本文主要是介绍【论文翻译】Progressive Network Grafting for Few-Shot Knowledge Distillation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Progressive Network Grafting for Few-Shot Knowledge Distillation
渐进式网络移植技术在少样本知识提取中的应用
论文地址:https://arxiv.org/pdf/2012.04915v2.pdf
代码地址:https://github.com/zju-vipa/NetGraft
摘要
Knowledge distillation has demonstrated encouraging performances in deep model compression. Most existing approaches, however, require massive labeled data to accomplish the knowledge transfer, making the model compression a cumbersome and costly process. In this paper, we investigate the practical few-shot knowledge distillation scenario, where we assume only a few samples without human annotations are available for each category. To this end, we introduce a principled dual-stage distillation scheme tailored for fewshot data. In the first step, we graft the student blocks one by one onto the teacher, and learn the parameters of the grafted block intertwined with those of the other teacher blocks. In the second step, the trained student blocks are progressively connected and then together grafted onto the teacher network, allowing the learned student blocks to adapt themselves to each other and eventually replace the teacher network. Experiments demonstrate that our approach, with only a few unlabeled samples, achieves gratifying results on CIFAR10, IFAR100, and ILSVRC-2012. On CIFAR10 and CIFAR100, our performances are even on par with those of knowledge distillation schemes that utilize the full datasets. The source code is available at https://github.com/zju-vipa/NetGraft.
知识提取在深度模型压缩中表现出很好性能。然而,大多数现有的方法都需要大量的标记数据来完成知识转移,这使得模型压缩成为一个繁琐而昂贵的过程。在本文中,我们研究了实际的少样本知识蒸馏场景,其中我们假设每个类别只有几个没有标注的样本可用。为此,我们介绍了一种为少样本数据量身定制的原则性双级蒸馏方案。在第一步中,我们将学生模块一个接一个地移植到教师模块上,并学习被移植模块与其他教师模块的参数交织在一起。在第二步中,经过训练的学生模块逐步连接,然后一起移植到教师网络上,使学习的学生模块能够相互适应,最终取代教师网络。实验表明,我们的方法仅使用少量未标记样本,在CIFAR10、IFAR100和ILSVRC-2012上取得了令人满意的结果。在CIFAR10和CIFAR100上,我们的性能甚至与利用完整数据集的知识提取方案的性能相当。源代码可在https://github.com/zju-vipa/NetGraft.
介绍
Deep neural networks have been widely applied to various computer vision tasks, such as image classification (Krizhevsky, Sutskever, and Hinton 2012; Simonyan and Zisserman 2014; Szegedy et al. 2015; He et al. 2016), semantic segmentation (Long, Shelhamer, and Darrell 2015; Chen et al. 2018; Badrinarayanan, Kendall, and Cipolla 2017), and object detection (Ren et al. 2015; Liu et al. 2016; Zhang et al. 2018). The state-of-the-art deep models, however, are often cumbersome in size and time-consuming to train and run, which precludes them from being deployed in the resource-critical scenarios such as Internet of Things (IoT).
深度神经网络已广泛应用于各种计算机视觉任务,如图像分类(Krizhevsky、Sutskever和Hinton 2012;Simonyan和Zisserman 2014;Szegedy等人2015;He等人2016);语义分割(Long、Shelhamer和Darrell 2015;Chen等人2018;Badrinarayanan、Kendall和Cipolla 2017),和目标检测(任等,2015;刘等,2016;张等,2018)。然而,最先进的深度模型通常规模庞大,训练和运行耗时,这使得它们无法部署在物联网(IoT)等资源关键场景中。
To this end, many model compression methods, such as network pruning (Li et al. 2017; Han et al. 2015; Wen et al. 2016) and knowledge distillation (Hinton, Vinyals, and Dean 2015; Romero et al. 2014), are proposed to trade off between model performance and size. Network pruning methods remove the weights of trained network based on priors and then retrain the pruned network to recover the performance of the original network. They require massive labeled data and an iterative retraining procedure, which is often time-consuming. Knowledge distillation methods (Hinton, Vinyals, and Dean 2015), on the other hand, train student networks by making them imitate the output of a given teacher. However, as student network is in many cases initialized randomly and trained from scratch, knowledge distillation approaches also rely on numerous training data to explore the large parameter space of student so as to train a well-behaved model.
为此,提出了许多模型压缩方法,如网络修剪(Li等人2017;Han等人2015;Wen等人2016)和知识蒸馏(Hinton、Vinyals和Dean 2015;Romero等人2014),以在模型性能和大小之间进行权衡。网络剪枝方法根据先验知识去除训练网络的权值,然后对剪枝后的网络进行再训练,恢复原网络的性能。它们需要大量的标记数据和迭代的再培训过程,这通常非常耗时。另一方面,知识提炼方法(Hinton、Vinyals和Dean 2015)通过让学生网络模仿给定教师的输出来训练学生网络。然而,由于学生网络在很多情况下是随机初始化的,并且是从头开始训练的,因此知识提取方法也依赖于大量的训练数据来探索学生的大参数空间,从而训练出性能良好的模型。
To alleviate data hunger in knowledge distillation, several few-shot distillation methods have been proposed to transfer knowledge from teacher to student with less dependency on the amount of data. The work of (Li et al. 2018) proposes a few-shot approach by combining network pruning and block-wise distillation to compress the teacher model. The one of (Wang et al. 2020) introduces an active mixup augmentation strategy that selects hard samples from a pool of the augmented images. The work of (Bai et al. 2019) designs a cross distillation method, combined with network pruning to reduce the layer-wise accumulated errors in the few-shot setting. In spite of the encouraging results achieved, existing methods still heavily rely on pre- or post-processing techniques, such as network pruning, which per se are unstable and error-prone.
为了缓解知识蒸馏中的数据饥饿问题,人们提出了几种少样本提取方法,以减少对数据量的依赖,将知识从教师传递给学生。Li等人(2018)的工作提出了一种结合网络剪枝和分块蒸馏来压缩教师模型的少样本方法。其中之一(Wang等人,2020年)介绍了一种主动混合增强策略,该策略从增强图像池中选择硬样本。的工作(Bai等人,2019年)设计了一种交叉蒸馏方法,与网络修剪相结合,以减少少样本设置中的分层累积误差。尽管取得了令人鼓舞的结果,但现有方法仍然严重依赖于前处理或后处理技术,例如网络修剪,其本身不稳定且容易出错。
In this paper, we propose a principled dual-stage progressive network grafting strategy for few-shot knowledge distillation, which allows us to eliminate the dependency on other techniques that are potentially fragile and hence strengthen the robustness of knowledge distillation. At the heart of our proposed approach is a block-wise “grafting” scheme, which learns the parameters of the student network by injecting them into the teacher network and optimizing them intertwined with the parameters of the teacher in a progressive fashion. Such a grafting strategy takes much better advantage of the well-trained parameters of the teacher network and therefore significantly shrinks parameter space of the student network, allowing us to training the student with much fewer samples.
