本文主要是介绍【自然语言处理与文本分析】PCA文本降维。奇异值分解SVD,PU分解法。无监督词嵌入模型Glove。有案例的将文本非结构化数据转化为结构化数据的方法。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
无监督的词嵌入模型-Glove
背后的理念源头是主成分分析PCA
先变为SVD-Glove
PCA是为了产生比较精简的维度,让原始数据在这个精简的维度也能保持原始的变异(信息)。
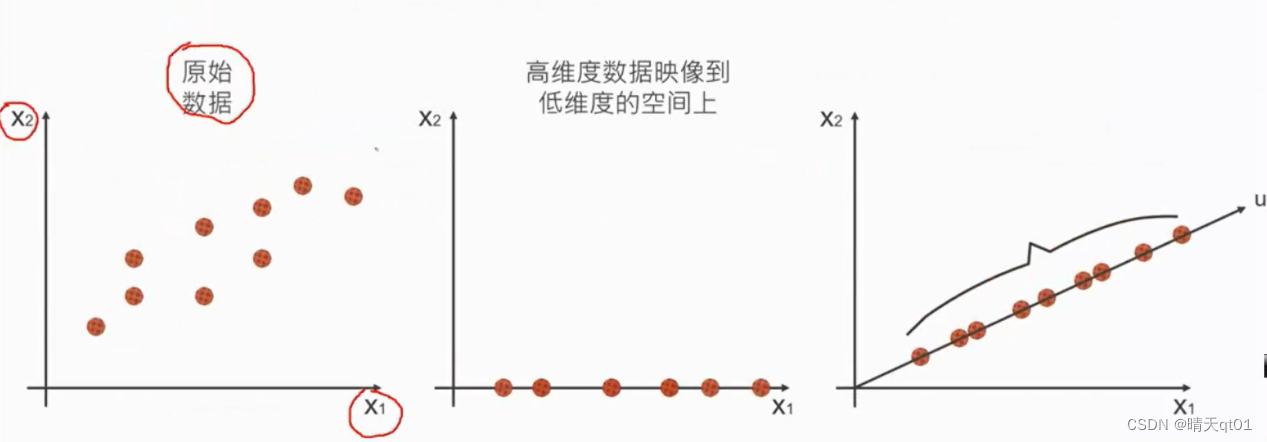
方法1就是将x2降维到x1,它从9个点变成6个点,而且牺牲了很大的信息
比较好的方法就是建立一个新的维度u。尽可能保留资料的变异。
PCA也可以做词嵌入的降维。比如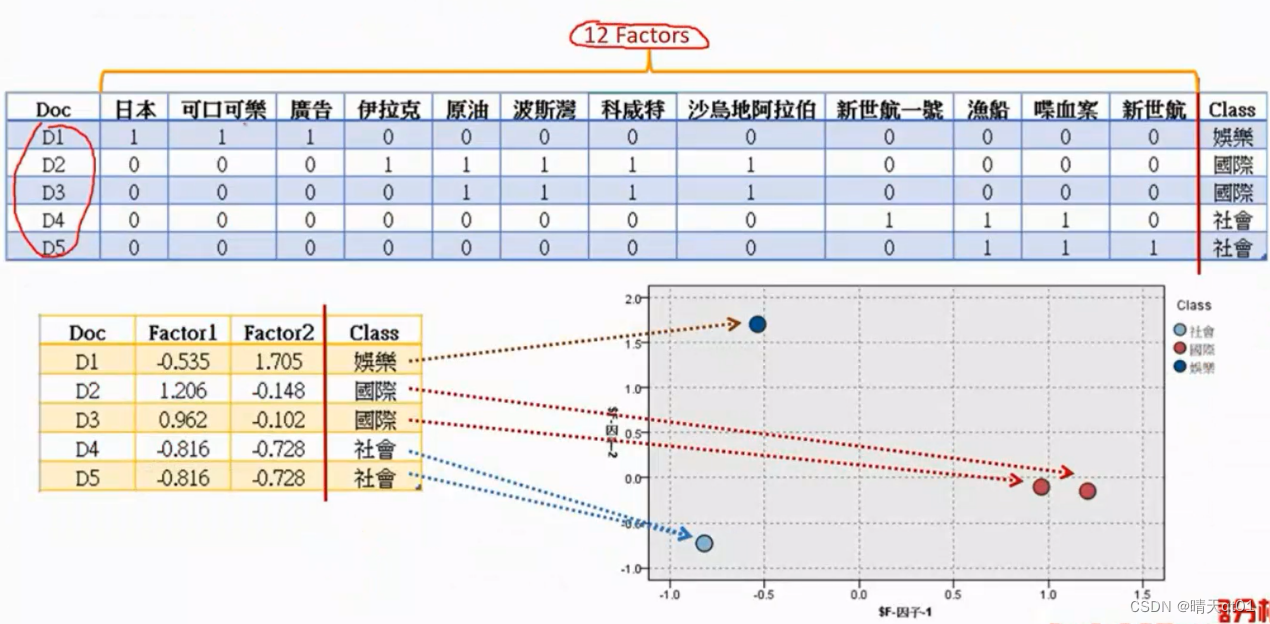
我们将词袋模型进行PCA主成分降维度。经过我们降维之后,就可以变成稠密的矩阵。
