glove专题

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出

深度学习--词嵌入方法:GloVe和BERT详解
GloVe 1. 概念 GloVe(Global Vectors for Word Representation)是一种静态词嵌入方法,用于将词汇表示为固定长度的向量。它是由斯坦福大学的研究人员在2014年提出的,用于捕捉单词之间的语义关系并表示为向量空间中的点。 2. 作用 GloVe的主要作用是将单词转换为稠密的向量表示,这些向量可以捕捉到单词之间的语义相似性和关系。这些词向量可以在各

word2vec and glove优缺点
传统方法 假设我们有一个足够大的语料库(其中包含各种各样的句子,比如维基百科词库就是很好的语料来源) 那么最笨(但很管用)的办法莫过于将语料库里的所有句子扫描一遍,挨个数出每个单词周围出现其它单词的次数,做成下面这样的表格就可以了。 假设矩阵是5W*5W维,矩阵运算量巨大。假设矩阵的每个数字都用标准32位Int表示,需要10,000,000,000个byte,也就是10GB的内存(且随着词

Word2Vec、GloVe、Fasttext等背后的思想简介
超长文, 建议收藏之后慢慢观看~ 1Efficient Estimation of Word Representations in Vector Space 本文是 word2vec 的第一篇, 提出了大名鼎鼎的 CBOW 和 Skip-gram 两大模型. 由于成文较早, 本文使用的一些术语有一些不同于现在的叫法, 我都替换为了现在的叫法. CBOW 的架构如下所示. 与作者提到的 feedfo


初次理解GloVe及其与word2vec区别
GloVe: Global Vectors for Word Representation1 进行词的向量化表示,使得向量之间尽可能多的蕴含语义和语法的信息。 GloVe是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性
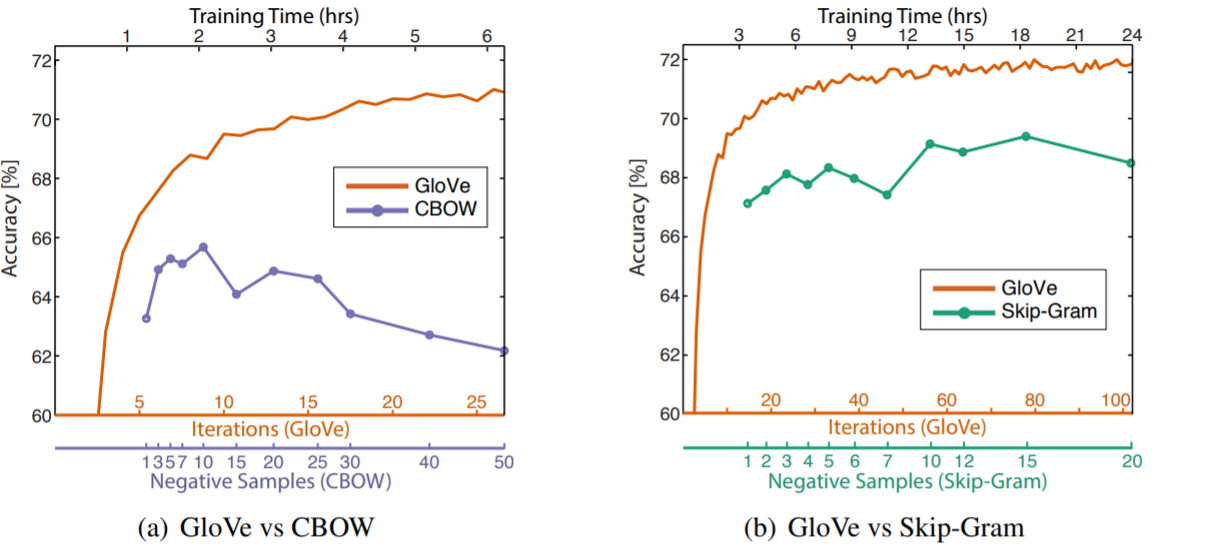
读Glove论文笔记
文章目录 1.Glove 背景介绍1.论文的背景知识2. 论文的研究成果 3.Glove历史意义 2.论文精度1.论文结构2. GloVe 模型3. 公式推导 3. 实验结果分析4.论文总结1.解词向量学习方法2.创新点3. 启发点 1.Glove 背景介绍 《Glove: Global Vectors for Word Representation》 # 1.论文导读
理解GloVe模型(+总结)
概述 模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息输入:语料库输出:词向量方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。*开始 -> 统计共现矩阵 -> 训练词向量 -> 结束 统计共现矩阵 设共现矩阵为X,其元素为Xi,j。 Xi,j的意义为:在整个语料库中,单词i和单词j共同出现在一个窗口中的次数。 举个栗子: 设有语料


