自然语言专题

C#使用DeepSeek API实现自然语言处理,文本分类和情感分析
《C#使用DeepSeekAPI实现自然语言处理,文本分类和情感分析》在C#中使用DeepSeekAPI可以实现多种功能,例如自然语言处理、文本分类、情感分析等,本文主要为大家介绍了具体实现步骤,... 目录准备工作文本生成文本分类问答系统代码生成翻译功能文本摘要文本校对图像描述生成总结在C#中使用Deep

【生成模型系列(初级)】嵌入(Embedding)方程——自然语言处理的数学灵魂【通俗理解】
【通俗理解】嵌入(Embedding)方程——自然语言处理的数学灵魂 关键词提炼 #嵌入方程 #自然语言处理 #词向量 #机器学习 #神经网络 #向量空间模型 #Siri #Google翻译 #AlexNet 第一节:嵌入方程的类比与核心概念【尽可能通俗】 嵌入方程可以被看作是自然语言处理中的“翻译机”,它将文本中的单词或短语转换成计算机能够理解的数学形式,即向量。 正如翻译机将一种语言

8. 自然语言处理中的深度学习:从词向量到BERT
引言 深度学习在自然语言处理(NLP)领域的应用极大地推动了语言理解和生成技术的发展。通过从词向量到预训练模型(如BERT)的演进,NLP技术在机器翻译、情感分析、问答系统等任务中取得了显著成果。本篇博文将探讨深度学习在NLP中的核心技术,包括词向量、序列模型(如RNN、LSTM),以及BERT等预训练模型的崛起及其实际应用。 1. 词向量的生成与应用 词向量(Word Embedding)

Level3 — PART 3 — 自然语言处理与文本分析
目录 自然语言处理概要 分词与词性标注 N-Gram 分词 分词及词性标注的难点 法则式分词法 全切分 FMM和BMM Bi-direction MM 优缺点 统计式分词法 N-Gram概率模型 HMM概率模型 词性标注(Part-of-Speech Tagging) HMM 文本挖掘概要 信息检索(Information Retrieval) 全文扫描 关键词

基于Python的自然语言处理系列(1):Word2Vec
在自然语言处理(NLP)领域,Word2Vec是一种广泛使用的词向量表示方法。它通过将词汇映射到连续的向量空间中,使得计算机可以更好地理解和处理文本数据。本系列的第一篇文章将详细介绍Word2Vec模型的原理、实现方法及应用场景。 1. Word2Vec 原理 Word2Vec模型由Google的Tomas Mikolov等人在2013年提出,主要有两种训练方式

自然语言处理系列六十三》神经网络算法》LSTM长短期记忆神经网络算法
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列六十三神经网络算法》LSTM长短期记忆神经网络算法Seq2Seq端到端神经网络算法 总结 自然语言处理系列六十三 神经网络算法》LSTM长短期记忆神经网络算法 长短期记忆网络(LSTM,Long S

【自然语言处理】第一章绪论
第一章 绪论 文章目录 第一章 绪论1. 什么是自然语言2. 自然语言处理的定义2.1 自然语言处理NLP2.2 计算语言学CL2.3 NLP与CL 3. 自然语言处理的研究内容3.1 研究对象3.2 研究层次3.3 研究问题3.4 研究内容3.4.1 资源建设3.4.2 基础研究3.4.3 应用技术研究3.4.4 应用系统 4. 自然语言处理的流派5. 自然语言处理的挑战
【自然语言处理 数据清洗】清洗文本中html标签
一段本文中既有文字,又有很多html标签,很乱,需要进行清洗,下面是用python 进行过滤辣鸡html的脚本。 # -*- coding:utf-8 -*-import pandas as pdimport reimport jiebadef filter_tags(htmlstr):"""# Python通过正则表达式去除(过滤)HTML标签:param htmlstr::return:"
【自然语言处理 词库建设】怎样将搜狗的细胞词库scel格式转化成txt格式
搜狗词库:https://pinyin.sogou.com/dict/ 1、先下载搜狗词库到本地,文件格式为.scel后缀 2、利用python3 自动转换成txt python3版本: # -*- coding:utf-8 -*-import structimport os# 由于原代码不适用python3且有大量bug# 以及有函数没有必要使用且一些代码书写不太规范或冗余#在原有
从基础到前沿:基于Python的自然语言处理系列介绍
在数据驱动的时代,自然语言处理(NLP)已成为理解和利用文本数据的关键技术。为了帮助大家深入掌握NLP技术,我将启动一个新的系列——“基于Python的自然语言处理系列”。这个系列将涵盖从基础概念到前沿技术的广泛内容,旨在帮助开发者和数据科学方向使用者全面了解和应用NLP技术。 系列概述 1. 基础知识 在这一部分,我们将探讨NLP的基本概念和技术,包括词

