本文主要是介绍阅读RFDN-Residual Feature Distillation Network for Lightweight Image Super-Resolution,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
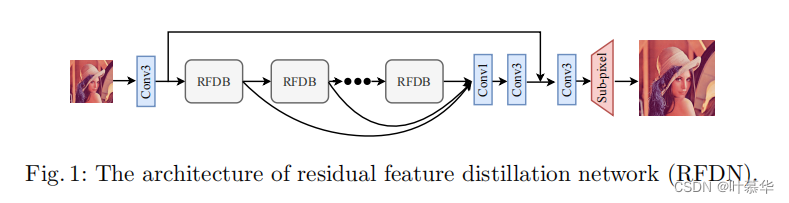
Residual Feature Distillation Network for Lightweight Image Super-Resolution
Abstract. 单图像超分辨率(SISR)的最新进展探索了卷积神经网络(CNN)的力量,以获得更好的性能。尽管基于cnn的方法取得了巨大的成功,但为了解决高计算量的问题,人们提出了各种快速和轻量级的CNN模型。信息蒸馏网络是目前最先进的方法之一,它采用信道分裂操作来提取提取特征。在本文中,我们提出了 feature distillation connection(FDC),它在功能上等同于信道分裂操作,同时更轻量级和灵活。多亏了FDC,我们可以重新考虑信息多蒸馏网络(IMDN),并提出了一个轻量级和精确的SISR模型,称为 residual feature distillation network(RFDN)。RFDN使用多个FDC来学习更多有区别的特征表示。我们还提出了一个 shallow residual block(SRB)作为RFDN的主要构件,这样网络就可以从residual learning中获益最大,同时仍然足够轻量级。
Introduction. 本文主要关注lightweight图像SR,这是需要在时间敏感的应用程序,如视频推流。介绍常用的SR模型:SRCNN,EDSR;接着引出lightweight SR模型:IDN和IMDN(本文即基于IMDN进行改进)。IMDN在PSNR和推理时间方面都有良好的性能,然而,IMDN的参数数量超过了大多数轻量级的SR模型。网络中的关键设计是information distillation mechanism (IDM),给网络设计带来了不灵活性。很难将identity connection与之合并。
我们选取IMDN作为baseline模型,因为它在重建质量和推理速度之间做了很好的权衡,这非常适合用于移动设备。但是IMDN还不够lightweight,SR的性能还可以进一步提高。通过使用 feature distillation connection(FDC),我们的RFDN更加轻量级。此外,我们提出了 shallow residual block(SRB),作为RFDN的构建块,以进一步提高SR性能。SRB由一个卷积层、一个恒等连接和在末端的一个激活单元组成。与普通卷积相比,它可以在不引入额外参数的情况下从residual learning中获益。
本文贡献点如下:
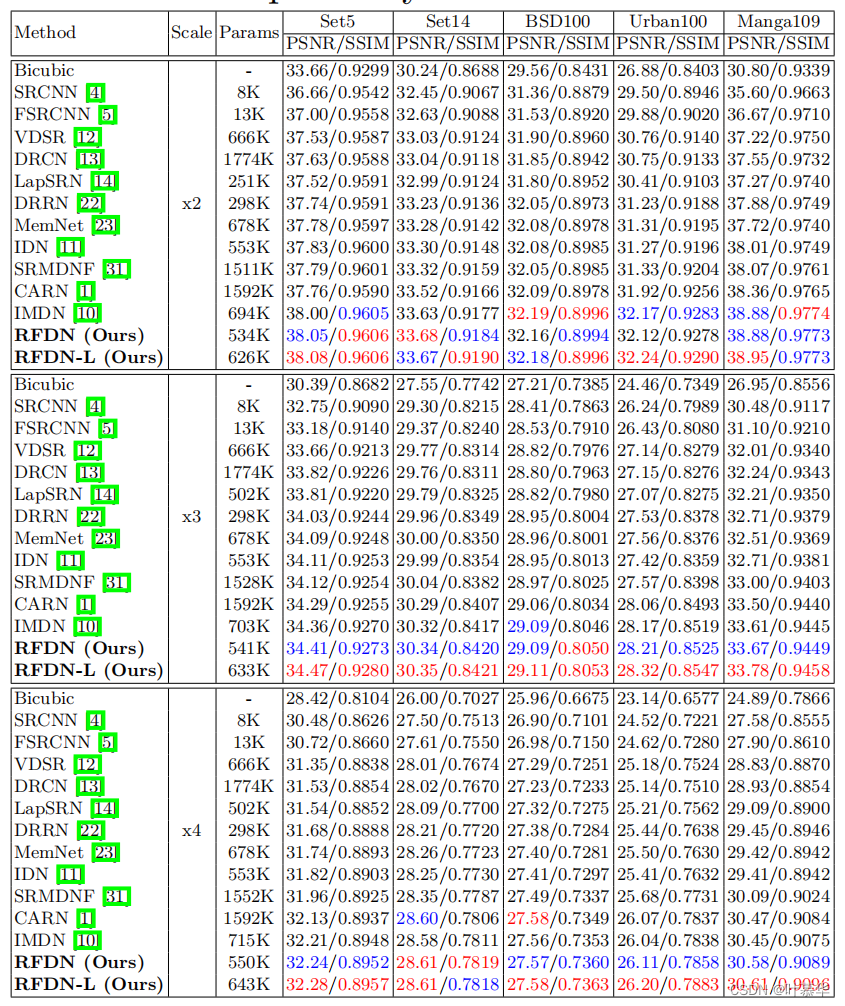
- 提出了一种轻量级的residual feature distillation network(RFDN),用于快速和准确的SR,它在使用比竞争对手更少的参数的同时,实现了最先进的SR性能。
- 对信息蒸馏机制(IDM)进行了更全面的分析,并重新思考了IMDN网络。基于这些新的理解,我们提出了比IDM更轻量级和更灵活的feature distillation network(FDC)。
- 我们提出了shallow residual block(SRB),它将identity connection与一个卷积块相结合,以在不引入任何额外参数的情况下进一步提高SR性能。
这篇关于阅读RFDN-Residual Feature Distillation Network for Lightweight Image Super-Resolution的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






