本文主要是介绍InternImage: 使用可变形卷积探索大规模视觉基础模型(Exploring Large-Scale Vision Foundation Models with Deformable Conv),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://arxiv.org/pdf/2211.05778v4.pdf https://arxiv.org/pdf/2211.05778v4.pdf
https://arxiv.org/pdf/2211.05778v4.pdf
代码库:https://github.com/OpenGVLab/InternImage/tree/masterhttps://github.com/OpenGVLab/InternImage/tree/master
0.摘要
相较于近年来大规模视觉Transformer(ViT)取得的巨大进展,基于卷积神经网络(CNN)的大规模模型仍处于早期阶段。本文提出了一种新的基于CNN的大规模基础模型,称为InternImage,它可以像ViTs那样从增加参数和训练数据中获益。与近期专注于大型密集卷积核的CNN不同,InternImage将可变形卷积作为核心运算符,因此我们的模型不仅具有下游任务(如检测和分割)所需的大有效感受野,而且具有由输入和任务信息条件化的自适应空间聚合。因此,所提出的InternImage减少了传统CNN的严格归纳偏差,并使得从类似ViTs的大规模数据中学习到更强大和更稳健的模式成为可能。我们的模型在包括ImageNet、COCO和ADE20K在内的具有挑战性的基准测试中证明了其有效性。值得一提的是,InternImage-H在COCO test-dev上取得了新的记录,达到了65.4的mAP,并在ADE20K上达到了62.9的mIoU,超过了当前领先的CNN和ViTs。
1.引言
随着大规模语言模型中transformers的显著成功[3-8],视觉transformers(ViTs)[2,9-15]也席卷了计算机视觉领域,并成为大规模视觉基础模型研究和实践的首选。一些先驱者[16-20]尝试将ViTs扩展到超过十亿参数的超大模型,击败了卷积神经网络(CNNs),并显著推动了广泛范围的计算机视觉任务(包括基本分类、检测和分割)的性能界限。尽管这些结果表明,在大规模参数和数据时代,CNNs相对于ViTs的表现较差,但我们认为,当CNN-based基础模型配备类似的操作器/架构级设计、参数扩展和大规模数据时,它们也能够实现与ViTs相媲美甚至更好的性能。为了弥合CNNs和ViTs之间的差距,我们首先从两个方面总结它们的差异:
(1)从操作器级别[9,21,22]来看,ViTs的多头自注意力(MHSA)具有长程依赖性和自适应空间聚合(见图1(a))。受益于灵活的MHSA,ViTs能够从大规模数据中学习出比CNNs更强大和稳健的表示。
(2)从架构视角[9,22,23]来看,除了MHSA,ViTs还包含一系列标准CNNs中不包括的先进组件,例如层归一化(LN)[24],前馈网络(FFN)[1],GELU [25]等。尽管最近的研究[21,22]通过使用具有非常大的卷积核(例如31×31)的密集卷积来引入CNNs的长程依赖性(如图1(c)所示),但在性能和模型规模方面,与最先进的大规模ViTs [16,18-20,26]仍存在相当大的差距。
在这项工作中,我们专注于设计一种基于CNN的基础模型,能够高效地扩展到大规模的参数和数据。具体而言,我们从一种灵活的卷积变体——可变形卷积(DCN)[27,28]开始。通过将它与一系列与transformers类似的定制块级和架构级设计相结合,我们设计了一个全新的卷积骨干网络,称为InternImage。如图1所示,与最近改进的具有非常大卷积核(例如31×31)的CNNs不同,InternImage的核心操作器是一个具有3×3常见窗口大小的动态稀疏卷积,
(1)其采样偏移量可以灵活地从给定数据中动态学习适当的感受野(可以是长程或短程);
(2)采样偏移量和调制标量根据输入数据自适应调整,可以实现像ViTs一样的自适应空间聚合,减少了常规卷积的过度归纳偏差;
(3)卷积窗口是一个常见的3×3,避免了大型稠密卷积核[22,29]引起的优化问题和高昂的代价。
通过上述设计,所提出的InternImage可以高效地扩展到大规模参数规模,并从大规模训练数据中学习到更强的表示,在各种视觉任务上实现与大规模ViTs [2,11,30]相当甚至更好的性能。总之,我们的主要贡献如下:
(1)我们提出了一种新的大规模基于CNN的基础模型——InternImage。据我们所知,这是第一个能够有效扩展到超过10亿参数和4亿训练图像,并实现与最先进的ViTs相当甚至更好性能的CNN,表明卷积模型也是一个值得探索的大规模模型研究方向。
(2)我们通过引入长程依赖性和改进的3×3 DCN操作符,以及围绕该操作符的定制基本块、堆叠规则和扩展策略,成功地将CNN扩展到大规模设置中。这些设计有效地利用了操作符,使我们的模型能够从大规模参数和数据中获得收益。
(3)我们通过将模型大小从3000万扩展到10亿,数据从100万扩展到4亿,对所提出的模型在代表性的视觉任务(包括图像分类、目标检测、实例和语义分割)上进行了评估,并与最先进的CNN和大规模ViTs进行了比较。具体而言,我们的不同参数大小的模型在ImageNet [31]上始终优于之前的方法。InternImage B在仅使用ImageNet-1K数据集进行训练时,达到了84.9%的top-1准确率,至少比基于CNN的对手[21,22]高出1.1个百分点。使用大规模参数(即10亿)和训练数据(即4.27亿)时,InternImage-H的top-1准确率进一步提高到89.6%,接近精心设计的ViTs [2,30]和混合ViTs [20]。此外,在COCO [32]这个具有挑战性的下游基准测试中,我们的最佳模型InternImage-H以21.8亿参数实现了65.4%的box mAP,比使用27%更少参数的SwinV2-G [16](65.4 vs. 63.1)高2.3个百分点,如图2所示。
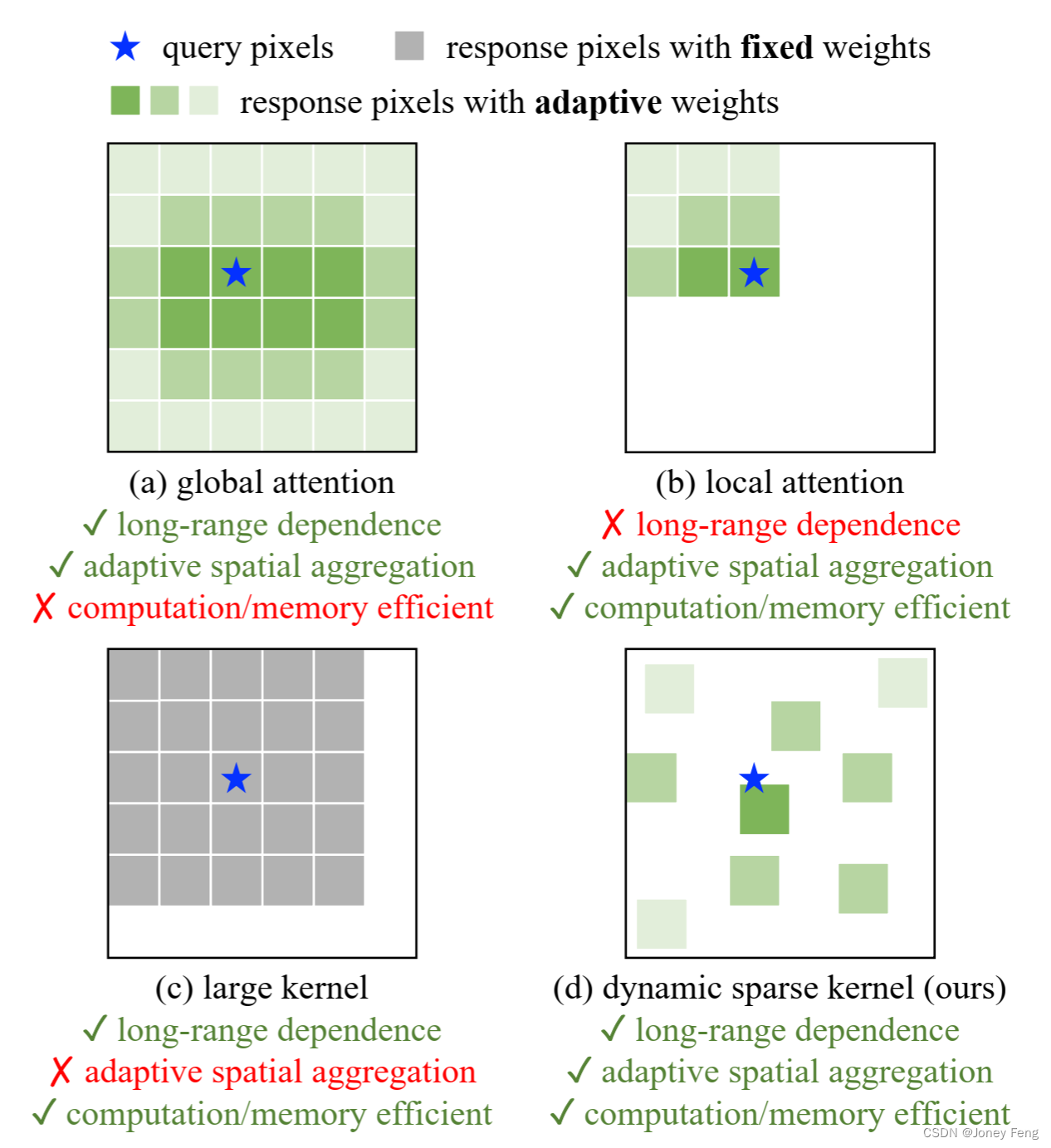 图1.不同核操作符的比较。
图1.不同核操作符的比较。
(a)显示了多头自注意力(MHSA)的全局聚合,在需要高分辨率输入的下游任务中,其计算和内存成本昂贵。
(b)将MHSA的范围限制在一个局部窗口内,以降低成本。
(c)是一个具有非常大核的深度卷积,用于建模长程依赖关系。
(d)是一种可变形卷积,与MHSA具有类似的有利特性,并且对于大规模模型而言效率高。我们从可变形卷积开始构建大规模CNN。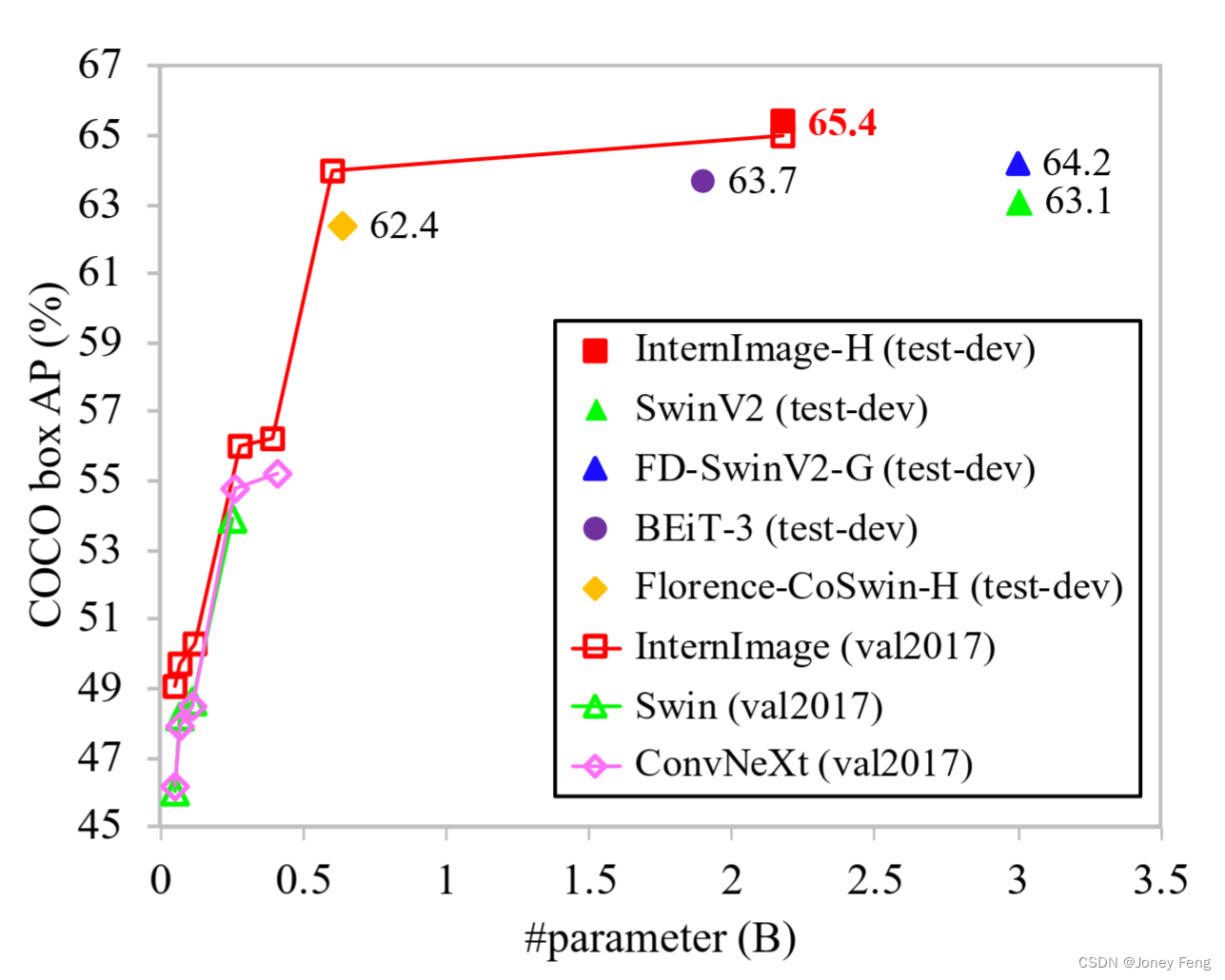 图2.不同骨干网络在COCO上的性能比较。所提出的InternImage-H在COCO test-dev上实现了新的记录,达到了65.4的box AP,明显优于最先进的CNN和大规模ViTs。
图2.不同骨干网络在COCO上的性能比较。所提出的InternImage-H在COCO test-dev上实现了新的记录,达到了65.4的box AP,明显优于最先进的CNN和大规模ViTs。
2.相关工作
视觉基础模型。在大规模数据集和计算资源可用之后,卷积神经网络(CNNs)成为视觉识别的主流。从AlexNet [33]开始,提出了许多更深层、更有效的神经网络架构,如VGG [34]、GoogleNet [35]、ResNet [36]、ResNeXt [37]、EfficientNet [38,39]等。除了架构设计外,还提出了更复杂的卷积操作,如深度卷积[40]和可变形卷积[27,28]。在考虑到Transformer的先进设计的基础上,现代CNN通过在宏观/微观设计中发现更好的组件,引入具有长程依赖性[21,41-43]或动态权重[44]的改进卷积,在视觉任务上展现了有望的性能。近年来,一种基于Transformer架构的新型视觉基础模型受到关注。ViT [9]是最具代表性的模型,通过全局感受野和动态空间聚合,在视觉任务中取得了巨大成功。然而,ViT中的全局注意力在大特征图上面临着昂贵的计算/内存复杂度问题,这限制了它在下游任务中的应用。为了解决这个问题,PVT [10,11]和Linformer [45]在下采样的关键点和值图上进行全局注意力,DAT [46]使用可变形注意力从值图中稀疏采样信息,而HaloNet [47]和Swin Transformer [2]开发了局部注意机制,并使用光晕和平移操作在相邻局部区域之间传递信息。
大规模模型。扩展模型是提高特征表示质量的重要策略,在自然语言处理(NLP)领域已经得到了广泛研究的。受到NLP领域的成功启发,Zhai等人[19]首次将ViT扩展到了20亿个参数。Liu等人[16]将分层结构的Swin Transformer扩展为更深更宽的模型,使用了30亿个参数。一些研究人员通过结合ViTs和CNNs在不同层级上的优势,开发了大规模混合ViTs [20,49]。最近,BEiT-3 [17]在基于ViT的大规模参数上进一步探索了更强的表示,并使用多模态预训练。这些方法显著提高了基本视觉任务的上限。然而,以卷积为基础的大规模模型在总参数数量和性能方面仍然落后于基于Transformer的架构。尽管新提出的CNNs [21,41-43]通过使用具有非常大核或递归门控核的卷积引入了长程依赖性,但与最先进的ViTs仍存在相当大的差距。在这项工作中,我们的目标是开发一种基于CNN的基础模型,能够高效地扩展到与ViT相当的大规模。
3.先前的方法
为了设计一个基于CNN的大规模基础模型,我们首先从一个灵活的卷积变体开始,即可变形卷积v2(DCNv2)[28],并在此基础上进行一些调整,以更好地适应大规模基础模型的要求。然后,我们将经过调整的卷积算子与现代主干网络[16,19]中使用的先进块设计相结合,构建基本块。最后,我们探索基于DCN的块的堆叠和缩放原则,构建一个可以从海量数据中学习强大表示的大规模卷积模型。
