://leetcode.com/problems/product-of-array-except-self/description/ 题目 Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all