在本文中,我们提出了一种原则性的双阶段渐进式网络移植策略,用于少样本知识提取,它允许我们消除对其他潜在脆弱技术的依赖,从而增强知识提取的鲁棒性。我们提出的方法的核心是一个分块“移植”方案,该方案通过将学生网络的参数注入到教师网络中,并以渐进的方式优化与教师参数交织的参数来学习学生网络的参数。这种移植策略更好地利用了教师网络经过良好训练的参数,因此显著缩小了学生网络的参数空间,使我们能够用更少的样本训练学生。
Specifically, our grafting-based distillation scheme follows a two-step procedure. In the first step, the student network is decomposed into several blocks, each of which contains fewer parameters to be optimized. We then take the block of the student to replace the corresponding one of the teacher, and learn the parameters of the student intertwined with the well-trained parameters of the teacher, enabling the knowledge transfer from the teacher to the student. In the second step, the trained student blocks are progressively connected and then grafted onto teacher network, in which the student blocks learn to adapt each other and together replace more teacher blocks. Once all the student blocks are grafted onto the teacher network, the parameter learning is accomplished. The proposed dual-stage distillation, by explicitly exploiting the pre-trained parameters and refined knowledge of the teacher, largely eases the student training process and reduces the the risk of overfitting.
具体来说,我们基于移植的蒸馏方案遵循两步程序。在第一步中,将学生网络分解为几个块,每个块包含较少的待优化参数。然后,我们将学生的模块替换为教师的相应模块,并将学生的参数与训练好的教师参数交织在一起,从而实现从教师到学生的知识转移。在第二步中,经过训练的学生模块逐步连接,然后嫁接到教师网络中,学生模块在其中学习相互适应,并一起替换更多的教师模块。一旦所有的学生模块都被移植到教师网络上,参数学习就完成了。通过明确利用预先训练的参数和教师精炼的知识,提出的双阶段蒸馏在很大程度上简化了学生的训练过程,并降低了过度拟合的风险。
In sum, our contribution is a novel grafting strategy for few-shot knowledge distillation, which removes the dependency on other brittle techniques and therefore reinforces robustness. By following a principled two-step procedure, the proposed grafting strategy dives into the off-the-shelf teacher network and utilizes the well-trained parameters of the teacher to reduce the parameter search space of the student, thus enabling the efficient training the student under the few-shot setup. With only a few unlabeled samples for each class, the proposed approach achieves truly encouraging performances on CIFAR10, CIFAR100, and ILSVRC-2012. On CIFAR10 and CIFAR100, the proposed method even yields results on par with those obtained by knowledge distillation using the full datasets.
总之,我们的贡献是一种新的移植策略,用于少样本知识蒸馏,它消除了对其他脆弱技术的依赖,因此增强了鲁棒性。通过遵循一个原则性的两步过程,所提出的移植策略潜入现成的教师网络,并利用训练有素的教师参数来减少学生的参数搜索空间,从而能够在少样本设置下有效地训练学生。由于每个类只有几个未标记的样本,该方法在CIFAR10、CIFAR100和ILSVRC-2012上取得了令人鼓舞的性能。在CIFAR10和CIFAR100上,所提出的方法甚至可以得到与使用完整数据集的知识蒸馏相同的结果。
相关工作
Few-Shot Learning. The mainstream of few-shot learning research focuses on image classification, which learns to classify using few samples per category. Two kinds of approaches are widely adopted: metric learning based method (Koch, Zemel, and Salakhutdinov 2015; Vinyals et al. 2016; Snell, Swersky, and Zemel 2017) and meta learning based one (Ravi and Larochelle 2017; Wang and Hebert 2016; Santoro et al. 2016). The difference of problem setting between few-shot distillation and few-shot classification can be summarized as two fold. Firstly, a trained teacher model is available in few-shot distillation, but few-shot classification has none. Secondly, the model is trained on various related tasks in few-shot classification, but few-shot distillation is trained on the same task.
少样本学习。少样本学习的主流研究集中在图像分类上,即在每个类别中使用很少的样本来学习分类。两种方法被广泛采用:基于度量学习的方法(Koch、Zemel和Salakhutdinov 2015;Vinyals等人2016;Snell、Swersky和Zemel 2017)和基于元学习的方法(Ravi和Larochelle 2017;Wang和Hebert 2016;Santoro等人2016)。少样本蒸馏和少样本分类在问题设置上的差异可以概括为两个方面。首先,一个经过训练的教师模型可以用于少样本蒸馏,但少样本分类没有。其次,该模型在少样本分类中针对各种相关任务进行训练,但在同一任务中对少样本蒸馏进行训练。
Knowledge Distillation. Resuing pre-trained networks has recently attracted attentions from researchers in the field (Chen et al. 2020; Yu et al. 2017). Bucilua et al (Bucilua, Caruana, and Niculescu-Mizil 2006) propose prototype knowledge distillation method, which trains a neural network using predictions from an ensemble of heterogeneous models. Hinton et al (Hinton, Vinyals, and Dean 2015) propose the knowledge distillation concept, where temperature is introduced to soften the predictions of teacher network. Following (Hinton, Vinyals, and Dean 2015), researchers pay more attention to the supervision from intermediate representations for better optimization performance (Romero et al. 2014; Wang et al. 2018; Shen et al. 2019a,b; Ye et al. 2020; Luo et al. 2020). To reduce total training time, online distillation (Yang et al. 2019; Zhang et al. 2019) is proposed to unify the training of student and teacher into one step. The above methods consume tremendous labeled data to transfer knowledge from teacher network, which significantly affects the convenience of deployment in practice. The works of (Song et al. 2019, 2020), on the other hand, focus on estimating knowledge transferability across different tasks, while those of (Yang et al. 2020b,a) explore distillation on the graph domain.
知识蒸馏。恢复预先训练的网络最近引起了该领域研究人员的关注(Chen等人,2020年;Yu等人,2017年)。Bucilua等人(Bucilua、Caruana和Niculescu-Mizil,2006)提出了原型知识提取方法,该方法使用异质模型集合的预测来训练神经网络。Hinton等人(Hinton、Vinyals和Dean 2015)提出了知识蒸馏概念,其中引入温度来软化教师网络的预测。随后(Hinton、Vinyals和Dean 2015),研究人员更加关注中间表征的监督,以获得更好的优化性能(Romero等人2014;Wang等人2018;Shen等人2019a、b;Ye等人2020;Luo等人2020)。为了缩短总训练时间,建议在线蒸馏(Yang等人2019;Zhang等人2019)将学生和教师的训练统一为一个步骤。上述方法消耗大量的标记数据从教师网络中传递知识,这严重影响了在实践中部署的便利性。另一方面,(Song等人,2019年,2020年)的工作侧重于估计不同任务之间的知识转移,而(Yang等人,2020b,a)的工作则探索了图域上的提炼。
To reduce the data dependency, data-efficient and datafree knowledge distillation are investigated. FSKD (Li et al. 2018) adopts block-wise distillation to align the pruned student and teacher, where the blocks are not optimized to imitate the final teacher predictions. Wang et al (Wang et al. 2020) combine image mixup and active learning to augment the dataset, which still requires considerable data. ZSKD (Nayak and Chakraborty 2019) adapts synthetic data impressions from teacher model to replace original training data to achieve knowledge transfer. ZSKT (Micaelli and Storkey 2019) and DFAD (Fang et al. 2019) introduce an adversarial strategy to synthesize training samples for knowledge distillation. DAFL (Chen et al. 2019) and KEGNET (Yoo et al. 2019) are proposed to synthesize images by random given labels and then student learns to imitate teacher.
