本文主要是介绍NLP | GloVe(带有全局向量的词嵌入) 图文详解及代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GloVe(Global Vectors for Word Representation)是一种无监督学习算法,用于获取单词的向量表示。是Word2Vec模型的扩展,有助于有效地学习单词向量。训练是在来自语料库的聚合全局词-词共现统计数据上执行的,并且生成的表示显示了词向量空间的有趣线性子结构。
代码地址:stanfordnlp/GloVe: GloVe model for distributed word representation (github.com)![]() https://github.com/stanfordnlp/GloVe
https://github.com/stanfordnlp/GloVe
Pennington等人认为,word2vec算法使用的在线扫描方法是次优的,因为它没有充分利用有关单词共出现的统计信息。因此,他们开发了一个GloVe模型,该模型结合了Word2vec跳过语法模型在单词类比任务方面的优势,以及可以利用全局统计信息的矩阵分解方法的优点。
在经典的向量空间模型中,单词的表示是通过使用矩阵分解技术(如潜在语义分析(LSA))开发的,这些技术在使用全局文本统计方面做得很好,但在捕获含义并在计算类比等任务中演示它方面不如Word2vec模型等学习方法。
例如,男性/女性关系是自动学习的,并且通过诱导的向量表示,“国王 - 男人+女人”导致向量非常接近“女王”。
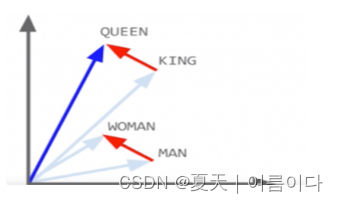
GloVe的优点在于,与Word2vec不同,GloVe不仅依赖于局部统计信息(单词的本地上下文信息),而是结合全局统计信息(单词共现)来获得单词向量。
GloVe可以从共现矩阵(co-occurrence probabilities matrix)中派生单词之间了解语义关系。
1.共现矩阵(co-occurrence probabilities matrix)
1.1.共现矩阵的统计特性

- 共现频率矩阵的所有元素之和
- 共现概率矩阵
- 通过对p(i,j)的行求和得到的边际概率矩阵中的条目
- 通过对p(i,j)的列求和得到的边际概率矩阵中的条目。
1.2.共现矩阵的构建
与作为矩形矩阵的出现矩阵不同,共现矩阵是一个方阵,它描述了上下文中两个词项的共现。因此,共现矩阵有时也称为词项矩阵。它是一个方阵,因为它是每个术语和另一个术语之间的矩阵。
通常有两种方法遵循
- 术语-上下文矩阵例如,每个句子都表示为一个上下文(也可以有其他定义)。如果两个术语出现在相同的上下文中,则称它们出现在相同的出现上下文中。
- k-skip-n-gram方法 例如,滑动窗口将包括 (k+n) 个单词。该窗口现在将用作上下文。在这种情况下同时出现的术语被认为是同时出现的。
词上下文矩阵的缺点是它不会考虑虽然相近但在不同句子中的词
举个例子:语料库中有以下俩句话
There is a bird sitting on a wall.
The cat is sitting on the fence.
对这些单词进行处理,可分为
bird, sitting, wall, cat, fence
对于这些存在于相同句子中的单词,术语-上下文共现矩阵将如下所示。
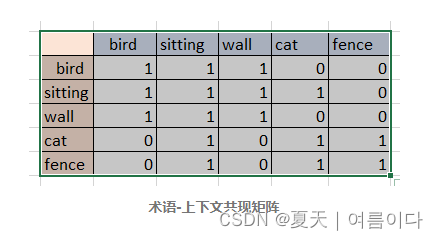
- 三个单词在同一句话为真1,不是同一句话为假0.
