大规模专题

Flink在大规模状态数据集下的checkpoint调优
今天接到一个同学的反馈问题,大概是: Flink程序运行一段时间就会报这个错误,定位好多天都没有定位到。checkpoint时间是5秒,20秒都不行。 Caused by: java.io.IOException: Could not flush and close the file system output stream to hdfs://HDFSaaaa/flink/PointWid

正面超越Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用(下)
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 我们书接上文,我们在之前的文章《正面超越Spark | 几大特性垫定Flink1.12流计算领域真正大规模生产可用(上)》详细描述了Flink的生产级别Flink on K8s高可用方案和DataStream API 对批执行模式的支持。 接下来是另外的几个特性增强。 第三个,Flink对SQL操作的全面支持 再很早之前,我在浏览社

区块链ARC如何能让节点能够大规模处理交易数据
发表时间:2024年8月7日 TAAL技术主管Michael Böckli表示,TAAL公司一直在对ARC进行测试,并准备在今年年底全面发布。因TAAL在区块链交易处理方面具备深厚的专业知识,BSV区块链委托TAAL进行ARC开源参考落地方案的开发。 ARC是一个多层交易处理系统,能够追踪交易在BSV区块链上的整个生命周期。 除了遵循BSV区块链的开源指南和要求开发ARC的开源版

【大规模语言模型:从理论到实践】Transformer中PositionalEncoder详解
书籍链接:大规模语言模型:从理论到实践 第15页位置表示层代码详解 1. 构造函数 __init__() def __init__(self, d_model, max_seq_len=80):super().__init__()self.d_model = d_model # 嵌入的维度(embedding dimension) d_model: 表示输入词向量的维度。max_se

CPU服务器如何应对大规模并行计算需求?
大规模并行计算是指利用多个处理单元同时处理计算任务,以提高计算效率和缩短完成时间。这种计算方式常用于科学计算、数据分析、机器学习、图像处理等领域,面对海量数据与复杂计算时,传统的串行计算往往显得无能为力。 现代 CPU 通常具备多个核心,这使得它们能够在同一时间内并行执行多个线程或任务。多核处理器可以大幅提升并行计算能力,适合处理大型计算任务。 CPU 服务器通常配备多级高速缓存(