工智能基础知识总结--词嵌入之GloVe
什么是GloVe GloVe(Global Vectors for Word Representation)是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等
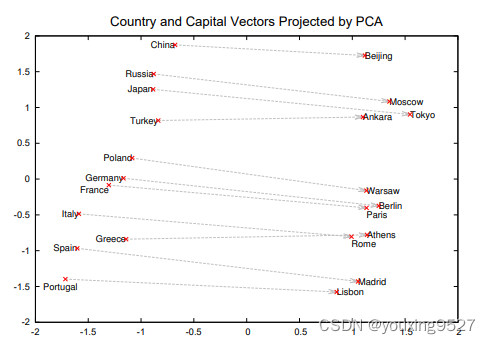
论文GloVe: Global Vectors for Word Representation(学习笔记)
来源:EMNLP 一:解决了什么问题? 1. 直接获取全局语料库统计信息的词向量模型,GloVe并非基于语料库中整个的稀疏矩阵或局部上下文窗口进行训练,而是通过训练词-词共现矩阵中的非零元素,从而有效利用统计信息。 二:怎么解决的问题?

词向量--原理、word2vec、GloVe及其实现
词向量--原理、word2vec、GloVe及其实现 数据集word2vecCBOWSkip-Gram模型改进的方法层次softmax负采样 代码实现 GloVeRefenrence 这学期选了研究生的NLP课程,期间有几次homework,在此记录一下。第一次作业的题目是 Implement a word clustering method based on neural

【如何用大语言模型快速深度学习系列】从word2vec、SVD到GloVe
三天热度果然名不虚传,写作的效率有所下降,但是只要坚持二十一天就能养成习惯啦!冲冲冲! 又被推进每日值得看啦!那我加油,尽量补充点内容,使其更加精彩! 上一节回顾 文章链接 在上一章我们将词的概念,通过n-gram组合成了n个词的切片,终于将前后词之间建立了一个联系,可以根据词的关系,逐步看见句子之间的相似度,以及根据高频词能够判断文章之间的关联程度。 上一节todo 相关代码未补充完整预

cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结
生成词向量的方法 以前大致有两种方法: ①是Matrix Factorization Method,主要代表是SVD Based的LSA等方法,核心是对共现矩阵(co-occurence)进行SVD(奇异值)分解,得到词向量。 ②是Iteration Based Method(Shallow window-based),主要代表是上节课讲到的Skip-Gram和CBOW。核心是概率,通过设置

论文记录笔记NLP(五):Glove
这篇笔记主要是结合,各种学习资源,整理而成的查找笔记,整理的不好,还望指出错误,主要是用于查找与记录。 Glove:基于全局共现信息的词表示 --Glove,在word2vec基础上的一种改进方法 摘要: 最近学习单词的向量空间表示(vector space representations of words)的方法已成功地使用向量算法(vector arithmetic)捕获细粒度
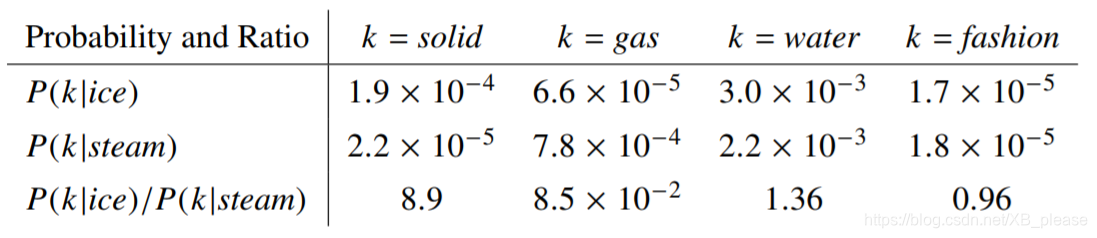
GloVe学习:Global Vectors for Word Representation
GloVe: Global Vectors for Word Representation 什么是GloVe? 正如GloVe: Global Vectors for Word Representation论文而言,GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statist