自然语言处理系列六十一》分布式深度学习实战》TensorFlow深度学习框架
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列六十一分布式深度学习实战》TensorFlow深度学习框架安装和部署过程 总结 自然语言处理系列六十一 分布式深度学习实战》TensorFlow深度学习框架 TensorFlow作为最流行的深度学习

Chainlit结合百度飞浆的ocr识别和nlp自然语言处理做图片文字信息提取
PP飞桨简介 PaddlePaddle(PArallel Distributed Deep LEarning),是由百度公司开发的一款开源深度学习平台,支持动态和静态图模式,提供了从模型构建到训练、预测等一系列的功能。PaddlePaddle 的设计目标是让开发者能够更容易地实现、训练和部署自己的深度学习模型。它支持多种操作系统,并提供了多种编程接口,包括 Python 和 C++。 Pad

自然语言处理系列五十三》文本聚类算法》文本聚类介绍及相关算法
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列五十三文本聚类算法》文本聚类介绍及相关算法K-means文本聚类算法原理 总结 自然语言处理系列五十三 文本聚类算法》文本聚类介绍及相关算法 分类和聚类都是文本挖掘中常使用的方法,他们的目的都是将相
自然语言处理领域的两大巨头,谁将引领未来?
在探索自然语言处理(NLP)及更广泛的人工智能(AI)领域的未来走向时,我们不得不将目光投向几个关键玩家:GPT-4o作为OpenAI的杰作,Llama作为Meta(原Facebook)的力作,以及那些正迅速崭露头角的新兴力量。 这两者各自拥有独特的优势,并将在未来的发展中扮演至关重要的角色。 本文将从专业角度出发,深入分析GPT-4o与Llama(由Meta(原Facebook)开发的大

自然语言处理系列五十二》文本分类算法》BERT模型算法原理及文本分类
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列五十二文本分类算法》BERT模型算法原理及文本分类BERT中文文本分类代码实战 总结 自然语言处理系列五十二 文本分类算法》BERT模型算法原理及文本分类 BERT是2018年10月由Google
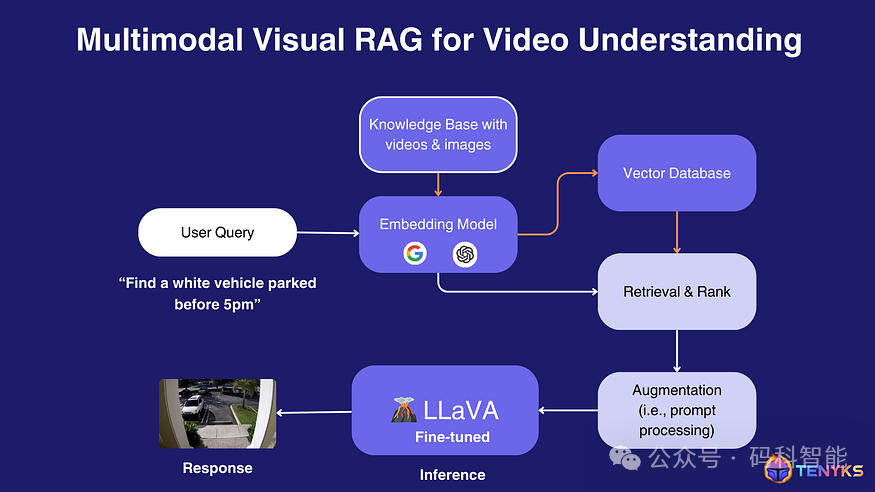
自然语言处理:第四十三章 视觉RAG:变革传统深度学习模型开发流程,开创下一代多模态视觉模型的新时代
文章链接:微信公众平台 (qq.com) 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!! 我们相信视觉领域即将发生范式转变,从而产生计算机视觉管道 2.0,其中一些传统阶段(例如标记)将被可提示的基础模型所取代。 本文深入剖析了Vis
自然语言处理系列五十》文本分类算法》SVM支持向量机算法原理
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列五十SVM支持向量机》算法原理SVM支持向量机》代码实战 总结 自然语言处理系列五十 SVM支持向量机》算法原理 SVM支持向量机在文本分类的应用场景中,相比其他机器学习算法有更好的效果。下面介绍其