3.1.可变性卷积V3
卷积与多头自注意力(MHSA)的区别。之前的研究[21,22,50]已经广泛讨论了CNN和ViT之间的区别。在决定InternImage的核心算子之前,我们先总结一下正常卷积和MHSA之间的主要区别。
(1)长程依赖性。尽管人们早就认识到具有大有效感受野(长程依赖性)的模型通常在下游视觉任务[51–53]上表现更好,但由3×3正常卷积堆叠的CNN的实际有效感受野相对较小。即使是非常深的模型,基于CNN的模型仍然无法像ViT那样获取长程依赖性,这限制了它的性能。
(2)自适应空间聚合。相比于MHSA,其权重是根据输入动态调整的,常规卷积[54]是一种具有静态权重和强烈归纳偏差(如2D局部性、邻域结构、平移等价性等)的算子。
由于具有很强的归纳特性,由常规卷积组成的模型可能比ViT更快地收敛,并且需要更少的训练数据,但它也限制了CNN从海量数据中学习更一般和更健壮的模式。重新审视DCNv2。将卷积和MHSA之间的差距缩小的一种直接方法是将长程依赖性和自适应空间聚合引入到常规卷积中。让我们从DCNv2 [28]开始,它是常规卷积的一种通用变体。给定输入x 2 RC×H×W和当前像素p0,DCNv2可以表示为:

其中,K表示采样点的总数,k枚举采样点。wk表示第k个采样点的投影权重,mk表示第k个采样点的调制标量,通过sigmoid函数进行归一化。pk表示预定义网格采样f(-1,-1);(-1,0);:::;(0,+1);:::;(+1,+1)中的第k个位置,∆pk表示与第k个网格采样位置对应的偏移量。从方程中可以看出:
(1)对于长程依赖性,采样偏移量∆pk是灵活的,并且能够与短程或长程特征进行交互;
(2)对于自适应空间聚合,采样偏移量∆pk和调制标量mk都是可学习的,并且受到输入x的影响。因此,可以发现DCNv2与MHSA具有类似的优良特性,这激发了我们基于这个算子开发大规模基于CNN的基础模型的动机, 扩展DCNv2用于视觉基础模型。
通常情况下,DCNv2通常被用作常规卷积的扩展,加载常规卷积的预训练权重,并进行微调以获得更好的性能,但这并不完全适用于需要从头开始训练的大规模视觉基础模型。为了解决这个问题,在本文中,我们从以下几个方面扩展了DCNv2:
(1)在卷积神经元之间共享权重。与常规卷积类似,原始的DCNv2中不同的卷积神经元1具有独立的线性投影权重,因此其参数和内存复杂性与采样点的总数呈线性关系,这在模型中限制了效率,尤其是在大规模模型中。为了解决这个问题,我们借鉴了可分离卷积[55]的思想,将原始的卷积权重wk分解为深度部分和点部分,其中深度部分由原始的位置感知调制标量mk负责,点部分是在采样点之间共享的投影权重w。
(2)引入多组机制。多组(头部)设计最早出现在组卷积[33]中,并在Transformer的MHSA[1]中广泛应用,与自适应空间聚合一起,可以在不同位置的不同表示子空间中有效地学习更丰富的信息。受此启发,我们将空间聚合过程分为G组,每组具有独立的采样偏移量∆pgk和调制标量mgk,因此单个卷积层上的不同组可以具有不同的空间聚合模式,从而为下游任务提供更强的特征。
(3)对采样点上的调制标量进行归一化。原始的DCNv2中的调制标量通过sigmoid函数进行逐元素归一化。因此,每个调制标量都在范围[0,1]内,并且所有采样点的调制标量之和不稳定,从0到K都有可能变化。这导致在使用大规模参数和数据进行训练时,DCNv2层的梯度不稳定。为了缓解不稳定性问题,我们将逐元素的sigmoid归一化改为沿采样点的softmax归一化。这样,调制标量之和被限制为1,使得不同尺度的模型训练过程更加稳定。 综合以上修改,扩展后的DCNv2,标记为DCNv3,可以表示为公式(2)。
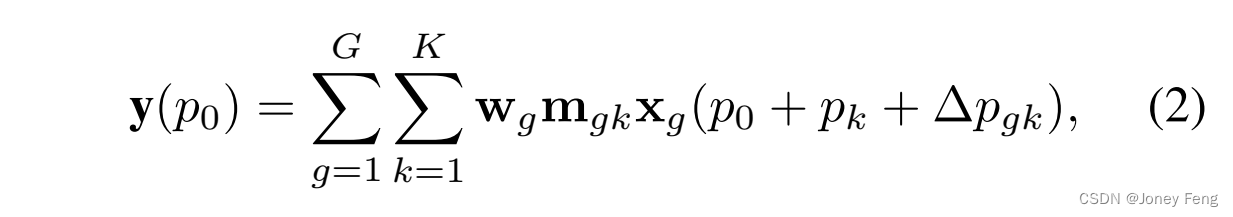
其中,G表示聚合组的总数。对于第g组,wg是表示该组的与位置无关的投影权重,其中C0=C=G表示组的维度。mgk是第g组中第k个采样点的调制标量,通过沿维度K进行softmax函数归一化。xg表示切片的输入特征图,维度为RC0×H×W。∆pgk是与网格采样位置pk对应的偏移量。总体上,DCNv3作为DCN系列的扩展具有以下三个优点:
(1)该算子弥补了常规卷积在长距离依赖和自适应空间聚合方面的不足;
(2)与基于注意力的算子(如常见的MHSA和密切相关的可变形注意力[46, 56])相比,该算子继承了卷积的归纳偏置,使得我们的模型在更少的训练数据和更短的训练时间内更加高效;
(3)该算子基于稀疏采样,比之前的方法(如MHSA [1]和重新参数化的大卷积核[22])具有更高的计算和内存效率。此外,由于稀疏采样,DCNv3只需要一个3×3的卷积核来学习长距离依赖关系,这更容易优化,并避免了大卷积核中使用的重新参数化[22]等额外辅助技术。
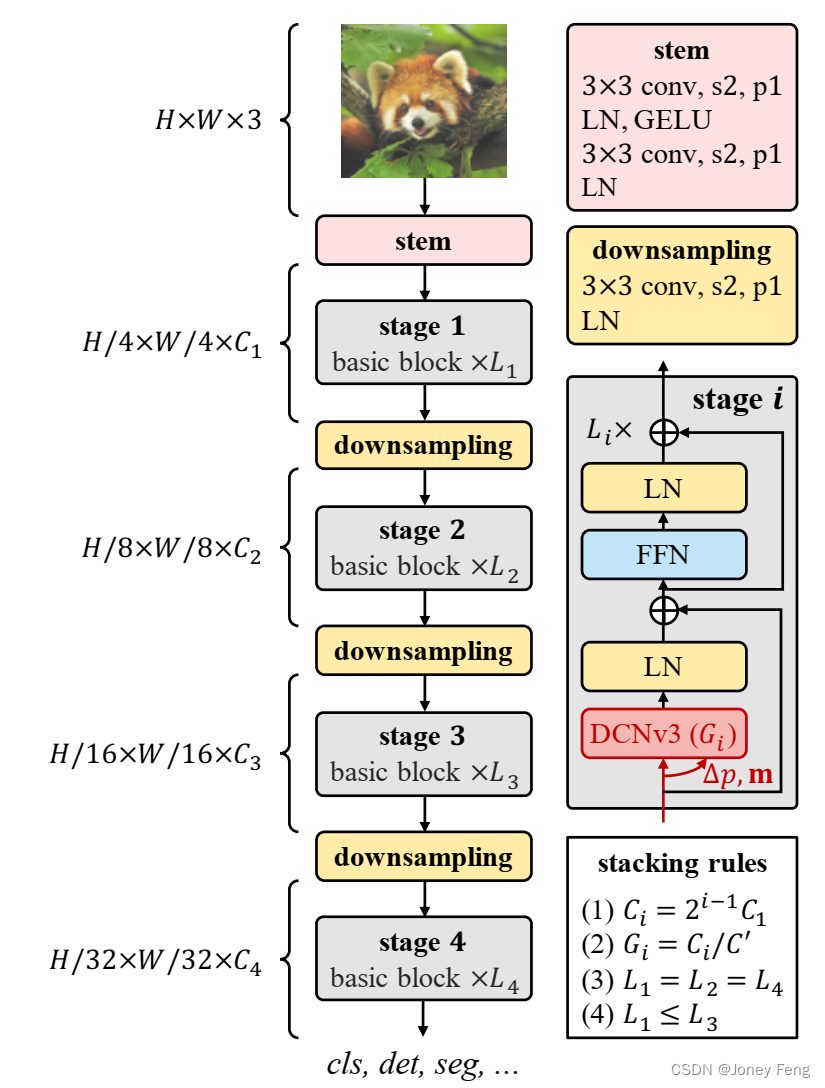 图3. InternImage的整体架构,其中核心算子是DCNv3,基本块由层归一化(LN)[24]和前馈网络(FFN)[1]组成,作为变换器,干线和下采样层遵循传统CNN的设计,其中"s2"和"p1"表示步幅为2和填充为1。根据堆叠规则的限制,只有4个超参数(C1;C0;L1;L3)可以决定一个模型的变体。
图3. InternImage的整体架构,其中核心算子是DCNv3,基本块由层归一化(LN)[24]和前馈网络(FFN)[1]组成,作为变换器,干线和下采样层遵循传统CNN的设计,其中"s2"和"p1"表示步幅为2和填充为1。根据堆叠规则的限制,只有4个超参数(C1;C0;L1;L3)可以决定一个模型的变体。
3.2.InternImage模型
使用DCNv3作为核心算子的InternImage模型带来了一个新问题:如何构建一个能够有效利用核心算子的模型?在本节中,我们首先介绍我们模型的基本块和其他组成层的详细信息,然后通过探索针对这些基本块的定制堆叠策略,构建一个新的基于CNN的基础模型,称为InternImage。最后,我们研究了提出的模型的扩展规则,以获得增加参数所带来的收益。
基本块:与传统CNN中广泛使用的瓶颈结构[36]不同,我们的基本块设计更接近于ViTs,它配备了更先进的组件,包括LN [24]、前馈网络(FFN)[1]和GELU [25]。这种设计在各种视觉任务中已被证明是有效的[2,10,11,21,22]。我们基本块的详细信息如图3所示,其中核心算子是DCNv3,通过将输入特征x通过可分离卷积(一个3×3的深度卷积后跟一个线性投影)来预测采样偏移和调制尺度。对于其他组件,我们默认使用后归一化设置[57],并遵循与普通transformer [1,9]相同的设计。
干线和下采样层:为了得到分层的特征图,我们使用卷积干线和下采样层将特征图调整为不同的尺度。如图3所示,干线层位于第一个阶段之前,将输入分辨率降低4倍。它由两个卷积层、两个LN层和一个GELU层组成,其中两个卷积层的卷积核尺寸为3,步幅为2,填充为1,第一个卷积层的输出通道数是第二个卷积层的一半。类似地,下采样层由一个步幅为2、填充为1的3×3卷积层和一个LN层组成。它位于两个阶段之间,用于将输入特征图下采样2倍。
堆叠规则。为了明确块堆叠过程,我们首先列出InternImage的几个关键超参数如下:
Ci:第i阶段的通道数;
Gi:第i阶段中DCNv3的组数;
Li:第i阶段的基本块数。
由于我们的模型有4个阶段,一个变体由12个超参数决定,超参数的搜索空间太大,无法穷举所有可能并找到最佳的变体。为了减小搜索空间,我们总结了之前研究的设计经验[2,21,36],将其归纳为图3中的4条规则。
第一条规则使得后三个阶段的通道数由第一个阶段的通道数C1决定,
第二条规则使得组数与各阶段的通道数对应。对于不同阶段的堆叠块数,我们简化堆叠模式为“AABA”,即第1、2和4阶段的块数相同,并且不大于第3阶段的块数,如最后两条规则所示。
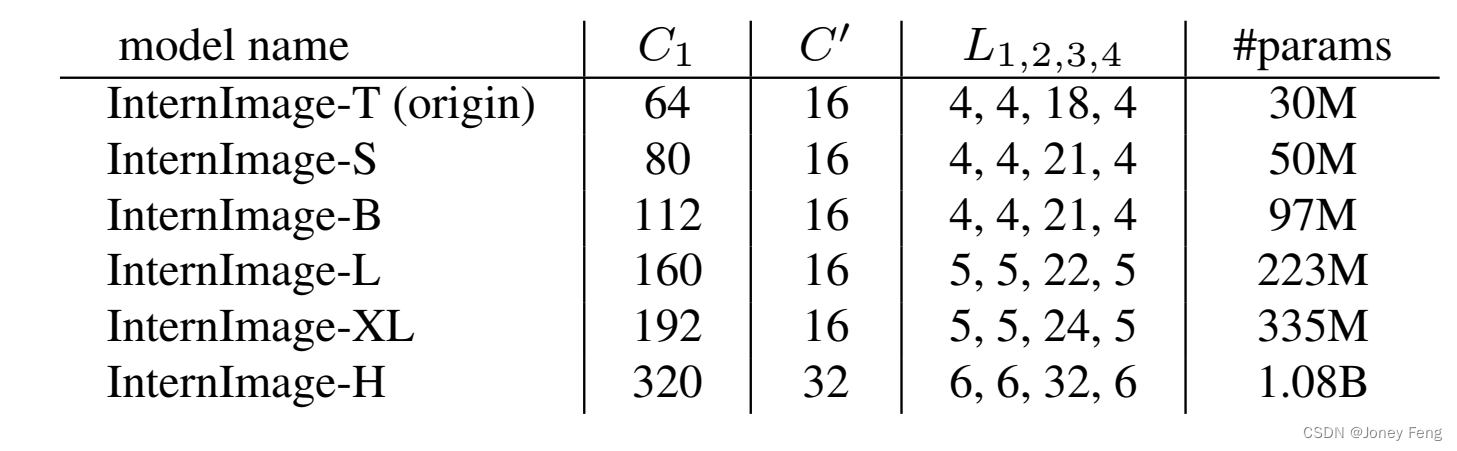
根据这些规则,InternImage的变体只需使用4个超参数(C1;C0;L1;L3)来定义。我们选择一个参数量为3000万的模型作为起点,将C1离散化为f48、64、80g,L1离散化为f1、2、3、4、5g,将C0离散化为f16、32g。通过这种方式,原始的庞大搜索空间被减小为30种,我们可以通过在ImageNet [31]上训练和评估这30种变体来找到最佳模型。在实践中,我们使用最佳的超参数设置(64;16;4;18)来定义起始模型,并将其按比例缩放到不同的尺度。
缩放规则。基于上述约束条件下的最优起点模型,我们进一步探索由[38]启发的参数缩放规则。具体来说,我们考虑两个缩放维度:深度D(即3L1 + L3)和宽度C1,并使用α,β和一个复合因子φ来缩放这两个维度。缩放规则可以写为:D0 = αφD和C10 = βφC1,其中α≥1,β≥1,并且αβ1:99≈2。这里,1.99是特定于InternImage的,并通过将模型宽度翻倍并保持深度不变来计算得到。我们实验性地发现,最佳的缩放设置是α=1:09和β=1:36,然后我们基于这个设置构建了具有不同参数规模的InternImage变体,即InternImage-T/S/B/L/XL,其复杂度与ConvNeXt [21]的相似。为了进一步测试能力,我们构建了一个更大的InternImage-H,其参数量为10亿,并且为了适应非常大的模型宽度,我们还将组维度C0更改为32。配置总结如表1所示。
表1.不同尺度模型的超参数。InternImage-T是原始模型,-S/B/L/XL/H是从-T缩放而来的。“#params”表示参数数量
4.实验
我们对InternImage与领先的CNN和ViTs在代表性视觉任务(包括图像分类、目标检测、实例和语义分割)上进行了分析和比较。除了主要论文中的实验外,由于篇幅限制,更多的实验设置和消融研究结果在补充材料中呈现。
4.1.图像分类