自然语言处理(四):全局向量的词嵌入(GloVe)
全局向量的词嵌入(GloVe) 全局向量的词嵌入(Global Vectors for Word Representation),通常简称为GloVe,是一种用于将词语映射到连续向量空间的词嵌入方法。它旨在捕捉词语之间的语义关系和语法关系,以便在自然语言处理任务中能够更好地表示词语的语义信息。 GloVe的设计基于两个观察结果:共现矩阵(co-occurrence matrix)和词向量的线性
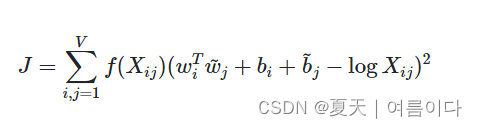
NLP | GloVe(带有全局向量的词嵌入) 图文详解及代码
GloVe(Global Vectors for Word Representation)是一种无监督学习算法,用于获取单词的向量表示。是Word2Vec模型的扩展,有助于有效地学习单词向量。训练是在来自语料库的聚合全局词-词共现统计数据上执行的,并且生成的表示显示了词向量空间的有趣线性子结构。 代码地址:stanfordnlp/GloVe: GloVe model for distribute
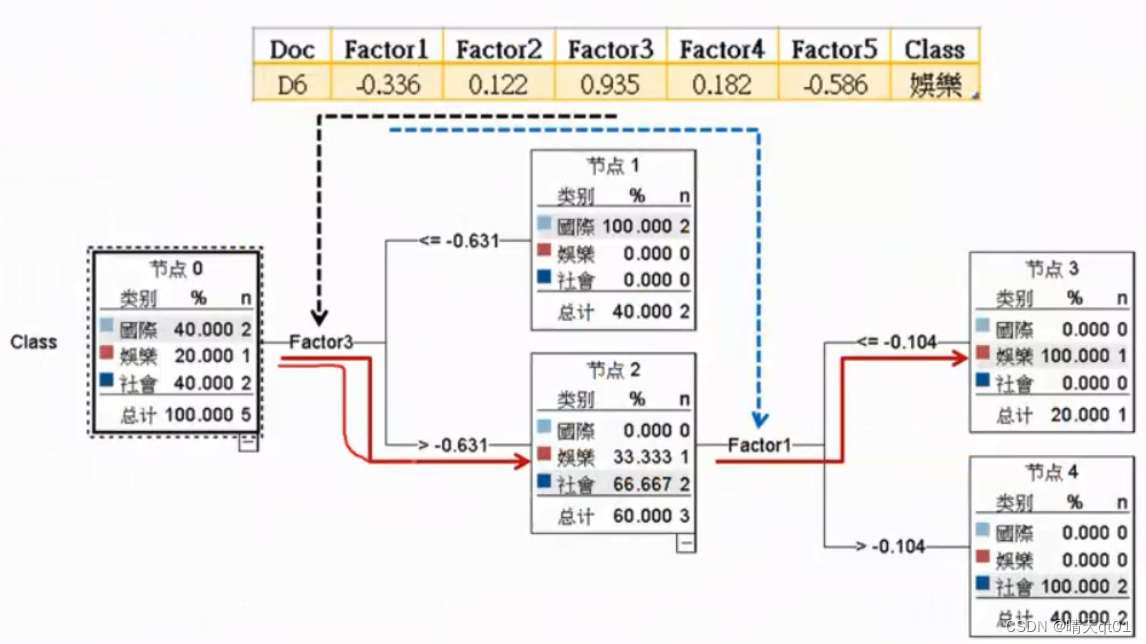
【自然语言处理与文本分析】PCA文本降维。奇异值分解SVD,PU分解法。无监督词嵌入模型Glove。有案例的将文本非结构化数据转化为结构化数据的方法。
无监督的词嵌入模型-Glove 背后的理念源头是主成分分析PCA 先变为SVD-Glove PCA是为了产生比较精简的维度,让原始数据在这个精简的维度也能保持原始的变异(信息)。 方法1就是将x2降维到x1,它从9个点变成6个点,而且牺牲了很大的信息 比较好的方法就是建立一个新的维度u。尽可能保留资料的变异。 PCA也可以做词嵌入的降维。比如 我们将词袋模型进行PCA主成分降维度

浅谈NLP预处理及WordEmbedding(Word2Vec,Glove等)
1. 文本预处理 1.1 分词器Tokenizer Tokenizer 是一个用于向量化文本的类,这是一个分词的过程。英文分词,考虑空格;中文分词就复杂点。 keras.preprocessing.text.Tokenizer(num_words=None,filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n',lower=True,split=" ",c

GloVe: Global Vectors for Word Representation阅读总结
论文:GloVe: Global Vectors for Word Representation cs224视频:https://www.bilibili.com/video/BV1pt411h7aT?t=4017&p=3 目录 一、背景介绍 二、实验方法 三、模型理解 1、和其他模型的关系 2、模型复杂度 四、实验结果 0、实验设置 1、单词类比任务(word analogy