本文主要是介绍读Glove论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.Glove 背景介绍
《Glove: Global Vectors for Word Representation》
# 1.论文导读
1.论文的背景知识
词的表示方法
-
矩阵分解方法
(Matrix Factorization Methods)
词共现矩阵
- I enjoy flying 。
- I like NLP。
- I like deep learning。
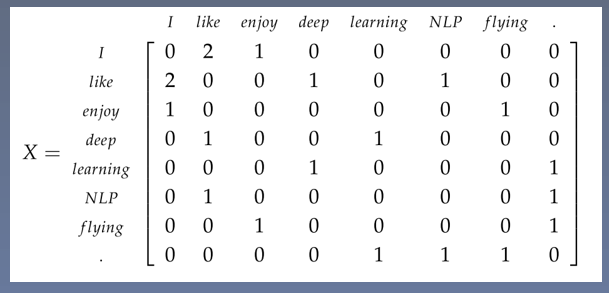
缺点: 在词对推理任务上表示特别差。
-
基于上下文的向量学习方法
(Shallow Window-Based Methods)
Word2Vec
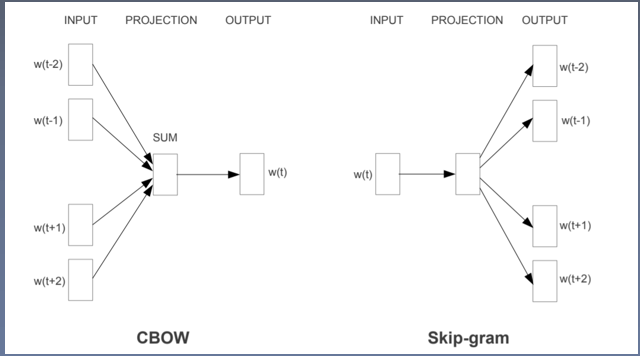
缺点:无法使用全局的统计信息。
2. 论文的研究成果
- 在词对推理数据集上取得最好的结果
- 公布了一系列基于Glove 的预训练词向量
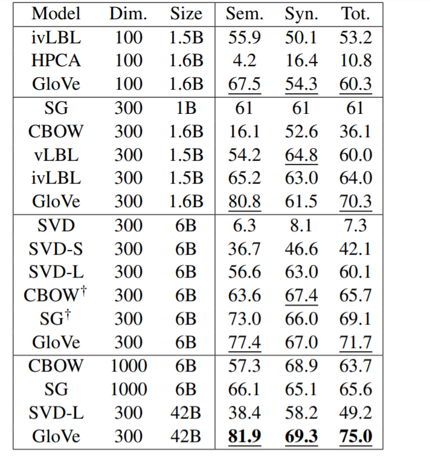
3.Glove历史意义
- 推动了基于深度学习的自然语言处理的发展


2.论文精度
1.论文结构
- 论文总览
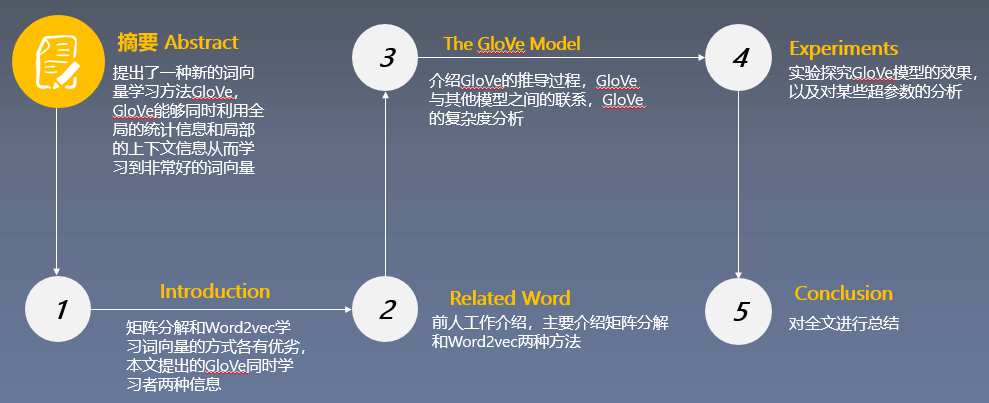