实验设置。我们在ImageNet [31]上评估InternImage的分类性能。为了公平比较,按照常见的做法[2,10,21,58],InternImage-T/S/B在ImageNet-1K(约130万张图像)上进行300个epoch的训练,而InternImage-L/XL则首先在ImageNet-22K(约1420万张图像)上进行90个epoch的训练,然后在ImageNet-1K上进行20个epoch的微调。为了进一步探索我们模型的能力,并与先前方法[16,20,59]中使用的大规模私有数据相匹配,我们采用M3I预训练[60],这是一种对无标签和弱标签数据都适用的统一预训练方法,将InternImage-H在公共数据集Laion-400M [61]、YFCC-15M [62]和CC12M [63]的427亿张图像上进行30个epoch的预训练,然后在ImageNet-1K上进行20个epoch的微调。
结果。表2显示了不同尺度模型的分类结果。在类似的参数和计算成本下,我们的模型与基于变换器和CNN的最先进模型相媲美甚至更优。例如,InternImage-T的top-1准确率达到83.5%,比ConvNext-T [21]高出1.4个百分点。InternImage-S/B保持领先地位,而InternImage-B超过了混合ViT CoAtNet-2 [20]0.8个百分点。当在ImageNet-22K和大规模联合数据集上进行预训练后,InternImage-XL和-H的top-1准确率分别提高到88.0%和89.6%,优于先前使用大规模数据训练的CNN [22,67],并且与最先进的大规模ViT相差约1个百分点。这个差距可能是由于大规模难以获取的私有数据与前述联合公共数据之间的差异所导致的。这些结果表明,我们的InternImage不仅在常规参数规模和公共训练数据上表现出色,而且在大规模参数和数据上也能有效推广。
4.2.物体检测
实验设置。我们在COCO基准测试[32]上验证了InternImage在两种代表性的目标检测框架Mask R CNN [70]和Cascade Mask R-CNN [71]上的检测性能。我们按照常见的做法[2,11],使用预训练的分类权重初始化骨干网络,并使用1×(12个epoch)或3×(36个epoch)的训练计划进行模型训练。
结果。如表3所示,在使用Mask R CNN进行目标检测时,我们发现在相同数量的参数下,我们的模型显著超过了其他模型。例如,使用1×训练计划,InternImage-T的框AP(APb)比Swin-T [2]高出4.5个百分点(47.2 vs. 42.7),比ConvNeXt-T [21]高出3.0个百分点(47.2 vs. 44.2)。在使用3×多尺度训练计划、更多参数和更先进的Cascade Mask R-CNN [71]时,InternImage-XL实现了56.2的APb,超过ConvNeXt-XL 1.0个百分点(56.2 vs. 55.2)。在实例分割实验中也得到了类似的结果。使用1×训练计划,InternImage-T的掩码AP(即APm)达到42.5,比Swin T和ConvNeXt-T分别高出3.2个百分点(42.5 vs. 39.3)和2.4个百分点(42.5 vs. 40.1)。InternImage-XL与Cascade Mask R-CNN一起获得了最佳的48.8的APm,比其他模型至少高出1.1个百分点。为了进一步推动目标检测的性能界限,我们按照领先方法[16,17,26,74,78]中使用的高级设置,使用在ImageNet-22K或大规模联合数据集上预训练的权重初始化骨干网络,并通过复合技术[78]将其参数加倍(参见图2中20亿参数的模型)。然后,我们与DINO [74]检测器一起在Objects365 [79]和COCO数据集上分别进行26个epoch和12个epoch的微调。如表4所示,我们的方法在COCO val2017和test-dev上取得了最好的结果,分别为65.0的APb和65.4的APb。与先前的最先进模型相比,我们的模型参数减少了27%,没有复杂的蒸馏过程,但超过了FD-SwinV2-G [26]1.2个百分点(65.4 vs. 64.2),这表明了我们的模型在目标检测任务上的有效性。表2.在ImageNet验证集上的图像分类性能。“type”表示模型类型,“T”和“C”分别表示Transformer和CNN。“scale”是输入的尺度。“acc”表示Top-1准确率。“z”表示模型在ImageNet-22K [31]上进行了预训练。“#”表示在额外的大规模私有数据集(如JFT-300M [68]、FLD-900M [59])或本工作中的联合公共数据集上进行了预训练。
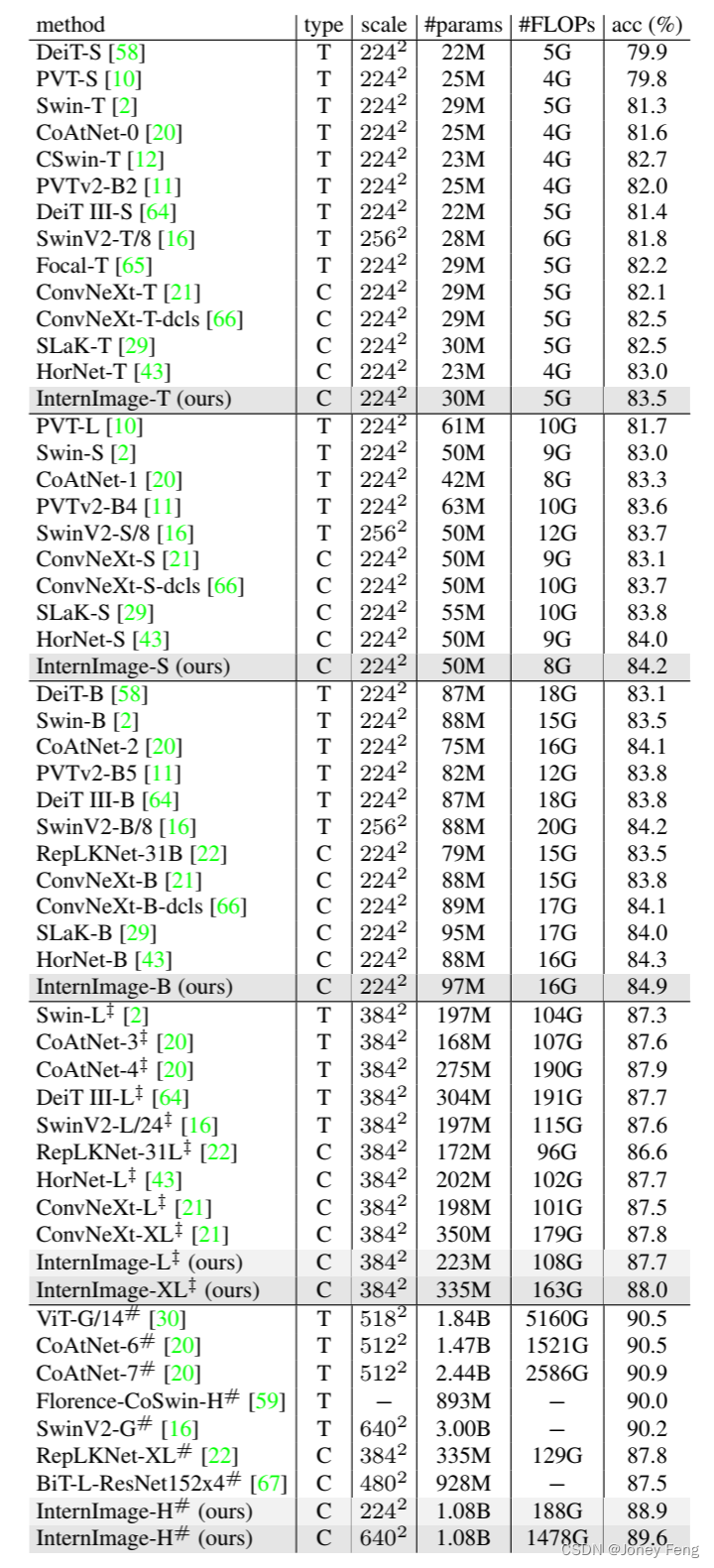 表3.在COCO val2017上的目标检测和实例分割性能。FLOPs是以1280×800的输入为基准测量的。APb和APm分别表示框AP和掩码AP。“MS”表示多尺度训练。
表3.在COCO val2017上的目标检测和实例分割性能。FLOPs是以1280×800的输入为基准测量的。APb和APm分别表示框AP和掩码AP。“MS”表示多尺度训练。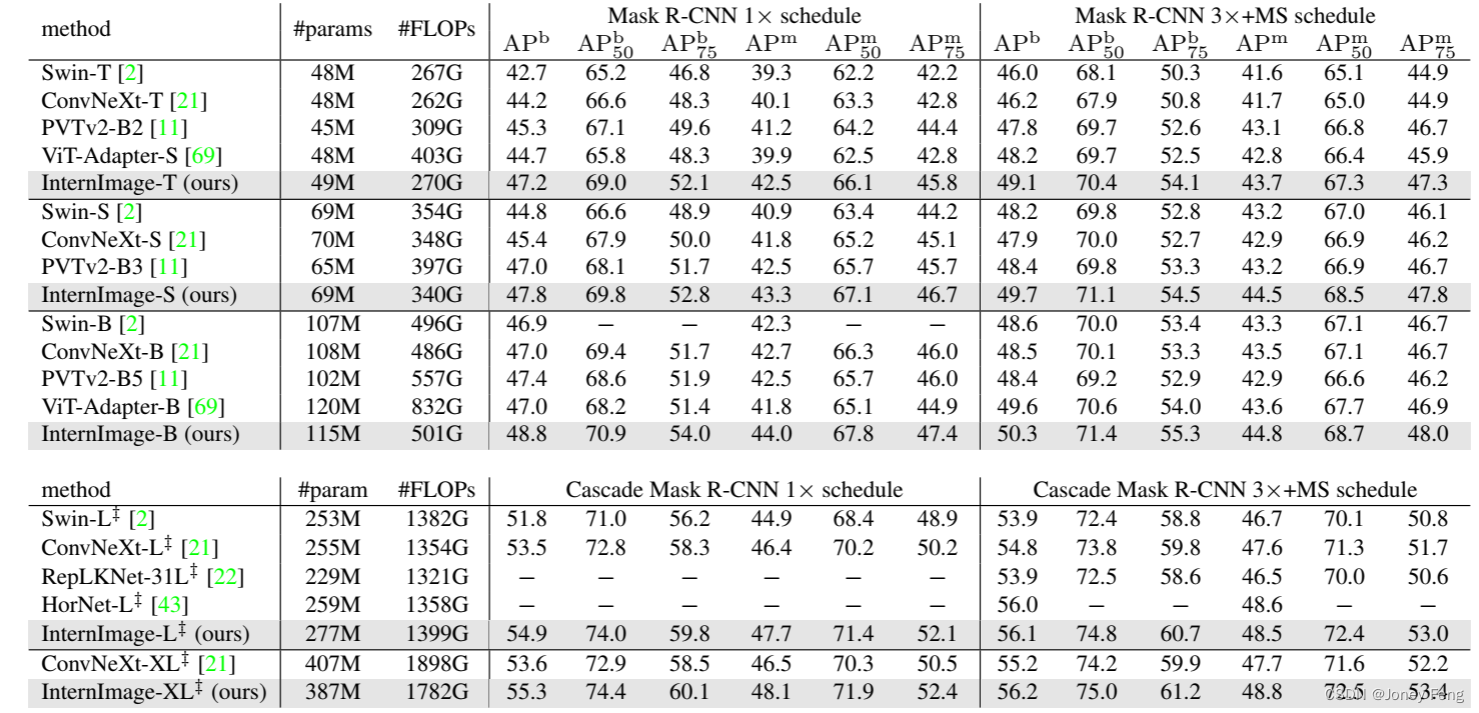
表4.在COCO val2017和test-dev上最先进检测器的比较。

4.3.语义分割
实验设置。为了评估InternImage的语义分割性能,我们使用预训练的分类权重初始化骨干网络,并使用UperNet [81]在ADE20K [82]上进行了160k次迭代的训练,并与之前基于CNN和Transformer的骨干网络进行了公平比较。为了进一步取得最佳性能,我们使用更先进的Mask2Former [80]来增强InternImage-H,并采用了[17,69]中的相同训练设置。
结果。如表5所示,在使用UperNet [81]进行语义分割时,我们的InternImage始终优于之前的方法[2,21,22,29]。例如,使用几乎相同的参数数量和FLOPs,我们的InternImage-B在ADE20K验证集上的mIoU达到了50.8,相比于ConvNeXt-B(50.8 vs. 49.1)和RepLKNet-31B(50.8 vs. 49.9)等强力对手表现出色。此外,我们的InternImage-H在MS mIoU上达到了60.3,比SwinV2-G [16]更好,而参数数量要小得多(1.12B vs. 3.00B)。值得注意的是,当使用Mask2Former [80]和多尺度测试时,我们的InternImage-H在ADE20K基准测试上取得了最佳的62.9的mIoU,超过了当前最好的BEiT-3 [17]。这些结果表明,基于CNN的基础模型也可以享受到大规模数据的好处,并挑战基于Transformer的模型的领先地位。
表5.在ADE20K验证集上的语义分割性能。FLOPs是根据裁剪尺寸使用512×2048、640×2560或896×896的输入进行测量的。“SS”和“MS”分别表示单尺度和多尺度测试。
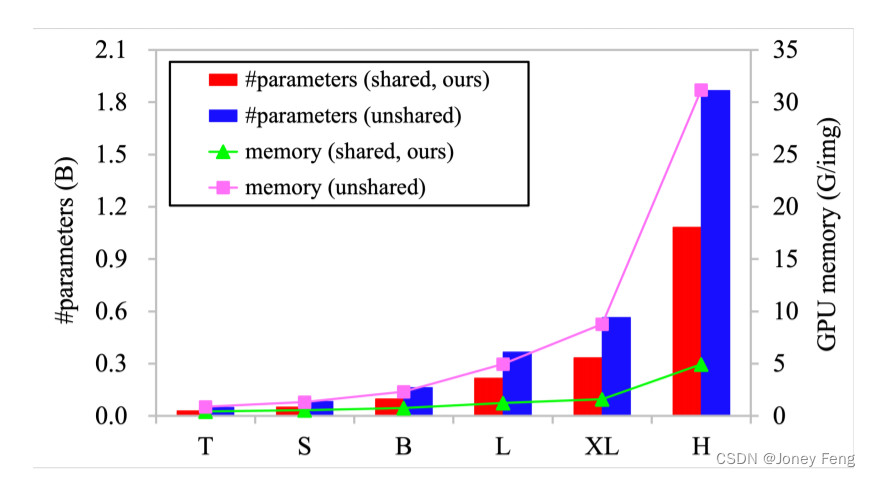
图4.共享权重与非共享权重卷积神经元的模型参数和GPU内存使用情况。左侧的垂直轴表示模型参数,右侧的垂直轴表示批量大小为32,输入图像分辨率为224×224时每个图像的GPU内存使用情况。
图5.不同阶段不同组别的采样位置可视化。蓝色星星表示查询点(位于左侧的羊身上),不同颜色的点表示不同组别的采样位置。
4.4.消融实验
共享卷积神经元之间的权重很重要。由于硬件限制,大规模模型对核心运算符的参数和内存消耗非常敏感。为了解决这个问题,我们在DCNv3的卷积神经元之间共享权重。如图4所示,我们比较了基于共享或非共享权重的DCNv3模型的参数和内存消耗。我们可以看到,非共享权重模型的参数和内存消耗要远高于共享权重模型,尤其是在-H规模上,保存的参数和GPU内存的比例分别为42.0%和84.2%。如表6所示,我们还对比了两个-T规模的模型在ImageNet(83.5 vs. 83.6)和COCO(47.2 vs. 47.4)上的top-1准确率,即使是没有共享权重的模型也比共享权重的模型多了66.1%的参数。多组空间聚合带来更强的特征。我们引入聚合组,使我们的模型能够从不同的表示子空间中学习信息,就像transformers [9]一样。如图5所示,对于相同的查询像素,来自不同组的偏移集中在不同的区域,从而产生分层的语义特征。我们还比较了具有多个组和没有多个组的模型的性能。如表6所示,模型在ImageNet上的准确率下降了1.2个点,在COCO val2017上下降了3.4个点。此外,我们还可以看到,在前两个阶段中,学习到的有效感受野(ERF)相对较小,随着模型的深入(即第3和第4阶段),ERF增加到全局。这种现象与ViTs [9,10,83]不同,ViTs的ERF通常是全局的。
表6.对DCNv3中三个修改的消融比较。这些实验是基于InternImage-T进行分类和Mask R-CNN 1×schedule进行检测。

5.总结和局限性
我们引入了InternImage,这是一个新的基于CNN的大规模基础模型,可以为各种视觉任务(如图像分类、目标检测和语义分割)提供强大的表示能力。我们调整了灵活的DCNv2运算符以满足基础模型的要求,并开发了一系列以核心运算符为中心的块、堆叠和缩放规则。对目标检测和语义分割基准的广泛实验验证了我们的InternImage可以获得与使用大量数据训练的设计良好的大规模视觉Transformer相当或更好的性能,表明CNN也是大规模视觉基础模型研究的一个可考虑的选择。然而,延迟仍然是适应具有高速要求的下游任务的基于DCN的运算符所面临的问题。此外,大规模CNN仍处于早期发展阶段,我们希望InternImage可以成为一个良好的起点。
附录
A.详细实验设置
在本节中,我们提供了图像分类、目标检测和语义分割的详细训练方法。
A1.骨干网络层级比较的设置
