本文主要是介绍卷积模型的剪枝、蒸馏---蒸馏篇--NST特征蒸馏(以deeplabv3+为例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文使用NST特征蒸馏实现deeplabv3+模型对剪枝后模型的蒸馏过程;
一、NST特征蒸馏简介
下面是两张叠加了热力图(heat map)的图片,从图中很容易看出这两个神经元具有很强的选择性:左图的神经元对猴子的脸部非常敏感,右侧的神经元对字符非常敏感。这种激活实际上意味着神经元的选择性,即什么样的输入可以触发这些神经元。换句话说,一个神经元高激活的区域可能共享一些与任务相关的相似特性,而这种相似特征,即为学生网络向教师网络学习的目标。

如下图所示为神经元选择性迁移的架构。学生网络不仅利用真正的标签训练,而且还模仿了教师网络中间层的激活分布。图中的每个点或三角形表示其对应的滤波器的激活图。
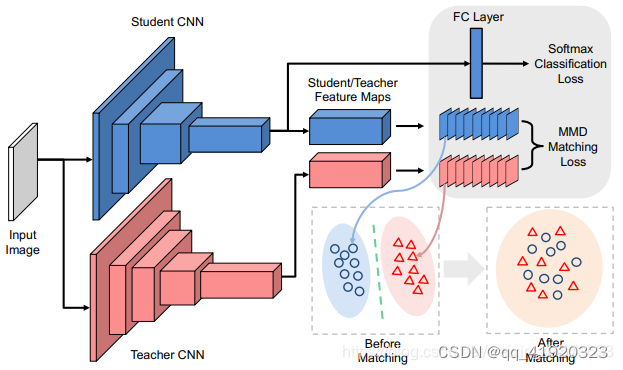
NST损失函数如下所示:
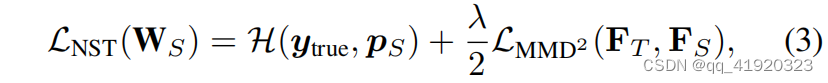
其中,第一项 H(y,p)为交叉熵损失,y是ground truth标签,p是学生模型的输出概率;第二项为最大平均差异(MMD)损失,即为NST损失,用来衡量教师和学生特征之间的差异;MMD的想法就是求两个随机变量在高维空间中均值的距离,
这篇关于卷积模型的剪枝、蒸馏---蒸馏篇--NST特征蒸馏(以deeplabv3+为例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







