本文主要是介绍A Gift from Knowledge Distillation: Fast Optimization,Network Minimization and Transfer Learning论文初读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
引言
相关工作
知识迁移
快速优化
迁移学习
方法
提出观点
数学表达式
FSP Matrix的损失
学习步骤
实验
快速优化
性能的提升
迁移学习
结论
摘要
提出了将蒸馏的知识看作成一种解决问题的流,它是在不同层之间的feature通过内积计算得到的
这个方法有三个好处:
student网络可以学的更快
student网络可以超过teacher网路的性能
可以适用于迁移学习(teacher和student属于不同的任务)
引言
- 之前的工作
KD
Fitnets(hint)
- 本文的创新点
将知识看作如何解决问题的流,所以将要蒸馏知识看作解决问题的流
流被定义为在两个不同层上的features上的关系
Gram matrix是通过计算特征间的内积得到的,可以表示输入图像的纹理信息,本文也是通过计算Gram matrix来得到流,不同点在于原本的Gram matrix是计算一个层的特征间的内积,而本文是结算不同层特征间的内积
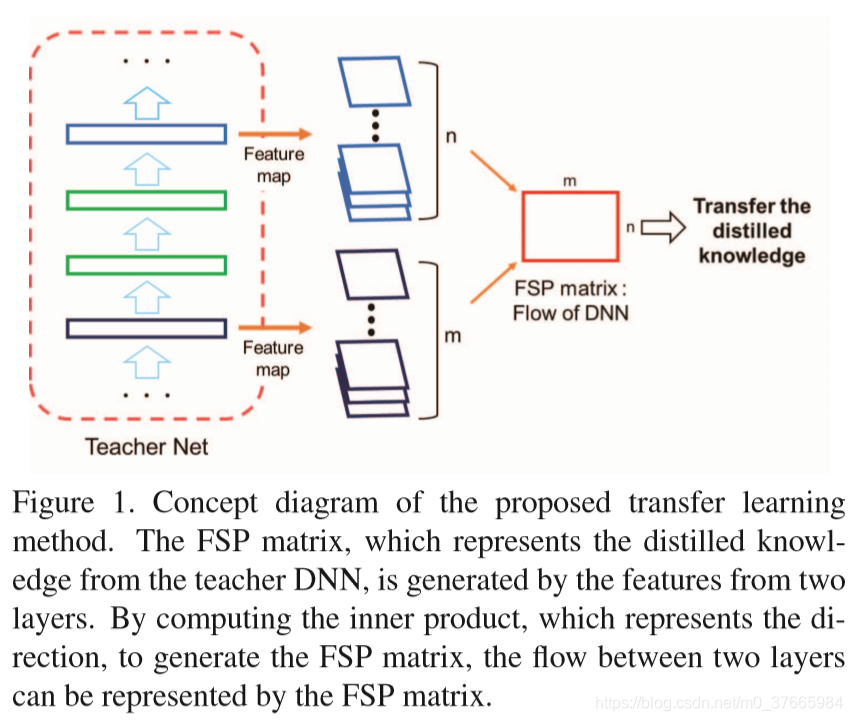
Figure1是计算FSP的概念图,FSP就是flow of solution procedure
- 本文的贡献
提出了一种好的知识蒸馏的方法
这种方法对快速优化有帮助
这种方法可以显著提升student网络的性能
这种方法适用于迁移学习
相关工作
知识迁移
KD
Fitnets
Net2Net根据teacher网络的参数,用一种函数保留的迁移方式初始化student网络的参数