我们会发现,社会映射到了同一个点上,

如果我们只选择1个维度,只保留了百分之51,我们可以发现选择2个因素,保留了百分之85的变异,也可以进行可视化。
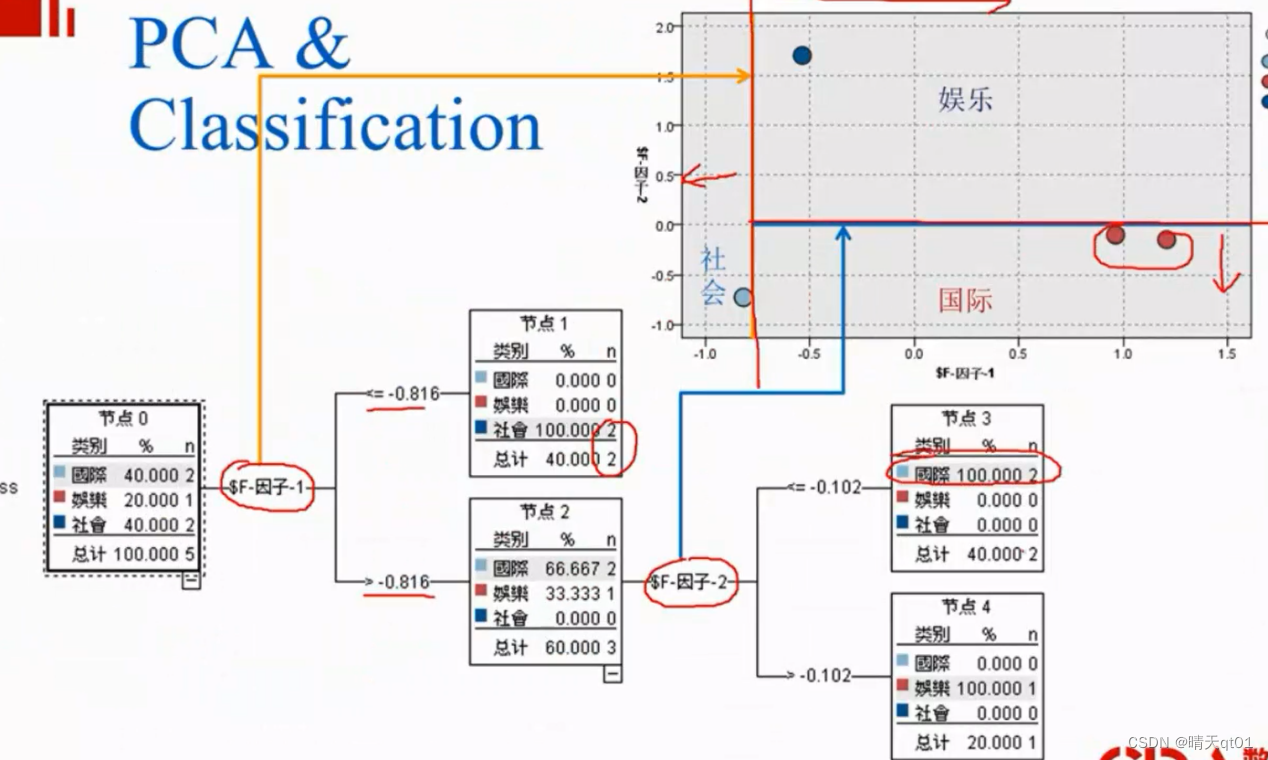
结果我们发现经过PCA的降维之后的决策树也是2个因素。
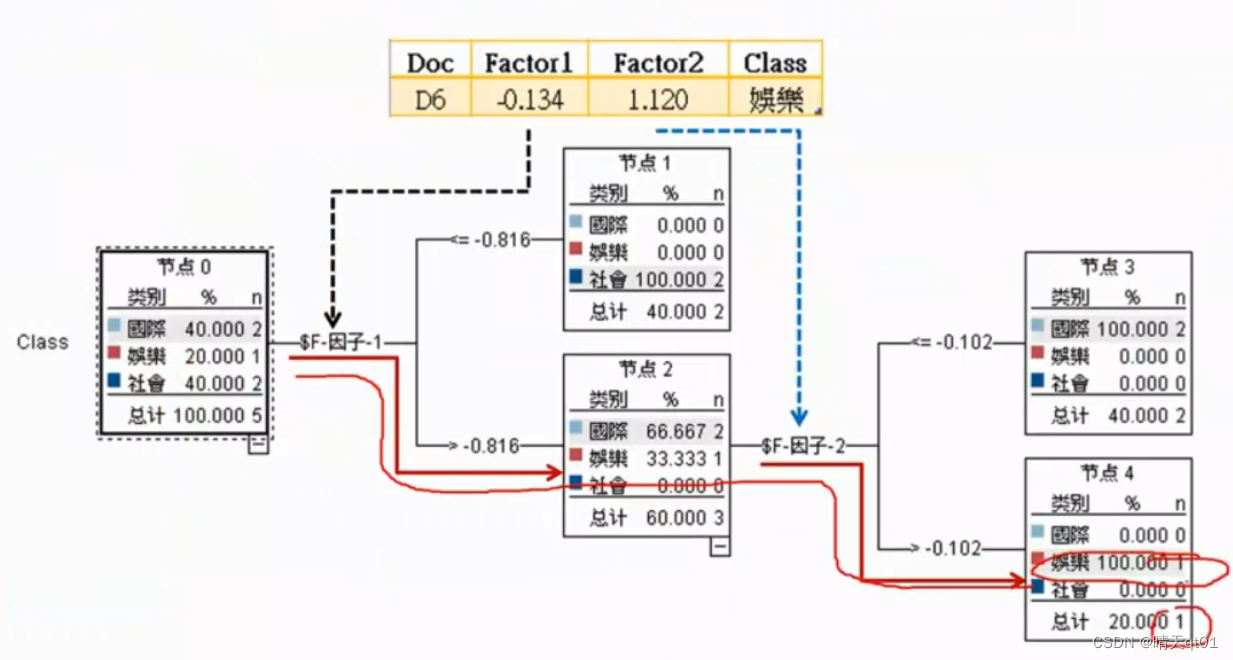
然后我们把一个测试集导入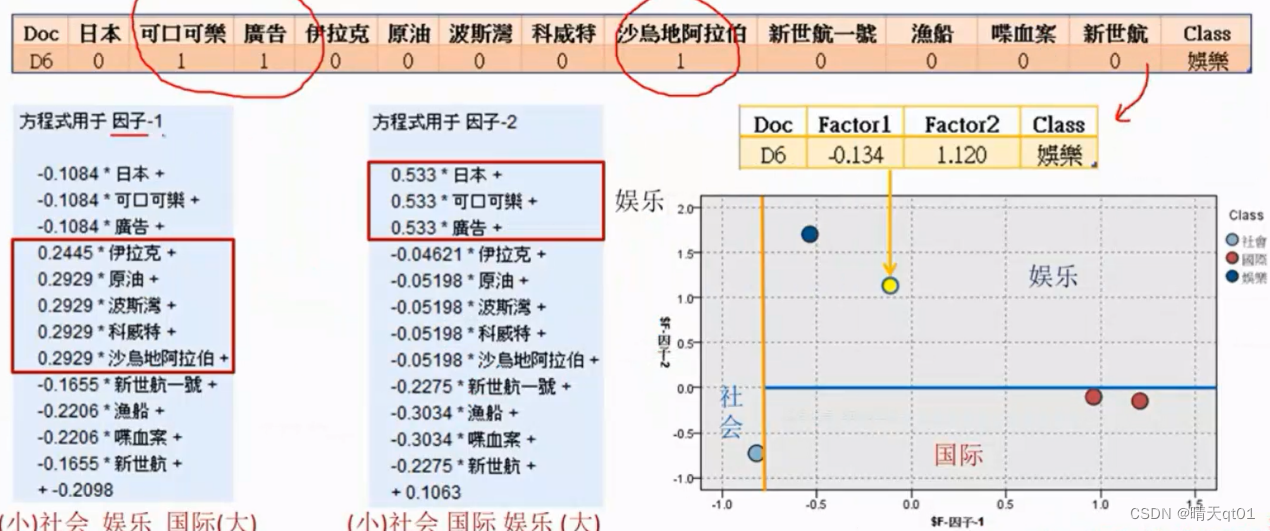
当然我们要按照PCA的公式把数值带入,得到FACTOR1和FACTOR2
结果也刚好得到娱乐的结果,十分准确。
另外我们看因子1,如果希望因子1的数值大,它要求方框里的因素都比较大,也就是方框中的值都比较大,才能被判定为国际新闻
因子二也是,只有日本,可口可乐,广告,都比较大,才能被判入娱乐新闻。也就是说,PCA之后的因子就变成综合考虑。
所以才会导致我们的数值更加正确。