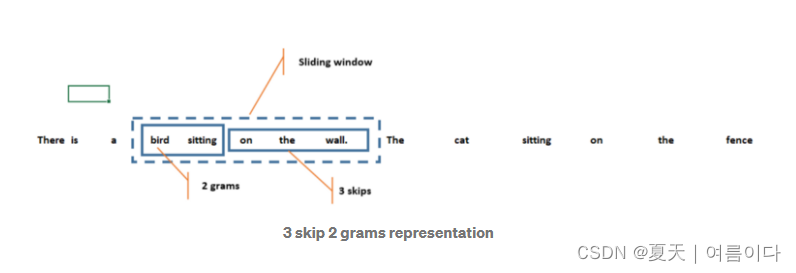
k-skip-n-gram 矩阵并假设k=3 和 n=2
那么就是3-skip-2-gram 矩阵。共现将变成如下图所示。这将形成一个大小为 3+2=5 的滑动窗口,并尝试找到2个gram,一个gram不超过 4 个单词。
以此为基础,创建新的矩阵如下
(bird,sitting), (bird,wall),(sitting,wall),(sitting,cat),(wall,cat),(cat,fence),(sitting,fence)
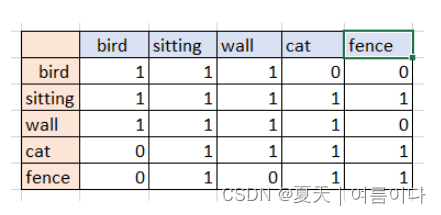
- 这也将表示墙和猫之间的相似性。因此,使用 skip gram 模型,上下文范围从句子扩大到 k+n 大小的滑动窗口,可以根据提供的数据进行调整。
2.从共现概率的比率解释 GloVe
pij=def P(wj∣wi) 是生成上下文词的条件概率wj给定 wi作为语料库中的中心词。那么给定单词ice和stream的共现概率如图
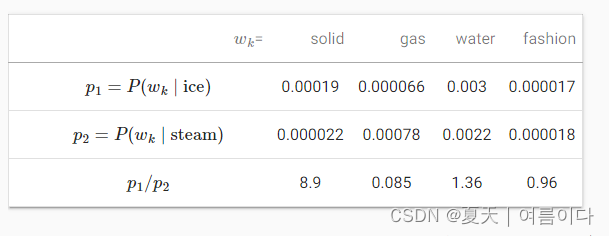
我们可以得到以下信息:
-
一句话wk与“ice”有关但与“gas”无关的,例如wk=solid,我们预计共现概率的比率更大-8.9。
-
一句话wk与“gas”相关但与“ice”无关的,例如wk=gas,我们预计共现概率的比率较小是0.085。
-
一句话wk与“ice”和“gas”有关,例如wk=water,共现概率的比率接近 1是1.36。
-
一句话wk与“ice”和“gas”无关,例如wk=fashion,共现概率的比率接近 1是0.96。
可见,共现概率的比值可以直观地表达词之间的关系。因此,我们可以设计一个三个词向量的函数来拟合这个比率。对于共现概率的比率pij/pik和wi 作为中心词和wj和wk作为上下文词,我们想使用一些函数来拟合这个比率f:

![]()
在许多可能的设计中f,我们只在下面选择一个合理的选择。由于共现概率的比率是一个标量,我们要求f是一个标量函数,例如 f(uj,uk,vi)=f((uj−uk)⊤vi). 切换词索引j和k在上文中,它必须持有f(x)f(−x)=1,所以一种可能性是 f(x)=exp(x), IE,
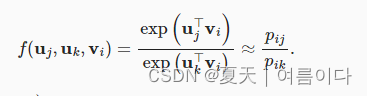
现在让我们挑选 exp(uj⊤vi)≈αpij, 在哪里α是一个常数。自从pij=xij/xi, 两边取对数后得到 uj⊤vi≈logα+logxij−logxi. 我们可能会使用额外的偏置项来拟合 −logα+logxi,比如中心词偏差 bi和上下文词偏差cj:

用权重测量的平方误差,得到GloVe损失函数。
GloVe 嵌入是一种词嵌入,它将两个单词之间的共现概率比编码为向量差。GloVe 使用加权最小二乘目标J将两个单词的向量的点积与其共出现次数的对数之间的差异最小化:
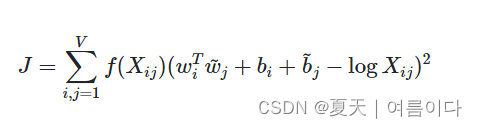
当Wi和bi分别是单词的向量和单词的偏差i,wj的导和bj分别是单词的上下文词向量和偏置词j,Xij是单词的次数i发生在单词的上下文中j和f是一个加权函数,可为罕见和频繁的共生事件分配较低的权重。
3.Glove,skip-gram,CBOW的区别
Word2Vec 是一种将单词嵌入向量的方法,用于预测中心单词作为中心词和外围单词。使嵌入单词的内积成为辅词相似性。GloVe研究小组还提到了潜在意义分析(LSA)的缺点,即对单词-上下文矩阵进行奇异值解(SVD),从而有效地缩小数据维度,同时减少噪声等,从而产生内在含义。
4.代码
环境:Anaconda3里的Jupyter Notebook
下载https://github.com/stanfordnlp/GloVe/archive/master.zip
import shutil
import gensimdef getFileLineNums(filename): f = open(filename,'r') count = 0 for line in f: count += 1 return countdef prepend_line(infile, outfile, line): """ Function use to prepend lines using bash utilities in Linux. (source: http://stackoverflow.com/a/10850588/610569) """ with open(infile, 'r') as old: with open(outfile, 'w') as new: new.write(str(line) + "\n") shutil.copyfileobj(old, new)def prepend_slow(infile, outfile, line): """ Slower way to prepend