大规模语言模型开发基础与实践
💂 个人网站:【 摸鱼游戏】【网址导航】【神级代码资源网站】🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交流,摸鱼划水的小伙伴,请点击【全栈技术交流群】 除了 Boss直聘,在找工作的朋友也可以使用【万码优才】:内推~避免已读不回的问题,解锁N多求职岗位: #小程序://万码优才/HDQZJEQiCJb9cFi 一、引言 近年来,大规模语言模型(LLM)迅速
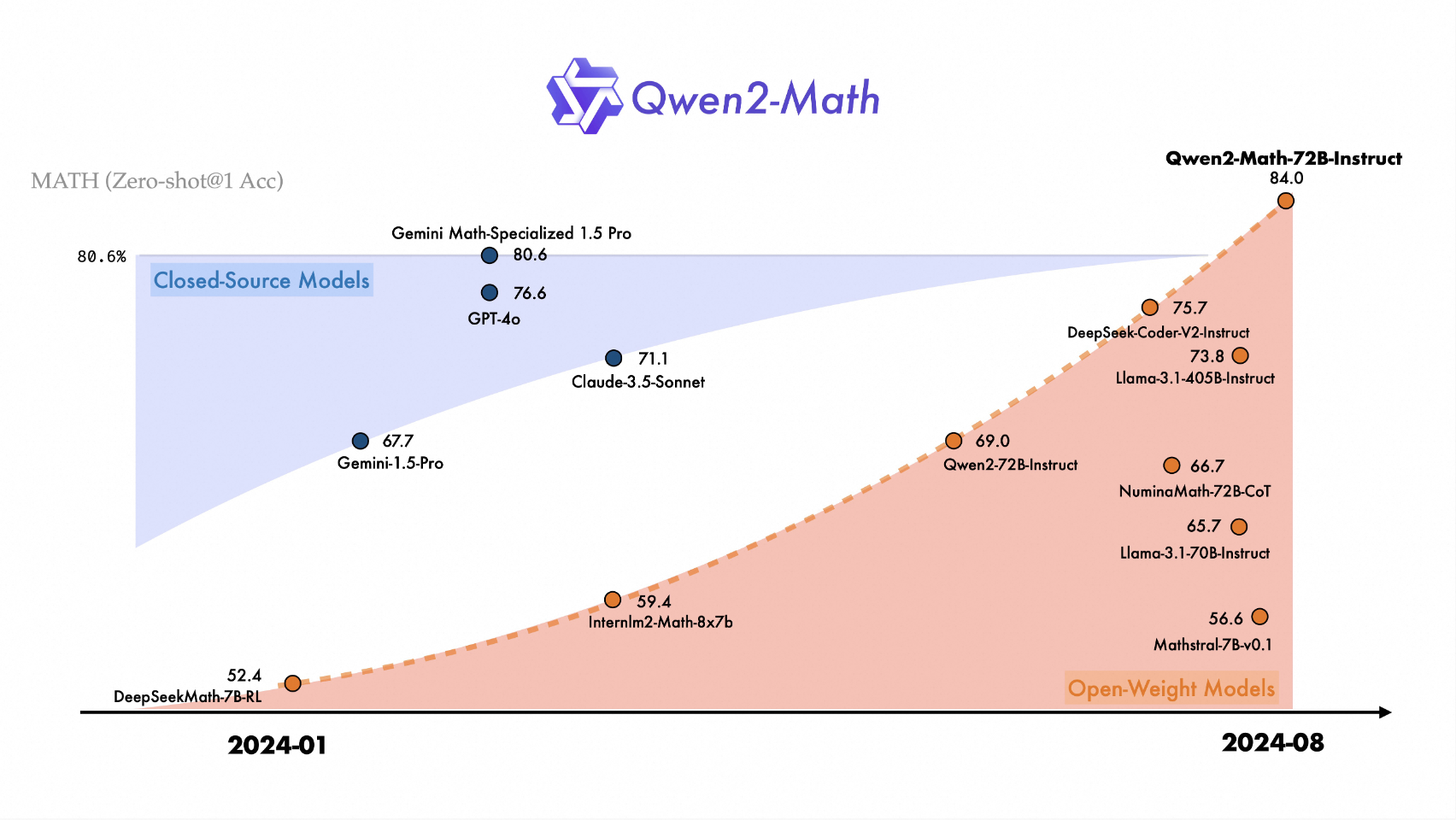
阿里PAI-ChatLearn:大规模 Alignment高效训练框架正式开源
导读 ChatGPT是OpenAI开发的基于大型语言模型(LLM)的聊天机器人,以其令人惊叹的对话能力而迅速火爆并被广泛采用。ChatGPT 成功背后得益于大型语言模型生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback),即以强化学习方式依据人类反馈优化语言模型。不同于传统的深度学习训练,只涉及到单个模型的迭代和优化,以 RLH

基于麒麟信安操作系统的光伏发电功率预测系统完成大规模部署建设
麒麟信安操作系统,作为行业数智化建设的安全根基,为电力业务系统提供了稳定可靠的底层平台,在全球能源结构转型大潮中扮演着至关重要的角色。某光伏电站项目中,基于麒麟信安操作系统的光伏发电功率预测系统完成大规模部署建设,充分展现电力新型生产场景中的自主创新能力。 光伏发电作为一种安全、可持续的能源生产方式,对于优化能源结构、改善生态环境有重要意义。光伏发电功率预测系统是实现“双碳”目标下,新型光伏