W2d(PCA下)
刚才,我们是对词为输入变量进行PCA降维
选择我们可以把文件作为维度,进行PCA降维
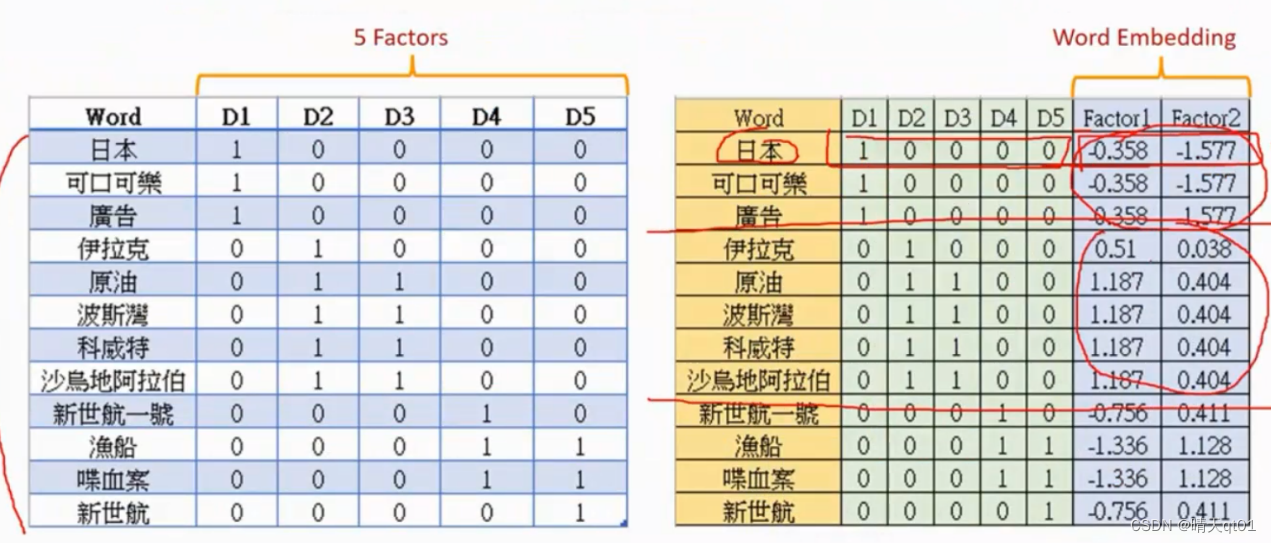
这时我们就会发现,它会把同一个内容(国际,娱乐,社会)的词的数值非常接近,认为二者是同义词,所以w2d会保留同义词。
所以这个词嵌入模型也可以进行寻找同义词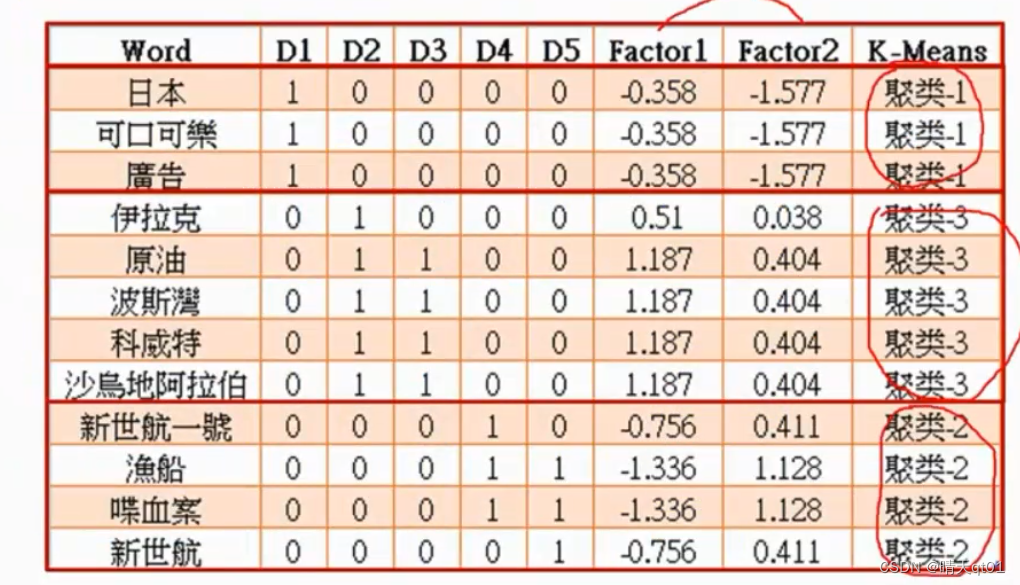
我们再对它进行聚类。我们会发现,刚好会分为3类,并且是国际,社会,娱乐。
Matrix factorization
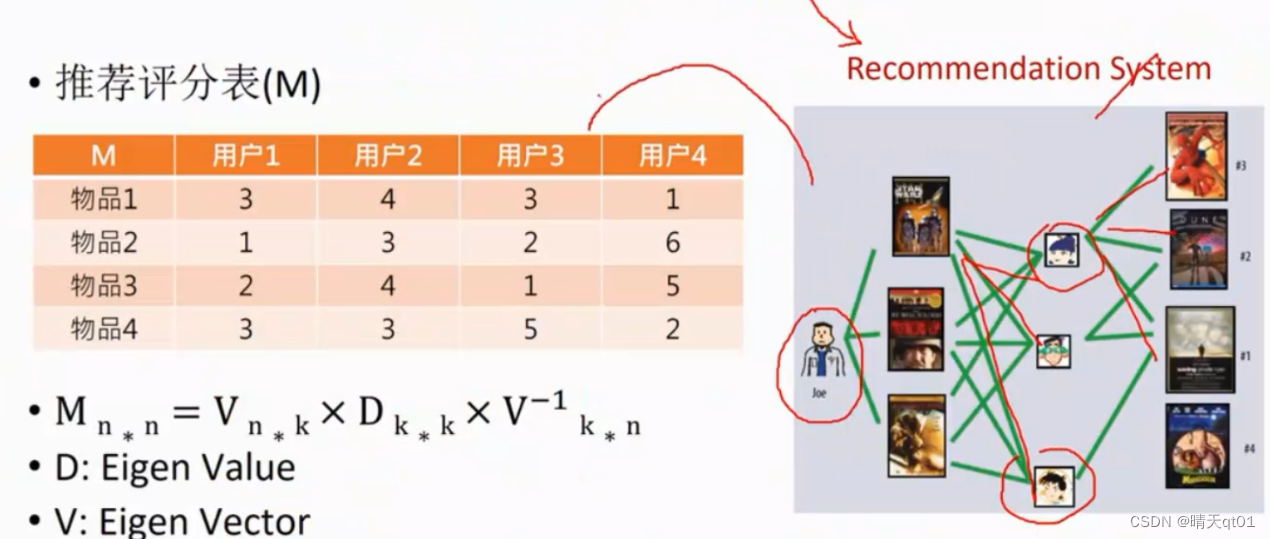
我们看右边的图,可以发现,医师joe会看3部电影,电影还会被其他的都人看。其他的人也会看其他的电影
我们把人和电影做矩阵就可以得到推荐评分表。上图就是横坐标是人纵坐标是电影。
我们就可以将它进行矩阵分解。Dk*k其实就是特征值