the line by re-creating the inputfile. """ with open(infile, 'r') as fin: with open(outfile, 'w') as fout: fout.write(line + "\n") for line in fin: fout.write(line) def load(filename): # Input: GloVe Model File # More models can be downloaded from http://nlp.stanford.edu/projects/glove/ # glove_file="glove.840B.300d.txt" glove_file = filename dimensions = 50 num_lines = getFileLineNums(filename) # num_lines = check_num_lines_in_glove(glove_file) # dims = int(dimensions[:-1]) dims = 50 print(num_lines) # # # Output: Gensim Model text format. gensim_file='glove_model.txt' gensim_first_line = "{} {}".format(num_lines, dims) # # # Prepends the line. #if platform == "linux" or platform == "linux2": prepend_line(glove_file, gensim_file, gensim_first_line) #else: # prepend_slow(glove_file, gensim_file, gensim_first_line) # Demo: Loads the newly created glove_model.txt into gensim API. model=gensim.models.KeyedVectors.load_word2vec_format(gensim_file,binary=False) #GloVe Model model_name = gensim_file[6:-4] model.save(model_name) return modelif __name__ == '__main__': myfile='GloVe-master/vectors.txt'model = load(myfile)############# 模型加载 ######################## model_name='glove_model.txt'# model = gensim.models.KeyedVectors.load(model_name) print(len(model.vocab)) word_list = [u'to',u'one'] for word in word_list: print(word,'--')for i in model.most_similar(word, topn=10): print(i[0],i[1])print('')总结:
-
可以使用全局语料库统计信息(例如词-词共现计数)来解释 skip-gram 模型。
-
交叉熵损失可能不是衡量两个概率分布差异的好选择,尤其是对于大型语料库。GloVe 使用平方损失来拟合预先计算的全局语料库统计数据。
-
对于 GloVe 中的任何单词,中心词向量和上下文词向量在数学上是等价的。
-
GloVe 可以从词-词共现概率的比率来解释。
参考文献
【1】GloVe: Global Vectors for Word Representation (stanford.edu)
【2】 Intuitive Guide to Understanding GloVe Embeddings | by Thushan Ganegedara | Towards Data Science
【3】GloVe: Global Vectors for Word Representation-InsideAIML
【4】 四步理解GloVe!(附代码实现) (wjhsh.net)
【5】 15.5. Word Embedding with Global Vectors (GloVe) — Dive into Deep Learning 1.0.0-alpha1.post0 documentation
【6】 https://becominghuman.ai/mathematical-introduction-to-glove-word-embedding-60f24154e54c
这篇关于NLP | GloVe(带有全局向量的词嵌入) 图文详解及代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





