本文主要是介绍超越OpenAI,谷歌重磅发布从大模型蒸馏的编码器Gecko,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:介绍文本嵌入模型的重要性和挑战
文本嵌入模型在自然语言处理(NLP)领域扮演着至关重要的角色。它们将文本转换为密集的向量表示,使得语义相似的文本在嵌入空间中彼此靠近。这些嵌入被广泛应用于各种下游任务,包括文档检索、句子相似度、分类和聚类。然而,创建一个既通用又高效的文本嵌入模型面临着巨大挑战。这些模型需要大量的训练数据来全面覆盖所需的领域和技能,而且,手动标注数据的过程既耗时又昂贵,通常还会带来不希望的偏见和缺乏多样性。近年来,大语言模型(LLMs)因其在各种领域的广泛知识和卓越的少样本学习能力而成为了一种强大的替代方案。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
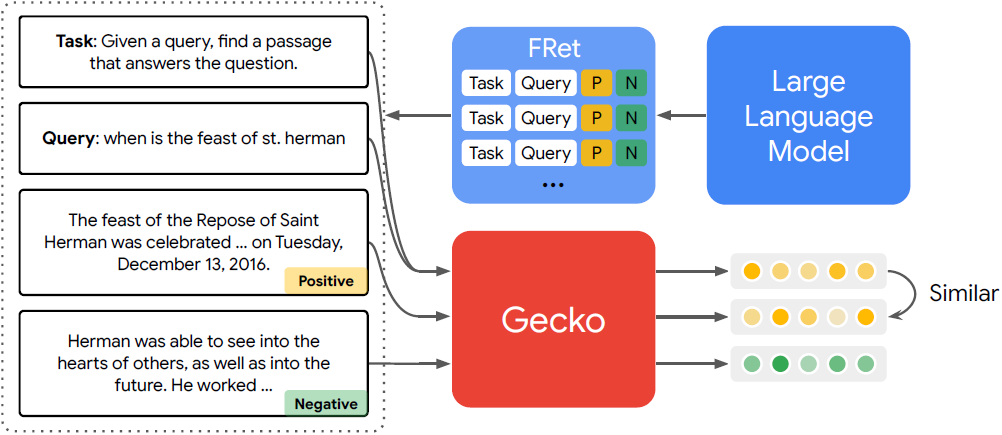
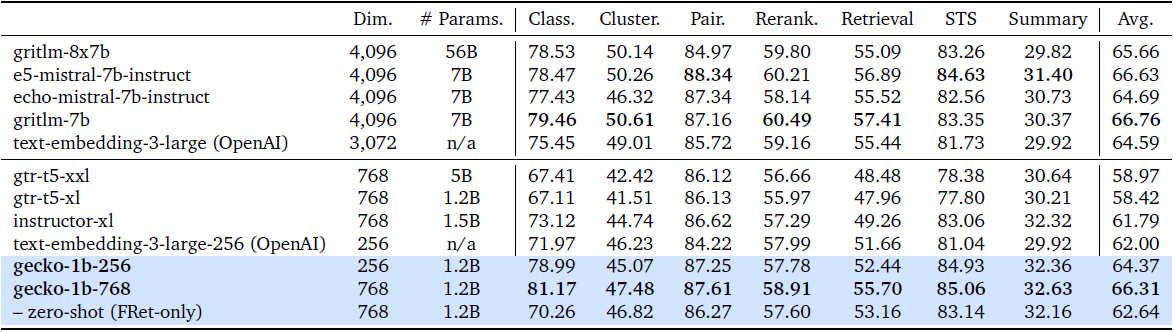
本文介绍了Gecko,一个高效且多功能的文本嵌入模型。如下图,Gecko通过从LLMs中提取知识并将其蒸馏到检索器中,从而实现了强大的检索性能。我们的两步蒸馏过程首先使用LLM生成多样化的合成配对数据。接下来,我们通过检索每个查询的候选段落集,并使用相同的LLM重新标记正面和非常负面的段落,进一步提炼数据质量。Gecko模型在Massive Text Embedding Benchmark(MTEB)上的紧凑性表现出色,256维嵌入的Gecko在性能上超越了所有768维嵌入大小的现有条目。768维嵌入的Gecko平均得分为66.31,可与7倍大的模型和5倍高维嵌入相竞争。
论文标题:
Gecko: Versatile Text Embeddings Distilled from Large Language Models
论文链接:
https://arxiv.org/pdf/2403.20327.pdf
项目地址:
https://github.com/google-research/gecko
Gecko模型的创新之处:两步蒸馏过程的详细介绍
1. 利用LLM生成多样化合成数据
在Gecko的第一步蒸馏过程中,我们使用LLM从一个大型未标记的段落语料库中为每个段落生成相关任务和查询(下图)。这些任务和查询的组合被嵌入到一个预训练的嵌入模型中,以获得最近邻段落,然后使用LLM对这些段落进行重排,并根据LLM的得分获得正面和负面段落。