【人工智能】项目案例分析:使用TensorFlow进行大规模对象检测
一、项目概述 在这个项目中,我们将使用TensorFlow进行大规模的对象检测。对象检测是计算机视觉领域的一个重要应用,它涉及从图像或视频中识别和定位特定的对象。TensorFlow作为一个强大的开源机器学习库,提供了丰富的工具和API来支持这一任务。 二、项目结构 1.数据准备 原始数据集 收集或下载已标注的数据集,例如COCO数据集。确保每张图片都带有相应的标注文件(如XML或JSO

探索分析文档布局,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建大规模文档数据集DocLayNet场景下文档图像布局智能检测分析识别系统
随着数字化和信息化的快速发展,大量的文档(如合同、报告、表格、发票等)以电子形式存在,这些文档中包含了丰富的信息。然而,这些信息往往以非结构化的形式存在,难以直接被计算机程序理解和处理。文档布局分析任务的目的就是将这些非结构化的文档转换为结构化的数据,从而使得计算机能够自动地理解、分类、检索和处理这些文档中的信息。 为了推动文档布局分析技术的发展,需要一个大规模、多样性、高质量的数据集来训练和评

大规模泛癌筛选揭示抗癌药物组合的新希望
大规模泛癌筛选揭示抗癌药物组合的新希望 引言 在抗癌治疗中,药物组合因其潜在的增效作用而备受关注。然而,由于可能的组合数量巨大且肿瘤间存在显著的异质性,识别真正有效的药物组合成为一项极具挑战性的任务。近期,一项发表在《Cell Reports Medicine》上的研究通过大规模细胞系筛选,揭示了多种具有潜在临床益处的抗癌药物组合,为精准医疗提供了新的线索。 研究方法 本研究团队筛