Eigen value和Eigen Vector的求解一般要求是正定矩阵,就是正方形。Use-item rating Matrix一般都不是正定矩阵。
D和V一般求出来的都是复数解,无法解释,在运用上有困难。
所以这个不太可行
为了解决这个问题,我们引进了奇异值分解法,它就算是长方形的矩阵也可以,并且结果一定是实数
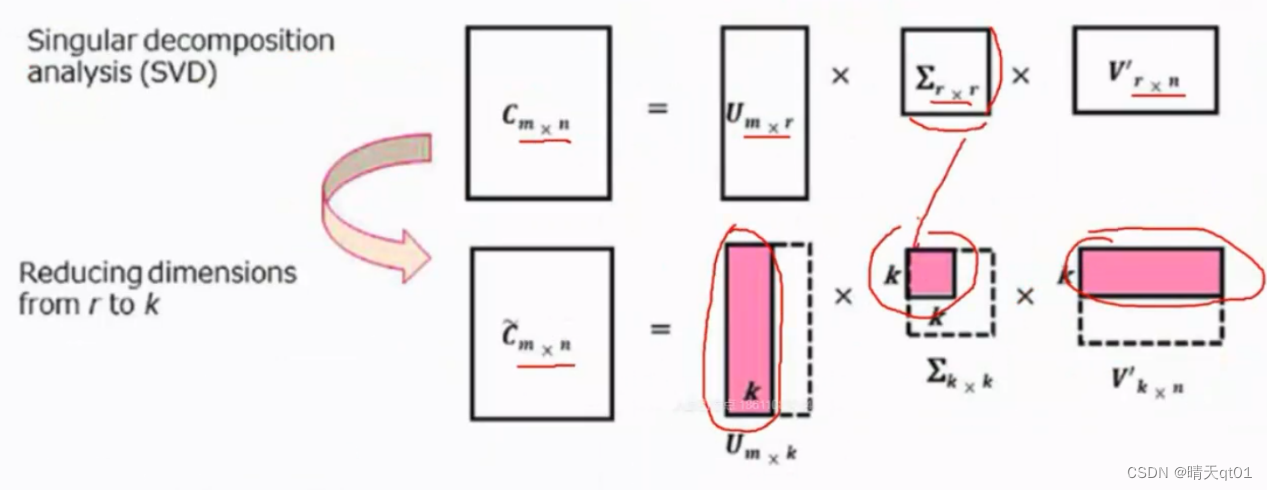
SVD相当于类似于主成分,它将原矩阵分成3个矩阵,我们往往取topk个奇异值就可以表示绝大部分信息。
SVD的几何原理,就算通过线性变化,找出
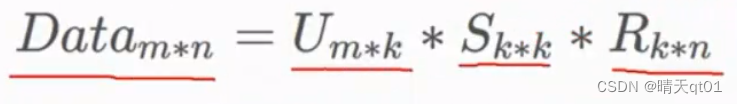
原本1*n维的词向量,可以用1*k维的向量表示关键词。进而实现word embedding(词嵌入)的效果
图示如下:
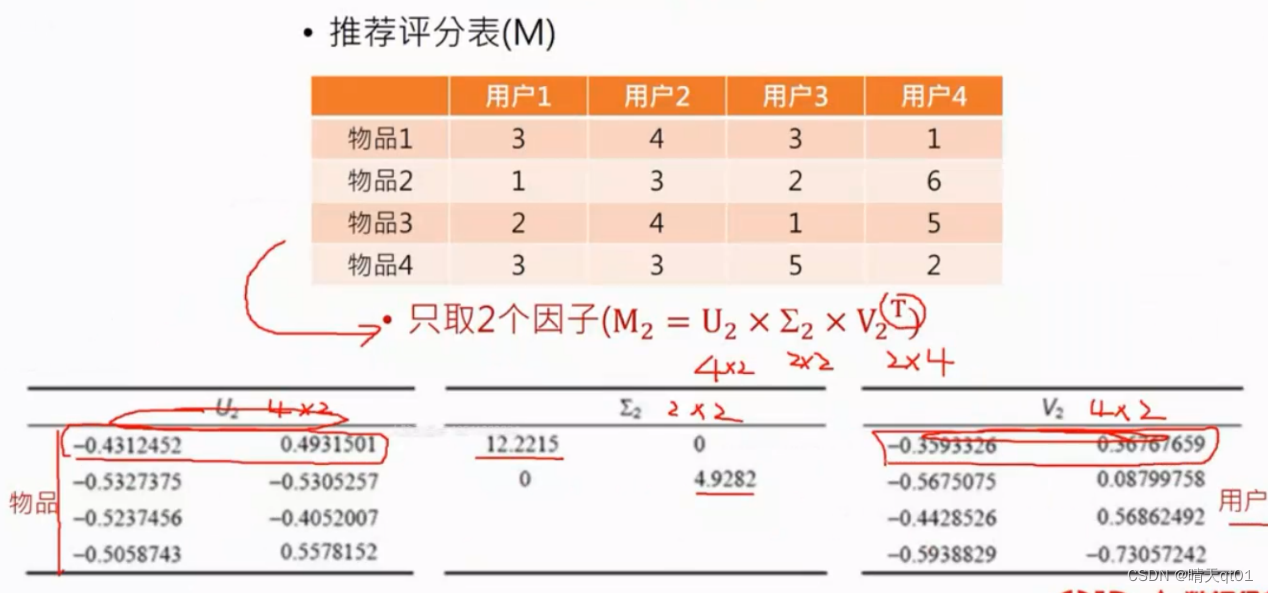