为了减少数据依赖,研究了数据高效和无数据的知识提取。FSKD(Li et al.2018)采用分块蒸馏来对齐修剪后的学生和教师,其中分块未优化以模仿最终的教师预测。Wang等人(Wang等人,2020年)将图像混合和主动学习结合起来,以增强数据集,这仍然需要大量数据。ZSKD(Nayak and Chakraborty 2019)采用了教师模型中的合成数据印象,以取代原始训练数据,实现知识转移。ZSKT(Micaelli and Storkey 2019)和DFAD(Fang et al.2019)引入了一种对抗策略,以合成用于知识提炼的训练样本。DAFL(Chen et al.2019)和KEGNET(Yoo et al.2019)提出通过随机给定标签合成图像,然后学生学习模仿老师。
However, data-free methods need to learn knowledge from massive low-quality synthetic samples, which is a time-consuming procedure. In the meanwhile, data-free methods need to redesign and train a dedicated generator to synthesize massive data, where image generation is largely limited by the capacity of the generator, especially for highresolution images. Few-shot methods have higher training efficiency, which only involve few real samples during optimization, even only one sample.
然而,无数据方法需要从大量低质量的合成样本中学习知识,这是一个耗时的过程。与此同时,无数据方法需要重新设计和培训一个专用的生成器来合成海量数据,而图像生成在很大程度上受到生成器容量的限制,尤其是对于高分辨率图像。少样本方法具有更高的训练效率,在优化过程中只涉及很少的真实样本,甚至只有一个样本。
Grafting. Grafting is adopted as an opposite operation against pruning in decision tree (Webb 1997; Penttinen and Virtamo 2003), which adds new branches to the existing tree to increase the predictive performance. Li et al (Li, Tao, and Lu 2012) graft additional nodes onto the hidden layer of trained neural network for domain adaption. NGA (Hu, Delbruck, and Liu 2020) is proposed to graft front end network onto a trained network to replace its counterpart, which adapts the model to another domain. Meng et al (Meng et al. 2020) propose an adaptive weighting strategy, where filters from two networks are weighted and summed to reactivate invalid filters. Our proposed network grafting strategy replaces cumbersome teacher blocks with the corresponding lightweight student ones in a progressive manner, which aims to smoothly transfer knowledge from teacher to student.
移植。在决策树(Webb 1997;Penttinen and Virtamo 2003)中,移植被用作反对修剪的相反操作,它在现有树上添加新的分支,以提高预测性能。Li等人(Li、Tao和Lu 2012)将额外的节点移植到经过训练的神经网络的隐藏层上,以进行域自适应。NGA(Hu、Delbruck和Liu 2020)提议将前端网络移植到经过训练的网络上,以取代其对应网络,从而使模型适应另一个领域。Meng等人(Meng等人,2020年)提出了一种自适应加权策略,对来自两个网络的滤波器进行加权和求和,以重新激活无效滤波器。我们提出的网络移植策略以渐进的方式将笨重的教师模块替换为相应的轻量级学生模块,旨在顺利地将知识从教师传递到学生。
方法
Overview
The goal of few-shot knowledge distillation is to transfer knowledge from teacher network T to student network S using only few samples per category. For K-shot distillation, the optimization algorithm needs to search a large parameter space of student S with only K samples per category. Hence, it is hard to directly optimize the student network with plain knowledge distillation scheme. To accomplish this goal, we adopt network grafting strategy to decompose the student network into several blocks, each of which only contains fewer parameters to be optimized.
少样本知识提取的目标是仅使用每个类别的少量样本,将知识从教师网络T转移到学生网络S。对于K-shot蒸馏,优化算法需要搜索一个大的student S参数空间,每个类别只有K个样本。因此,很难用简单的知识蒸馏方案直接优化学生网络。为了实现这一目标,我们采用网络移植策略将学生网络分解为几个模块,每个模块只包含较少的优化参数。
Let ![]() denotes the K samples from class c. The whole training dataset for K-shot N-way distillation can be presented as
denotes the K samples from class c. The whole training dataset for K-shot N-way distillation can be presented as ![]() . The teacher network can be regarded as a composite function as T (x) = fL◦· · ·◦fl◦ · · · ◦f1(x), where fl denotes the l-th block of teacher. In the same way, the student network can be presented as S(x) = hL ◦ · · · ◦hl ◦ · · · ◦h1(x), where hl denotes the l-th block of student. The knowledge distillation can be decomposed into a series of block distillation problems, where student block hl learns to master the functions of the corresponding block in the teacher: fl.
. The teacher network can be regarded as a composite function as T (x) = fL◦· · ·◦fl◦ · · · ◦f1(x), where fl denotes the l-th block of teacher. In the same way, the student network can be presented as S(x) = hL ◦ · · · ◦hl ◦ · · · ◦h1(x), where hl denotes the l-th block of student. The knowledge distillation can be decomposed into a series of block distillation problems, where student block hl learns to master the functions of the corresponding block in the teacher: fl.
![]() 表示来自c类的k个样本。k-shot N-way蒸馏的整个训练数据集可以表示为
表示来自c类的k个样本。k-shot N-way蒸馏的整个训练数据集可以表示为![]() 。教师网络可以被视为一个复合函数,即T (x) = fL◦· · ·◦fl◦ · · · ◦f1(x),其中fl表示教师的第l个区块。同样,学生网络可以表示为S(x)=hL◦ · · · ◦hl◦ · · · ◦h1(x),其中hl表示学生的第l个区块。知识蒸馏可以分解为一系列的块提取问题,其中学生块hl学习掌握教师fl中相应块的功能。
。教师网络可以被视为一个复合函数,即T (x) = fL◦· · ·◦fl◦ · · · ◦f1(x),其中fl表示教师的第l个区块。同样,学生网络可以表示为S(x)=hL◦ · · · ◦hl◦ · · · ◦h1(x),其中hl表示学生的第l个区块。知识蒸馏可以分解为一系列的块提取问题,其中学生块hl学习掌握教师fl中相应块的功能。
To this end, we adopt a dual-stage knowledge distillation strategy, which is depicted in Figure 1. In the first stage, each block of student is grafted onto teacher network, which replaces the corresponding block of teacher. Note that only single block of the teacher is replaced with the corresponding student block each time. Then the grafted student block is trained with the distillation procedure between the grafted teacher network and the original teacher one. In the second stage, all the trained student blocks are progressively grafted on teacher network, until the whole teacher network is fully replaced by a series of student block.