快速优化
Gaussian noise初始化
Xavier初始化
还有一些初始化方法
优化的新方法
迁移学习
加载训练好的参数,微调
方法
提出观点
将输入和输出看作是问题和答案,中间层看作是解决问题的一个步骤,按照Fitnets的思路,会学习中间这个步骤,然而解决这个问题可以有很多路径,中间这个步骤的状态不一定是一种,所以Fitnets给了太多的限制,作者提出学习输入和输出的关系,而不是直接学习中间的步骤的状态
数学表达式
- 表达式
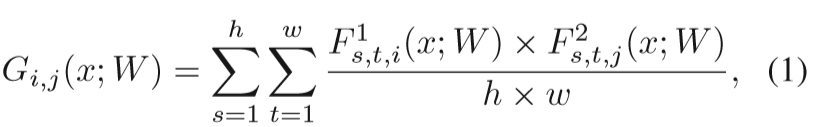
F1,F2是学生网络中两个不同层的特征
i,j表示F1和F2的通道号
这个式子其实就是不同通道的特征的相互内积
- 计算G的位置
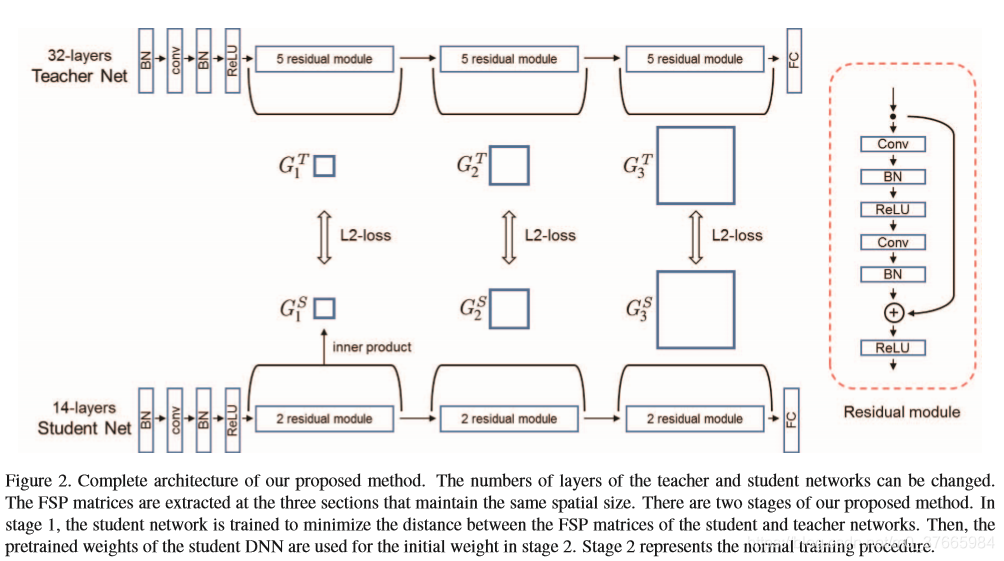
FSP Matrix的损失
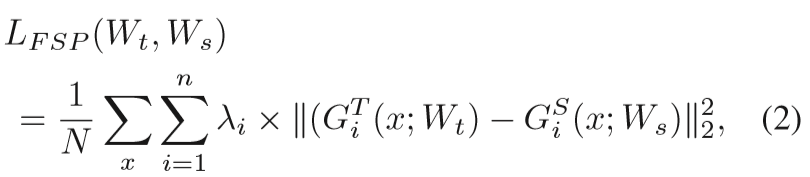
n代表在student中选择的层对数
N表示样本数量
T,S分别代表teacher和student
本论文的lamda对于所有的层对相同
学习步骤

实验
快速优化
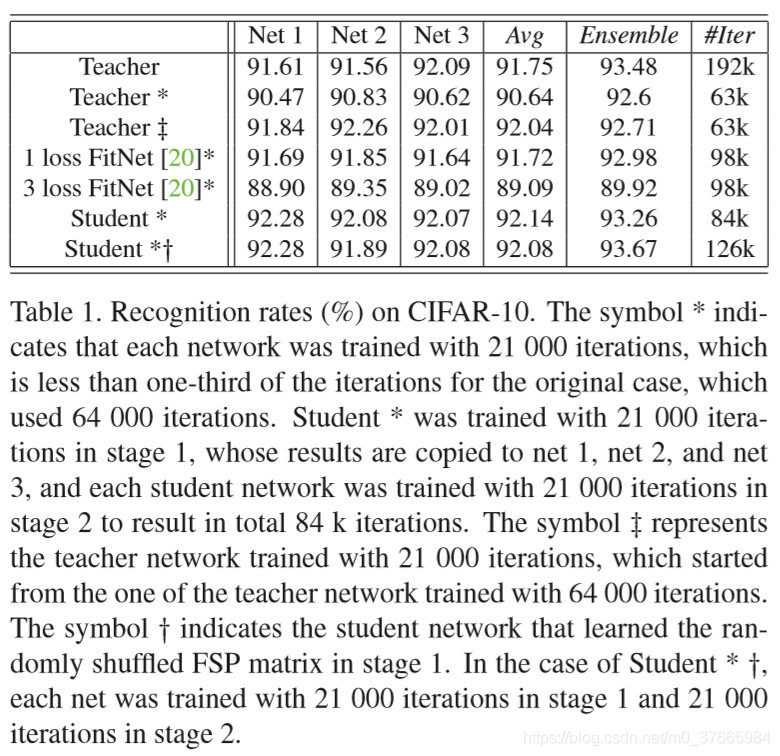
- 关于Student与FitNet的分析
由于本文提出的结构是学习一种输入和输出的关系,本文是通过FSP实现的,所以多个FSP之间可以相对独立一些,整个模块可以解耦;
而对于FitNet,假设加入三个中间层,在第二个中间层和第三个中间层不好去学习,因为要想学习好他们,首先要保证前边的一层中间层学习好,所以FitNet这种直接用特征做监督信息的方式不能解耦多个loss层,这也是为什么三层FitNet没有一层FitNet效果好的原因;