前者就是物品,在新的两个维度下的数字,我们如果对它进行可视化,就会得到下面这个图,用户对那些物品感兴趣
后者就是用户,在新的维度下的,
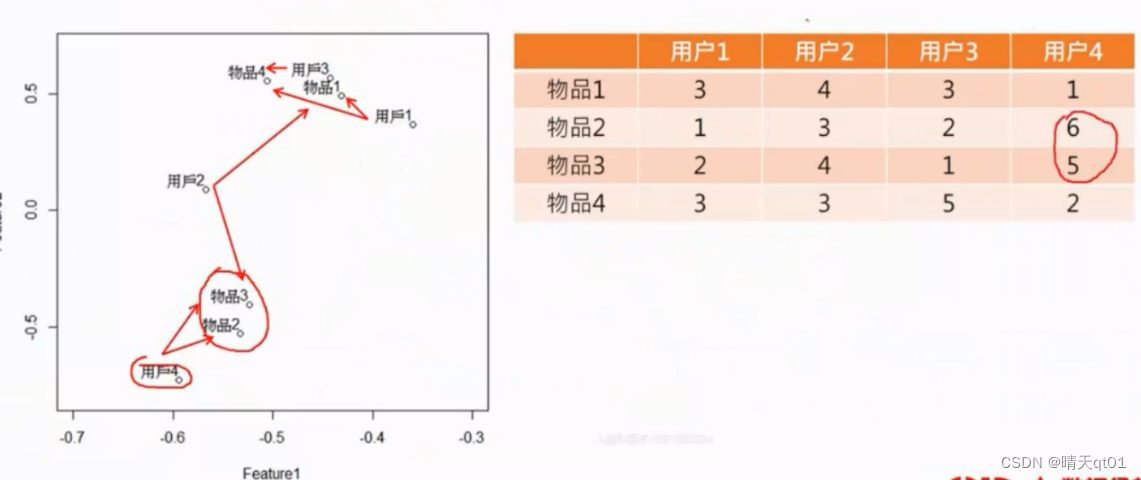
如果物品靠的比较近说明喜欢该物品的人都差不多,如果人靠的比较近,说明该人喜欢的物品都差不多。
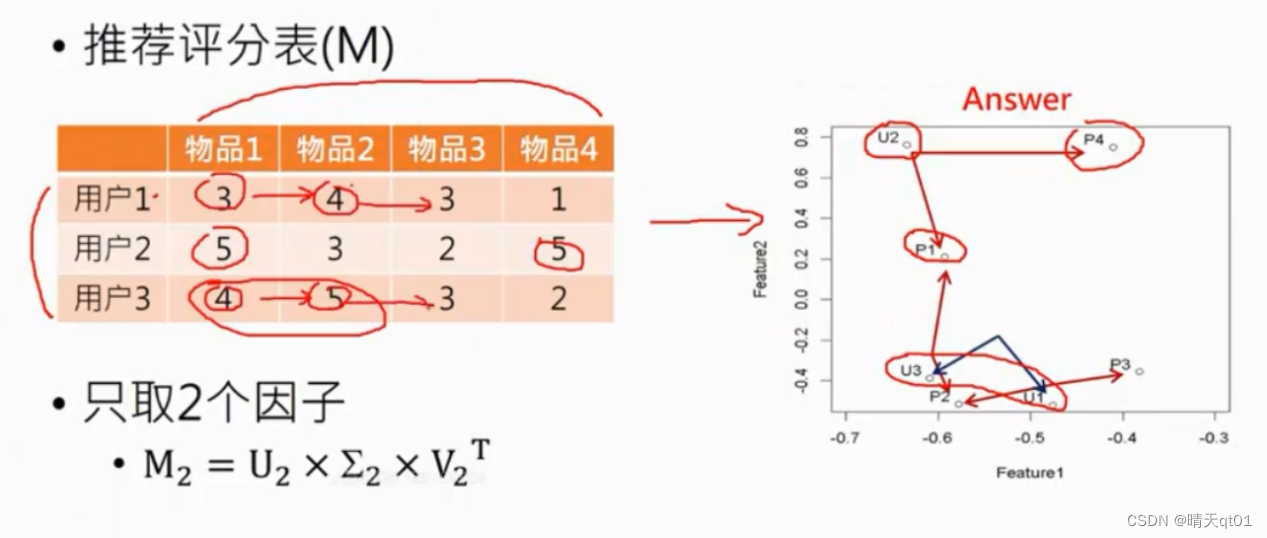
我们可以发现用户1和用户3是一致的,为什么呢,因为他们都是一起打高分,一起打低分。趋势是一致的。我们看这种图不能看数值的大小,要看打分的趋势。
物品二和物品3也是一样的,都是对用户13的评分高些,对用户二的评分低些,(人会喜欢打高分或者低分,不能决定什么,趋势才是重要的。)
我们如果只取两个因子,就可以达到可视化的目的。
因为不一定每个人都会把所有的电影都看了,所有的项目都看了。所以会出现下图,稀疏矩阵的情况。SVD就不能分解了
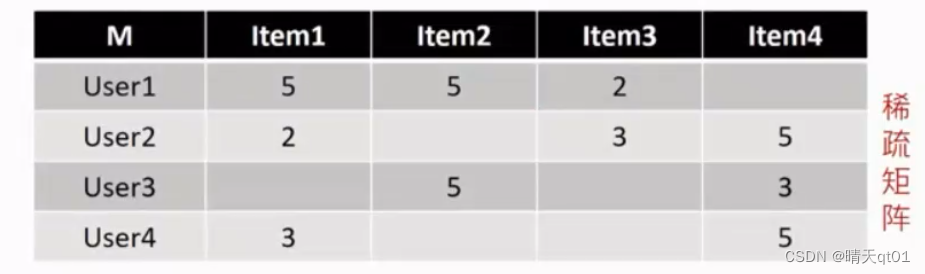