为此,我们采用了一种双阶段知识提炼策略,如图1所示。在第一阶段,将每个学生块移植到教师网络上,以取代相应的教师块。请注意,每次只有教师的单个块被相应的学生块替换。然后,在移植的教师网络和原始教师网络之间,通过蒸馏过程对移植的学生块进行训练。在第二阶段,所有经过训练的学生模块都逐步移植到教师网络上,直到整个教师网络被一系列学生模块完全取代。

Figure 1: The dual-stage knowledge distillation strategy for few-shot knowledge distillation. Firstly, student network S is decomposed into several blocks:
, each of which is grafted onto teacher and then optimized by few-shot distillation between
and T . Secondly, trained blocks in the first stage:
are sequentially composed into the trained student network: S using few-shot distillation between
and T .
图1:用于少量知识蒸馏的双阶段知识提取策略。首先,将学生网络S分解为几个模块:
Block Grafting
In the setting of few samples available, it’s believed that the optimization of neural network is difficult, especially the network with massive parameters. To reduce the complexity of network optimization, the student network is decomposed into a series of blocks, each of which contains fewer parameters. For the training of block module, two alternative solutions are available, as shown in Figure 2.
在样本数较少的情况下,神经网络的优化比较困难,尤其是参数较多的网络。为了降低网络优化的复杂度,将学生网络分解为一系列块,每个块包含较少的参数。对于block模块的训练,有两种可选解决方案,如图2所示。
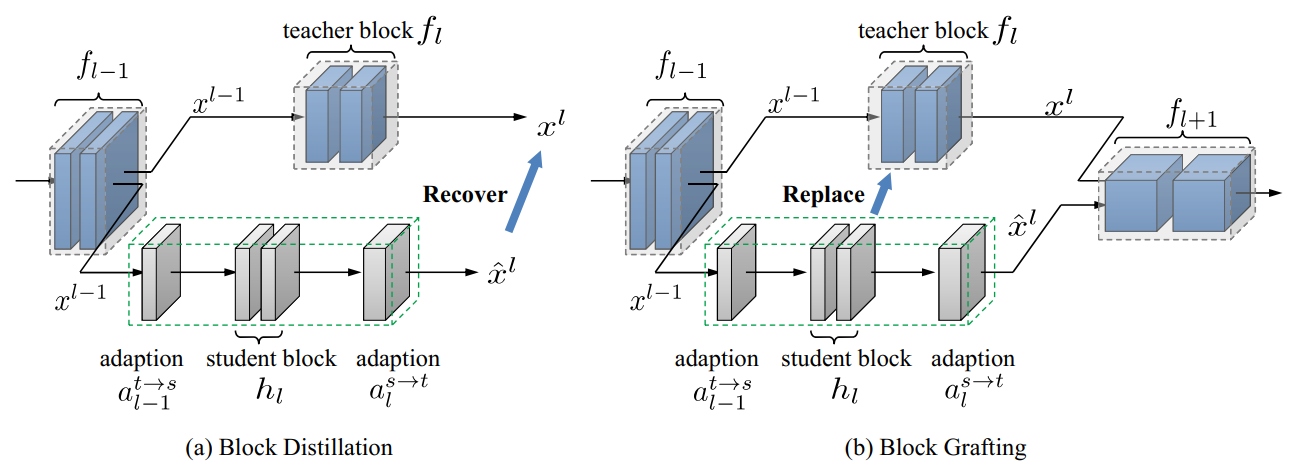
Figure 2: Two alternative block-wise distillation solutions. (a) Block distillation tries to recover the output of teacher block using a lightweight student block. (b) Block grafting is trained to replace teacher block with student one to recover the final prediction of teacher. Note that only the modules in green dashed box are updated during optimization.
图2:两种可选的分段蒸馏溶液。(a) 块蒸馏尝试使用一个轻量级的学生块恢复教师块的输出。(b) 块移植训练是用学生块代替教师块,恢复教师的最终预测。请注意,在优化过程中,仅更新绿色虚线框中的模块。
For the first solution, the input and output of the corresponding block from teacher network are used to train the student block, as depicted in Figure 2 (a). This solution aims to imitate and recover the output of teacher block originally. However, due to model compression, the student block is generally much smaller than the teacher one. In other word, the capacity of student block is smaller than teacher block. There is some noise in teacher block output, which is trivial for final classification decision. Learning without information selection may hurt the performance of the student.
对于第一种解决方案,教师网络中相应模块的输入和输出用于训练学生模块,如图2(a)所示。该解决方案旨在模拟并恢复教师模块的输出。然而,由于模型压缩,学生块通常比教师块小得多。换句话说,学生区的容量比教师区小。教师模块输出中存在一定的噪声,这对于最终的分类决策来说是微不足道的。没有信息选择的学习可能会损害学生的表现。
For the second solution, the student block is grafted on teacher network, as shown in Figure 2 (b). The grafted teacher network can be denoted as:
对于第二种解决方案,学生块被移植到教师网络上,如图2(b)所示。移植的教师网络可以表示为:
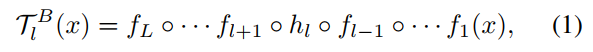
where the l-th block of student: hl replaces the teacher block fl. Note that the block number of student needs to be equal to the teacher one, but the inner structure of the hl and the fl can be different. The grafted teacher ![]() is trained to recover the predictions of the original teacher T and only the parameters of hl are optimized. This solution encourages the block hl to focus on the knowledge, which is vital for final classification predictions. It effectively avoids the problem in the first solution, where the block only learns the original outputs of teacher block but not the function of the block in the whole network.
is trained to recover the predictions of the original teacher T and only the parameters of hl are optimized. This solution encourages the block hl to focus on the knowledge, which is vital for final classification predictions. It effectively avoids the problem in the first solution, where the block only learns the original outputs of teacher block but not the function of the block in the whole network.
