本文主要是介绍浅谈NLP预处理及WordEmbedding(Word2Vec,Glove等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 文本预处理
1.1 分词器Tokenizer
Tokenizer 是一个用于向量化文本的类,这是一个分词的过程。英文分词,考虑空格;中文分词就复杂点。
keras.preprocessing.text.Tokenizer(num_words=None,filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n',lower=True,split=" ",char_level=False)
num_words:处理的最大单词数据量,若被设置为整数,则分词器将被限制为待处理数据集中最常见的num_words个单词;
char_level:若为True,每个字符被视为一个标记。
属性:
word_index: 字典,将单词(字符串)映射为它们的排名或者索引。仅在调用fit_on_texts之后设置。
Tokenizer几种方法应用:
包括训练fit_on_texts, texts_to_sequences,pad_sequences(将多个序列截断或补齐为相同长度。)
## some config values
embed_size = 300 # how big is each word vector
max_features = None # how many unique words to use (i.e num rows in embedding vector)
maxlen = 72 # max number of words in a question to use #99.99%## fill up the missing values
X = train["question_text"].fillna("_na_").values
X_test = test["question_text"].fillna("_na_").values## Tokenize the sentences
tokenizer = Tokenizer(num_words=max_features)
tokenizer.fit_on_texts(list(X))X = tokenizer.texts_to_sequences(X)
X_test = tokenizer.texts_to_sequences(X_test)## Pad the sentences
X = pad_sequences(X, maxlen=maxlen)
X_test = pad_sequences(X_test, maxlen=maxlen)## Get the target values
Y = train['target'].valuessub = test[['qid']]
关于OOV(out of value)的处理:
>> num_words = 3
>> tk = kpt.Tokenizer(oov_token='UNK', num_words=num_words+1)
>> texts = ["my name is far faraway asdasd", "my name is","your name is"]
>> tk.fit_on_texts(texts)
>> print(tk.word_index)
>> print(tk.texts_to_sequences(texts))
>> ## **Key Step**
>> tk.word_index = {e:i for e,i in tk.word_index.items() if i <= num_words} # <= because tokenizer is 1 indexed
>> tk.word_index[tk.oov_token] = num_words + 1
>> print(tk.word_index)
>> print(tk.texts_to_sequences(texts))
{'your': 7, 'my': 3, 'name': 1, 'far': 4, 'faraway': 5, 'is': 2, 'UNK': 8, 'asdasd': 6}
[[3, 1, 2], [3, 1, 2], [1, 2]] ## Wrong Behavior. Should not drop OOVs
{'name': 1, 'my': 3, 'is': 2, 'UNK': 4}
[[3, 1, 2, 4, 4, 4], [3, 1, 2], [4, 1, 2]] ## Correct behavior
2. Word Embedding
词向量(Word Embedding),或者词嵌入,就是把词使用向量来表示。

这里把,Embedding 分成 tf-idf(稀疏向量表示) 和 稠密向量表示。把单词用稠密向量(dense vectors)表示的方法有 NNLM, Word2vec, GloVe等方法。
tfidf 介绍看这;
这里,对用稠密向量表示单词的工具进行分类:
(1)基于预测模型
代表: googlenews, Word2Vec
(2) 基于统计单词频率模型
例如:GloVe。
2.1 NNLM
初期的prediction-based模型/神经网络语言模型(NNLM)

在这里神经网络的输入是前一个单词 w i − 1 w_{i−1} wi−1的词向量( 1-of-N Encoding )形式,经过神将网络他的输出是下一个出现的单词 w i w_i wi 是某一个词的几率,拟合目标是真实的 w i w_i wi的onehot向量。因为是 1-of-N Encoding 形式,所以输出的每一维代表是某一个词的概率。然后取输入层的权值输入作为词向量。
假如知道语料有 N 个不同的单词,每个单词经过 one-hot为 N N N维向量.
