蒸馏专题

蒸馏之道:如何提取白酒中的精华?
在白酒的酿造过程中,蒸馏是一道至关重要的工序,它如同一位技艺精细的炼金术士,将原料中的精华提炼出来,凝聚成滴滴琼浆。今天,我们就来探寻这蒸馏之道,看看豪迈白酒(HOMANLISM)是如何提取白酒中的精华的。 一、蒸馏:白酒酿造的魔法时刻 蒸馏,是白酒酿造中的关键环节。在这个过程中,酿酒师们通过巧妙的操作和精细的技艺,将原料中的酒精和风味物质提取出来,为后续的陈酿和勾调提供基础。蒸馏不仅要求
大语言模型数据增强与模型蒸馏解决方案
背景 在人工智能和自然语言处理领域,大语言模型通过训练数百亿甚至上千亿参数,实现了出色的文本生成、翻译、总结等任务。然而,这些模型的训练和推理过程需要大量的计算资源,使得它们的实际开发应用成本非常高;其次,大规模语言模型的高能耗和长响应时间问题也限制了其在资源有限场景中的使用。模型蒸馏将大模型“知识”迁移到较小模型。通过模型蒸馏,可以在保留大部分性能的前提下,显著减少模型的规模,从而降低计算资源

ICD-Face:用于人脸识别的类内紧致蒸馏算法
ICD-Face: Intra-class Compactness Distillation for Face Recognition 摘要 在ICD-Face中,首先提出计算教师和学生模型的相似度分布,然后引入特征库来构造足够多的高质量的正对。然后,估计教师和学生模型的概率分布,并引入相似性分布一致性(SDC)损失来提高学生模型的类内紧致性。 网络模型 ICD-Fac

通过模板级知识蒸馏进行掩模不变人脸识别
Mask-invariant Face Recognition through Template-level Knowledge Distillation 创新点 1.提出了一种掩模不变人脸识别解决方案(MaskInv),该解决方案在训练范式中利用模板级知识蒸馏,旨在生成与相同身份的非蒙面人脸相似的蒙面人脸嵌入。 2.除了提炼的信息之外,学生网络还受益于基于边

IEEE T-ASLP | 利用ASR预训练的Conformer模型通过迁移学习和知识蒸馏进行说话人验证
近期,昆山杜克大学在语音旗舰期刊 IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)上发表了一篇题为“Leveraging ASR Pretrained Conformers for Speaker Verification Through Transfer Learning and Knowledge Di

SDXS:知识蒸馏在高效图像生成中的应用
人工智能咨询培训老师叶梓 转载标明出处 扩散模型虽然在图像生成方面表现出色,但其迭代采样过程导致在低功耗设备上部署面临挑战,同时在云端高性能GPU平台上的能耗也不容忽视。为了解决这一问题,小米公司的Yuda Song、Zehao Sun、Xuanwu Yin等人提出了一种新的方法——SDXS,通过知识蒸馏简化了U-Net和图像解码器架构,并引入了一种创新的一步式DM训练技术,使用特征匹配和得分蒸

氟化氢的制备与纯化PFA蒸馏冷凝装置耐受强酸PFA烧瓶精馏装置
制备与分馏装置 反应: 浓硫酸+Na3AlF6 温度 200 – 300度,产生HF气体 冰晶石(又名六氣铝酸钠,Na3AIF2;)是白色固体,微溶于水,常用作电解铝工业的助熔剂。工业上用萤石(主要成分是CaF,)、浓硫酸、氢氧化铝和碳酸钠溶液通过湿法制备冰晶石,某化学实验小组模拟工业上制取Nà,AIF,的装置图如下(该装置均由聚四氣乙烯仪器组装而成)。 已知:CaF,+H,SO:ACaS

20240621日志:大模型压缩-从闭源大模型蒸馏
目录 1. 核心内容2. 方法2.1 先验估计2.2 后验估计2.3 目标函数 3. 交叉熵损失函数与Kullback-Leibler(KL)损失函数 location:beijing 涉及知识:大模型压缩、知识蒸馏 Fig. 1 大模型压缩-知识蒸馏 1. 核心内容 本文提出在一个贝叶斯估计框架内估计闭源语言模型的输出分布,包括先验估计和后验估计。先验估计的目的是通

CVPR2024知识蒸馏Distillation论文49篇速通
Paper1 3D Paintbrush: Local Stylization of 3D Shapes with Cascaded Score Distillation 摘要小结: 我们介绍了3DPaintbrush技术,这是一种通过文本描述自动对网格上的局部语义区域进行纹理贴图的方法。我们的方法直接在网格上操作,生成的纹理图能够无缝集成到标准的图形管线中。我们选择同时生成一个定位图(指定编辑