其中,第l个学生块:hl取代了教师区fl。请注意,学生区编号需要等于教师区编号,但hl和fl的内部结构可能不同。对移植教师![]() 进行训练,恢复原教师T的预测,只优化hl的参数。这种解决方案鼓励块hl专注于知识,这对最终分类预测至关重要。它有效地避免了第一种解决方案中的问题,即模块只学习教师模块的原始输出,而不学习模块在整个网络中的功能。
进行训练,恢复原教师T的预测,只优化hl的参数。这种解决方案鼓励块hl专注于知识,这对最终分类预测至关重要。它有效地避免了第一种解决方案中的问题,即模块只学习教师模块的原始输出,而不学习模块在整个网络中的功能。
Due to the channel dimension difference between student block and teacher one, we introduce adaption module to align the channel dimension difference. The adaption module can be categorized into two kinds: adaption module for the dimension transform from teacher block to student one ![]() and the one from student to teacher
and the one from student to teacher ![]() . Combined with adaption modules, the wrapped scion
. Combined with adaption modules, the wrapped scion ![]() can be written as:
can be written as:
由于学生区和教师区的通道尺寸差异,我们引入了自适应模块来调整通道尺寸差异。自适应模块可分为两类:用于从教师模块到学生模块![]() 和从学生模块到教师模块
和从学生模块到教师模块![]() 的维度转换的自适应模块。结合适应模块,wrapped分支
的维度转换的自适应模块。结合适应模块,wrapped分支 ![]() 可以写为:
可以写为:
![]()
where xl denotes the output of l-th block from network. The adaption module is implemented with 1 × 1 convolution operation. It achieves a linear recombination of input features across channel dimension and doesn’t change the size of receptive field, which is designed to align features between student and teacher. There are two special cases to be clarified:
其中,xl表示来自网络的第l个块的输出。自适应模块采用1×1卷积运算实现。它实现了输入特征在通道维度上的线性重组,并且不改变感受野的大小,感受野的设计目的是在学生和教师之间对齐特征。有两种特殊情况需要澄清:
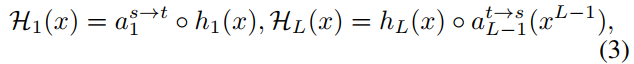
where H1(x) and HL(x) denote the first wrapped scion and the last one, respectively. Combining Eq.1, Eq.2 and Eq.3, the final grafted teacher can be written as:
其中H1(x)和HL(x)分别表示第一个wrapped分支和最后一个wrapped分支。结合Eq.1、Eq.2和Eq.3,最终的移植老师可以写成:
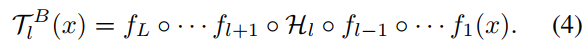
Progressive Network Grafting
A series of trained student blocks can be obtained from the above section, each of which can make decision with the blocks of teacher network. However, these trained blocks are not trained to work with each other. In this section, we adopt a network grafting strategy to progressively increase the student blocks in the grafted teacher network and reduce the dependency of the original teacher.
从上述部分可以获得一系列经过训练的学生模块,每个模块都可以利用教师网络的模块进行决策。然而,这些经过训练的模块并没有经过相互协作的训练。在本节中,我们采用网络移植策略,逐步增加移植教师网络中的学生块,并减少对原始教师的依赖。
On the base of ![]() , the trained blocks:
, the trained blocks:![]() are sequentially grafted onto T , as shown in Figure 1. The grafted teacher for network grafting can be denoted as:
are sequentially grafted onto T , as shown in Figure 1. The grafted teacher for network grafting can be denoted as:
在![]() 的基础上,经过训练的块:
的基础上,经过训练的块:![]() 被顺序地移植到T上,如图1所示。用于网络移植的移植教师可以表示为:
被顺序地移植到T上,如图1所示。用于网络移植的移植教师可以表示为:
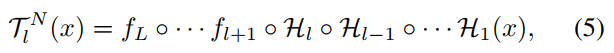
where![]() . During network grafting, a sequence of models:
. During network grafting, a sequence of models: ![]() are optimized. Finally,
are optimized. Finally, ![]() is obtained, which connects all student blocks and forms a complete network. However,
is obtained, which connects all student blocks and forms a complete network. However, ![]() is still different from original student network S(x). TLN(x) is composed of a series of Hl, but S(x) is composed of hl. Compared to hl, Hl contains additional adaption module:
is still different from original student network S(x). TLN(x) is composed of a series of Hl, but S(x) is composed of hl. Compared to hl, Hl contains additional adaption module: ![]() , which means the obtained
, which means the obtained ![]() has more parameters than S(x).
has more parameters than S(x).
其中![]() 。在网络嫁接过程中,优化了一系列模型:
。在网络嫁接过程中,优化了一系列模型:![]() 。最后得到TLN(x),它连接所有学生模块,形成一个完整的网络。然而,
。最后得到TLN(x),它连接所有学生模块,形成一个完整的网络。然而,![]() 仍然不同于最初的学生网络S(x)。
仍然不同于最初的学生网络S(x)。![]() 由一系列Hl组成,而S(x)由Hl组成。与hl相比,hl包含额外的自适应模块:
由一系列Hl组成,而S(x)由Hl组成。与hl相比,hl包含额外的自适应模块:![]() ,这意味着获得的
,这意味着获得的![]() 比S(x)有更多的参数。
比S(x)有更多的参数。
Thanks to the linearity of adaption module, the parameters of adaption module can be merged into the convolution layer in the next block hl+1 without increasing any parameters. For ![]() ,
, ![]() can be merged into
can be merged into ![]() . We denote
. We denote ![]()
![]() . Then, TLN(x) can be transformed into the following form:
. Then, TLN(x) can be transformed into the following form:
由于自适应模块的线性,自适应模块的参数可以在下一块hl+1中合并到卷积层,而无需增加任何参数。对于![]() ,
,![]() 可以合并到
可以合并到![]() 中。我们表示
中。我们表示![]()
![]() 。然后,TLN(x)可以转换为以下形式:
。然后,TLN(x)可以转换为以下形式:
![]()
Optimization
The scale of logits from different network architectures may have a large gap, which may result in optimization difficulty. To this end, we propose an L2 loss function on normalized logits for knowledge transfer between teacher block fl and student block hl as follow:
不同网络架构的Logit规模可能存在较大差距,这可能导致优化困难。为此,我们提出了一个规范化逻辑上的二语损失函数,用于教师模块fl和学生模块hl之间的知识转移,如下所示:
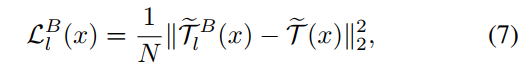
where ![]() . In the optimization of block grafting, only the wrapped student block Hl is learnable and updated with the gradient
. In the optimization of block grafting, only the wrapped student block Hl is learnable and updated with the gradient ![]() , where Θl denotes the parameters of Hl. For network grafting, a similar distillation is adopted,
, where Θl denotes the parameters of Hl. For network grafting, a similar distillation is adopted,
式中![]() 。在块移植优化中,只有 wrapped的学生块Hl是可学习的,并用梯度
。在块移植优化中,只有 wrapped的学生块Hl是可学习的,并用梯度![]() 更新,其中Θl表示Hl的参数。对于网络嫁接,采用了类似的蒸馏,
更新,其中Θl表示Hl的参数。对于网络嫁接,采用了类似的蒸馏,
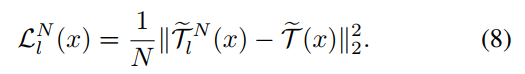
The difference to block grafting is that a sequence of wrapped student blocks: ![]() need to be optimized, for the l-th step of network grafting. The complete algorithm for our proposed approach can be summarized as Algorithm 1.
need to be optimized, for the l-th step of network grafting. The complete algorithm for our proposed approach can be summarized as Algorithm 1.