ImageNet图像分类。图像分类在ImageNet [31]上的训练细节如表7所示,这与常见的做法[2,21,58,64]相似,但也有一些调整。为了进一步探索我们模型的能力,并与之前方法[16,20,59]中使用的大规模私有数据相匹配,我们采用M3I预训练[60],这是一种适用于无标签和弱标签数据的统一预训练方法,用于在公共Laion-400M [61],YFCC-15M [62]和CC12M [63]的42.7亿联合数据集上对InternImage-H进行30个epoch的预训练,然后在ImageNet-1K上对模型进行20个epoch的微调。有关InternImage-H的更详细的预训练设置,请参考M3I预训练[60]。COCO目标检测。我们在COCO基准[32]上验证了InternImage在Mask R-CNN [70]和级联Mask R-CNN [71]之上的检测性能。为了公平比较,我们遵循常见的做法[2,11],使用预训练的分类权重初始化骨干网络,并使用1×(12个epoch)或3×(36个epoch)的训练计划进行训练。对于1×计划,图像被调整大小,使得较短的一边为800像素,而较长的一边不超过1333像素。在测试时,输入图像的较短一边固定为800像素。对于3×计划,较短的一边被调整为480-800像素,而较长的一边不超过1333像素。所有这些检测模型都使用批大小为16进行训练,并使用AdamW [84]进行优化,初始学习率为1×10^(-4)。ADE20K语义分割。我们在ADE20K数据集[82]上评估了InternImage模型,并使用预训练的分类权重进行初始化。对于InternImage-T/S/B模型,我们使用AdamW [84]进行优化,初始学习率为6×10^(-5),InternImage-X/XL的初始学习率为2×10^(-5)。学习率按照幂为1.0的多项式衰减计划进行衰减。与之前的方法[2,11,21]一样,InternImage-T/S/B的裁剪尺寸设置为512,InternImage-L/XL的裁剪尺寸设置为640。所有分割模型都使用UperNet [81]进行训练,批大小为16,迭代160k次,并与以前的基于CNN和Transformer的骨干模型进行公平比较。
A.2.系统层级比较的设置
COCO目标检测。为了与最先进的大规模检测模型[16,17,26,74,78]进行系统级比较,我们首先使用在ImageNet-22K或427M大规模联合数据集上预训练的InternImage-XL/H骨干网络权重进行初始化,并使用组合技术[78]将其参数扩大一倍。然后,我们将模型与DINO [74]检测器一起在Objects365 [79]上进行26个epoch的预训练,初始学习率为2×10^(-4),批大小为256。在预训练期间,输入图像的较短边被调整为600-1200像素,学习率在第22个epoch时降低10倍。最后,我们在COCO数据集上对这些检测器进行12个epoch的微调,批大小为64,初始学习率为5×10^(-5),在最后一个epoch时降低10倍。 ADE20K语义分割。为了进一步达到领先的分割性能,我们首先使用在427M大规模联合数据集上预训练的InternImage-H骨干网络权重进行初始化,并结合最先进的分割方法Mask2Former [80]进行训练。我们遵循[17,69]中相同的训练设置,即在COCO-Stuff [85]和ADE20K [82]数据集上分别进行80k次迭代的预训练和微调,裁剪尺寸为896,初始学习率为1×10^(-5)。
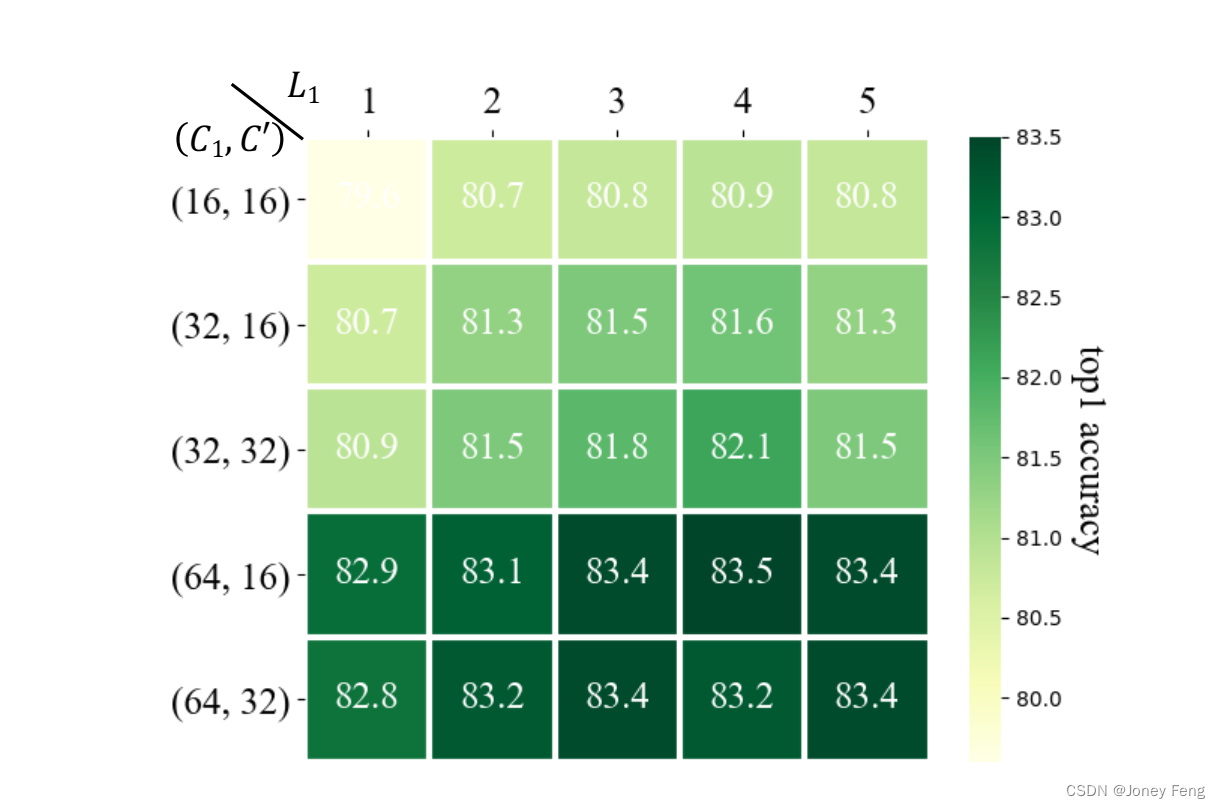 图6.不同堆叠超参数的比较。每个方块表示由超参数确定的模型的准确性,颜色越深,准确性越高。
图6.不同堆叠超参数的比较。每个方块表示由超参数确定的模型的准确性,颜色越深,准确性越高。
B.超参数的探究
B.1.模型堆叠
正如第3.2节所讨论的,我们的模型由四个堆叠规则构建,并且我们进一步将模型参数限制为30M。我们将堆叠超参数C1离散化为16、32、64;L1离散化为1、2、3、4、5;C0离散化为16、32。而L2是通过选择模型大小使其接近30M来确定的。通过组合这三个超参数,我们得到了30个模型。除非另有说明,我们采用表7中列出的训练方法来训练我们的-T模型。图6显示了这些模型在相同的训练设置下的ImageNet-1K top-1准确率,较深的绿色表示更高的准确率,即具有更强的表示能力的模型。当C0等于16时,模型一般比C0为32的模型更好,而L1在4时效果最佳,这要归功于合理的堆叠比例。更多的通道数可以获得更大的增益。最后,通过以上探索实验,我们确定了我们的基本堆叠超参数为(C1;C0;L1;L3)为(64;16;4;18)。
表7.不同参数规模的InternImage在ImageNet [31]上的详细训练设置。"CE"表示交叉熵损失,"LR"表示学习率。训练设置遵循常见的实践方法[2,21,58,64]并进行了一些调整。"IN-1K pt"、"IN-22K pt"和"IN-1K ft"分别表示ImageNet-1K预训练、ImageNet-22K预训练和ImageNet-1K微调。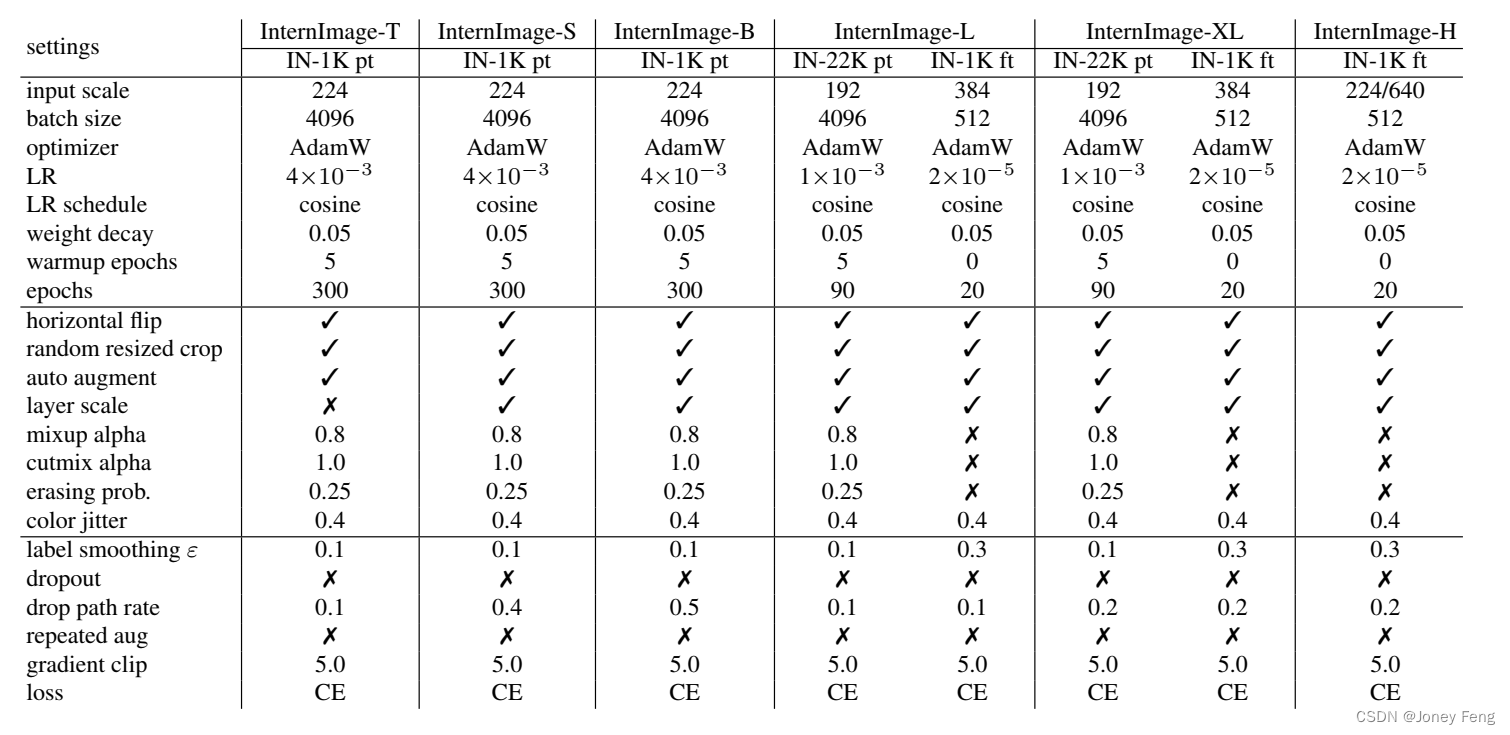
B.2.模型缩放
在第3.2节中,我们已经展示了深度缩放因子α和宽度缩放因子β的约束条件。基于这个条件和-T模型(30M),我们展示了将-T模型扩展为-B模型(100M)的合理缩放可能性。如表8所示,前两列显示了α和β的公式。倒数第二列表示模型参数,最后一列表示这些模型在经过300个训练epoch后的ImageNet-1K top-1准确率。值得注意的是,模型宽度C1需要被C0整除。因此,在确定具体的缩放参数时需要进行一些调整。这导致参数数量有小幅波动,但这是可以接受的。我们的探索性实验证明,当(α;β)设置为(1:09;1:36)时可以获得最佳性能。此外,其他大小的模型-S/L/XL/H也证实了我们的缩放规则的有效性。
表8.不同缩放因子的比较。默认设置用灰色背景标记。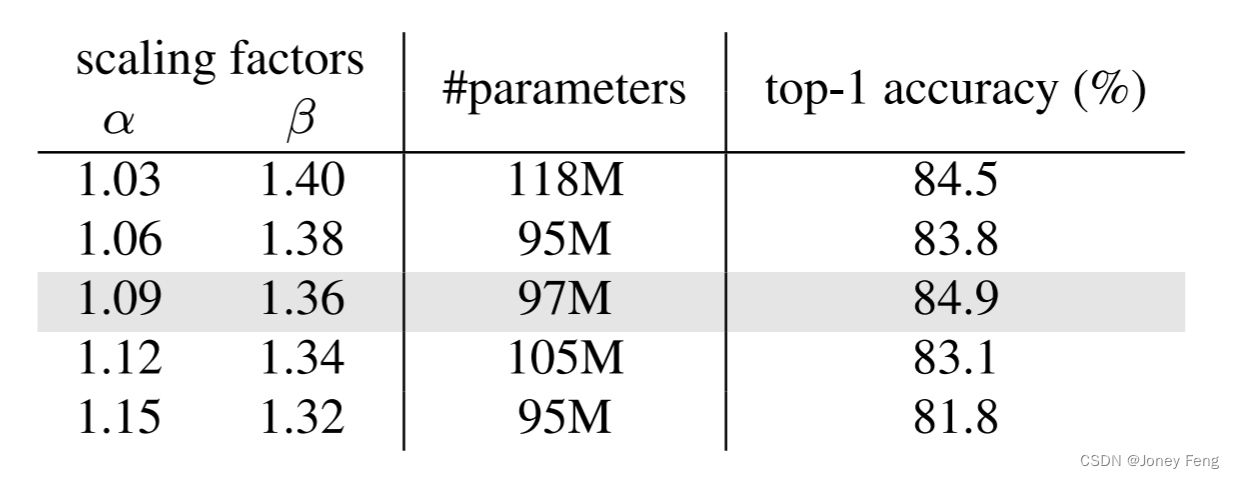
表9.我们算子中不同卷积核尺寸的比较。默认设置用灰色背景标记。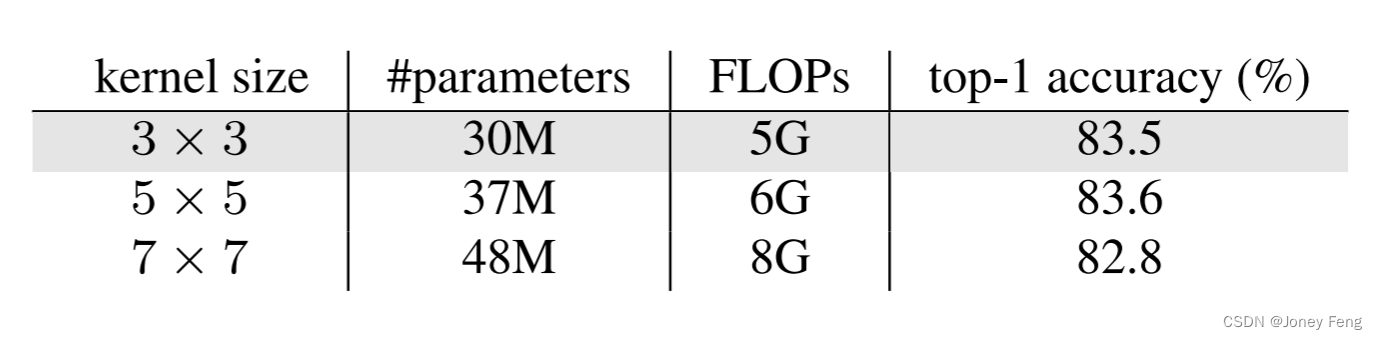
B.3.卷积核大小
正如第3.1节中提到的,我们认为3×3的动态稀疏卷积对于大感受野已经足够了。在这里,我们探索了DCNv3操作符中卷积神经元数量的作用。具体来说,我们将DCNv3操作符中的3×3卷积核替换为5×5或7×7卷积核。它们都是通过-T训练方法(详见表7)进行训练,并在ImageNet-1K验证集上进行验证。结果如表9所示。结果显示,当扩大卷积核时,参数和FLOPs都会大幅增加,而准确率并没有显著提高(83.5对比83.6),甚至下降(83.5对比82.8)。这些结果表明,当单层卷积神经元数量增加时,模型变得更难优化。这一现象也在RepLKNet [22]中得到了证实,并且它通过重新参数化[22]技术来解决这个问题,但这可能会在训练阶段增加额外的时间和内存开销。在这项工作中,我们通过采用简单而有效的3×3 DCNv3作为InternImage的核心操作符来避免这个问题。图7显示了ResNet-101 [36]和InternImage-S的有效感受野(ERF)。亮区域的分布更广泛表示更大的ERF。我们在狗眼睛上均匀激活输入图像,计算每个块的梯度图,按通道聚合,然后映射回输入图像。我们可以看到,未经训练的ResNet-101 [36]的ERF仅限于局部区域,而经过充分训练的ResNet-101仍然具有围绕眼睛的ERF,梯度幅值较低,分布更稀疏。因此,ResNet-101能够有效感知的区域非常有限。对于未经训练的InternImage-S,它的ERF集中在激活点附近。由于偏移量没有被学习,它在最后两个块中的ERF也非常小。但经过充分训练,InternImage-L在第3和第4阶段可以有效感知整个图像的信息。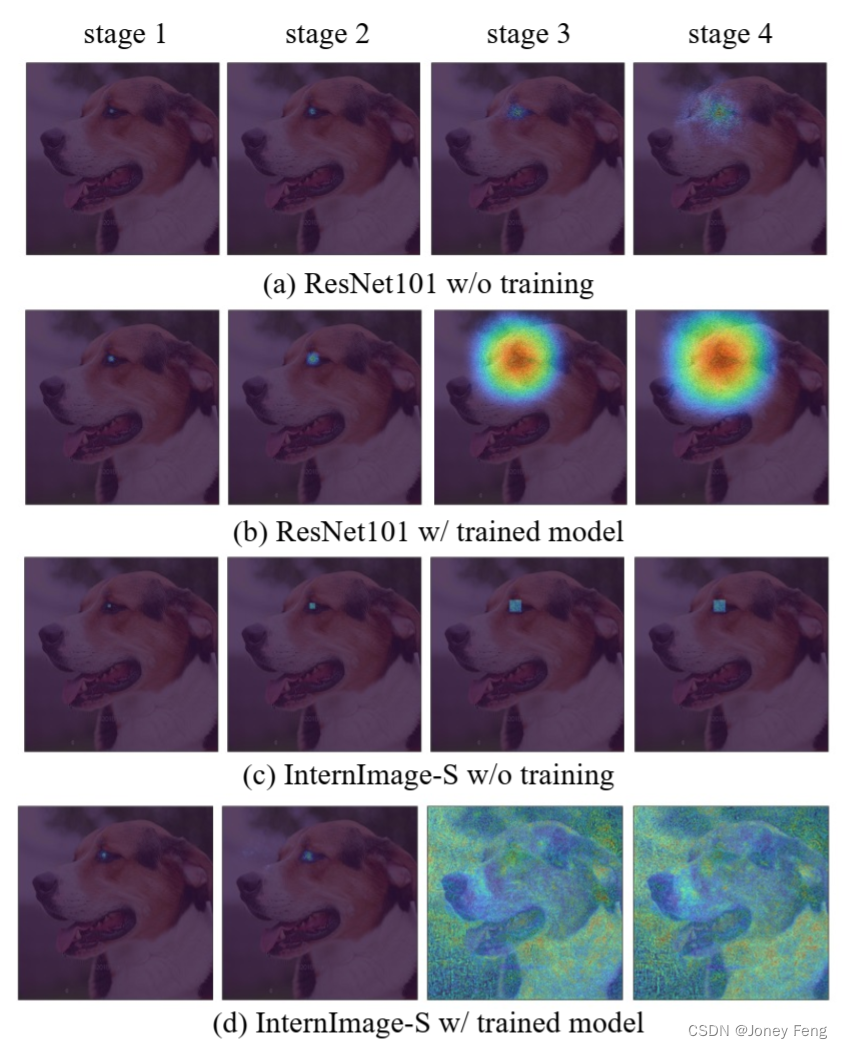
图7.不同骨干网络的有效感受野(ERF)可视化。激活的像素位于狗眼处。(a)和(b)分别显示了在ImageNet-1K上训练和未训练的ResNet-101 [36]的ERF。(c)和(d)是在ImageNet-1K上训练和未训练的InternImage-B的ERF。
C.额外的下游任务
C.1.分类
iNaturalist 2018 [98]是一个包含8142个细粒度物种的长尾数据集。该数据集包含437.5K张训练图像,且不平衡因子为500。在这个实验中,我们使用在427M大规模联合数据集上预训练的InternImage-H模型的权重来初始化,并在iNaturalist 2018的训练集上进行100个epoch的微调。我们按照MetaFormer [86]的做法,采用384×384的分辨率进行微调,并利用元信息。其他训练设置与在ImageNet-1K上微调InternImage-H的方法相同,如表7所述。结果上,我们的方法在iNaturalist 2018的验证集上实现了92.6的最新准确率(见表10),比之前最好的模型MetaFormer [86]提高了3.9个百分点。 Places205 [99]是一个包含205个场景类别的数据集,其中包含250万张图像,专门用于场景识别任务。这个数据集中的图像涵盖了各种室内外场景,例如办公室、厨房、森林和海滩。我们使用在一个包含4.27亿张图像的大规模联合数据集上预训练的权重来初始化我们的模型,并在Places205的训练集上进行微调。其他训练设置与在ImageNet-1K上微调InternImage-H的方法相同,如表7所述。我们的方法在Places205的验证集上实现了71.7的最新准确率(见表10),比之前最好的模型MixMIM-L [87]提高了2.4个百分点。 Places365 [100]是一个包含365个场景类别的数据集,其中包含180万张图像,专门用于场景识别任务。这个数据集中的图像涵盖了各种室内外场景,例如机场、卧室、沙漠和瀑布。具体的预训练和微调策略与Places205相同。我们的方法在Places365的验证集上实现了61.2的最新准确率(见表10),比之前最好的模型SWAG [88]提高了0.5个百分点。与Places205相比,Places365数据集提供了更细粒度的分类任务,使得我们的模型能够学习到更相似场景之间的细微差别。