此时我们应该用PU进行分解。可以得到下面这个结果
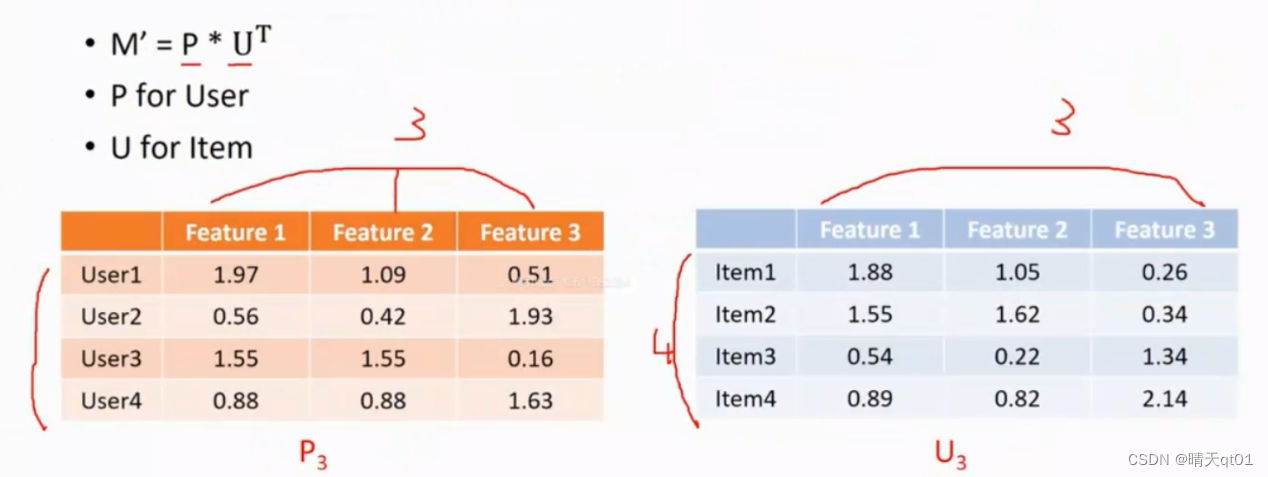
我们可以使用P*U分解,得到上图的情况。分解之后就可以将P*UT再乘回去,得到下图的情况 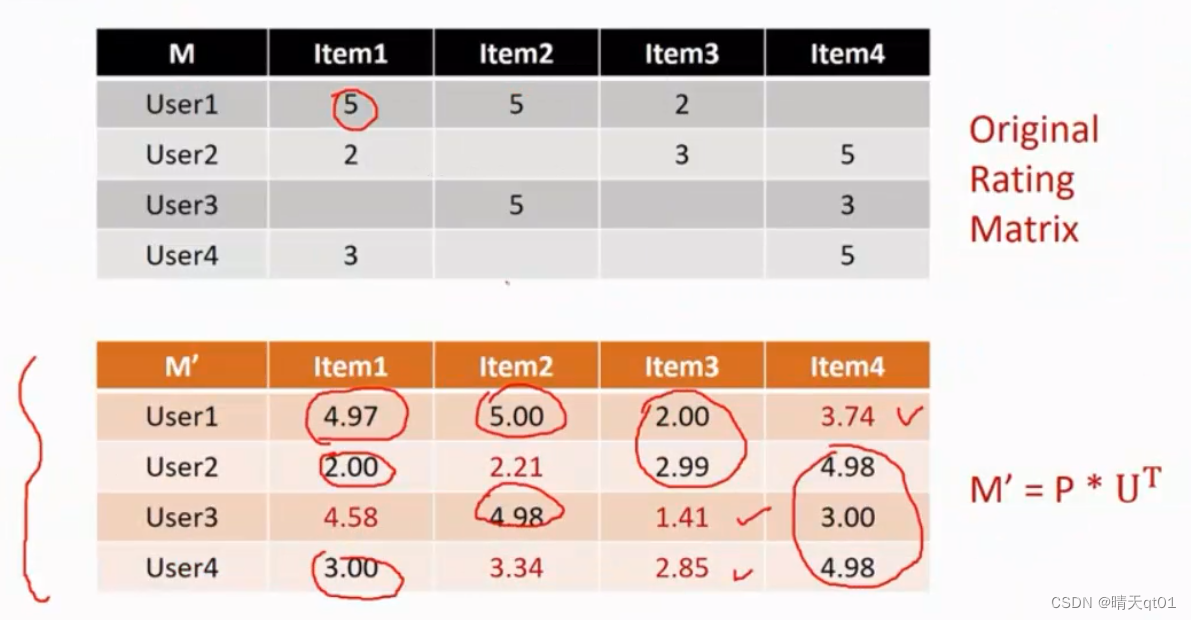
我们乘积得到之后,我们就可以完善用户的评分,来对用户还未尝购买的项目进行推荐,得分高的就可以进行针对性的推荐。
案例2:我们要推荐顾客还没买的产品。下图就可以发现我们原本的数值的几乎没有差距,但是新值也会得到。我们对顾客还没买的数值。比如产品3Use3就很感兴趣。
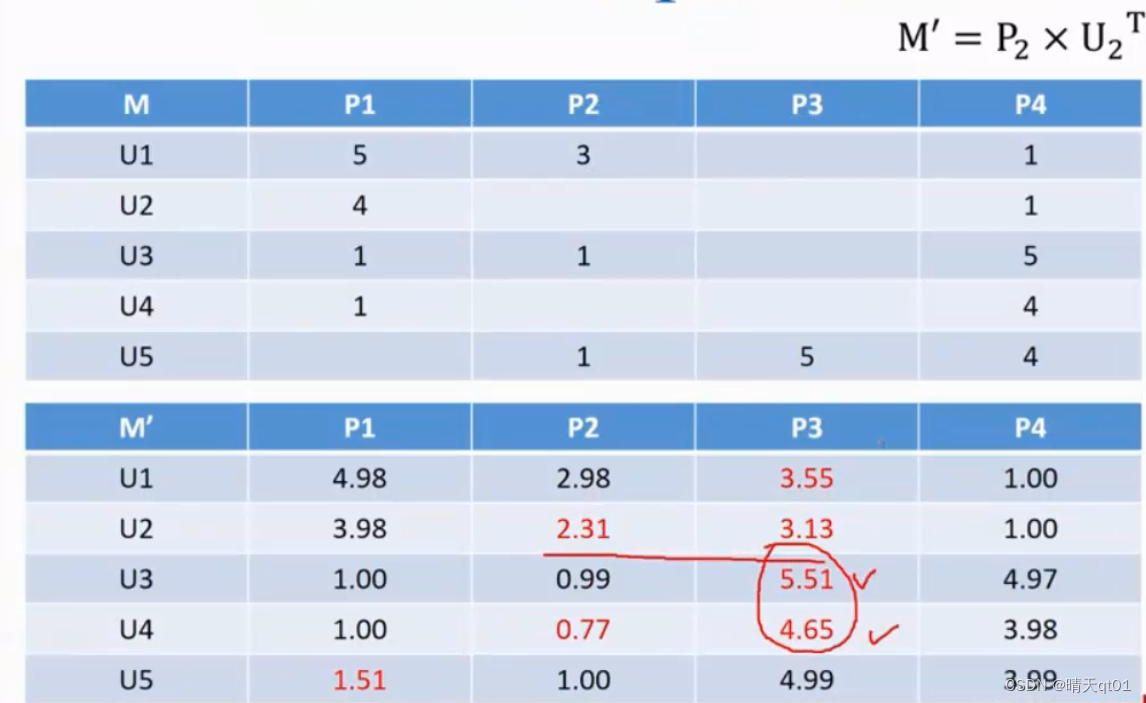
P是把项目作为输入字段,降维。U是针对人物作为输入字段进行降维。
Glove:
这个看起来很新,但是其实是酒品黄小姐就PCA的一种