与块移植不同的是,对于网络移植的第l步,需要优化包裹的学生块序列:![]() 。我们提出的方法的完整算法可以总结为算法1。
。我们提出的方法的完整算法可以总结为算法1。

实验
Experimental Settings
Datasets and Models. Both CIFAR10 (Krizhevsky, Hinton et al. 2009) and CIFAR100 (Krizhevsky, Hinton et al. 2009) are composed of 60000 colour images with 32 × 32 size, where 50000 images are used as training set and the rest 10000 images are used as test set. The CIFAR 10 dataset contains 10 classes, and the CIFAR100 contains 100 classes. In few-shot setting, we randomly sample K samples per class from the original CIFAR datasets as training set, where K ∈{1,5,10}. Random crop and random horizontal flip are applied to training images to augment the dataset. The test set is the same as the original one. Due to low resolution of images in CIFAR, a modified VGG16 (Li et al. 2017) are used as the teacher model. Following (Li et al. 2018) and (Li et al. 2017), we adopt VGG16-half as student model.
数据集和模型。CIFAR10(Krizhevsky,Hinton et al.2009)和CIFAR100(Krizhevsky,Hinton et al.2009)均由60000幅32×32大小的彩色图像组成,其中50000幅图像用作训练集,其余10000幅图像被用作测试集。CIFAR 10数据集包含10个类,CIFAR100包含100个类。在少样本设置下,我们从原始CIFAR数据集中随机抽取每类K个样本作为训练集,其中K ∈{1,5,10}。将随机裁剪和随机水平翻转应用于训练图像以增强数据集。测试集与原始测试集相同。由于CIFAR中的图像分辨率较低,因此使用了改进的VGG16(Li等人,2017)作为教师模型。继(Li et al.2018)和(Li et al.2017)之后,我们采用VGG16-half作为学生模型。
The ILSVRC-2012 dataset (Russakovsky et al. 2015) contains 1.2 million images as training set, 50000 images as validation set, from 1000 categories. We randomly sample 10 images per class from the training set for few-shot training. The training images are augmented with random crop and random horizontal flip. During test, the images are cropped into 224×224 size in the center. We adopt PyTorch official trained ResNet34 (He et al. 2016) as the teacher model, ResNet18 as the student one.
ILSVRC-2012数据集(Russakovsky et al.2015)包含120万张图像作为训练集,50000个图像作为验证集,从1000个类别。我们从训练集中随机抽取每类10张图片,进行少样本训练。训练图像通过随机裁剪和随机水平翻转进行增强。在测试过程中,图像在中心被裁剪成224×224大小。我们采用Pytork官方培训的ResNet34(He等人,2016)作为教师模型,ResNet18作为学生模型。
Implementation Details. The proposed method is implemented using PyTorch on a Quadro P6000 24G GPU. The batch size is set to 64 for 10-shot training. For K-shot training, we set batch size to [64 × K/10]. For all experiments, we adopt Adam algorithm for network optimization. Without extra clarification, the following learning rates work when batch size is 64. For other batch size: B, the learning rate is scaled by the factor: B=64 as (He et al. 2016). The learning rates for block grafting and network grafting on CIFAR10 are set to ![]() respectively. For CIFAR100, the learning rates are
respectively. For CIFAR100, the learning rates are ![]() , respectively. Following (Kingma and Ba 2014), we set the weight decay to zero and the running averages of gradient and its square to 0.9 and 0.999, respectively. We adopt the weight initialization proposed by (He et al. 2015). For ResNet18 on ILSVRC-2012, we adopt the same optimizer and weight initialization method as VGG16-half. During block grafting,we s et the learning rate of block1 and block2 to
, respectively. Following (Kingma and Ba 2014), we set the weight decay to zero and the running averages of gradient and its square to 0.9 and 0.999, respectively. We adopt the weight initialization proposed by (He et al. 2015). For ResNet18 on ILSVRC-2012, we adopt the same optimizer and weight initialization method as VGG16-half. During block grafting,we s et the learning rate of block1 and block2 to ![]() , the one of block3 and block4 to
, the one of block3 and block4 to ![]() . During network grafting, the learning rates for block1∼2, block1∼3 and block1∼4 are set to
. During network grafting, the learning rates for block1∼2, block1∼3 and block1∼4 are set to ![]() , respectively.
, respectively.
实施细节。该方法在Quadro P6000 24G GPU上使用Pytorh实现。对于10-shot训练,批量大小设置为64。对于K-shot训练,我们将批量大小设置为[64 × K/10]。对于所有的实验,我们都采用Adam算法进行网络优化。在没有额外说明的情况下,当批量大小为64时,以下学习率有效。对于其他批量:B,学习率按系数B=64进行缩放(He等人,2016)。CIFAR10上的块移植和网络移植的学习率分别设置为![]() 。对于CIFAR100,学习率分别为
。对于CIFAR100,学习率分别为![]() 。接下来(Kingma和Ba 2014),我们将权重衰减设置为零,梯度及其平方的运行平均值分别设置为0.9和0.999。我们采用了(He等人,2015)提出的权重初始化。对于ILSVRC-2012上的ResNet18,我们采用与VGG16相同的优化器和权重初始化方法。在块移植过程中,我们将块1和块2的学习率设置为
。接下来(Kingma和Ba 2014),我们将权重衰减设置为零,梯度及其平方的运行平均值分别设置为0.9和0.999。我们采用了(He等人,2015)提出的权重初始化。对于ILSVRC-2012上的ResNet18,我们采用与VGG16相同的优化器和权重初始化方法。在块移植过程中,我们将块1和块2的学习率设置为![]() ,区块3和区块4中的一个设置为
,区块3和区块4中的一个设置为![]() .在网络移植过程中,块1∼2的,块1~3,块1~4的学习率分别设置为
.在网络移植过程中,块1∼2的,块1~3,块1~4的学习率分别设置为![]() 。
。
Experimental Results
Homogeneous Architecture Knowledge Distillation. Intuitively, the knowledge between homogeneous network architectures tends to have a more clear correlation than heterogeneous networks, especially for block-wise distillation situation. In this section, we first investigate knowledge distillation between homogeneous network to validate the effectiveness of the proposed method. In Table 1, VGG16-half has a similar network architecture as VGG16 but has fewer channels than VGG16 in the corresponding layer. With full dataset, both KD (Hinton, Vinyals, and Dean 2015) and FitNet (Romero et al. 2014) for VGG16-half achieve comparable performance as their larger teacher. However, when only few samples are available, both KD and FitNet encounter a significant performance drop. FSKD (Li et al. 2018) adopts a dual-step strategy: first network pruning and then block-wise distillation, which achieves an efficient improvement against KD and FitNet in few-shot setting. Our proposed method achieves comparable performance as KD trained with full dataset, even better than teacher in 10-shot setting on CIFAR10. And our method is also superior to other few-shot knowledge distillation methods in all settings. FSKD focuses on the imitation of the intermediate teacher outputs, whose student is not optimized to imitate the predictions of teacher. We owe the improvement of our method to the endto-end imitation of the teacher predictions, which is more robust to some trivial intermediate noise.