C.2.目标检测
LVIS v1.0 [101]是一个用于目标检测和实例分割任务的大规模词汇数据集,包含164k张图像中的1203个类别。对于这个数据集,我们使用Objects365 [79]的预训练权重来初始化我们的InternImage-H模型,然后在LVIS v1.0的训练集上进行微调。我们在minival集和val集上使用多尺度测试报告了盒子AP(即APb)。如表10所示,我们的InternImage-H在LVIS minival上实现了65.8的APb,在LVIS val上实现了63.2的APb,明显优于之前最先进的方法。Pascal VOC [102]包含20个物体类别,广泛用作目标检测任务的基准。我们采用这个数据集来进一步评估我们模型的检测性能。具体来说,我们使用Objects365 [79]的预训练权重来初始化我们的InternImage-H,并在Pascal VOC 2007和Pascal VOC 2012的trainval集上进行微调,按照之前的方法 [93]。如表10所示,在Pascal VOC 2007的测试集上,我们的InternImage-H在单尺度测试下获得了94.0的AP50,比之前最好的Cascade Eff-B7 NAS-FPN [93]提高了4.7个百分点。在Pascal VOC 2012的测试集上,我们的方法达到了97.2的mAP,比官方排行榜上的最好记录 [94]高出4.3个百分点。OpenImages v6 [103]是一个包含约900万张图像和1600万个边界框的数据集,用于目标检测任务,涵盖了600个物体类别的1.9万张图像,场景非常多样且常常包含多个对象(平均每张图像有8.3个对象)。对于这个数据集,我们使用与前两个数据集相同的设置。此外,我们根据[95]的方法在微调过程中使用类别感知的采样。如表10所示,我们的InternImage-H在OpenImages v6上达到了74.1的mAP,在之前最好的结果 [95]基础上提高了1.9个mAP。
CrownHuman [104]是一个用于在拥挤场景下更好地评估检测器的基准数据集。CrowdHuman数据集规模大,注释丰富,包含高度多样化的数据。CrowdHuman包含15000张用于训练,4370张用于验证,5000张用于测试。训练和验证子集中共有47万个人体实例,每张图像平均有23个人体实例,并且数据集中存在各种类型的遮挡。我们使用了与之前数据集相同的训练设置。我们的预训练模型在3750次迭代中达到了最佳性能,超过了之前最好的模型Iter-Deformable-DETR [96]3.1个AP。BDD100K [105]是一个包含约10万张高分辨率图像的数据集,具有多样的天气和光照条件,包括行人、汽车、公交车和自行车等10个物体类别,专门用于目标检测任务。该数据集中的图像是从行驶的车辆中捕获的,模拟了真实场景。在这个实验中,我们使用在427M联合数据集上预训练的InternImage-H模型权重,并在BDD100K的训练集上进行了12个epoch的微调。如表10所示,我们的InternImage-H在验证集上实现了38.8的mAP,达到了最先进的性能,比之前最好的模型高出3.2个mAP。我们的方法在检测现实世界驾驶场景中的目标方面表现出卓越性能,可以为自动驾驶和智能交通系统带来好处。
表10.在各种主流视觉基准上的InternImage-H性能总结。a:MetaFormer [86]。b:MixMIM L [87]。c:SWAG [88]。d:ViT-Adapter [69]。e:PSA [89]。f:CMX-B5 [90]。g:GLIPv2 [91]。h:EVA [92]。i:Cascade Eff-B7 NAS-FPN [93]。j:ATLDETv2 [94]。k:OpenImages 2019 competition 1st [95]。l:Iter-Deformable-DETR [96]。m:PP-YOLOE [97]
C.3.语义分割
COCO-Stuff [85]是一个用于语义分割的数据集,包含了来自COCO [32]数据集的图像,涵盖了171个类别。具体而言,COCO-Stuff-164K是完整的数据集,包含了所有的16.4万张图像,而COCO-Stuff-10K是-164K的一个子集,分为9,000张训练图像和1,000张测试图像。在这里,我们使用了先进的Mask2Former [80]来增强我们的InternImage-H模型,并在COCO-Stuff-164K上进行了80k次迭代的预训练。然后我们在COCO-Stuff-10K上进行了40k次迭代的微调,并报告了多尺度的mIoU。在这个实验中,我们将裁剪大小设置为512×512。如表10所示,我们的模型在测试集上实现了59.6的多尺度mIoU,优于之前最好的ViT-Adapter [69]5.4个mIoU。 Pascal Context [106]包含59个语义类别。它分为4,996张训练图像和5,104张测试图像。对于这个数据集,我们还是用了Mask2Former和InternImage-H,并按照[69]中的训练设置进行训练。具体而言,我们先加载分类预训练权重来初始化模型,然后在Pascal Context的训练集上进行40k次迭代的微调。在这个实验中,我们将裁剪大小设置为480×480。如表10所示,我们的方法在测试集上报告了70.3的多尺度mIoU,比ViT-Adapter [69]高出2.1个mIoU。 Cityscapes [107]是一个在街景中记录的高分辨率数据集,包含19个类别。在这个实验中,我们使用Mask2Former [80]作为分割框架。按照常见的做法[69,83,108],我们首先在Mapillary Vistas [109]上进行预训练,然后在Cityscapes上分别进行80k次迭代的微调。在这个实验中,我们将裁剪大小设置为1024×1024。如表10所示,我们的InternImage-H在验证集上实现了87.0的多尺度mIoU,在测试集上实现了86.1的多尺度mIoU。 NYU Depth V2 [110]包含了1449张RGB-D图像,每张图像的尺寸为640×480。这些图像被分为795张训练图像和654张测试图像,每张图像上有40个语义类别的注释。我们采用了与在Pascal Context上微调时相同的训练设置。如表10所示,我们的方法在验证集上实现了68.1的多尺度mIoU,比CMX-B5 [90]提高了11.2个mIoU。
表11.不同模型在不同输入分辨率下的吞吐量比较。"#params"表示参数数量。在使用单个A100 GPU时,224×224和800×800输入分辨率下的吞吐量分别使用批量大小为256和2进行测试,并在ImageNet-1K验证集上计算top-1准确率。
D.吞吐量分析
在这一部分中,我们将我们的InternImage与其他模型进行了吞吐量的基准测试,包括配备了DCNv2 [28]、ConvNext [21]、RepLKNet [22]和带有变形注意力的视觉变换器(DAT) [46]的变体。如表11所示,与配备了DCNv2 [28]的变体相比,我们的模型在224×224和800×800的输入分辨率下享有更好的参数效率和显著更快的推理速度。与RepLKNet-B [22]和DAT-B [46]相比,我们的模型在高输入分辨率(即800×800)下具有吞吐量优势。这种分辨率在目标检测等密集预测任务中被广泛使用。与ConvNeXt [21]相比,尽管由于基于DCN的运算符而导致的吞吐量差距,我们的模型仍然具有准确性优势(84.9 vs. 83.8),我们也在寻找一种高效的DCN,使我们的模型更适用于需要高效率的下游任务。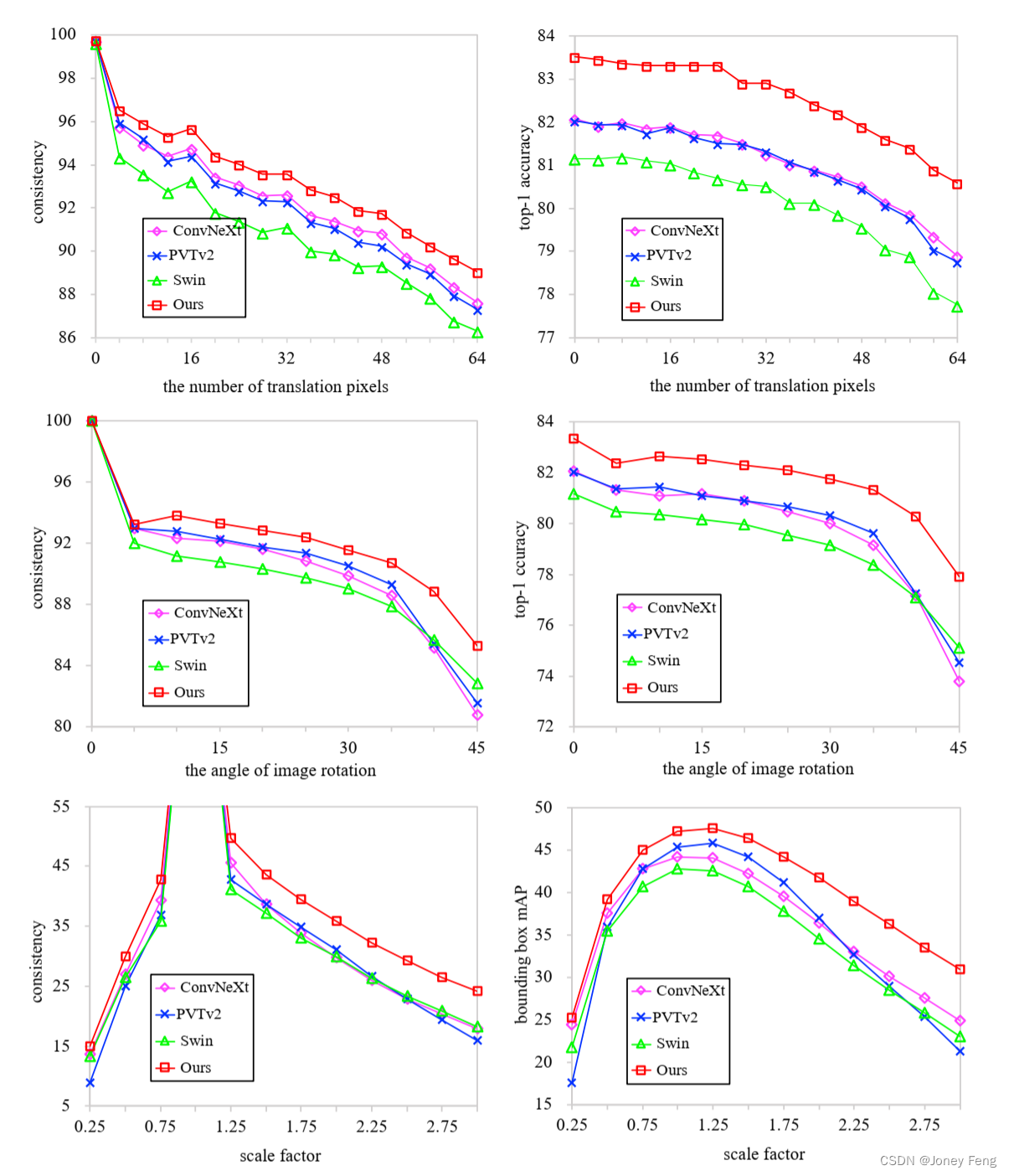 图8.不同方法在鲁棒性评估方面的比较。这些结果表明我们的模型在平移、旋转和输入分辨率方面具有更好的鲁棒性。
图8.不同方法在鲁棒性评估方面的比较。这些结果表明我们的模型在平移、旋转和输入分辨率方面具有更好的鲁棒性。
E.在ImageNet上的鲁棒性
在本节中,我们评估了不同模型在不同变换下的鲁棒性(见图8)。我们考虑了平移、旋转和缩放进行评估。我们选择进行比较的模型包括卷积模型(ConvNeXt-T [21]),基于局部注意力的模型(Swin-T [2]),基于全局注意力的模型(PVTv2-B2 [11])以及我们的InternImage-T模型。
E.1.平移不变性
平移不变性描述了模型在输入图像平移时保持原始输出的能力。我们通过将图像从0到64像素进行抖动来评估分类任务中的平移不变性。当相同的输入图像被平移时,通过模型预测相同标签的概率来衡量不变性。图8的第一行显示了我们的InternImage与其他方法在平移不变性方面的表现。显然,四种模型对平移的鲁棒性表现为我们的方法最好,紧随其后的是基于卷积的ConvNeXt,然后是基于全局注意力的PVTv2,最差的是基于局部注意力的Swin Transformer。
E.2.旋转不变性
为了评估分类任务的旋转不变性,我们将图像从0°到45°以5°的步长进行旋转。与平移不变性类似,使用在不同旋转角度下的预测一致性来评估旋转不变性。从图8的第二行可以看出,在小角度阶段,所有模型的一致性表现相当。然而,在大角度旋转(i.e.,>10°)时,我们的模型明显优于其他模型。
E.3.尺度不变性
我们在目标检测任务中评估了尺度不变性。输入图像的尺度因子从0.25到3.0,步长为0.25。检测一致性被定义为检测任务的不变性度量。在缩放后的图像上预测的框首先被转换回原始分辨率,然后将原始分辨率上的预测框用作计算框mAP的真实框。从图8的最后一行可以看出,我们实验中的所有方法对缩小尺度都比较敏感。在小分辨率下,它们显示出与输入相当的不变性。当放大图像时,我们的方法表现更好。无论是框一致性还是边界框mAP都优于其他方法。
E.4.模型对数据规模的需求程度有多大?
