本文主要是介绍多教师知识蒸馏综述-分类(Knowledge Distillation and Student-Teacher Learning for Visual Intelligence),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Overall:学生可以从多个教师那里学到更好的知识,比一个教师的信息更丰富、更有指导意义
文章目录
- 前言
- 一、Distillation from the ensemble of logits
- 二、Distillation from the ensemble of features
- 三、Distillation by unifying data sources
- 四、 From a single teacher to multiple sub-teachers
- 五、 Customizing student form heterogeneous teachers
- 五、 Mutual learning with ensemble of peers
- 总结
前言
虽然在常见的S-T KD范式下已经取得了令人印象深刻的进展,即知识从一个大容量的教师网络转移到一个学生网络。在这种情况下,知识能力相当有限,为此,一些工作探索从多个老师或一群老师那里学习一个便携式学生。在实践中,学生不仅向一个老师学习,而是学习知识的概念,有来自同一任务或不同任务的指导。通过这种方式,学生可以合并和吸收来自多个教师网络的各种知识表示的插图,并构建一个全面的知识系统。因此,人们提出了许多新的KD方法。
尽管这些工作是不同的蒸馏场景和假设,他们共享一些标准特征,可以分为五种类型:集成的logits,集成的特性级信息,统一的数据源,从一个教师网络获得副教师网络,和从异构教师和学习定制学生网络。我们现在明确地分析每个类别,并提供关于它们如何以及为什么对这些问题有价值的见解。
一、Distillation from the ensemble of logits
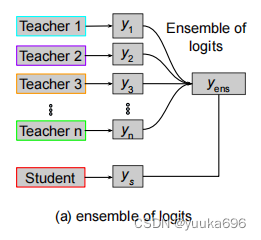
KD中常用的方法之一,如图(1)示在这样的环境下,学生被鼓励通过交叉熵损失来学习集合的教师ligits(soft target/dark knowledge)的软化的输出。概括为:
L E n s logits = H ( 1 m ∑ i = 1 m N T i ( x ) , N S ( x ) ) \mathcal{L}_{Ens}^{\text{logits}} = H\left(\frac{1}{m} \sum_{i=1}^{m} N_{T_i}(x), N_{S}(x)\right) LEnslogits=H(m1i=1∑mNTi(x),NS(x))
其中 m m m 是教师的总数, H H H 是交叉熵损失, N T i N_T^i NTi 和 N S i N_S^i NSi 分别是第 i i i 个教师和第 i i i 个学生的对数几率(或 softmax 输出), τ \tau τ 是温度参数。平均化的软化输出作为在输出层合并多个教师网络的手段。最小化方程实现了在这一层上知识蒸馏的目标。请注意,平均化的软化输出比任何单个输出更为客观,因为它能够减轻输入数据中某些软化输出存在的意外偏差。
[1] Knowledge distillation by on-the-fly native ensemble
[2] Better and faster: knowledge transfer from multiple self-supervised learning tasks via graph distillation for video classification
[3] Knowledge adaptation: Teaching to adapt
[4] Efficient knowledge distillation from an ensemble of teachers
[5]Learning from multiple experts: Self-paced knowledge distillation for long-tailed classifi-
cation
与上面提到的方法不同,[1,2,3,4,5]认为,取个体预测的平均值可能会忽略一个整体的成员教师的多样性和重要性的多样性。因此,他们建议通过使用一个门控组件来模仿教师预测的总和来学习学生模型。然后,等式变为:
L E n s logits = H ( ∑ i = 1 m g i N T i ( x ) , N S ( x ) ) \mathcal{L}_{Ens}^{\text{logits}} = H\left(\sum_{i=1}^{m} g_i N_{T_i}(x), N_{S}(x)\right) LEnslogits=H(i=1∑mgiNTi(x),NS(x))