同质架构知识蒸馏。直观地说,同质网络体系结构之间的知识往往比异质网络之间有更明确的相关性,尤其是在分块蒸馏的情况下。在本节中,我们首先研究齐次网络之间的知识蒸馏,以验证所提出方法的有效性。在表1中,VGG16 half的网络架构与VGG16类似,但在相应层中的通道数少于VGG16。有了完整的数据集,KD(Hinton、Vinyals和Dean 2015)和FitNet(Romero等人,2014)在VGG16上的表现都与他们的大老师相当。然而,当只有很少的样本可用时,KD和FitNet都会遇到显著的性能下降。FSKD(Li et al.2018)采用了一种双步骤策略:首先是网络修剪,然后是分块蒸馏,在少样本设置下实现了对KD和FitNet的有效改进。我们提出的方法与使用完整数据集训练的KD具有相当的性能,甚至在CIFAR10上的10-shot设置中优于教师。在所有情况下,我们的方法也优于其他几次知识蒸馏方法。FSKD侧重于模仿中级教师的输出,其学生没有优化到模仿教师的预测。我们将方法的改进归功于对教师预测的端到端模拟,这对一些微小的中间噪声更为鲁棒。
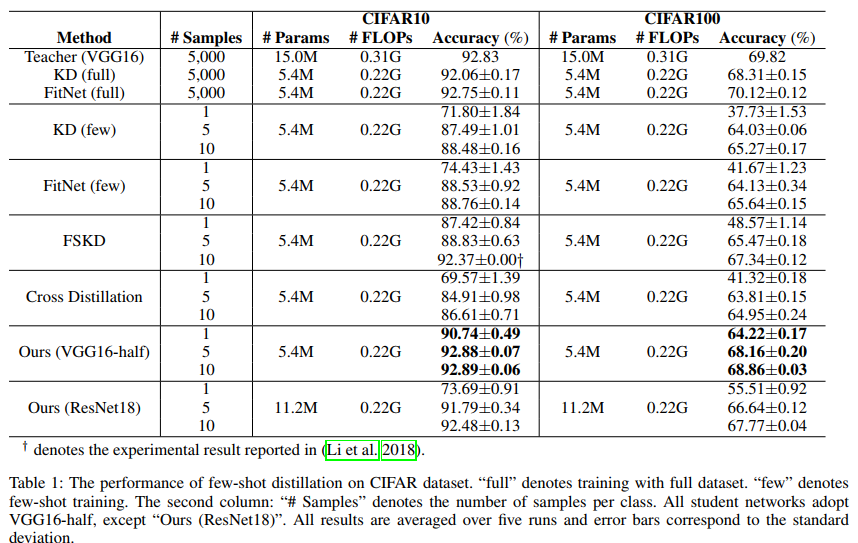
Heterogeneous Architecture Knowledge Distillation. To further verify our method, we conduct few-shot distillation between heterogeneous networks. We adopt ResNet18 as the student, whose network architecture is significantly different from VGG16. Despite more parameters than VGG16-half, the ResNet18 does not achieve better performance in few-shot distillation setting than VGG16-half. Especially when only one sample is available per category, the performance drop of ResNet18 is dramatic on both CIFAR10 and CIFAR100. We guess that the knowledge distribution of ResNet18 is significantly different from the VGG16 one across blocks, which harms the performance of knowledge distillation. We put the exploration for knowledge transfer between very different network architectures in future work.
异构架构知识蒸馏。为了进一步验证我们的方法,我们在异构网络之间进行了几次蒸馏。我们采用ResNet18作为学生,其网络架构与VGG16有显著不同。尽管参数比VGG16的一半多,但ResNet18在几次蒸馏设置中并没有比VGG16的一半实现更好的性能。尤其是当每个类别只有一个样本可用时,ResNet18在CIFAR10和CIFAR100上的性能都会显著下降。我们猜测,ResNet18的知识分布与VGG16的知识分布在不同的区块之间存在显著差异,这会损害知识蒸馏的性能。我们将在未来的工作中探索不同网络架构之间的知识转移。
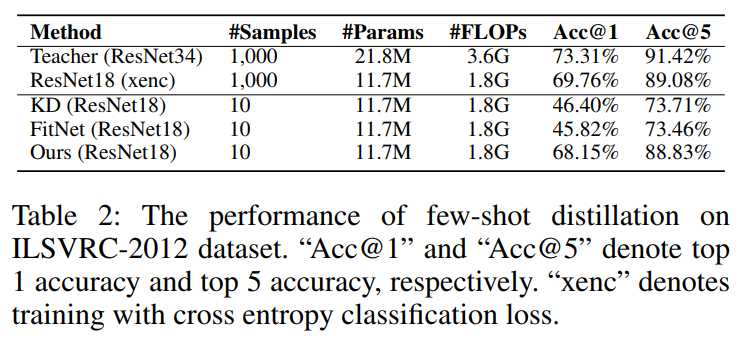
Knowledge Distillation for Large-Scale Dataset. To validate the generality of the proposed method, we also conduct experiments on a more challenging large-scale dateset ILSVRC-2012. As shown in Table 2, the experimental results demonstrate that our proposed method significantly outperforms other few-shot distillation baselines. The performance of our method is slightly below ResNet18 trained on full ILSVRC-2012 with classification loss. We deduce that the dataset for few-shot distillation struggles to cover the high diversity of full ILSVRC-2012.
大规模数据集的知识蒸馏。为了验证该方法的通用性,我们还对更具挑战性的大规模数据集ILSVRC-2012进行了实验。如表2所示,实验结果表明,我们提出的方法明显优于其他几种间歇蒸馏基线。我们的方法的性能略低于在完整的ILSVRC-2012上训练的ResNet18,分类损失。我们推断,少样本蒸馏的数据集难以覆盖完整ILSVRC-2012的高度多样性。
Learning with Different Numbers of Samples. To investigate the effect of different numbers of training samples, we conduct a series of few-shot distillation experiments. The experiments are implemented on CIFAR10 and CIFAR100, as shown in Figure 4. For KD and FitNet, the distillation performances are significantly improved with the increment of the training sample number. When the number of training samples is extremely small, the performances of KD and FitNet are both far from the teacher one. Our proposed method achieves comparable performance as teacher, even when only one training sample is available. Due to smaller parameter search space, our method is more robust to the size of training dataset.