为了验证模型对数据规模的鲁棒性,我们均匀采样了ImageNet-1K数据,分别获得了1%、10%和100%的数据。然后我们选择ResNet-50 [36]、ConvNeXt-T [21]、Swin-T [2]、InternImage-T-dattn和我们的InternImage-T在这些数据上进行了300轮的训练实验。实验设置与表7一致。实验结果如表12所示。我们可以看到ResNet [36]在1%和10%的数据上表现最好(12.2%和57.5%),这得益于它的归纳偏差。但当数据足够时,它的上限较低(80.4%)。Swin-T在1%的数据集上完全失败,只在100%的数据集上表现良好。我们提出的InternImage-T不仅在1%和10%的数据上具有很强的鲁棒性(5.9%和56.0%),而且在完整数据上也表现出色(83.5%),这一点始终优于带有变形注意力(dattn)的InternImage-T变体和ConvNeXt [21]。这些结果表明我们的模型对数据规模具有鲁棒性。
表12.不同模型在不同数据规模下的准确率。"InternImage-dattn"指的是配备变形注意力[56]的模型变体。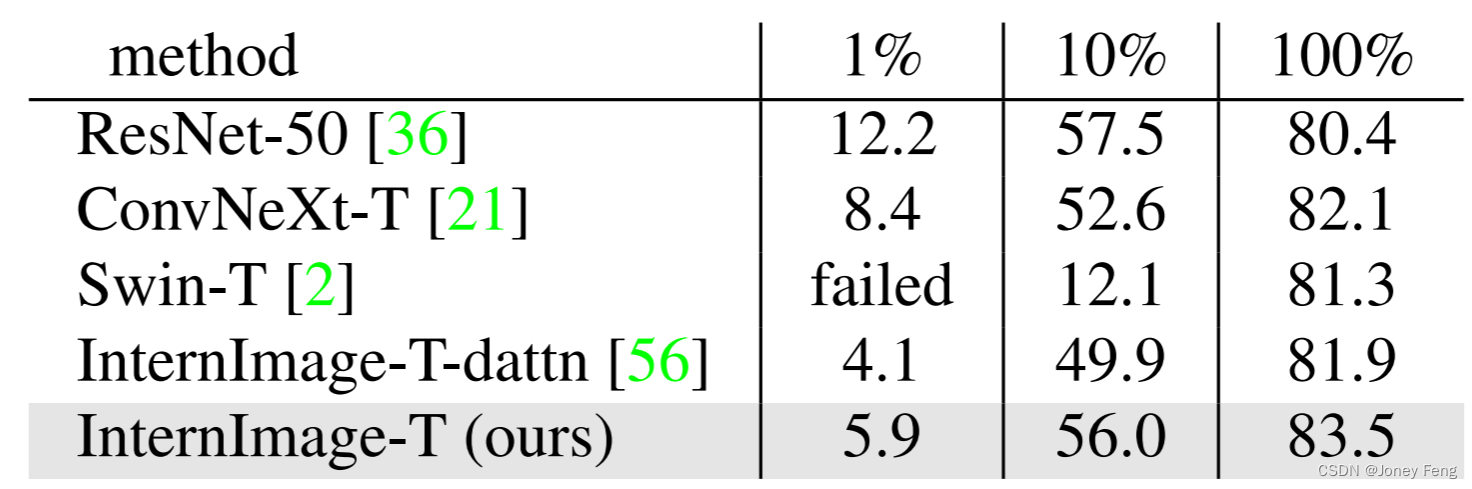
参考文献
[1] Ashish Vaswani等人。注意力就是你所需要的。《高级神经信息处理系统进展》(Adv.Neural Inform.Process.Syst.),30,2017年。1、2、4、5
[2] 刘泽,林雨桐,曹越,胡涵,魏怡轩,张峥,林斌,郭百宁。Swin Transformer: 使用偏移窗口的层次化视觉Transformer。《计算机视觉国际会议》(Int.Conf.Comput.Vis.),2021年。1、2、3、5、6、7、8、10、11、14、15
[3] Mohammad Shoeybi等人。Megatron LM: 使用模型并行训练超过100亿参数语言模型。arXiv预印本arXiv:1909.08053,2019年。1
[4] Alec Radford等人。语言模型是无监督多任务学习器。OpenAI博客,1(8):9,2019年。1
[5] Colin Raffel等人。使用统一的文本到文本Transformer探索迁移学习的极限。《机器学习研究》(Journal of Machine Learning Research),21:1-67,2020年。1
[6] Tom Brown等人。语言模型是少样本学习器。《高级神经信息处理系统进展》(Adv.Neural Inform.Process.Syst.),33:1877-1901,2020年。1
[7] Aakanksha Chowdhery等人。PALM: 使用路径扩展语言建模的规模化。arXiv预印本arXiv:2204.02311,2022年。1
[8] William Fedus,Barret Zoph和Noam Shazeer。Switch Transformer:使用简单高效的稀疏性扩展到万亿参数模型。《机器学习研究》(Journal of Machine Learning Research),23(120):1-39,2022年。1
[9] Alexey Dosovitskiy等人。一张图值得16x16个单词:规模化图像识别的Transformer。《学习表征国际会议》(Int.Conf.Learn.Represent.),2020年。1、2、3、5、7、9
[10] Wenhai Wang等人。金字塔视觉Transformer:一种适用于密集预测的多功能骨干网络。《计算机视觉国际会议》(Int.Conf.Comput.Vis.),2021年。1、3、5、6、9
[11] 汪文海,谢恩泽,李翔,范登平,宋凯涛,梁鼎,卢通,罗平,邵凌。Pvt v2:金字塔视觉变换器改进基准。《计算视觉媒体》8(3):415-424,2022。
[12] 董晓毅,鲍建民,陈东东,张伟明,余能海,袁露,陈东和郭柏宁。Cswin变换器:具有交叉形窗口的通用视觉变换器骨干。IEEE计算机视觉和模式识别会议,页码12124-12134,2022年。
[13] 吴海平,肖斌,诺艾尔·科代拉,刘梦晨,戴希洋,袁露,张雷。Cvt:将卷积引入视觉变换器。国际计算机视觉会议,页码22-31,2021年。
[14] Alaaeldin Ali,Hugo Touvron,Mathilde Caron,Piotr Bojanowski,Matthijs Douze,Armand Joulin,Ivan Laptev,Natalia Neverova,Gabriel Synnaeve,Jakob Verbeek等。Xcit:交叉协方差图像变换器。神经信息处理系统进展,34,2021年。
[15] 韩凯,肖安,吴恩华,郭建元,徐春景,王云鹤。变压器中的变压器。神经信息处理系统进展,34,2021年。
[16] 刘泽,胡汉,林宇彤,姚竹亮,谢振达,魏亦轩,宁佳,曹跃,张征,董立等。Swin变换器v2:扩大容量和分辨率。神经信息处理系统进展,页码12009-12019,2022年。
[17] 王文辉,鲍航博,董力,约翰·比约克,彭志亮,刘强,Kriti Aggarwal,Owais Khan Mohammed,Saksham Singhal,Subhojit Som等。图像作为外语:适用于所有视觉和视觉语言任务的Beit预训练。arXiv预印本arXiv:2208.10442,2022年。
[18] Carlos Riquelme,Joan Puigcerver,Basil Mustafa,Maxim Neumann,Rodolphe Jenatton,Andre Susano Pinto,Daniel Keysers和Neil Houlsby。通过稀疏混合专家扩展视觉。神经信息处理系统进展,34:8583-8595,2021年。
[19] 翟小华,Alexander Kolesnikov,Neil Houlsby和Lucas Beyer。扩展视觉变换器。IEEE计算机视觉和模式识别会议,页码12104-12113,2022年。
[20] 戴子航,刘汉霄,乐乐和谭明兴。Coatnet:将卷积和注意力结合起来适用于所有数据大小。神经信息处理系统进展,34:3965-3977,2021年。
[21] 刘壮,毛汉子,吴超远,Christoph Feichtenhofer,Trevor Darrell和Saining Xie。2020年的ConvNet。arXiv预印本arXiv:2201.03545,2022年。
[22] 丁小翻,张向宇,韩峻工和丁贵光。将卷积核扩展到31x31:重新审视在CNN中的大卷积核设计。IEEE计算机视觉和模式识别会议,页码11963-11975,2022年。
[23] 于伟豪,罗密,周攀,司辰阳,周一辰,王新超,冯家实和严水城。元变换器实际上是您在视觉方面所需的。IEEE计算机视觉和模式识别会议,页码10819-10829,2022年。
[24] Jimmy Lei Ba,Jamie Ryan Kiros和Geoffrey E Hinton。层归一化。arXiv预印本arXiv:1607.06450,2016年。
[25] Dan Hendrycks和Kevin Gimpel。高斯误差线性单元(GELUS)。arxiv.arXiv预印本:1606.08415,2016年。
[26] 魏亦轩,胡汉,谢振达,张征,曹跃,鲍建民,陈东和郭柏宁。反差学习通过特征蒸馏在微调中与掩模图像建模相抗衡。arXiv预印本arXiv:2205.14141,2022年。
[27] Jifeng Dai,Haozhi Qi,Yuwen Xiong,Yi Li,张国栋,胡汉和易晨峰。变形卷积网络。国际计算机视觉会议,页码764-773,2017年。
[28] Xizhou Zhu,Han Hu,Stephen Lin和Jifeng Dai。Deformable convnets v2:更多的可变形,更好的结果。IEEE计算机视觉和模式识别会议,页码9308-9316,2019年。
[29] 刘诗伟,陈天龙,陈晓涵,陈旭曦,肖乔,吴博谦,Mykola Pechenizkiy,Decebal Mocanu和Zhangyang Wang。更多的卷积神经网络在2020年代:使用稀疏性超越51x51的核。arXiv预印本arXiv:2207.03620,2022年。
[30] 翟小华,Alexander Kolesnikov,Neil Houlsby和Lucas Beyer。扩展视觉变换器。IEEE计算机视觉和模式识别会议,页码12104-12113,2022年。
[31] Jia Deng,Wei Dong,Richard Socher,Li-Jia Li,Kai Li和Li Fei-Fei。ImageNet:大规模分层图像数据库。IEEE计算机视觉和模式识别会议,页码248-255,2009年。
[32] 林彤毅,Michael Maire,Serge Belongie,James Hays,Pietro Perona,Deva Ramanan,Piotr Dollar和C Lawrence Zitnick。Microsoft coco:上下文中的常见对象。欧洲计算机视觉会议,页码740-755,2014年。
[33] Alex Krizhevsky,Ilya Sutskever和Geoffrey E Hinton。用深度卷积神经网络对ImageNet分类。ACM通讯,60(6):84-90,2017年。
[34] Karen Simonyan和Andrew Zisserman。非常深的卷积神经网络用于大规模图像识别。arXiv预印本arXiv:1409.1556,2014年。
[35] Christian Szegedy,刘伟,贾阳清,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke和Andrew Rabinovich。越深入越深入的卷积。IEEE计算机视觉和模式识别会议
[36]Kaiming He, 张翔宇, 任少卿和孙剑。用于图像识别的深度残差学习。IEEE计算机视觉和模式识别大会, 2016年,第3、5、12和15页。
[37]谢赛宁,Ross Girshick,皮奥特·达拉尔,杜卓文和郝柯明。用于深度神经网络的聚合残差变换。IEEE计算机视觉和模式识别大会,2017年,第1492-1500页。
[38]明星谷和乐鲲。EfficientNet:重新考虑卷积神经网络的模型缩放。机器学习国际会议, 2019年,第6105-6114页。
[39]明星谷和乐鲲。EfficientNetV2:更小的模型和更快的训练。机器学习国际会议, 2021年,第10096-10106页。
[40]Andrew G Howard,Menglong Zhu,Bo Chen,Dmitry Kalenichenko,Weijun Wang,Tobias Weyand,Marco Andreetto和Hartwig Adam。MobileNet:用于移动视觉应用的高效卷积神经网络。arXiv预印本arXiv:1704.04861,2017年。
[41]丁小汉,张翔宇,韩俊功和丁贵光。将卷积神经网络中的大卷积核设计重新扩展为31x31:IEEE计算机视觉和模式识别大会,2022年,第11963-11975页。
[42]刘世伟,陈天龙,陈晓晗,陈旭曦,肖乔,武博谦,Mykola Pechenizkiy,Decebal Mo canu和Zhangyang Wang。在2020年代中使用稀疏性将卷积神经网络的内核扩大到超过51x51个:arXiv预印本arXiv:2207.03620,2022年。
[43]饶永明,赵文亮,唐燕松,周杰和Ser-Nam Lim和陆继文。 Hornet:递归门控卷积的高效高阶空间交互。arXiv预印本arXiv:2207.14284,2022年,第3、6、7页。
[44]韩琦,樊泽佳,戴琪,孙磊,程明明,刘家英和王景东。关于局部注意力和动态深度卷积之间的联系。学习代表国际会议,2021年。
[45]Sinong Wang,Belinda Z Li,Madian Khabsa,Han Fang和Hao Ma。Linformer:具有线性复杂性的自我关注。arXiv预印本arXiv:2006.04768,2020年。
[46]夏卓范,潘旭然,宋世纪,李尔然和黄高。采用变形注意力的视觉变压器。IEEE计算机视觉和模式识别大会,2022年,第4794-4803页。
[47]Ashish Vaswani,Prajit Ramachandran,Aravind Srinivas,Niki Parmar,Blake Hechtman和Jonathon Shlens。扩展本地自我注意力以实现参数有效的视觉后骨干。IEEE计算机视觉和模式识别大会,2021年,第12894-12904页。
[48]Jared Kaplan,Sam McCandlish,Tom Henighan,Tom B Brown,Benjamin Chess,Rewon Child,Scott Gray,Alec Radford,Jeffrey Wu和Dario Amodei。神经语言模型的缩放定律。arXiv预印本arXiv:2001.08361,2020年。
[49]Mingyu Ding,Bin Xiao,Noel Codella,Ping Luo,Jingdong Wang和Lu Yuan。Davit:双重关注视觉变换器。arXiv预印本arXiv:2204.03645,2022年。
[50]朱锡洲,程大智,张政,林顺宇和戴吉峰。深度网络中空间注意机制的经验研究。计算机视觉国际会议,2019年,第6688-6697页。
[51]陈良杰,George Papandreou,Iasonas Kokkinos,Kevin Murphy和Alan L Yuille。Deeplab:具有深度卷积神经网络,空洞卷积和全连接CRF的语义图像分割。IEEE Trans.Pattern Anal.Mach.Intell.,40(4):834-848,2017年。
[52]L-CCGP Florian和Schroff Hartwig Adam。重新思考分层卷积用于语义图像分割的应用。IEEE计算机视觉和模式识别大会,卷6,2017年。
[53]陈良杰,朱宇坤,George Papandreou,Florian Schroff和Hartwig Adam。使用带空洞可分离卷积的编码器-解码器进行语义图像分割。欧洲计算机视觉会议,2018年,第801-818页。
[54]Yann LeCun,Bernhard Boser,John S Denker,Donnie Henderson,Richard E Howard,Wayne Hubbard和Lawrence D Jackel。反向传播应用于手写邮政编码识别。神经计算,1(4):541-551,1989年。
[55]François Chollet。Xception: 深度可分离卷积的深度学习。IEEE计算机视觉和模式识别大会,2017年,第1251-1258页。
[56]朱锡洲,苏伟杰,卢乐威,李彬,王晓刚和戴吉峰。Deformable DETR: 变形变换器用于端到端目标检测。arXiv预印本arXiv:2010.04159,2020年。
[57]Ruibin Xiong,Yunchang Yang,Di He,Kai Zheng,Shuxin Zheng,Chen Xing,Huishuai Zhang,Yanyan Lan,Liwei Wang和Tieyan Liu。在变形器架构中使用层归一化。机器学习国际会议, 2020年,第10524-10533页。
[58]Hugo Touvron,Matthieu Cord,Matthijs Douze,Francisco Massa,Alexandre Sablayrolles和Herve Jégou。通过注意力进行数据高效图像变换和蒸馏。机器学习国际会议, 2021年,第10347-10357页。
[59]Lu Yuan,Dongdong Chen,陈依玲,Noel Codella,Xiyang Dai,高剑峰,胡厚东,黄学东,李博鑫,李春源等。Florence:计算机视觉的新基础模型。arXiv预印本arXiv:2111.11432,2021年6月7日,10。
[60]苏伟杰,朱锡洲,陶晨欣,陆乐威,李斌,黄高,乔宇,王小刚,周杰,戴继峰。通过最大化多模态互信息实现全一体预训练。arXiv预印本arXiv:2211.09807,2022年6月10日。
[61]Christoph Schuhmann,Richard Vencu,Romain Beaumont,Robert Kaczmarczyk,Clayton Mullis,Aarush Katta,Theo Coombes,Jenia Jitsev和Aran Komatsuzaki。Laion-400m:剪辑过滤的400万图像文本对的开放数据集。arXiv预印本arXiv:2111.02114,2021年6月10日。
[62]Bart Thomee,David A Shamma,Gerald Friedland,Benjamin Elizalde,Karl Ni,Douglas Poland,Damian Borth和Li-Jia Li。Yfcc100m:多媒体研究中的新数据。《ACM通信》,59(2):64-73,2016年6月10日。
[63]Soravit Changpinyo,Piyush Sharma,Nan Ding和Radu Soricut。Conceptual 12m:将Web规模的图像文本预训练推向识别长尾视觉概念。在IEEE Conf.Comput.Vis.Pattern Recog.,页面3558-3568,2021年6月10日。
[64]Hugo Touvron,Matthieu Cord和Herve J ´ egou。Deit iii:Vit的复仇。arXiv预印本arXiv:2204.07118,2022年6月10日,11日。
[65]Jianwei Yang,李春源,张鹏川,戴希阳,肖斌,袁路和高建峰。聚焦自我关注:视觉转换的局部全局交互。arXiv预印本arXiv:2107.00641,2021年6月。
[66]Ismail Khalfaoui Hassani,Thomas Pellegrini和Tim othee Masquelier。具有可学习间隔的扩张卷积。arXiv预印本arXiv:2112.03740,2021年6月。
[67]Alexander Kolesnikov,Lucas Beyer,Xiaohua Zhai,Joan Puigcerver,Jessica Yung,Sylvain Gelly和Neil Houlsby。大规模转移(Bit):通用视觉表示学习。在欧洲。计算机视觉会议,页面491-507。Springer,2020年6月。
[68]Qizhe Xie,Minh-Thang Luong,Eduard Hovy和Quoc V Le。使用嘈杂的学生进行自我训练可改进Imagenet分类。在IEEE Conf.Comput.Vis.Pattern Recog.,页面10687-10698,2020年6月。
[69]Zhe Chen,段宇琛,王文海,何俊俊,卢彤,戴继峰和乔宇。视觉变换器适配器用于密集预测。arXiv预印本arXiv:2205.08534,2022年7月8日,10日,13日,14日。
[70]Kaiming He,Georgia Gkioxari,Piotr Dollar和Ross Gir-´shick。蒙特卡罗树搜索。在Int.Conf.Comput.Vis.,页面2961-2969,2017年7月10日。
[71]Zhaowei Cai和Nuno Vasconcelos。级联r-cnn:高质量物体检测和实例分割。 IEEE Trans.Pattern Anal.Mach.Intell.,43(5):1483-1498,2019年7月10日。
[72]Xiyang Dai,陈隐鹏,肖斌,陈东东,刘梦晨,袁路和张磊。动态头部:将物体检测头部与注意力统一起来。在IEEE Conf.Comput.Vis.Pattern Recog.,页面7373-7382,2021年7月。
[73]Mengde Xu,张振,胡汉,王建峰,王丽娟,魏方云,白翔和刘自成。使用软教师的端到端半监督目标检测。在国际计算机视觉会议上,页面3060-3069,2021年7月。
[74]Hao Zhang,李峰,刘世龙,张磊,苏航,朱军,Lionel M Ni和Heung-Yeung Shum。Dino:具有改进的去噪锚框的Detr端到端目标检测。arXiv预印本arXiv:2203.03605,2022年7月10日。
[75]Jianwei Yang,李春源和高建峰。焦点调制网络。arXiv预印本arXiv:2203.11926,2022年7月。
[76]Qiang Chen,陈晓康,曾刚和王京东。Group detr:使用解耦的一对多标签分配实现快速训练收敛。arXiv预印本arXiv:2207.13085,2022年7月。
[77]Yanghao Li,毛汉梓,Ross Girshick和Kaiming He。探索纯视觉变换器主干用于对象检测。arXiv预印本arXiv:2203.16527,2022年7月。
[78] 梁婷婷,储晓杰,刘宇东,王永涛,唐智,储伟,陈景东和凌海滨。Cb-Net: 一种用于目标检测的复合骨干网络架构。IEEE图像处理期刊,2022年7月10日。
[79]邵帅,李泽明,张天远,彭超,于钢,张祥宇,李静和孙剑。Objects365: 一种用于目标检测的大规模高质量数据集。在国际计算机视觉会议上,2019年7月10日、12日、13日。
[80] 成博文,Ishan Misra,Alexander G Schwing,Alexander Kirillov和Rohit Girdhar。掩码-关注掩码变压器用于通用图像分割。arXiv预印本 arXiv:2112.01527,2021年8月10日、13日、14日。