其中 g i g_i gi 是门控参数。在文献[3]中, g i g_i gi 是源域 D S D_S DS 和目标域 D T D_T DT 的标准化相似度 s i m ( D S i , D T ) sim(D_{S_i}, D_{T}) sim(DSi,DT)。
Summary: 从教师网络集合中蒸馏知识主要取决于取平均或求和个别教师逻辑输出的方法。取平均可以减少意外偏差,但它可能忽视了集合中个别教师的多样性。每个教师逻辑输出的求和可以通过门控参数 g i g_i gi 来平衡,但确定更优的 g i g_i gi 值是未来工作中值得研究的问题。
二、Distillation from the ensemble of features
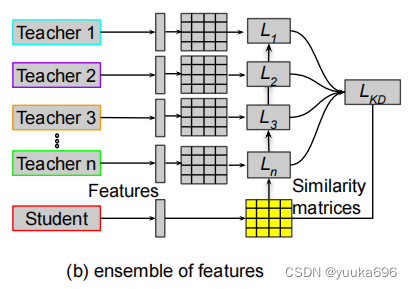
从特征表示集合中蒸馏比从logits中蒸馏更灵活和有利,因为它可以为学生提供更丰富和多样化的交叉信息。然而,从[18,45,48,82,92,94,102]的特征集合中蒸馏更具有挑战性,因为每个教师在特定层上的特征表示与其他层不同。因此,对特征进行转换,形成教师特征图级表示的集合成为关键问题,如图所示。
为了解决这个问题,Park等人[Feed: Feature-level ensemble for knowledge distillation]提出将学生的特征映射输入到一些非线性层(称为变形器)中。然后训练输出来模拟教师网络的最终特征图。在这方面,一般模型集成和基于特征的KD方法的优点,如Sec所述两者都可以合并。损失函数为:
L E n s f e a = ∑ i = 1 m ∥ x T i ∥ x T i ∥ 2 − T F i ( x S ) ∥ T F i ( x S ) ∥ 2 ∥ 1 \mathcal{L}^{fea}_{Ens} = \sum_{i=1}^{m} \left\| \frac{x_{T_i}}{\|x_{T_i}\|_2} - \frac{TF_i(x_S)}{\|TF_i(x_S)\|_2} \right\|_1 LEnsfea=i=1∑m ∥xTi∥2xTi−∥TFi(xS)∥2TFi(xS) 1
其中 x T i x_{T_i} xTi 和 x S i x_{S_i} xSi 分别是第 i i i 个教师和第 i i i 个学生的特征映射,而 T F TF TF 是变换器(例如, 3 × 3 3 \times 3 3×3 卷积层)用于适配学生的特征映射与教师的特征映射。
相比之下,Wu等人[45:Distilled person re-identification: Towards a more scalable system]和Liu等人[18:Knowledge flow: Improve upon your teachers]提出让学生模型模仿教师模型的可学习变换矩阵。该方法是单个教师模型[61:Similarity-preserving knowledge distillation]的更新版本。对于[Wu]中的第i个教师和学生网络,特征映射之间的相似度,特征映射基于欧几里得度量计算如下:
L E n s f e a = ∑ i α i ∥ log ( A S ) − log ( A T i ) ∥ F 2 \mathcal{L}^{fea}_{Ens} = \sum_{i} \alpha_i \left\| \log(\mathbf{A}_S) - \log(\mathbf{A}_{T_i}) \right\|_F^2 LEnsfea=i∑αi∥log(AS)−log(ATi)∥F2
其中 α i \alpha_i αi 是用于控制第 i i i 个教师贡献的教师权重,并且 α i \alpha_i αi 应满足 ∑ i = 1 m α i = 1 \sum_{i=1}^{m} \alpha_i = 1 ∑i=1mαi=1。 A S A_S AS 和 A T i A_{T_i} ATi 分别是学生和第 i i i 个教师的相似性矩阵。这些可以通过 A S = x S T x S A_S = x_S^T x_S AS=xSTxS 和 A T i = x T i T x T i A_{T_i} = x_{T_i}^T x_{T_i} ATi=xTiTxTi 来计算。
Open challenges:基于我们的回顾,很明显,只有少数研究提出从特征表示的集合中提取知识。虽然[48,90]提出让学生通过非线性变换或具有加权机制的相似矩阵来直接模拟教师的特征图的集成,但仍存在一些挑战。首先,我们**如何知道哪个教师的特征表示在集合中更可靠或更有影响力?**其次,我们如何以自适应的方式确定每个学生的加权参数αi?第三,与其将所有特征信息相加,是否有任何机制从集合中选择一个教师的最佳特征图作为代表性知识?