使用不同数量的样本进行学习。为了研究不同数量的训练样本的影响,我们进行了一系列的少样本蒸馏实验。实验在CIFAR10和CIFAR100上实现,如图4所示。对于KD和FitNet,随着训练样本数的增加,蒸馏性能显著提高。当训练样本数量非常少时,KD和FitNet的表现都与教师相差甚远。即使只有一个培训样本可用,我们提出的方法也能达到与教师相当的绩效。由于参数搜索空间较小,我们的方法对训练数据集的大小更具鲁棒性。
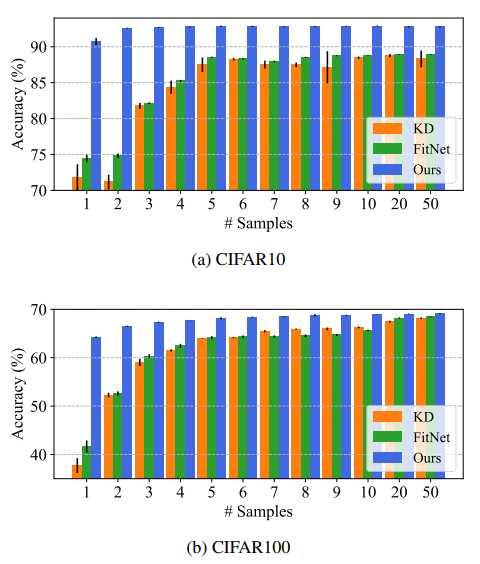
Figure 4: Learning with different numbers of samples. All experiments are averaged over five runs and error bars correspond to the standard deviation
图4:使用不同数量的样本进行学习。所有实验在五次运行中取平均值,误差条对应于标准偏差
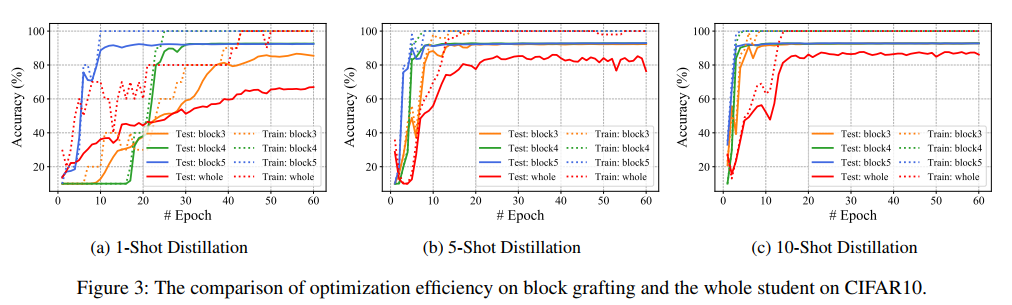
Optimization Efficiency of Block Grafting. To evaluate the efficiency of our proposed block grafting strategy, we compare the training curves of single grafted block optimization and the whole student optimization, denoted as “whole”, in different few-shot settings. Specifically, the last three blocks of VGG16-half, which contain most of parameters in network, are selected as the target to validate block grafting algorithm. As shown in Figure 3, our proposed method not only converges more quickly, but also outperforms the “whole” by a large margin. We observe that our method has a smaller gap between training accuracy and test one, which demonstrates our method can significantly reduce the risk of overfitting.
优化嵌段移植效率。为了评估我们提出的块移植策略的效率,我们比较了在不同的少样本设置下,单个移植块优化和整个学生优化(表示为“整体”)的训练曲线。具体来说,选择包含网络中大部分参数的VGG16半块的最后三个块作为目标,验证块嫁接算法。如图3所示,我们提出的方法不仅收敛速度更快,而且大大优于“整体”。我们观察到,我们的方法在训练精度和测试精度之间的差距较小,这表明我们的方法可以显著降低过度拟合的风险。
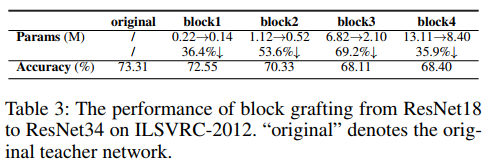
Partial Network Grafting. Some trained networks contain several cumbersome blocks, which can be simplified. Partial network grafting provides an alternative solution to improve the compactness of the existing trained network. We graft some lightweight blocks onto the target trained network to reduce the original model size. In this section, we evaluate the effect of different blocks’ graft from ResNet18 to ResNet34, as shown in Table 3. We split the backbone of ResNet34 and ResNet18 into four blocks: block1∼4, according to down-sampling layer. As depicted in Table 3, the block3 and block4 contain most of parameters in ResNet34. Replacing these blocks with the corresponding blocks from ResNet18 can significantly reduce the original model size. For example, replacing block3 with the one from ResNet18 can reduce the parameter number from 6.82M to 2.10M, a 69.2% reduction. Compared to the ResNet18 trained on full ILSVRC-2012, the performance only drops 1.65%, where only 10 samples per category are used to train network.
部分网络移植。一些经过训练的网络包含几个繁琐的模块,这些模块可以简化。部分网络移植为提高现有训练网络的紧凑性提供了另一种解决方案。我们将一些轻量级块移植到目标训练网络上,以减小原始模型的大小。在本节中,我们评估了从ResNet18到ResNet34的不同块移植的效果,如表3所示。我们将ResNet34和ResNet18的主干分成四个块:block1∼4.根据下采样层。如表3所示,block3和block4包含ResNet34中的大部分参数。用ResNet18中相应的块替换这些块可以显著减小原始模型尺寸。例如,将block3替换为ResNet18中的block3可以将参数数从6.82M减少到2.10M,减少69.2%。与在完整的ILSVRC-2012上训练的ResNet18相比,性能仅下降1.65%,其中每个类别仅使用10个样本来训练网络。
结论与后期工作
In this paper, we propose an progressive network grafting method to distill knowledge from teacher with few unlabeled samples per class. This is achieved by a dual-stage approach. In the first stage, the student is split into blocks and grafted onto the corresponding position of teacher. The student blocks are optimized with fixed teacher blocks using distillation loss. In the second stage, the trained student blocks are incrementally grafted onto the teacher and trained to connect to each other, until the whole student network replaces the teacher one. Experimental results on several benchmarks demonstrate that the proposed method successfully transfers knowledge from teacher in few-shot setting and achieves comparable performance as knowledge distillation using full dataset.
在本文中,我们提出了一种渐进式网络移植方法,以提取知识从教师与少数未标记的每类样本。这是通过双阶段方法实现的。在第一阶段中,学生被分成若干块,并被移植到相应的教师部分上。利用蒸馏损失,使用固定的教师区块对学生区块进行优化。在第二阶段,经过训练的学生模块被逐步移植到教师上,并被训练为相互连接,直到整个学生网络取代教师网络。在多个基准测试上的实验结果表明,该方法在少样本设置下成功地从教师那里转移知识,并与使用完整数据集的知识提取方法取得了相当的性能。
Few-shot distillation can significantly reduce the training cost of neural network. For future work, we plan to explore network architecture search on distillation using block grafting, which aims to find a series of more efficient block modules. We believe that this work is one step toward efficient network architecture search.
少样本蒸馏可以显著降低神经网络的训练成本。在未来的工作中,我们计划探索使用块移植的蒸馏网络架构搜索,目的是找到一系列更高效的块模块。我们相信,这项工作是向高效网络架构搜索迈出的一步。
这篇关于【论文翻译】Progressive Network Grafting for Few-Shot Knowledge Distillation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