[81] 肖特特、刘英成、周博磊、姜玉宁和孙剑。统一的感知解析用于场景理解。在欧洲计算机视觉会议上,2018年8月10日。
[82] 周伯磊、赵杭、Xavier Puig、Sanja Fidler、Adela Barriuso和Antonio Torralba。通过ade20k数据集进行场景分割。在IEEE计算机视觉与模式识别会议上,2017年8月10日。
[83] Enze Xie,Wenhai Wang,Zhiding Yu,Anima Anandkumar,Jose M Alvarez和Ping Luo。Segformer: 用于transformer语义分割的简单而有效的设计。在神经信息处理系统进阶版中。第34卷,2021年9月。
[84] Ilya Loshchilov和Frank Hutter。分离的权重衰减正则化。arXiv预印本 arXiv:1711.05101,2017年10月。
[85] Holger Caesar、Jasper Uijlings和Vittorio Ferrari。Coco stuff: 上下文中的Thing和Stuff类。在IEEE计算机视觉与模式识别会议上,2018年10月13日。
[86] 刁启帅、姜轶、闻斌、孙家和袁泽寰。Metaformer: 一种统一的元框架,用于细粒度识别。arXiv预印本 arXiv:2203.02751,2022年12月13日。
[87] 刘继豪、黄鑫、刘宇和李宏生。混合和掩蔽图像建模,实现高效的视觉表示学习。arXiv预印本 arXiv:2205.13137,2022年12月13日。
[88] Mannat Singh、Laura Gustafson、Aaron Adcock、Vinicius de Freitas Reis、Bugra Gedik、Raj Prateek Kosaraju、Dhruv Mahajan、Ross Girshick、Piotr Dollar和Laurens Van Der Maaten。重访视觉感知模型的弱监督预训练。在IEEE计算机视觉与模式识别会议上,2022年12月13日。
[89] 刘华军、刘福强、范新艺和黄东。极化自注意力: 实现高质量像素级回归。arXiv预印本 arXiv:2107.00782,2021年13月。
[90] 刘华尧、张佳明、杨凯伦、胡欣欣和Rainer Stiefelhagen。CMX: 基于transformer的RGB-X语义分割的跨模态融合。arXiv预印本 arXiv:2203.04838,2022年13月、14月。
[91] 张浩天、张鹏川、胡小炜、Yen Chun Chen、Liunian Harold Li、戴希阳、王丽娟、袁璐、Jenq-Neng Hwang和高建峰。GLIPv2: 统一定位和视觉语言理解。arXiv预印本 arXiv:2206.05836,2022年13月。
[92] 方宇鑫、王文、谢斌辉、孙权、Ledell Wu、王兴刚、黄铁军、王鑫龙和曹越。EVA: 探索规模下面罩视觉表示学习的极限。arXiv预印本 arXiv:2211.07636,2022年13月。
[93] Golnaz Ghiasi、Yin Cui、Aravind Srinivas、Rui Qian、Tsung-Yi Lin、Ekin D Cubuk、Quoc V Le和Barret Zoph。简单的复制-粘贴是一种强大的实例分割数据增强方法。在IEEE计算机视觉与模式识别会议上,2021年13月。
[94] 金轩、苏伟、张荣、何元和薛辉。ATLDETv2。http://host.robots.ox.ac.uk/leaderboard/displaylb_main.php?challengeid=11&compid=4,2019年13月。
[95] 刘宇、宋广禄、臧玉航、高岩、谢恩泽、晏俊杰、陈长乐和王晓刚。openimage2019-对象检测和实例分割的第一名解决方案。arXiv预印本 arXiv:2003.07557,2020年13月。
[96] Anlin Zheng、Yuang Zhang、Xiangyu Zhang、Xiaojuan Qi和Jian Sun。拥挤场景下的渐进式端到端目标检测。在IEEE计算机视觉与模式识别会议上,2022年13月。
[97] 徐尚亮、王欣欣、吕文宇、常钦瑶、崔成、邓凯鹏、王冠中、党庆庆、韦盛宇、杜昀宁等。PP-YOLOv2: YOLO的进化版本。arXiv预印本 arXiv:2203.16250,2022年13月。 [98] Grant Van Horn、Oisin Mac Aodha、Yang Song、Yin Cui、Chen Sun、Alex Shepard、Hartwig Adam、Pietro Perona和Serge Belongie。iNaturalist物种分类和检测数据集。在IEEE计算机视觉与模式识别会议上,2018年12月。
[99] 周伯磊、Agata Lapedriza、Jianxiong Xiao、Antonio Torralba和Aude Oliva。使用Places数据库学习场景识别的深度特征。在神经信息处理系统进阶版中。第27卷,2014年12月。
[100] Alejandro Lopez-Cifuentes、Marcos Escudero-Vinolo、Jesus Bescos和Alvaro Garcia-Martin。语义感知场景识别。模式识别,102:107256,2020年12月。
[101] Agrim Gupta、Piotr Dollar和Ross Girshick。LVIS: 一种用于大词汇量实例分割的数据集。在IEEE计算机视觉与模式识别会议上,2019年12月。 [102] Mark Everingham、Luc Van Gool、Christopher KI Williams、John Winn和Andrew Zisserman。Pascal可视对象类别(VOC)挑战赛。
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.core import add_prefix
from mmseg.models import builder
from mmseg.models.builder import SEGMENTORS
from mmseg.models.segmentors.base import BaseSegmentor
from mmseg.ops import resize@SEGMENTORS.register_module()
class EncoderDecoderMask2Former(BaseSegmentor):"""Encoder Decoder segmentors.EncoderDecoder typically consists of backbone, decode_head, auxiliary_head.Note that auxiliary_head is only used for deep supervision during training,which could be dumped during inference."""def __init__(self,backbone,decode_head,neck=None,auxiliary_head=None,train_cfg=None,test_cfg=None,pretrained=None,init_cfg=None):super(EncoderDecoderMask2Former, self).__init__(init_cfg)if pretrained is not None:assert backbone.get('pretrained') is None, \'both backbone and segmentor set pretrained weight'backbone.pretrained = pretrainedself.backbone = builder.build_backbone(backbone)if neck is not None:self.neck = builder.build_neck(neck)decode_head.update(train_cfg=train_cfg)decode_head.update(test_cfg=test_cfg)self._init_decode_head(decode_head)self._init_auxiliary_head(auxiliary_head)self.train_cfg = train_cfgself.test_cfg = test_cfgassert self.with_decode_headdef _init_decode_head(self, decode_head):"""Initialize ``decode_head``"""self.decode_head = builder.build_head(decode_head)self.align_corners = self.decode_head.align_cornersself.num_classes = self.decode_head.num_classesdef _init_auxiliary_head(self, auxiliary_head):"""Initialize ``auxiliary_head``"""if auxiliary_head is not None:if isinstance(auxiliary_head, list):self.auxiliary_head = nn.ModuleList()for head_cfg in auxiliary_head:self.auxiliary_head.append(builder.build_head(head_cfg))else:self.auxiliary_head = builder.build_head(auxiliary_head)def extract_feat(self, img):"""Extract features from images."""x = self.backbone(img)if self.with_neck:x = self.neck(x)return xdef encode_decode(self, img, img_metas):"""Encode images with backbone and decode into a semantic segmentationmap of the same size as input."""x = self.extract_feat(img)out = self._decode_head_forward_test(x, img_metas)out = resize(input=out,size=img.shape[2:],mode='bilinear',align_corners=self.align_corners)return outdef _decode_head_forward_train(self, x, img_metas, gt_semantic_seg,**kwargs):"""Run forward function and calculate loss for decode head intraining."""losses = dict()loss_decode = self.decode_head.forward_train(x, img_metas,gt_semantic_seg, **kwargs)losses.update(add_prefix(loss_decode, 'decode'))return lossesdef _decode_head_forward_test(self, x, img_metas):"""Run forward function and calculate loss for decode head ininference."""seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg)return seg_logitsdef _auxiliary_head_forward_train(self, x, img_metas, gt_semantic_seg):"""Run forward function and calculate loss for auxiliary head intraining."""losses = dict()if isinstance(self.auxiliary_head, nn.ModuleList):for idx, aux_head in enumerate(self.auxiliary_head):loss_aux = aux_head.forward_train(x, img_metas,gt_semantic_seg,self.train_cfg)losses.update(add_prefix(loss_aux, f'aux_{idx}'))else:loss_aux = self.auxiliary_head.forward_train(x, img_metas, gt_semantic_seg, self.train_cfg)losses.update(add_prefix(loss_aux, 'aux'))return lossesdef forward_dummy(self, img):"""Dummy forward function."""seg_logit = self.encode_decode(img, None)return seg_logitdef forward_train(self, img, img_metas, gt_semantic_seg, **kwargs):"""Forward function for training.Args:img (Tensor): Input images.img_metas (list[dict]): List of image info dict where each dicthas: 'img_shape', 'scale_factor', 'flip', and may also contain'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.For details on the values of these keys see`mmseg/datasets/pipelines/formatting.py:Collect`.gt_semantic_seg (Tensor): Semantic segmentation masksused if the architecture supports semantic segmentation task.Returns:dict[str, Tensor]: a dictionary of loss components"""x = self.extract_feat(img)losses = dict()loss_decode = self._decode_head_forward_train(x, img_metas,gt_semantic_seg,**kwargs)losses.update(loss_decode)if self.with_auxiliary_head:loss_aux = self._auxiliary_head_forward_train(x, img_metas, gt_semantic_seg)losses.update(loss_aux)return losses# TODO refactordef slide_inference(self, img, img_meta, rescale):"""Inference by sliding-window with overlap.If h_crop > h_img or w_crop > w_img, the small patch will be used todecode without padding."""h_stride, w_stride = self.test_cfg.strideh_crop, w_crop = self.test_cfg.crop_sizebatch_size, _, h_img, w_img = img.size()num_classes = self.num_classesh_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1preds = img.new_zeros((batch_size, num_classes, h_img, w_img))count_mat = img.new_zeros((batch_size, 1, h_img, w_img))for h_idx in range(h_grids):for w_idx in range(w_grids):y1 = h_idx * h_stridex1 = w_idx * w_stridey2 = min(y1 + h_crop, h_img)x2 = min(x1 + w_crop, w_img)y1 = max(y2 - h_crop, 0)x1 = max(x2 - w_crop, 0)crop_img = img[:, :, y1:y2, x1:x2]crop_seg_logit = self.encode_decode(crop_img, img_meta)preds += F.pad(crop_seg_logit,(int(x1), int(preds.shape[3] - x2), int(y1),int(preds.shape[2] - y2)))count_mat[:, :, y1:y2, x1:x2] += 1assert (count_mat == 0).sum() == 0if torch.onnx.is_in_onnx_export():# cast count_mat to constant while exporting to ONNXcount_mat = torch.from_numpy(count_mat.cpu().detach().numpy()).to(device=img.device)preds = preds / count_matif rescale:preds = resize(preds,size=img_meta[0]['ori_shape'][:2],mode='bilinear',align_corners=self.align_corners,warning=False)return predsdef whole_inference(self, img, img_meta, rescale):"""Inference with full image."""seg_logit = self.encode_decode(img, img_meta)if rescale:# support dynamic shape for onnxif torch.onnx.is_in_onnx_export():size = img.shape[2:]else:size = img_meta[0]['ori_shape'][:2]seg_logit = resize(seg_logit,size=size,mode='bilinear',align_corners=self.align_corners,warning=False)return seg_logitdef inference(self, img, img_meta, rescale):"""Inference with slide/whole style.Args:img (Tensor): The input image of shape (N, 3, H, W).img_meta (dict): Image info dict where each dict has: 'img_shape','scale_factor', 'flip', and may also contain'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.For details on the values of these keys see`mmseg/datasets/pipelines/formatting.py:Collect`.rescale (bool): Whether rescale back to original shape.Returns:Tensor: The output segmentation map."""assert self.test_cfg.mode in ['slide', 'whole']ori_shape = img_meta[0]['ori_shape']assert all(_['ori_shape'] == ori_shape for _ in img_meta)if self.test_cfg.mode == 'slide':seg_logit = self.slide_inference(img, img_meta, rescale)else:seg_logit = self.whole_inference(img, img_meta, rescale)output = F.softmax(seg_logit, dim=1)flip = img_meta[0]['flip']if flip:flip_direction = img_meta[0]['flip_direction']assert flip_direction in ['horizontal', 'vertical']if flip_direction == 'horizontal':output = output.flip(dims=(3,))elif flip_direction == 'vertical':output = output.flip(dims=(2,))return outputdef simple_test(self, img, img_meta, rescale=True):"""Simple test with single image."""seg_logit = self.inference(img, img_meta, rescale)seg_pred = seg_logit.argmax(dim=1)if torch.onnx.is_in_onnx_export():# our inference backend only support 4D outputseg_pred = seg_pred.unsqueeze(0)return seg_predseg_pred = seg_pred.cpu().numpy()# unravel batch dimseg_pred = list(seg_pred)return seg_preddef aug_test(self, imgs, img_metas, rescale=True):"""Test with augmentations.Only rescale=True is supported."""# aug_test rescale all imgs back to ori_shape for nowassert rescale# to save memory, we get augmented seg logit inplaceseg_logit = self.inference(imgs[0], img_metas[0], rescale)for i in range(1, len(imgs)):cur_seg_logit = self.inference(imgs[i], img_metas[i], rescale)seg_logit += cur_seg_logitseg_logit /= len(imgs)seg_pred = seg_logit.argmax(dim=1)seg_pred = seg_pred.cpu().numpy()# unravel batch dimseg_pred = list(seg_pred)return seg_pred# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from mmseg.core import add_prefix