-
论文摘要
- 当前词向量学习模型能够通过向量的算术计算捕捉词之间细微的语法和语义规律,但是这种规律背后的原理依旧不清楚
- 经过仔细的分析,我们发现了一些有助于这种词向量规律的特性,并基于词提出了一种新的对数双线性回归模型,这种模型能够利用全局矩阵分解和局部上下文的优点来学习词向量。
- 我们的模型通过只在共线矩阵中的非0位置训练达到高效训练的目的。
- 我们的模型在词对推理任务上得到75%的准确率,并且在多个任务上得到最优结果。
-
论文的小标题
Introduction
Related Work
2.1 Matrix Factorization Methods
2.2 Shallow Window Based Methods
The GloVe Model
3.1 Relationship to Other Models
3.2 Complexity of the model
Experiments
4.1 Evaluation methods
4.2 Corpora and training details
4.3 Results
4.4 Model Analysis: Vector Length and Context Size
4.5 Model Analysis: Corpus Size
4.6 Model Analysis: Run-time
4.7 Model Analysis : Comparison with word2vec
- Conclusion
2. GloVe 模型
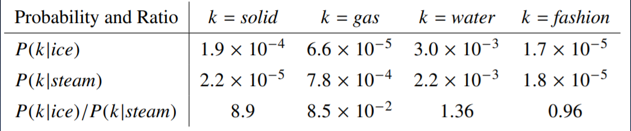
观察分析
原理:我们可以使用一些词来描述一个词,比如我们使用冰块和蒸汽来描述固体、气体、水和时尚四个词。
- 与冰块接近,并且和蒸汽不接近:固体并且概率比值很大
- 与蒸汽接近,并且和冰块不接近:气体并且概率比值很小
- 与冰块和蒸汽都不接近: 水和时尚并且概率比值不大不小
结论:共线矩阵的概率比值可以用来区分词。
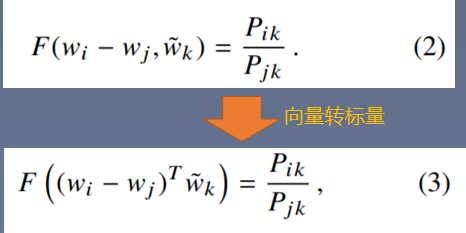
3. 公式推导


- 求得的损失函数
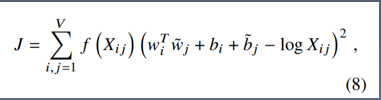
- 原理:词对出现次数越多,那么这两个词在loss函数中的影响越大。
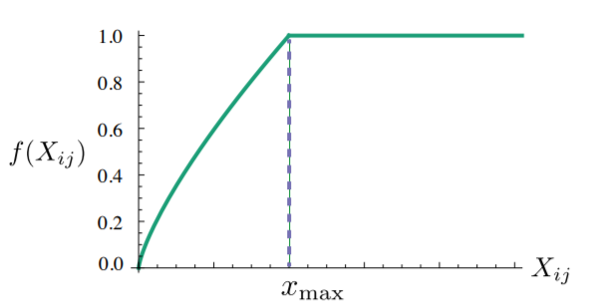
f(Xij)需要满足:
- Xij=0时, f(Xij) = 0 : 表示没有共线过的权重为0, 不参加训练
- 非减函数,因为共线次数越多,权重越大
- f(Xij)不能无限制的大,防止is, are, the的影响
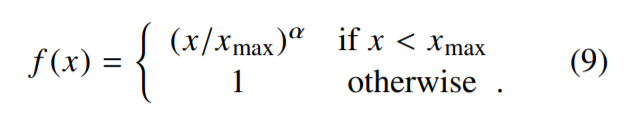
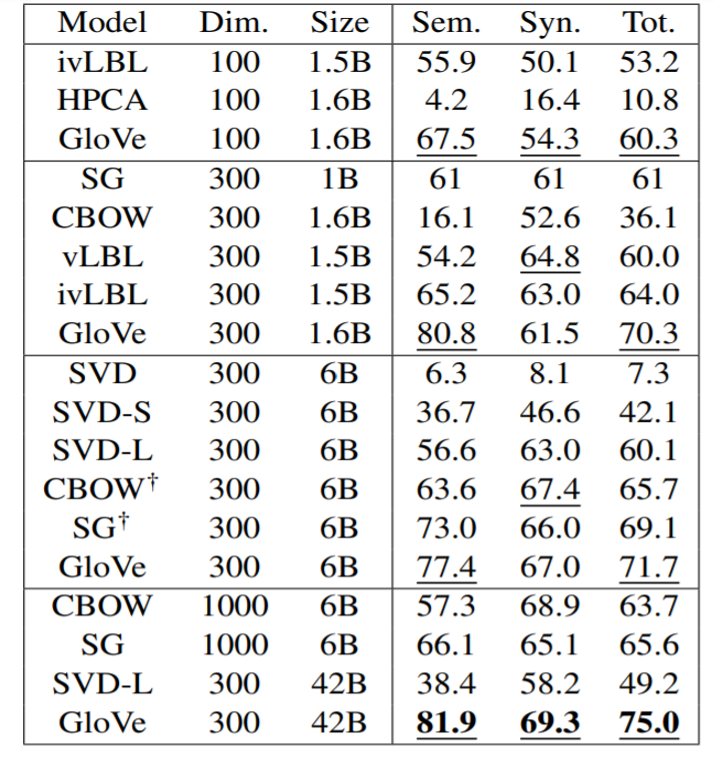