人工智能-机器学习-深度学习-自然语言处理(NLP)-生成模型:Seq2Seq模型(Encoder-Decoder框架、Attention机制)
我们之前遇到的较为熟悉的序列问题,主要是利用一系列输入序列构建模型,预测某一种情况下的对应取值或者标签,在数学上的表述也就是通过一系列形如 X i = ( x 1 , x 2 , . . . , x n ) \textbf{X}_i=(x_1,x_2,...,x_n) Xi=(x1,x2,...,xn) 的向量序列来预测 Y Y Y 值,这类的问题的共同特点是,输入可以是一个定长或者不

自然语言处理(NLP)-预训练模型:别人已经训练好的模型,可直接拿来用【ELMO、BERT、ERNIE(中文版BERT)、GPT、XLNet...】
预训练模型(Pretrained model):一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型. 在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT, GPT, roBERTa, transf
自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词

自然语言处理-应用场景-问答系统(知识图谱)【离线:命名实体识别(BiLSTM+CRF>维特比算法预测)、命名实体审核(BERT+RNN);在线:句子相关性判断(BERT+DNN)】【Flask部署】
一、背景介绍 什么是智能对话系统? 随着人工智能技术的发展, 聊天机器人, 语音助手等应用在生活中随处可见, 比如百度的小度, 阿里的小蜜, 微软的小冰等等. 其目的在于通过人工智能技术让机器像人类一样能够进行智能回复, 解决现实中的各种问题. 从处理问题的角度来区分, 智能对话系统可分为: 任务导向型: 完成具有明确指向性的任务, 比如预定酒店咨询, 在线问诊等等.非任务导向型:

自然语言处理-应用场景-聊天机器人(三):MaLSTM【基于FAQ 的问答系统】【文本向量化-->问题召回(利用PySparNN句子相似度计算海选相似问题)-->问题排序(深度学习:句子相似度计算)】
一、问答机器人介绍 1. 问答机器人 在前面的课程中,我们已经对问答机器人介绍过,这里的问答机器人是我们在分类之后,对特定问题进行回答的一种机器人。至于回答的问题的类型,取决于我们的语料。 当前我们需要实现的问答机器人是一个回答编程语言(比如python是什么,python难么等)相关问题的机器人 2. 问答机器人的实现逻辑 主要实现逻辑:从现有的问答对中,选择出和问题最相似的问题,

自然语言处理-应用场景-聊天机器人(二):Seq2Seq【CHAT/闲聊机器人】--> BeamSearch算法预测【替代 “维特比算法” 预测、替代 “贪心算法” 预测】
在项目准备阶段我们知道,用户说了一句话后,会判断其意图,如果是想进行闲聊,那么就会调用闲聊模型返回结果。 目前市面上的常见闲聊机器人有微软小冰这种类型的模型,很久之前还有小黄鸡这种体验更差的模型 常见的闲聊模型都是一种seq2seq的结构。 一、准备训练数据 单轮次的聊天数据非常不好获取,所以这里我们从github上使用一些开放的数据集来训练我们的闲聊模型 数据地址:https://gi
自然语言处理-应用场景-文本生成:Seq2Seq --> 看图说话【将一张图片转为一段文本】
人工智能-自然语言处理(NLP)-应用场景-Seq2Seq:看图说话【将一张图片转为一段文本】
自然语言处理(NLP)-第三方库(工具包):Annoy 【向量最邻近检索工具】
自然语言处理(NLP)-第三方库(工具包):Annoy 【向量最邻近检索工具】 参考资料: 推荐系统的向量检索工具: Annoy & Faiss