量化、剪枝、蒸馏,这些大模型黑话到底说了些啥?
扎克伯格说,Llama3-8B还是太大了,不适合放到手机中,有什么办法? 量化、剪枝、蒸馏,如果你经常关注大语言模型,一定会看到这几个词,单看这几个字,我们很难理解它们都干了些什么,但是这几个词对于现阶段的大语言模型发展特别重要。这篇文章就带大家来认识认识它们,理解其中的原理。 模型压缩 量化、剪枝、蒸馏,其实是通用的神经网络模型压缩技术,不是大语言模型专有的。 模型压缩的意义 通过压缩

(Arxiv,2023)CLIP激活的蒸馏学习:面向开放词汇的航空目标检测技术
文章目录 相关资料摘要引言方法问题描述开放词汇对象探测器架构概述类不可知框回归头语义分类器头 定位教师指数移动平均一致性训练与熵最小化边界框选择策略 动态伪标签队列生成伪标签维护队列 混合训练未标记数据流队列数据流 实验 相关资料 论文:Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Stud
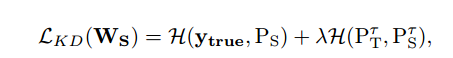
蒸馏Knowledg Distilling
文章目录 蒸馏基础知识Distilling the Knowledge in a Neural Network 2015-HintonDeep mutual learning 2017Improved Knowledge Distillation via Teacher Assistant 2019FitNets:Hints for thin deep nets 2015-ICLR蒸馏的分类

模型蒸馏(distillation)
大size的teacher模型,训练的样本,最后一层softmax之前的logits,当作student模型的训练目标,损失函数是2个向量的距离; 原理:logits包含更多的信息,比label(也就是1-hot vector)的信息量更大; student也可以加上对teacher中间层feature的学习;(模型size不同的话,不好办) 一般是先训练完毕teacher模型,再开始训st
『大模型笔记』量化 vs 剪枝 vs 蒸馏:为推理优化神经网络!
量化 vs 剪枝 vs 蒸馏:为推理优化神经网络! 文章目录 一. 量化 vs 剪枝 vs 蒸馏:为推理优化神经网络!1.1. 量化(Quantization)1.2. 剪枝(purning)1.3. 知识蒸馏(Knowledge Distillation,也称为模型蒸馏)1.4. 工程优化(Engineering Optimizations)1.5. 总结 二. 参考文献

大模型蒸馏:高效AI的秘诀
引言 在人工智能的快速发展中,大模型因其强大的学习能力和广泛的应用场景而备受瞩目。然而,这些模型通常需要大量的计算资源和存储空间,限制了它们在实际应用中的部署。为了解决这一问题,大模型蒸馏技术应运而生,它旨在通过将大模型的知识转移到更小、更高效的模型中,以实现资源优化和性能提升。 1. 大模型蒸馏的基本原理 1.1 定义与概念 模型蒸馏是一种模型压缩技术,它借鉴了教育领域中的“知识传递”概
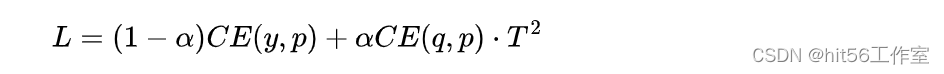

模仿高效网络进行目标检测——知识蒸馏
摘要 链接:https://openaccess.thecvf.com/content_cvpr_2017/papers/Li_Mimicking_Very_Efficient_CVPR_2017_paper.pdf 当前的基于卷积神经网络(CNN)的目标检测器需要从预训练的ImageNet分类模型中初始化,这通常非常耗时。在本文中,我们提出了一种全卷积特征模仿框架来训练非常高效的基于CNN的检
YoloV8改进策略:蒸馏改进|MimicLoss|使用蒸馏模型实现YoloV8无损涨点|特征蒸馏
摘要 在本文中,我们成功应用蒸馏策略以实现YoloV8小模型的无损性能提升。我们采用了MimicLoss作为蒸馏方法的核心,通过对比在线和离线两种蒸馏方式,我们发现离线蒸馏在效果上更为出色。因此,为了方便广大读者和研究者应用,本文所描述的蒸馏方法仅保留了离线蒸馏方案。此外,我们还提供了相关论文的译文,旨在帮助大家更深入地理解蒸馏方法的原理和应用。 YOLOv8n summary (fused)
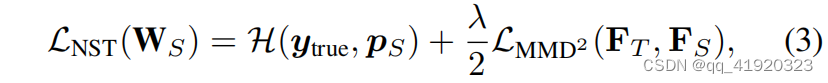
卷积模型的剪枝、蒸馏---蒸馏篇--NST特征蒸馏(以deeplabv3+为例)
本文使用NST特征蒸馏实现deeplabv3+模型对剪枝后模型的蒸馏过程; 一、NST特征蒸馏简介 下面是两张叠加了热力图(heat map)的图片,从图中很容易看出这两个神经元具有很强的选择性:左图的神经元对猴子的脸部非常敏感,右侧的神经元对字符非常敏感。这种激活实际上意味着神经元的选择性,即什么样的输入可以触发这些神经元。换句话说,一个神经元高激活的区域可能共享一些与任务相关的相似特性,而这种