NNLM的输入是 w t − 1 w_{t-1} wt−1的onehot 向量,目标是它下一时刻单词 w t w_t wt的onehot向量。
所以,输入层,输出层的节点个数都是 N。经过训练后,输出层代表 w t − 1 w_{t-1} wt−1下一个单词是语料中对应索引单词的概率。
图中, z z z 是隐层,或者Embedding层,节点数远比N要小。我们把所有连接到 w 1 w_1 w1 非零的节点的权重值当作一个向量,也就是隐层 z z z,当做输入单词 w t − 1 w_{t-1} wt−1或者 w t w_t wt的词向量, 这里把隐层向量 z z z当做 w t w_t wt 的词向量了。
改进的NNLM模型
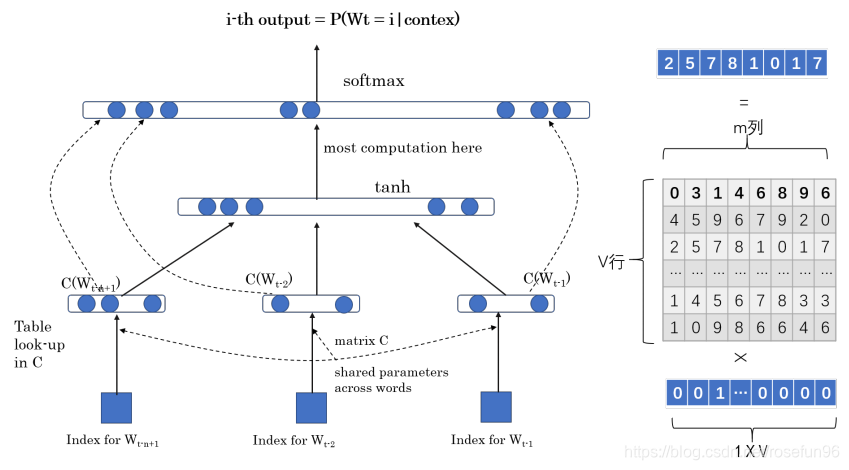
既然可以用前面的一个 w t − 1 w_{t-1} wt−1来预测后一个 w t w_t wt,我们也可以用多个前面的单词,比如, w t − n + 1 , . . . , w t − 1 w_{t-n+1},...,w_{t-1} wt−n+1,...,wt−1 来预测后面的单词 w t w_t wt。
用到的技巧是,把输入的单词 w t − 1 w_{t-1} wt−1的onehot向量乘于一个随机的Q矩阵,得到 C ( W t − 1 ) C(W_{t-1}) C(Wt−1),然后,把他们拼接,最后,输出为下一个单词 w t w_t wt为词料中某个单词的概率。训练后的Q矩阵的每一行就是相应单词的词向量。
2.2 Word2vec
word2vec 是 google 在2013年提出 NLP 模型,它的特点是将所有的词表示成低维稠密向量,从而可以在词向量空间上定性衡量词与词之间的相似性。
onehot ,使用0-1来对字符串编码,也是word2vec,但是有个缺点,如果出现的不同的字符串个数很多,那么维度就很大。
因此,我们引入表。
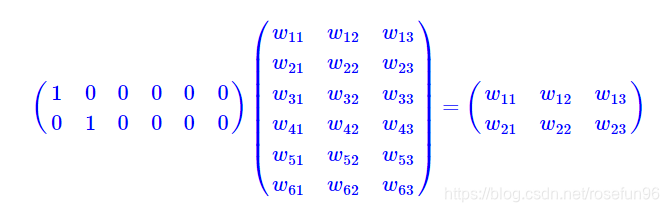
中间W 矩阵,相当于一个表,行维度应该包含输入输入内容的所有元素个数,比如一定领域的汉字作为输入,这个表的行数可能就上万了。 W矩阵,可以看成一个全连接神经网络层,也就是所谓的 Embedding层。
一旦训练好embedding层,把text 转化为向量后,获得 index 矩阵,直接查表,就可以获得word embedding了。
示例:
一般把分词后padding 的数据作为Word2vec模型的输入。
TensorFlow/Keras模型Embedding Layer参数:
tf.keras.layers.Embedding(input_dim,output_dim,embeddings_initializer="uniform",embeddings_regularizer=None,activity_regularizer=None,embeddings_constraint=None,mask_zero=False,input_length=None,**kwargs
)
定义Embedding Layer:
model = Sequential()
model.add(Embedding(1000, 64, input_length=10))
# 模型将输入一个大小为 (batch, input_length) 的整数矩阵。
# 输入中最大的整数(即词索引)不应该大于 999 (词汇表大小)
# 现在 model.output_shape == (None, 10, 64),其中 None 是 batch 的维度。
input_array = np.random.randint(1000, size=(32, 10))
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64)
除了使用模型进行训练之外,还可以使用一些已经训练好的词向量,只需要找到你文本里边的词对应的index加载即可。开源的词向量有word2vec api.
