本文主要是介绍模型蒸馏笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、什么是模型蒸馏
- 二、如何蒸馏
- 三、常见问题
- 3.1
- 四、参考文献
一、什么是模型蒸馏
Hinton在NIPS2014提出了知识蒸馏(Knowledge Distillation)的概念,旨在把一个大模型或者多个模型ensemble学到的知识迁移到另一个轻量级单模型上,方便部署。简单的说就是用小模型去学习大模型的预测结果,而不是直接学习训练集中的label。
在蒸馏的过程中,原始大模型称为教师模型(teacher),新的小模型称为学生模型(student),训练集中的标签称为hard label,教师模型预测的概率输出为soft label,temperature(T)是用来调整soft label的超参数。
学习软标签之所以能work,核心是因为好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。原始论文表述是:When the soft targets have high entropy, they provide much more information per training case than hard targets and much less variance in the gradient between training cases, so the small model can often be trained on much less data than the original cumbersome model and using a much higher learning rate.
二、如何蒸馏
之前提到学生模型需要通过教师模型的输出学习泛化能力,那对于简单的二分类任务来说,直接拿教师预测的0/1结果会与训练集差不多,没什么意义,那拿概率值是不是好一些?于是Hinton采用了教师模型的输出概率q,同时为了更好地控制输出概率的平滑程度,给教师模型的softmax中加了一个参数T。
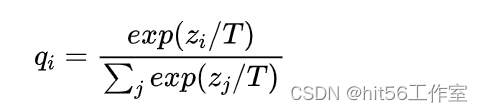
有了教师模型的输出后,学生模型的目标就是尽可能拟合教师模型的输出,新loss就变成了:
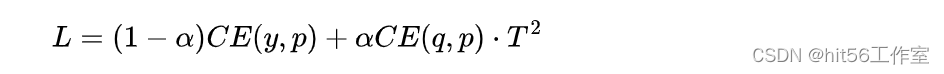
其中CE是交叉熵(Cross-Entropy),y是真实label,p是学生模型的预测结果,是蒸馏loss的权重。这里要注意的是,因为学生模型要拟合教师模型的分布,所以在求p时的也要使用一样的参数T。另外,因为在求梯度时新的目标函数会导致梯度是以前的 ,所以要再乘上,不然T变了的话hard label不减小(T=1),但soft label会变。
有同学可能会疑惑:如果可以拟合prob,那直接拟合logits可以吗?
当然可以,Hinton在论文中进行了证明,如果T很大,且logits分布的均值为0时,优化概率交叉熵和logits的平方差是等价的。
三、常见问题
3.1
四、参考文献
- BERT蒸馏完全指南|原理/技巧/代码
- Distilling the Knowledge in a Neural Network
这篇关于模型蒸馏笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