三、Distillation by unifying data sources
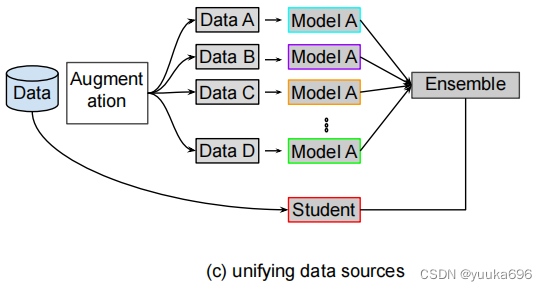
虽然上述使用多名教师的KD方法在某些方面是很好的,但它们假设所有教师和学生模型的目标班级都是相同的。此外,用于培训的数据集往往稀缺,具有高容量的教师模型也有限。为了解决这些问题,[39,42,45,86,103,104]最近的一些工作提出了通过统一多个教师的数据源进行数据蒸馏,如图所示这些方法的目标是通过各种数据处理方法(如数据增强)为未标记的数据生成标签,以训练学生模型。
Vongkulbhisal et al[86]等人提出了统一一个异构分类器(教师)的集合,这些分类器可以被训练来分类不同的目标类集,并且可以共享相同的网络架构。为了推广蒸馏,提出了一种连接异构分类器输出与统一(集成)分类器输出的概率关系。同样地,Wu等人[45]和Gong等人[104]也探索了通过使用未标记数据形成决策函数,将知识从现有数据中训练的教师模型转移到学生模型中。此外,一些工作利用数据增强方法的潜力,从一个训练有素的教师模型中建立多个教师模型。
Radosavovic et al.[42]提出了一种通过对未标记数据进行多次转换的蒸馏方法,来构建共享相同网络结构的不同教师模型。该技术包括四个步骤。首先,对手工标记的数据进行训练单个教师模型。其次,将训练后的教师模型应用于未标记数据的多次转换。第三,对未标记数据的预测被转换为众多预测的集合。第四,利用手工标记数据和自动标记数据的联合对学生模型进行训练。Sau等人[39]提出了一种通过向训练数据注入噪声来模拟多个教师的效果的方法。这样,扰动输出不仅模拟了多个教师的设置,而且在softmax层中产生噪声,从而规范了蒸馏损失。
Summary: 使用数据增强技术和来自单个教师模型的未标记数据来统一数据源来建立多个替补教师模型,也适用于训练学生模型。然而,它需要一个高能力的教师和更广泛的目标类,这可能会限制这些技术的应用。此外,这些技术对一些低水平视觉问题的有效性还需要基于特征表示来进一步研究。
四、 From a single teacher to multiple sub-teachers
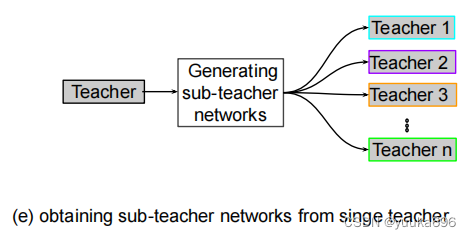
研究表明,多个教师合作或单独使用可以进一步提高学生。然而,使用多个教师网络是资源繁重的,并延迟了培训过程。随后,我们提出了一些从单个教师网络中生成多个副教师的方法[37,41,49,84,88,90,97],如图所示Lee等人[49]提出了随机块,并跳过与教师网络的连接,从而从一个教师网络中可以在同一资源中获得多个教师的效果。副教师网络具有可靠的性能,因为每个批处理都有一个有效的路径。通过这样做,学生可以在整个培训阶段与多个教师一起进行培训。类似地,Ruiz等人[89]通过采用二叉树结构在不同模型之间共享中间层的子集,引入了层次神经集成。该方案允许动态地控制推理成本,并决定需要评估多少个分支。Tran等人[88],Song等人[41]和He等人[97]引入了多头架构来构建多个教师网络。
Open challenges:虽然使用随机或确定性方法的网络集成可以实现多个教师和在线KD的效果,但仍存在许多不确定性。首先,目前还不清楚有多少教师足以进行在线蒸馏。其次,在替补教师群体中,哪种结构是最优的是不清楚的?第三,平衡学生网络的训练效率和准确性是一个有待解决的问题。这些挑战值得进一步研究。
五、 Customizing student form heterogeneous teachers
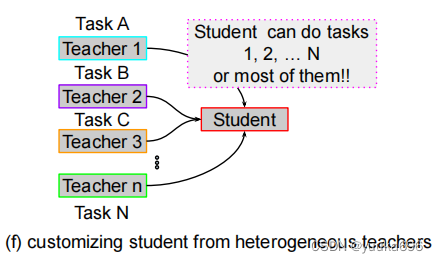
在许多情况下,训练有素的深度网络(教师)专注于不同的任务,并针对不同的数据集进行优化。然而,大多数研究关注的是通过从教师网络中提取学生在同一任务或同一数据集上的知识来训练学生。为了解决这些问题,最近的工作[18,46,83,98,99,100,102,105,106,107]初始化了知识合并,通过从所有教师的专业知识中提取知识来学习一个通用的学生模型,如图4(e)所示。Shen等人[83],Ye等人[99],Luo等人[100]和Ye等人[105]提出了通过定制任务而不访问人工标记注释的方法来训练学生网络。这些方法依赖于分支[108]或选择性学习[109]等方案。这些方法的优点在于,它们能够重用在不同任务的各种数据集上预先训练过的深度网络,从而根据用户的需求构建一个量身定制的学生模型。学生继承了异质性教师的大部分能力,因此可以同时执行多个任务。Shen等人[98]和Gao等人[106]使用了类似的方法,但专注于相同的任务分类。
有两位老师专门研究不同的分类问题。在这种方法中,学生能够处理全面的或细粒度的分类。Dvornik等人[46]试图通过少数学生从老师那里提取知识来预测看不见的课程。Rusu等人[107]提出了一种多教师单个学生策略蒸馏方法,该方法可以将多个强化学习代理的策略提取到单个学生网络中,用于顺序预测任务。