Keras载入已经训练好的Embedding矩阵emb:
emb_layer = Embedding(input_dim=emb1.shape[0],output_dim=emb.shape[1],
weights=[emb],input_length=90,trainable=False)
注意:这里weights参数是Keras Layer的参数,Embedding 层是Layer的子类。
关于网络训练问题:
严格来讲,神经网络都是有监督的,而Word2Vec之类的模型,准确来说应该是“自监督”的,它事实上训练了一个语言模型,通过语言模型来获取词向量。所谓语言模型,就是通过前nn个字预测下一个字的概率,就是一个多分类器而已,我们输入one hot,然后连接一个全连接层,然后再连接若干个层,最后接一个softmax分类器,就可以得到语言模型了,然后将大批量文本输入训练就行了,最后得到第一个全连接层的参数,就是字、词向量表,当然,Word2Vec还做了大量的简化,但是那都是在语言模型本身做的简化,它的第一层还是全连接层,全连接层的参数就是字、词向量表。
这样看,问题就比较简单了,我也没必要一定要用语言模型来训练向量吧?对呀,你可以用其他任务,比如文本情感分类任务来有监督训练。因为都已经说了,就是一个全连接层而已,后面接什么,当然自己决定。当然,由于标签数据一般不会很多,因此这样容易过拟合,因此一般先用大规模语料无监督训练字、词向量,降低过拟合风险。注意,降低过拟合风险的原因是可以使用无标签语料预训练词向量出来(无标签语料可以很大,语料足够大就不会有过拟合风险),跟词向量无关,词向量就是一层待训练参数,有什么本事降低过拟合风险?
Word2Vec两种实现
Word2Vec和NNLM类似,但做了一些改变,实现有 CBOW(Continuous Bags of Words Model)和Skip-Gram(Continuous Skip-gram model)。

首先,CBOW 在NNLM的基础上,引入了下文单词 w t + 1 , . . . , w t + n w_{t+1},...,w_{t+n} wt+1,...,wt+n。
而 Skip-gram 则和CBOW相反,它输入是当前时刻单词 w t w_t wt,输出是它临近各个时刻 . . . , w t − 1 , w t + 1 , . . . ...,w_{t-1}, w_{t+1},... ...,wt−1,wt+1,...是哪几个单词的概率,拟合的目标就是 w t w_t wt附近这些时刻 . . . , w t − 1 , w t + 1 , . . . ...,w_{t-1}, w_{t+1},... ...,wt−1,wt+1,...的onehot向量拼接成的大向量。
2.3 GLOVE模型
Word2Vec 之后又有GloVe 模型产生。
GloVe模型主要思路如下图所示 :

两词向量共同出现的频率比较高的话,那么这两个词向量也应该比较相似。所以两个词向量的点积应该与它们公共出现的次数成正比.