它通过借鉴Wordvec的Pair-wise的方法,以及一些其他的Trick来进行传统的矩阵分解运算得到wordVector(词嵌入向量)
案例:共线矩阵:


我们会提取全部的关键词,然后得到共线矩阵,我们把行叫做内容维度,、(context)列看成keyword关键词维度。
共线矩阵是怎么来的呢,我们就是看词前后有什么词,有一个就加一,我们会给对于的词进行设置数值。
下面是关键词,上面是关键词附近的文本
案例:
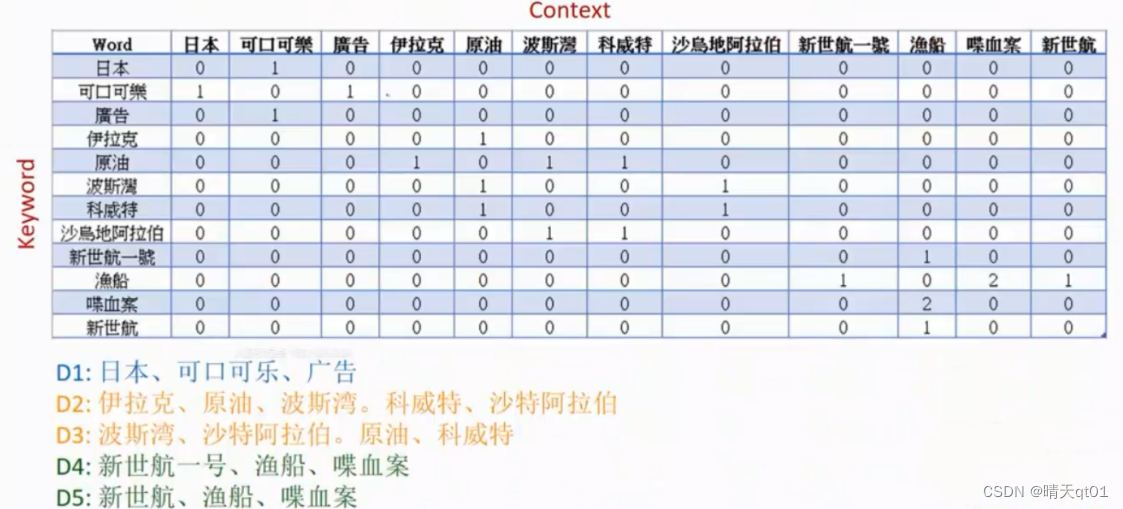
我们用一样的方式得到词共线矩阵。
这个顺序是词原来的顺序,因为它就算看词出现的概率
然后我们对这个进行PCA矩阵。
然后我们取了5个factor,因为这个关键词比较多所以我们就要取多一些主成分,确保有百分之80的变异信息被保留
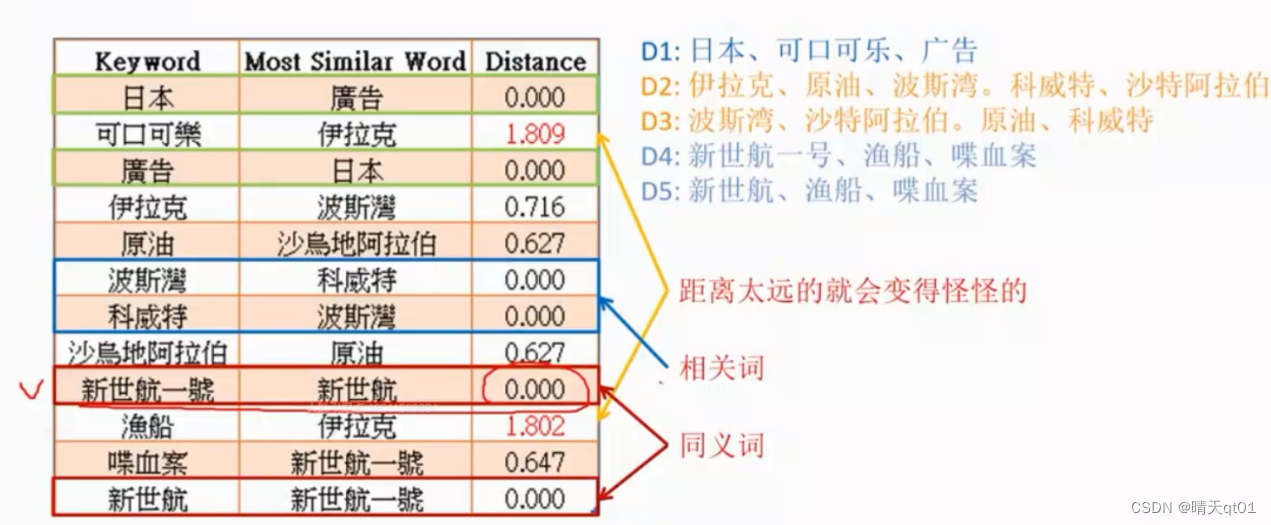
然后我们计算词两两的距离。如果数值是很小的话就说明的同义词或者相关词。