from mmseg.models import builder
from mmseg.models.builder import SEGMENTORS
from mmseg.models.segmentors.base import BaseSegmentor
from mmseg.ops import resize@SEGMENTORS.register_module()
class EncoderDecoderMask2FormerAug(BaseSegmentor):"""Encoder Decoder segmentors.EncoderDecoder typically consists of backbone, decode_head, auxiliary_head.Note that auxiliary_head is only used for deep supervision during training,which could be dumped during inference."""def __init__(self,backbone,decode_head,neck=None,auxiliary_head=None,train_cfg=None,test_cfg=None,pretrained=None,init_cfg=None):super(EncoderDecoderMask2FormerAug, self).__init__(init_cfg)if pretrained is not None:assert backbone.get('pretrained') is None, \'both backbone and segmentor set pretrained weight'backbone.pretrained = pretrainedself.backbone = builder.build_backbone(backbone)if neck is not None:self.neck = builder.build_neck(neck)decode_head.update(train_cfg=train_cfg)decode_head.update(test_cfg=test_cfg)self._init_decode_head(decode_head)self._init_auxiliary_head(auxiliary_head)self.train_cfg = train_cfgself.test_cfg = test_cfgassert self.with_decode_headdef _init_decode_head(self, decode_head):"""Initialize ``decode_head``"""self.decode_head = builder.build_head(decode_head)self.align_corners = self.decode_head.align_cornersself.num_classes = self.decode_head.num_classesdef _init_auxiliary_head(self, auxiliary_head):"""Initialize ``auxiliary_head``"""if auxiliary_head is not None:if isinstance(auxiliary_head, list):self.auxiliary_head = nn.ModuleList()for head_cfg in auxiliary_head:self.auxiliary_head.append(builder.build_head(head_cfg))else:self.auxiliary_head = builder.build_head(auxiliary_head)def extract_feat(self, img):"""Extract features from images."""x = self.backbone(img)if self.with_neck:x = self.neck(x)return xdef encode_decode(self, img, img_metas):"""Encode images with backbone and decode into a semantic segmentationmap of the same size as input."""x = self.extract_feat(img)out = self._decode_head_forward_test(x, img_metas)out = resize(input=out,size=img.shape[2:],mode='bilinear',align_corners=self.align_corners)return outdef _decode_head_forward_train(self, x, img_metas, gt_semantic_seg,**kwargs):"""Run forward function and calculate loss for decode head intraining."""losses = dict()loss_decode = self.decode_head.forward_train(x, img_metas,gt_semantic_seg, **kwargs)losses.update(add_prefix(loss_decode, 'decode'))return lossesdef _decode_head_forward_test(self, x, img_metas):"""Run forward function and calculate loss for decode head ininference."""seg_logits = self.decode_head.forward_test(x, img_metas, self.test_cfg)return seg_logitsdef _auxiliary_head_forward_train(self, x, img_metas, gt_semantic_seg):"""Run forward function and calculate loss for auxiliary head intraining."""losses = dict()if isinstance(self.auxiliary_head, nn.ModuleList):for idx, aux_head in enumerate(self.auxiliary_head):loss_aux = aux_head.forward_train(x, img_metas,gt_semantic_seg,self.train_cfg)losses.update(add_prefix(loss_aux, f'aux_{idx}'))else:loss_aux = self.auxiliary_head.forward_train(x, img_metas, gt_semantic_seg, self.train_cfg)losses.update(add_prefix(loss_aux, 'aux'))return lossesdef forward_dummy(self, img):"""Dummy forward function."""seg_logit = self.encode_decode(img, None)return seg_logitdef forward_train(self, img, img_metas, gt_semantic_seg, **kwargs):"""Forward function for training.Args:img (Tensor): Input images.img_metas (list[dict]): List of image info dict where each dicthas: 'img_shape', 'scale_factor', 'flip', and may also contain'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.For details on the values of these keys see`mmseg/datasets/pipelines/formatting.py:Collect`.gt_semantic_seg (Tensor): Semantic segmentation masksused if the architecture supports semantic segmentation task.Returns:dict[str, Tensor]: a dictionary of loss components"""x = self.extract_feat(img)losses = dict()loss_decode = self._decode_head_forward_train(x, img_metas,gt_semantic_seg,**kwargs)losses.update(loss_decode)if self.with_auxiliary_head:loss_aux = self._auxiliary_head_forward_train(x, img_metas, gt_semantic_seg)losses.update(loss_aux)return losses# TODO refactordef slide_inference(self, img, img_meta, rescale, unpad=True):"""Inference by sliding-window with overlap.If h_crop > h_img or w_crop > w_img, the small patch will be used todecode without padding."""h_stride, w_stride = self.test_cfg.strideh_crop, w_crop = self.test_cfg.crop_sizebatch_size, _, h_img, w_img = img.size()num_classes = self.num_classesh_grids = max(h_img - h_crop + h_stride - 1, 0) // h_stride + 1w_grids = max(w_img - w_crop + w_stride - 1, 0) // w_stride + 1preds = img.new_zeros((batch_size, num_classes, h_img, w_img))count_mat = img.new_zeros((batch_size, 1, h_img, w_img))for h_idx in range(h_grids):for w_idx in range(w_grids):y1 = h_idx * h_stridex1 = w_idx * w_stridey2 = min(y1 + h_crop, h_img)x2 = min(x1 + w_crop, w_img)y1 = max(y2 - h_crop, 0)x1 = max(x2 - w_crop, 0)crop_img = img[:, :, y1:y2, x1:x2]crop_seg_logit = self.encode_decode(crop_img, img_meta)preds += F.pad(crop_seg_logit,(int(x1), int(preds.shape[3] - x2), int(y1),int(preds.shape[2] - y2)))count_mat[:, :, y1:y2, x1:x2] += 1assert (count_mat == 0).sum() == 0if torch.onnx.is_in_onnx_export():# cast count_mat to constant while exporting to ONNXcount_mat = torch.from_numpy(count_mat.cpu().detach().numpy()).to(device=img.device)preds = preds / count_matif unpad:unpad_h, unpad_w = img_meta[0]['img_shape'][:2]# logging.info(preds.shape, img_meta[0])preds = preds[:, :, :unpad_h, :unpad_w]if rescale:preds = resize(preds,size=img_meta[0]['ori_shape'][:2],mode='bilinear',align_corners=self.align_corners,warning=False)return predsdef whole_inference(self, img, img_meta, rescale):"""Inference with full image."""seg_logit = self.encode_decode(img, img_meta)if rescale:# support dynamic shape for onnxif torch.onnx.is_in_onnx_export():size = img.shape[2:]else:size = img_meta[0]['ori_shape'][:2]seg_logit = resize(seg_logit,size=size,mode='bilinear',align_corners=self.align_corners,warning=False)return seg_logitdef inference(self, img, img_meta, rescale):"""Inference with slide/whole style.Args:img (Tensor): The input image of shape (N, 3, H, W).img_meta (dict): Image info dict where each dict has: 'img_shape','scale_factor', 'flip', and may also contain'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.For details on the values of these keys see`mmseg/datasets/pipelines/formatting.py:Collect`.rescale (bool): Whether rescale back to original shape.Returns:Tensor: The output segmentation map."""assert self.test_cfg.mode in ['slide', 'whole']ori_shape = img_meta[0]['ori_shape']assert all(_['ori_shape'] == ori_shape for _ in img_meta)if self.test_cfg.mode == 'slide':seg_logit = self.slide_inference(img, img_meta, rescale)else:seg_logit = self.whole_inference(img, img_meta, rescale)output = F.softmax(seg_logit, dim=1)flip = img_meta[0]['flip']if flip:flip_direction = img_meta[0]['flip_direction']assert flip_direction in ['horizontal', 'vertical']if flip_direction == 'horizontal':output = output.flip(dims=(3, ))elif flip_direction == 'vertical':output = output.flip(dims=(2, ))return outputdef simple_test(self, img, img_meta, rescale=True):"""Simple test with single image."""seg_logit = self.inference(img, img_meta, rescale)seg_pred = seg_logit.argmax(dim=1)if torch.onnx.is_in_onnx_export():# our inference backend only support 4D outputseg_pred = seg_pred.unsqueeze(0)return seg_predseg_pred = seg_pred.cpu().numpy()# unravel batch dimseg_pred = list(seg_pred)return seg_preddef aug_test(self, imgs, img_metas, rescale=True):"""Test with augmentations.Only rescale=True is supported."""# aug_test rescale all imgs back to ori_shape for nowassert rescale# to save memory, we get augmented seg logit inplaceseg_logit = self.inference(imgs[0], img_metas[0], rescale)for i in range(1, len(imgs)):cur_seg_logit = self.inference(imgs[i], img_metas[i], rescale)seg_logit += cur_seg_logitseg_logit /= len(imgs)seg_pred = seg_logit.argmax(dim=1)seg_pred = seg_pred.cpu().numpy()# unravel batch dimseg_pred = list(seg_pred)return seg_pred这篇关于InternImage: 使用可变形卷积探索大规模视觉基础模型(Exploring Large-Scale Vision Foundation Models with Deformable Conv)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