知识蒸馏,需要合适的教师模型,学生模型,蒸馏数据,损失函数,训练策略,让小模型有大模型的知识
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段: 原始模型训练: 训练"Teacher模型", 它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过sof

(2024,SD,条件 GAN,蒸馏,噪声到图像翻译,E-LatentLPIPS)将扩散模型蒸馏为条件 GAN
Distilling Diffusion Models into Conditional GANs 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 3. 方法 3.1 用于一步生成的配对的噪声到图像翻译 3.2 用于潜在空间蒸馏的组合的 LatentLPIPS 3.3 条件扩散鉴别器 4. 实验 5.
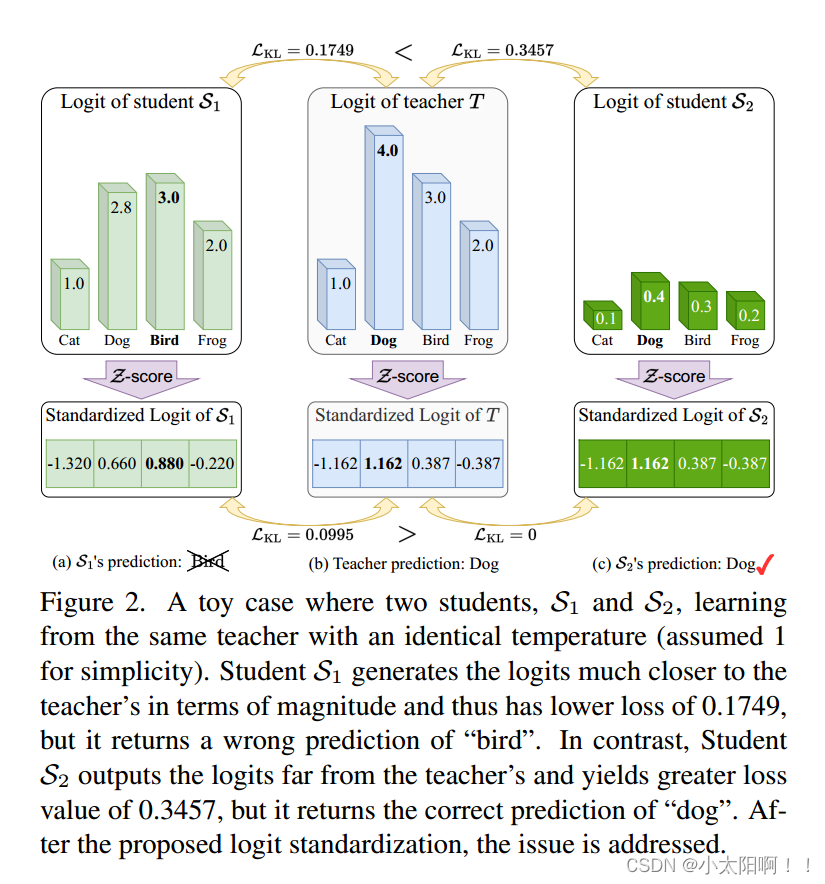
Logit Standardization in Knowledge Distillation 知识蒸馏中的logit标准化
摘要 知识蒸馏涉及使用基于共享温度的softmax函数将软标签从教师转移到学生。然而,教师和学生之间共享温度的假设意味着他们的logits在logit范围和方差方面必须精确匹配。这种副作用限制了学生的表现,考虑到他们之间的能力差异,以及教师天生的logit关系足以让学生学习。为了解决这个问题,我们建议将温度设置为logit的加权标准差,并在应用softmax和KL散度之前进行logit标准化的即

告别互信息:跨模态人员重新识别的变分蒸馏
Farewell to Mutual Information: Variational Distillation for Cross-Modal Person Re-Identification 摘要: 信息瓶颈 (IB) 通过在最小化冗余的同时保留与预测标签相关的所有信息,为表示学习提供了信息论原理。尽管 IB 原理已应用于广泛的应用,但它的优化仍然是一个具有挑战性的问题,严重依赖于互信息的

超越OpenAI,谷歌重磅发布从大模型蒸馏的编码器Gecko
引言:介绍文本嵌入模型的重要性和挑战 文本嵌入模型在自然语言处理(NLP)领域扮演着至关重要的角色。它们将文本转换为密集的向量表示,使得语义相似的文本在嵌入空间中彼此靠近。这些嵌入被广泛应用于各种下游任务,包括文档检索、句子相似度、分类和聚类。然而,创建一个既通用又高效的文本嵌入模型面临着巨大挑战。这些模型需要大量的训练数据来全面覆盖所需的领域和技能,而且,手动标注数据的过程既耗时又昂贵,通常还