距离非常远,就说明是完全不一样的大小。
Glove就可以吧同义词提取出来。
我们也可以运用Glove进行决策树:
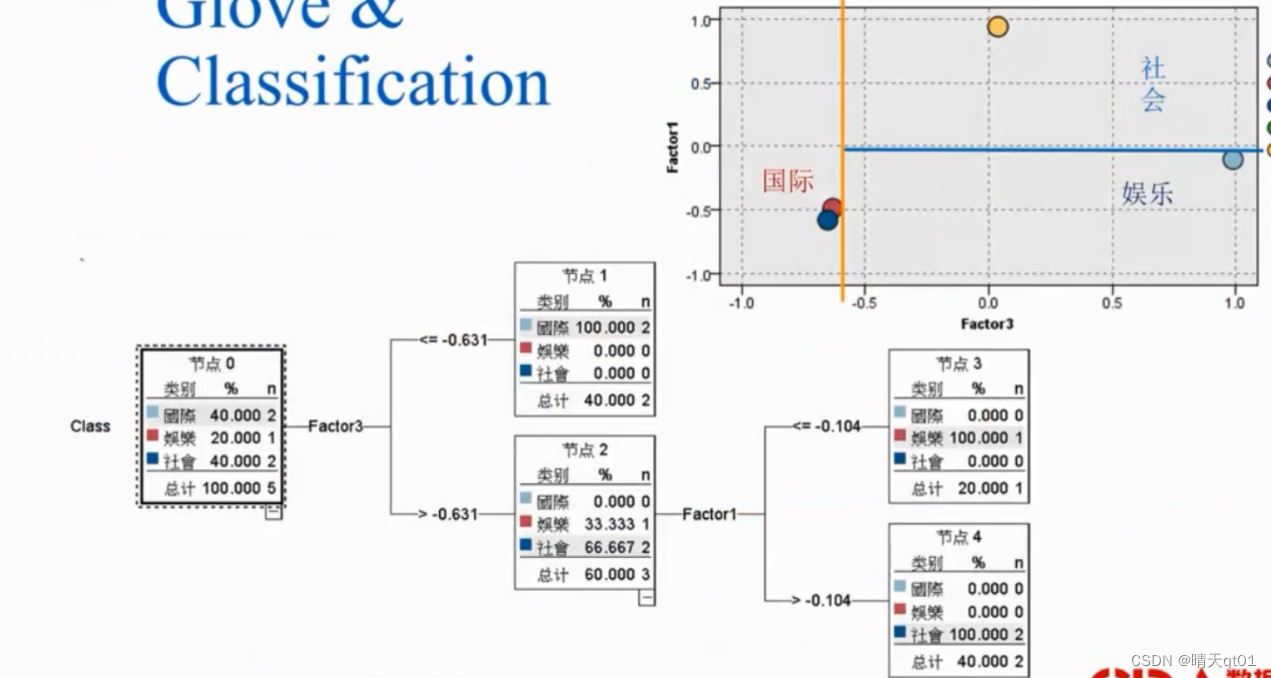
我们发现只需要用,Factor3和factor1就可以进行决策
然后我们还是一样加入测试集合,来进行测试模型准确与否。显然是正确的。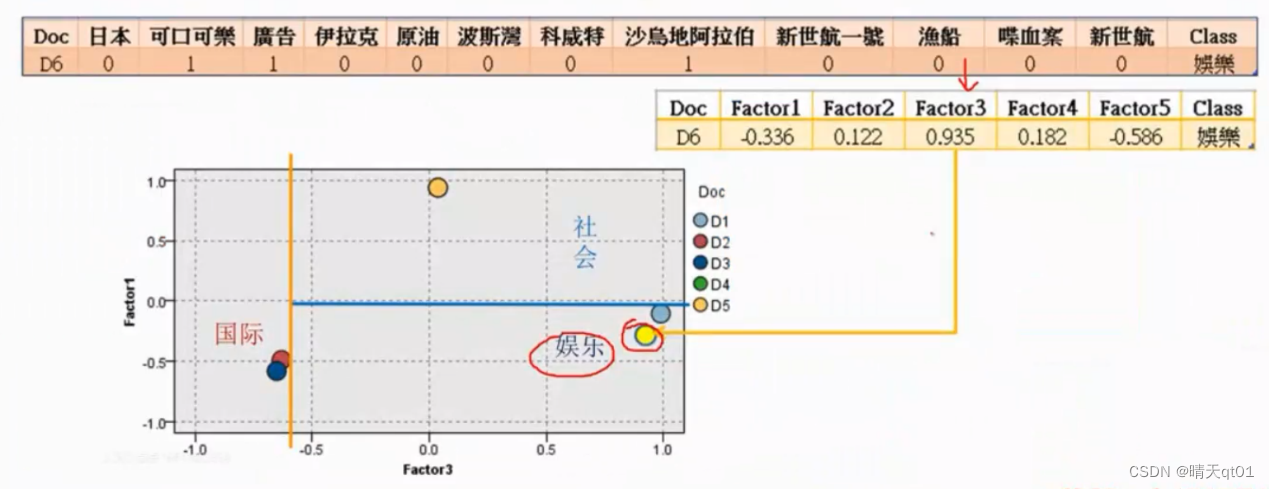
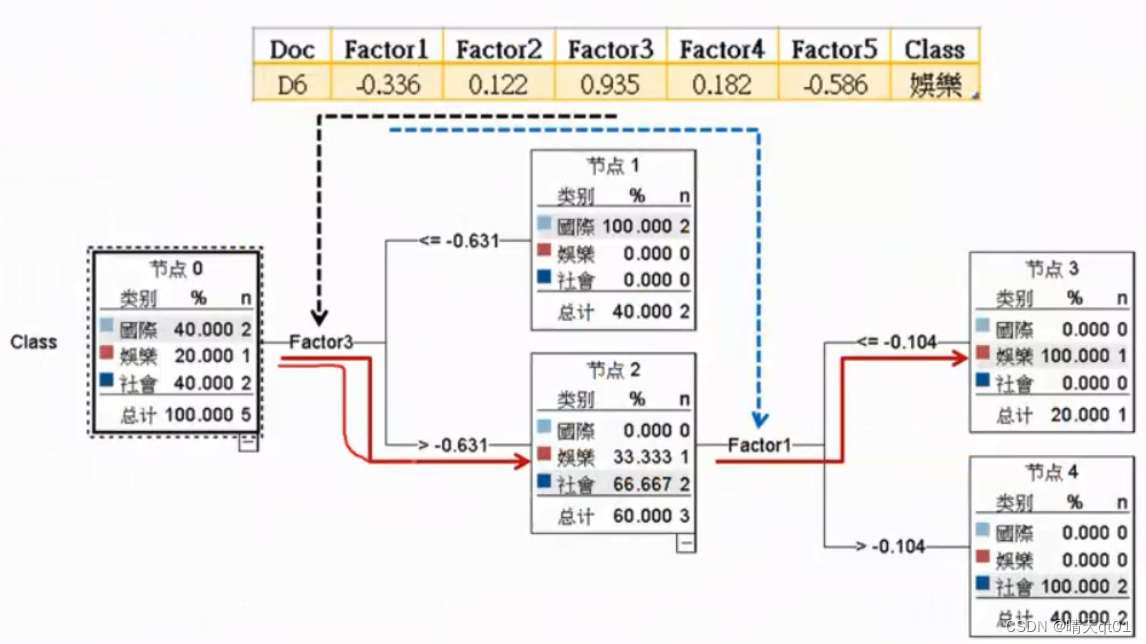
则是glove决策树对第六个文章数据走的一个路线。
下次我们会针对有监督的词嵌入模型进行一个解说。
这篇关于【自然语言处理与文本分析】PCA文本降维。奇异值分解SVD,PU分解法。无监督词嵌入模型Glove。有案例的将文本非结构化数据转化为结构化数据的方法。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