2. 利用LLM进一步提炼数据质量!
如下图,在第二步蒸馏过程中,我们使用LLM来挖掘更好的正面示例,同时寻找有用的非常负面的示例。我们发现,生成查询的最佳段落通常与原始源段落不同。通过这种方法,我们创建了一个新的数据集FRet,它包含了6.6M个示例,每个示例都包含一个任务、一个查询、一个正面段落和一个负面段落。

Gecko模型的训练策略和优化目标
Gecko模型的训练策略包括预微调和微调两个阶段。在预微调阶段,Gecko利用自监督任务处理大量文本语料,以暴露模型于丰富的文本多样性。微调阶段的主要贡献是创建了一个通过两步LLM蒸馏过程生成的新颖微调数据集FRet,该数据集识别了每个生成查询的正面和非常负面的案例。
在微调过程中,Gecko使用了一个标准的损失函数,该函数使得查询能够区分正面目标和硬负面案例,以及批次中的其他查询。此外,Gecko还采用了MRL损失,该损失优化了小于嵌入维度d的子维度,从而支持单一模型的多种不同嵌入维度。
通过这一训练策略,Gecko在MTEB上的多个文本嵌入任务中取得了优异的成绩,特别是在分类、语义文本相似性(STS)和摘要任务上设定了新的最高标准。此外,仅使用FRet训练的Gecko在MTEB上的零样本基准测试中也展现了强大的性能,与其他基线模型相比具有竞争力。
实验结果:Gecko在MTEB基准测试中的表现
Gecko模型在Massive Text Embedding Benchmark(MTEB)上展现了卓越的性能(下表)。在256维嵌入空间中,Gecko的表现超越了所有768维嵌入尺寸的现有模型。当嵌入维度提升至768时,Gecko的平均得分达到了66.31,与体量大7倍、嵌入维度高5倍的模型相抗衡。这一结果证明了Gecko在紧凑性和效能之间取得了良好的平衡。
1. 多语言检索结果:Gecko模型在多语言任务中的应用和表现
在多语言检索任务中,Gecko模型同样表现出色。尽管Gecko的训练数据FRet仅包含英语,Gecko的多语言版本在MIRACL基准测试中的平均nDCG@10得分为56.2(下表),这一成绩优于其他单一多语言检索器。这表明,即使是仅使用英语数据集生成的模型,也能在多语言任务上取得良好的性能。

2. LLM作为标签器的作用
LLM在Gecko模型中扮演了关键的标签器角色。通过使用LLM生成的查询和任务描述,Gecko能够从大量的网络语料中挖掘出更相关的正面和非常负面的案例。下表,我们测试了FRet的不同标注策略,其中我们使用了不同的正面和非常负面段落。实验结果表明,使用LLM选择的最相关的正面案例作为正样本,比原始生成查询的文本段落更有效,这进一步提升了模型的性能。