FSP想比FitNet,赋予了网络更大的自由。如果student与teacher网络有相同的中间层,那么肯定有相同的FSP,但反过来确不成立,FSP的相同并不限制中间层的具体状态。
- 关于加强多个Student的不相关性,从而提升集成模型的准确率
Table1的倒数第二行:虽然student网络的单体能力已经超过了teacher网络,但是集成的student网络确没有集成的teacher的集成效果好,这是因为多个student网络的FSP矩阵是一致的,导致他们的相关性太大
Table1的倒数第一行:作者提出了将生成的FSP矩阵的行和列进行重新洗牌,得到新的几个FSP,用新的FSP训练student得到的集成效果要好。其实这相当于将生成FSP的两个不同层的特征的通道打乱而得出的FSP,本质上没有改变信息的内容。
性能的提升
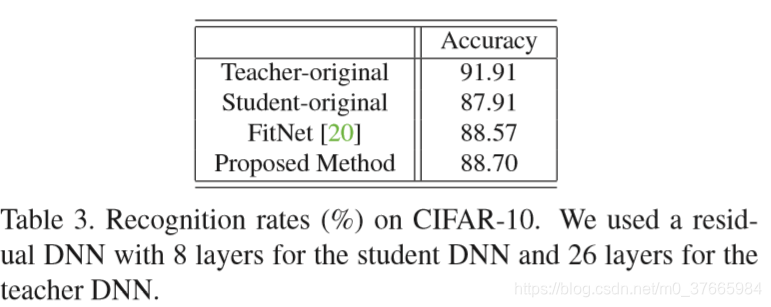
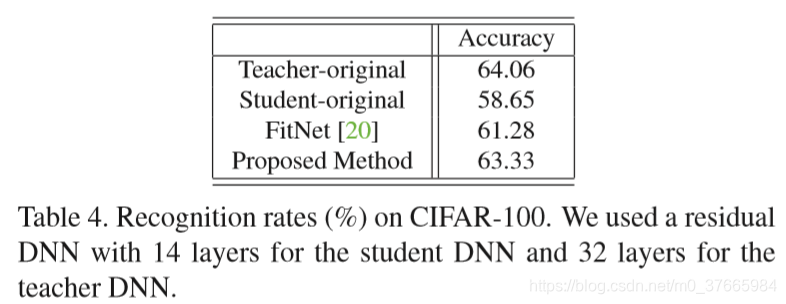
本次实验student网络的深度要小于teacher网络的深度
迁移学习
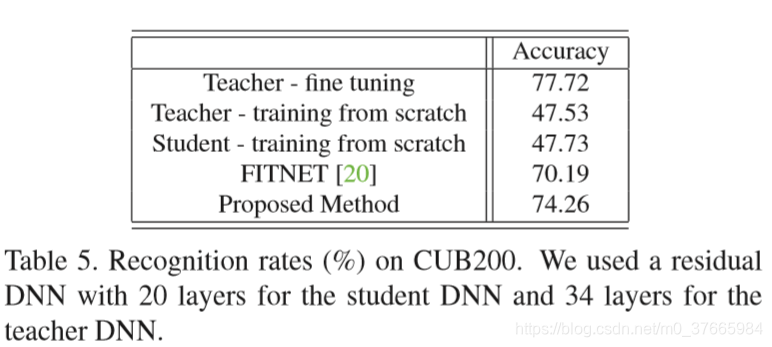
Teacher-fine tuning是在34层的网络上进行迁移学习得到的结果,Proposed Method是在20层的网络上进行FSP学习得到的结果,可以看出,已经很接近了。
结论
提出了以解决问题的流的方式来进行知识蒸馏
从三个方面验证了提出的方法的有效性
这篇关于A Gift from Knowledge Distillation: Fast Optimization,Network Minimization and Transfer Learning论文初读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