GloVe模型公式:
代价函数:
J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − log ( X i , j ) ) 2 J=\sum_{i, j}^{N} f\left(X_{i, j}\right)\left(v_{i}^{T} v_{j}+b_{i}+b_{j}-\log \left(X_{i, j}\right)\right)^{2} J=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2
v i , v j v_{i}, v_{j} vi,vj是单词 i i i和单词 j j j的词向量, b i , b j b_{i}, b_{j} bi,bj是两个标量(偏差项), f f f是权重函数(具体函数公式及功能下一节介绍), N N N是词汇表的大小(共现矩阵维度为 N ∗ N N*N N∗N), X i , j X_{i,j} Xi,j是共现矩阵。。
可以看到,GloVe模型没有使用神经网络的方法
具体权重函数, 首先应该是非减的,其次当词频过高时,权重不应过分增大,作者通过实验确定权重函数为:
f ( x ) = { ( x / x max ) 0.75 , if x < x max 1 , if x > = x max f(x)=\left\{\begin{array}{ll}{(x / x \max )^{0.75},} & {\text { if } x<x \max } \\ {1,} & {\text { if } x>=x \max }\end{array}\right. f(x)={(x/xmax)0.75,1, if x<xmax if x>=xmax
2.4 paragram
释义数据库PPDB(the Paraphrase Database)来学习通用的sentence embeddings。
论文模型的基本流程是输入mini-batch的释义对 ( < x 1 , x 2 > ) (<x_1, x_2>) (<x1,x2>)集合 ( X b ) (X_b) (Xb),并通过对\(X_b\)中的句子进行采样得到\(x_1,x_2\)对应的负样本\(t_1, t_2\),将这四个句子通过编码器(编码函数)\(g\)得到句子编码,然后使用一种 margin-based loss进行优化,损失函数的基本思想是希望编码后的释义对\(<x_1,x_2>\)能够非常相近而非释义对\(<x_1,t_1>\)和\(<x_2,t_2>\)能够有不小于\(\delta\)的间距。

原论文;
2.5 wiki news

wiki news 训练加入子词信息,n_gram对单词进行提取信息。
2.6 随机Embedding
如果没有训练好的语料,Embedding层先用随机的Vector来代替。
import torch.nn as nn
import torch embedding_size = 10
max_idx = 10000
embedding = nn.Embedding(max_idx, embedding_size, padding_idx=0)
input = np.array([7788, 9992, 9999])
embedding(torch.LongTensor(input))
结果:
tensor([[-0.6454, 1.0659, 0.8753, 0.0054, -0.8724, 0.7973, 0.1209, -0.2043,0.1764, 0.0975],[-0.8743, 1.6775, 0.5449, 0.1142, 0.8465, 1.6576, 0.3122, -0.4616,1.0896, 2.5375],[ 1.4861, -1.5820, 1.0397, 0.0299, -0.5425, -0.0418, 0.0634, 1.2271,0.0850, 0.0540]], grad_fn=<EmbeddingBackward>)
2.7 小结: GloVe模型和Word2Vec模型区别
区别:
两者最直观的区别在于,word2vec是predictive的模型,而GloVe是count-based模型。
不采用 negative sampling 的word2vec 速度非常快,但是准确率仅有57.4%。只告诉模型什么是有关的,却不告诉它什么是无关的,模型很难对无关的词进行惩罚从而提高自己的准确率.
在python的gensim这个包里,gensim.models.word2vec. Word2Vec默认是不开启negative sampling的,需要开启的话请设置negative参数,如何设置文档中有明确说明gensim: models.word2vec. 当使用了negative sampling之后,为了将准确率提高到68.3%,word2vec就需要花较长的时间了(8h38m)
相比于word2vec,因为golve更容易并行化,所以速度更快,达到67.1%的准确率,只需要花4h12m。
由于GloVe算法本身使用了全局信息,自然内存费的也就多一些,相比之下,word2vec在这方面节省了很多资源.
3. 总结
NLP对文本数据处理有两种:
1、词袋模型
其中,词袋模型又可以分成3种,tfidf、CountVector、HashVector。
2、词向量方法
其中,词向量分为onehot、常见的Word2Vec;word2vec根据上下文推中间文字,或者根据中间文字推上下文;其中,对于句子,目前一些模型,如fastrnn, 使用句子单词的词向量求和作为输入。
目前,处理文本思路有 RNN(把词向量作为输入);CNN、Attention三种。
reference:
- towardsdatascience :A non-nlp application of word2vec;
- (推荐)Keras Tokenizer 介绍;
- bojone: 词向量与embedding;
- keras: embedding层;
- cs124 pdf CS 124/LINGUIST 180 From Languages to Information ;
- github :awesome embedding;
- 论文: wiki news model, Advances in Pre-Training Distributed Word Representations;
- csdn: blog 无监督学习:词嵌入;
- csdn :理解GloVe模型(Global vectors for word representation);
- github: glove简单pytorch代码实现 ;
- blog :nlp面经;
- 知乎: [NLP] 秒懂词向量Word2vec的本质;
- CNblog: NLP之Word2Vec详解;
- cloudTencent :将句子表示为向量(下):基于监督学习的句子表示学习(sentence embedding);
- 知乎: 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史;
- Using Tokenizer with num_words;
这篇关于浅谈NLP预处理及WordEmbedding(Word2Vec,Glove等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