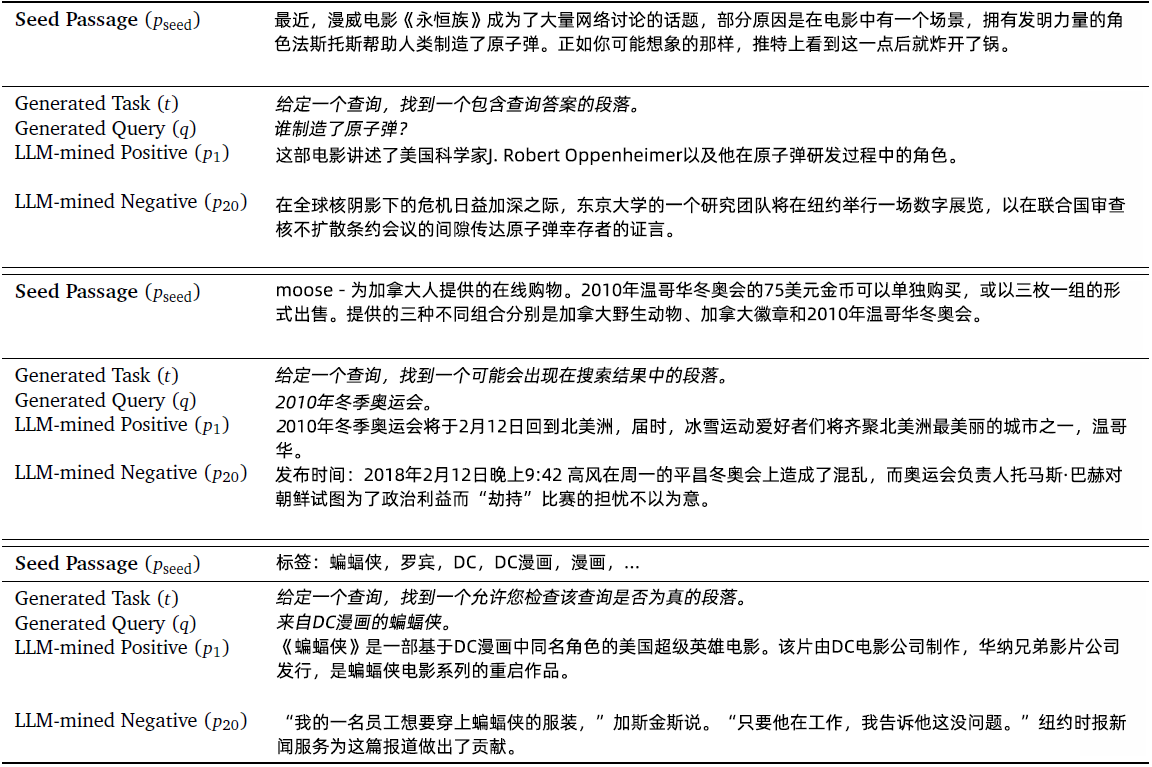
下表是作为定性分析的LLM挖掘的正面和负面示例。虽然每个查询的意图与每个任务相符,但LLM挖掘的正面内容通常比生成查询的种子段落更为相关。
3. FRet数据集的多样性对模型泛化能力的影响
FRet数据集的多样性对Gecko模型的泛化能力产生了显著影响。FRet包含了多种任务类型,如问题回答、搜索结果、事实核查和句子相似性等。如下表,我们测试了FRet的多样性如何影响模型在MTEB跨任务的泛化能力。通过均匀采样不同任务类型的数据,Gecko在MTEB的多个任务上都取得了更好的性能。这一发现强调了数据集多样性对于构建具有广泛适用性的文本嵌入模型的重要性。

讨论:Gecko模型在不同任务中的平衡性和零样本泛化能力
在探讨Gecko模型的平衡性和零样本泛化能力之前,我们首先了解Gecko模型的基本构成。Gecko是一种紧凑且多功能的文本嵌入模型,通过从LLMs中提取知识来实现强大的检索性能。该模型采用了两步蒸馏过程,首先利用LLM生成多样化的合成配对数据,然后通过检索每个查询的候选段落并使用相同的LLM重新标记正面和非常负面的段落,进一步提炼数据质量。
1. 平衡性
Gecko模型在Massive Text Embedding Benchmark (MTEB)上的表现显示出其在不同任务之间的平衡性。具体来说,Gecko在256维嵌入空间上就超越了所有768维嵌入大小的现有条目。而当嵌入维度为768时,Gecko的平均得分为66.31,与7倍大的模型以及5倍高维嵌入相竞争。这表明Gecko能够在保持较小模型尺寸和嵌入维度的同时,实现多任务之间的良好平衡。
2. 零样本泛化能力
Gecko模型的零样本泛化能力体现在其能够在没有任何人类标注数据或MTEB领域内训练数据集的情况下,仅使用LLM生成和排名的数据(FRet)进行训练,并在MTEB上展示出强大的性能。这一结果令人惊讶,因为它与其他基线模型相比具有强大的竞争力,表明Gecko能够在没有见过具体任务实例的情况下,通过LLM的知识进行有效的泛化。
结论:总结Gecko模型的创新点和对未来文本嵌入模型的启示
Gecko模型的创新之处在于其利用LLM的广泛世界知识,通过两步蒸馏过程创建了一个高效的嵌入模型。Gecko的训练涉及到使用LLM生成的多任务合成数据集FRet,该数据集包含了LLM排名的正面和负面段落。Gecko模型的成功展示了LLM可以用于识别合成查询的更好的正面和负面目标,同时也显示了将这些合成生成的数据以统一格式结合起来,可以实现在多个不同任务上同时取得出色性能的可能性。
此外,Gecko模型的零样本泛化能力启示我们,即使在没有大量人类标注数据的情况下,也可以通过利用LLM的知识来训练出能够在多任务上表现良好的文本嵌入模型。这为未来的文本嵌入模型提供了一个新的方向,即通过利用LLM的强大能力来提高模型的泛化能力和效率。


这篇关于超越OpenAI,谷歌重磅发布从大模型蒸馏的编码器Gecko的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