【mysql】大规模企业常用的MySQL性能优化方案分享
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全栈,前后端开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi
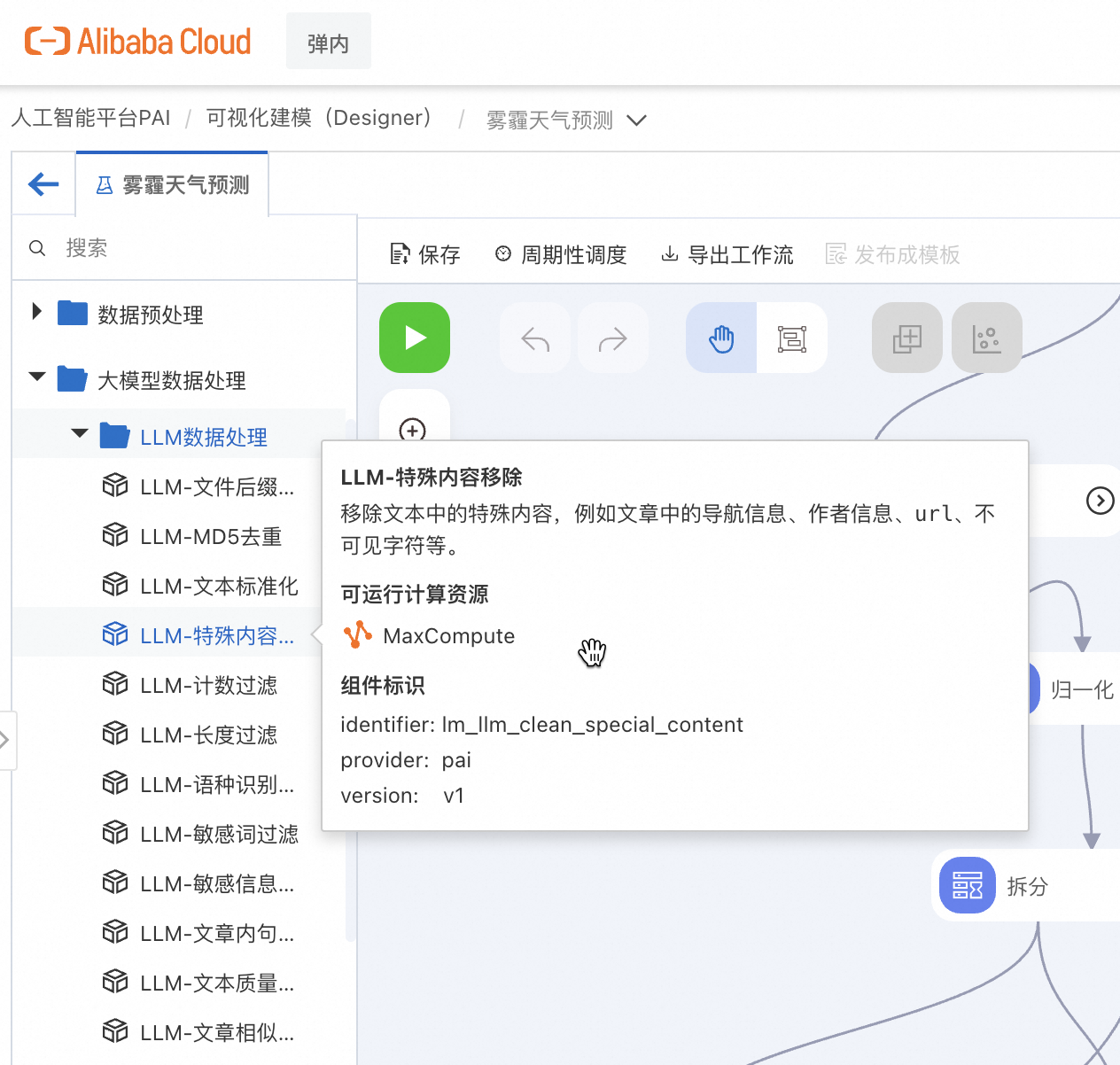
Big Data for AI实践:面向AI大模型开发和应用的大规模数据处理套件
作者:夕陌,临在,熊兮,道辕,得水,施晨 随着人工智能技术的快速发展,大模型在各个领域的应用日益广泛。大模型能够更好地模拟人类的认知能力,大幅提升机器在复杂任务上的表现。然而,不断增长的模型参数规模使得数据集的复杂度也不断上升,数据质量更直接影响模型的准确性和可靠性。本文叙述的 Big Data for AI 最佳实践,基于阿里云人工智能平台PAI、MaxCompute自研分布式计算框架Ma
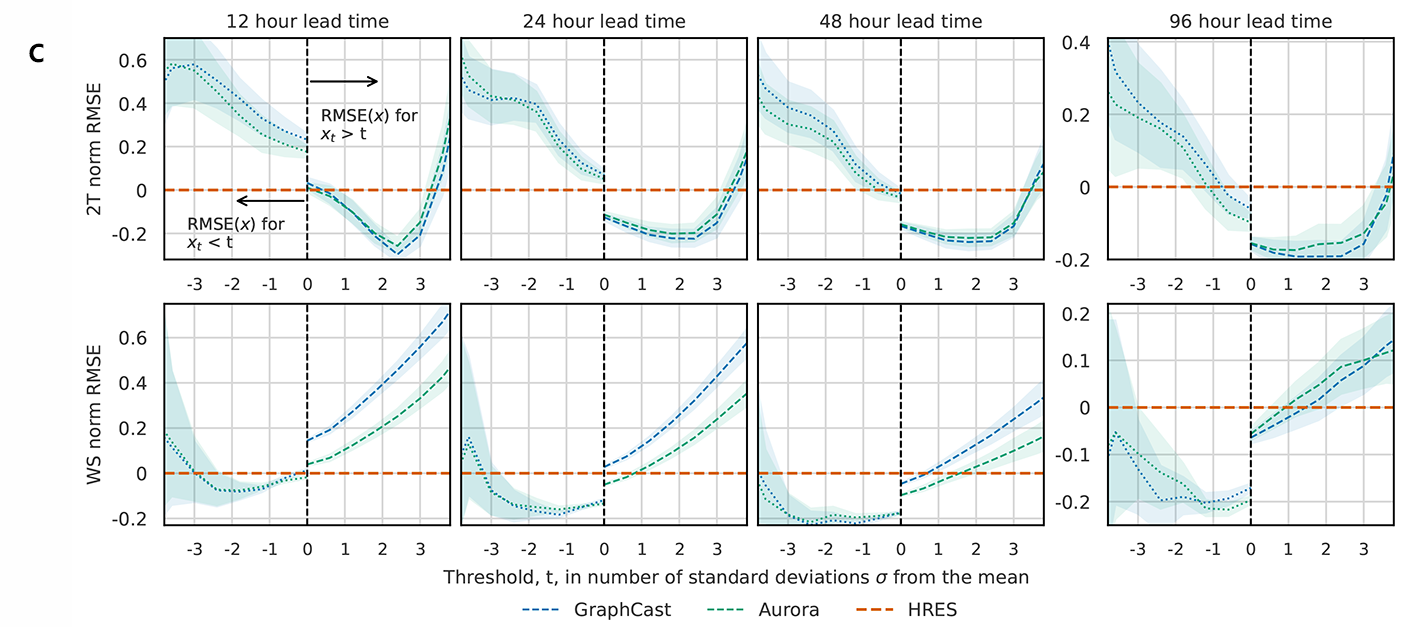
AI赋能天气:微软研究院发布首个大规模大气基础模型Aurora
编者按:气候变化日益加剧,高温、洪水、干旱,频率和强度不断增加的全球极端天气给整个人类社会都带来了难以估计的影响。这给现有的天气预测模型提出了更高的要求——这些模型要更准确地预测极端天气变化,为政府、企业和公众提供更可靠的信息,以便做出及时的准备和响应。为了应对这一挑战,微软研究院开发了首个大规模大气基础模型 Aurora,其超高的预测准确率、效率及计算速度,实现了目前最先进天气预测系统性能的显著
在 Clojure 中,如何实现高效的并发编程以处理大规模数据处理任务?
在Clojure中,可以使用以下几种方式来实现高效的并发编程以处理大规模数据处理任务: 并发集合(Concurrent Collections):Clojure提供了一些并发集合数据结构,如ref、agent和atom,它们能够在多个线程之间共享和修改数据。通过使用这些数据结构,可以实现高效的并发访问和更新数据。 异步编程:Clojure提供了一些异步编程的机制,如promise和futur