3. 实验结果分析
- 在词对推理数据集上取得最好得结果
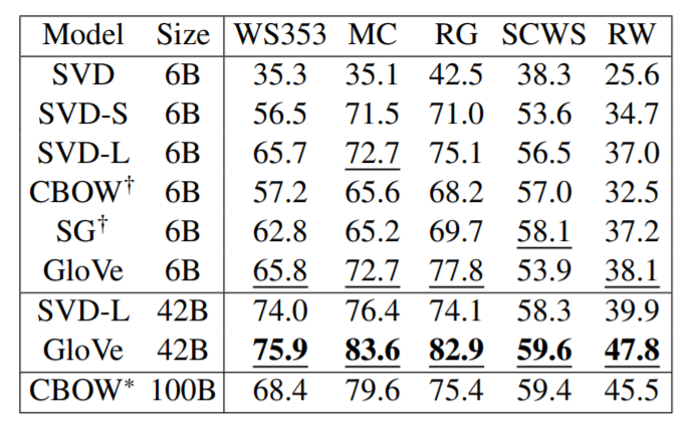
-
多个词相似度任务上取得最好得结果
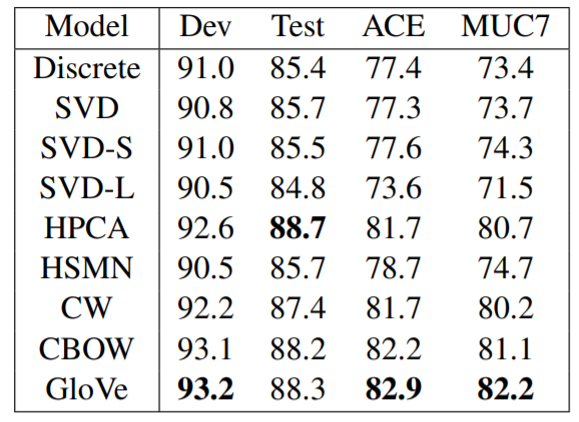
-
命名实体识别实验结果
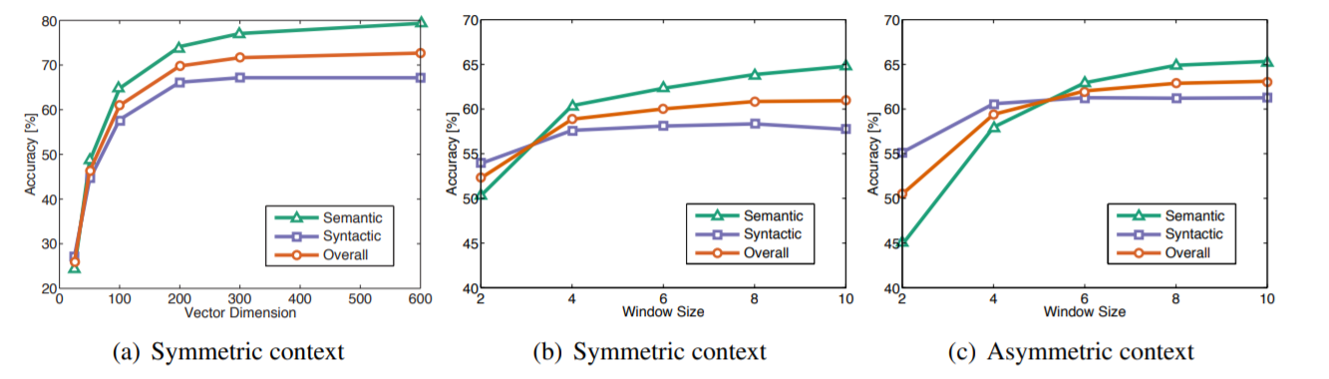
- 向量长度对结果的影响
- 窗口大小对结果的影响
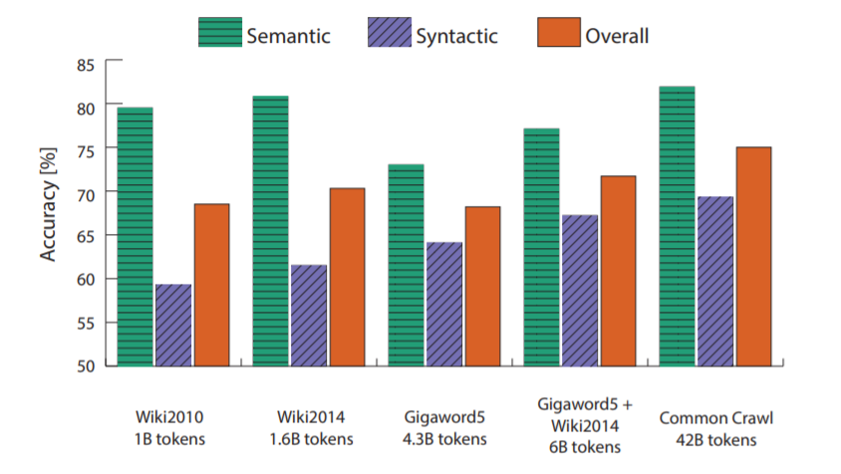
- 训练语料对结果的影响
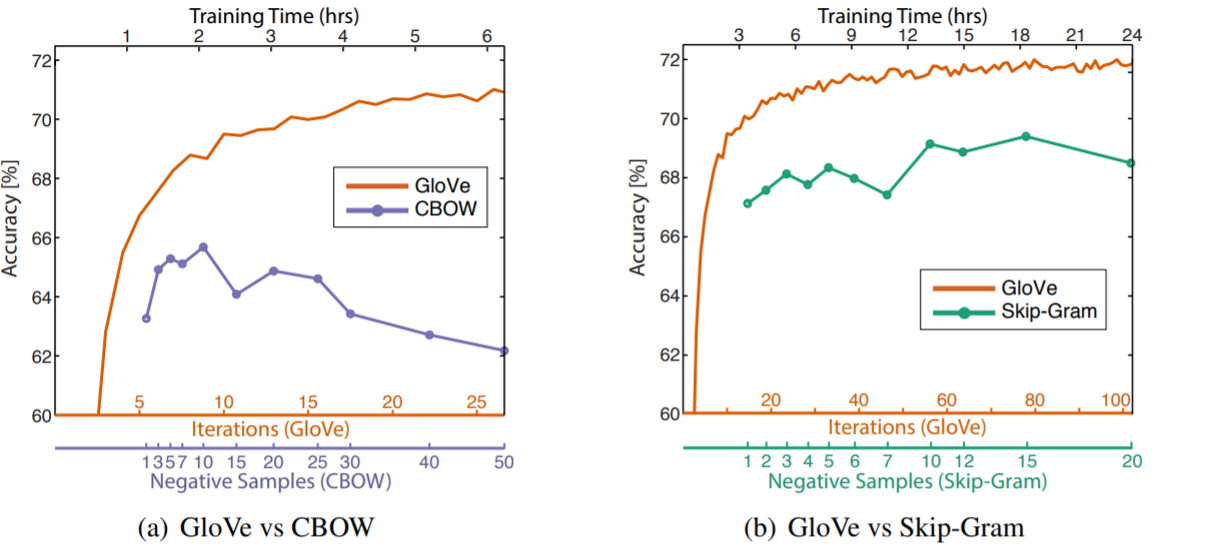
- 和Word2vec对比实验
4.论文总结
1.解词向量学习方法
- 基于上下文的词向量学习方法
- 预训练词向量
2.创新点
- 提出了一种新的词向量训练模型-- Glove
- 在多个任务上取得最好的结果
- 公布了一系列预训练的词向量
3. 启发点
- 相对于原始的概率,概率的比值更能够区分相关的词和不相关的词,并且能够区分两种相关的词。
- 提出了一种新的对数双线性回归模型,这种模型结合全局矩阵分解和局部上下文的优点。
这篇关于读Glove论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