Open challenges:像上面提到的研究在为各种任务定制多功能学生网络方面显示出了相当大的潜力。然而,这些方法也有一些局限性。首先,由于存在分支结构,学生可能不紧凑。其次,目前的技术大多要求教师共享相似的网络结构(如编码器-解码器),这限制了这些方法的泛化。第三,训练可能是复杂的,因为一些工作采用了双阶段策略,然后是多个步骤进行微调。这些挑战为未来的研究开辟了研究范围。
五、 Mutual learning with ensemble of peers
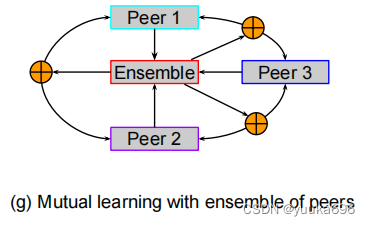
使用多名教师的传统KD方法的一个问题是它们的计算成本和复杂性,因为它们需要预先训练的高容量教师进行双阶段(也称为离线)学习。为了简化蒸馏过程,开发了单级(在线)KD方法[34,40,50,64,82,85,101,110,111],如图所示。这些方法不是预先训练一个静态的教师模型,而是同时训练一组学生模型,让他们以同伴教学的方式互相学习。这种方法也有一些好处。首先,这些方法合并了教师和学生模式的培训过程,并使用同伴网络来提供教学知识。其次,这些在线提取策略可以提高任何容量的模型的性能,从而导致通用的应用程序。第三,这种同行蒸馏方法有时可以优于基于教师的两阶段KD方法。对于具有相互学习的KD,两个对等点的蒸馏损失是基于KL散度的,可以表述为:
L P e e r K D = K L ( z ^ 1 , z ^ 2 ) + K L ( z ^ 2 , z ^ 1 ) \mathcal{L}^{KD}_{Peer} = KL(\hat{z}_1, \hat{z}_2) + KL(\hat{z}_2, \hat{z}_1) LPeerKD=KL(z^1,z^2)+KL(z^2,z^1)
其中 K L KL KL 是KL散度函数, z 1 z_1 z1 和 z 2 z_2 z2 分别是第一个和第二个的预测。此外,Lan等人[40]和Chen等人[50]还通过添加辅助分支创建一个本地的集成教师,从所有分支构建了给定目标(学生)网络的多分支模型。每个分支都接受了蒸馏损失训练,将该分支的预测与老师的预测相一致。
数学上,蒸馏损失可以通过最小化 z e z_e ze(集成教师的预测)和第 i i i 个分支对等体的预测 z i z_i zi 的KL散度来表述:
L E n s K D = ∑ i = 1 m K L ( z e , z i ) \mathcal{L}^{KD}_{Ens} = \sum_{i=1}^{m} KL(z_e, z_i) LEnsKD=i=1∑mKL(ze,zi)
其中预测 z e = ∑ i = 1 m g i z i z_e = \sum_{i=1}^{m} g_i z_i ze=∑i=1mgizi。 g i g_i gi 是第 i i i 个分支对等体的加权得分或基于注意力的权重。
虽然这些方法大多只考虑使用logits,但也有一些工作利用特性信息。Chung等人提出了一种采用对抗性学习(鉴别器)的特征图级提取方法。Kim等人[110]引入了一个特征融合模块来形成一个集成教师。然而,融合是基于分支对等点的特征(输出通道)的连接。此外,Liu等人[18]提出了将知识从多个教师网络的特征转移到一个学生。
Summary: 与使用预先训练过的教师的两阶段KD方法相比,从学生同伴中蒸馏有许多优点。这些方法是基于同伴的相互学习,有时也是基于同伴的集合。大多数研究依赖于logit信息;然而,一些工作也通过对抗性学习或特征融合来利用特征信息。在这个方面还有改进的空间。例如,对于KD处理的最优对等点的数量值得研究。此外,当教师可用时,同时使用在线和离线方法的可能性是很有趣的。在不牺牲精度和泛化的情况下降低计算成本也是一个开放性的问题。
总结
总结了有多个教师的KD方法。总的来说,大多数方法都依赖于logits的集成。然而,特征表示的知识并没有被充分考虑。因此,可以通过设计更好的门控机制来利用特征表示集成的知识。统一数据源和扩展教师模型是减少单个教师模型的两种有效方法;然而,他们的性能下降。因此,克服这一问题还需要进行更多的研究。定制一个多才多艺的学生是一个有价值的想法,但现有的方法受到网络结构、多样性和计算成本的限制,这些在未来的工作中必须改进。
from:Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks
这篇关于多教师知识蒸馏综述-分类(Knowledge Distillation and Student-Teacher Learning for Visual Intelligence)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