数据结构与算法笔记:基础篇 - 分治算法:谈一谈大规模计算框架MapReduce中的分治思想
概述 MapReduce 是 Google 大数据处理的三姐马车之一,另外两个事 GFS 和 Bigtable。它在倒排索引、PageRank 计算、网页分析等搜索引擎相关的技术中都有大量的应用。 尽管开发一个 MapReduce 看起来很高深。实际上,万变不离其宗,它的本质就是本章要学的这种算法思想,分支算法。 如何理解分支算法? 为什么说 MapReduce 的本质就是分治算法呢?

全新量子计算技术!在硅中可以生成大规模量子比特
内容来源:量子前哨(ID:Qforepost) 文丨沛贤/浪味仙 排版丨沛贤 深度好文:1600字丨6分钟阅读 摘要:研究人员利用气体环境在硅中形成被称为“色心”的可编程缺陷,首次利用飞秒激光,实现了在掺氢硅中按需精准创建量子比特,有助于实现更安全、更高效的量子互联网。 图片:考沙利亚-朱里亚(Kaushalya Jhuria)在实验室测试用于在硅片中制造量子
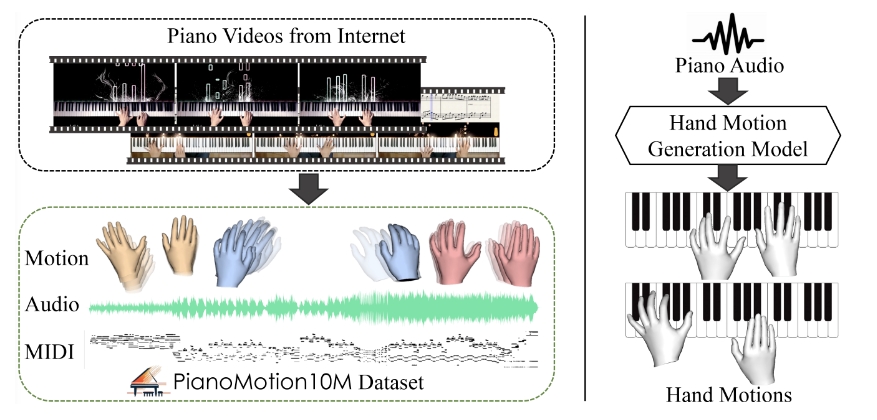
开源的代码语言模型DeepSeek-Coder-V2;Runway推出Gen-3;多层架构整合多个大语言模型;大规模钢琴手部动作数据集和基准
✨ 1: DeepSeek-Coder-V2 开源的多专家代码语言模型,支持338种编程语言。 DeepSeek-Coder-V2 是一个开源的代码语言模型,专为代码生成、代码补全、代码修复以及数学推理等任务而设计。该模型通过在大量高质量的多源语料库上进一步训练,显著提升了其在代码生成和数学推理方面的能力,同时在一般语言任务中的表现也保持在同等水平。DeepSeek-Coder-V2
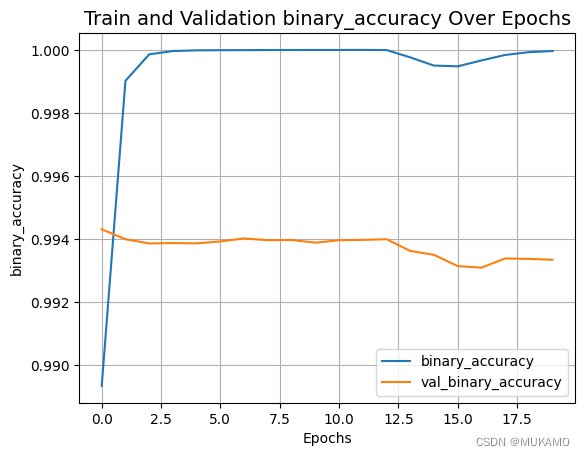
【机器学习】对大规模的文本数据进行多标签的分类处理
1. 引言 1.1. NLP研究的背景 随着人工智能技术的飞速发展,智能助手、聊天机器人和虚拟客服的需求正呈现出爆炸性增长。这些技术不仅为人们提供了极大的生活便利,如日程管理、信息查询和情感陪伴,还在工作场景中显著提高了效率。聊天机器人凭借自然语言处理技术的进步,能够更准确地理解用户需求,并在多元化应用场景中提供个性化的服务。而虚拟客服则通过降低企业运营成本、提升服务效率以及提供数据分析与优化

随着技术的不断发展,Perl 在处理大规模数据和高并发场景下的性能优化策略有哪些?
Perl 在处理大规模数据和高并发场景下的性能优化策略有以下几点: 选择合适的数据结构:对于大规模数据,选择合适的数据结构可以提高Perl程序的性能。例如,使用数组而不是哈希表可以节省内存和加快访问速度。 使用内置函数和操作符:Perl提供了许多内置函数和操作符,它们通常比自定义函数更快。使用内置函数和操作符可以提高Perl程序的执行速度。 使用正则表达式优化:Perl的正则表达式是其强大
大规模数据的PCA降维
20200810 - 0. 引言 最近在做的文本可视化的内容,文本处理的方法是利用sklearn的CountVer+Tf-idf,这样处理数据之后,一方面数据的维度比较高,另一方面呢,本身这部分数据量也比较大。如果直接使用sklearn的pca进行降维,会很慢,而且pca也没有n_jobs来支持多线程工作。不过,我看到spark中已经支持的pca了,所以希望通过spark来实现这部分内容。
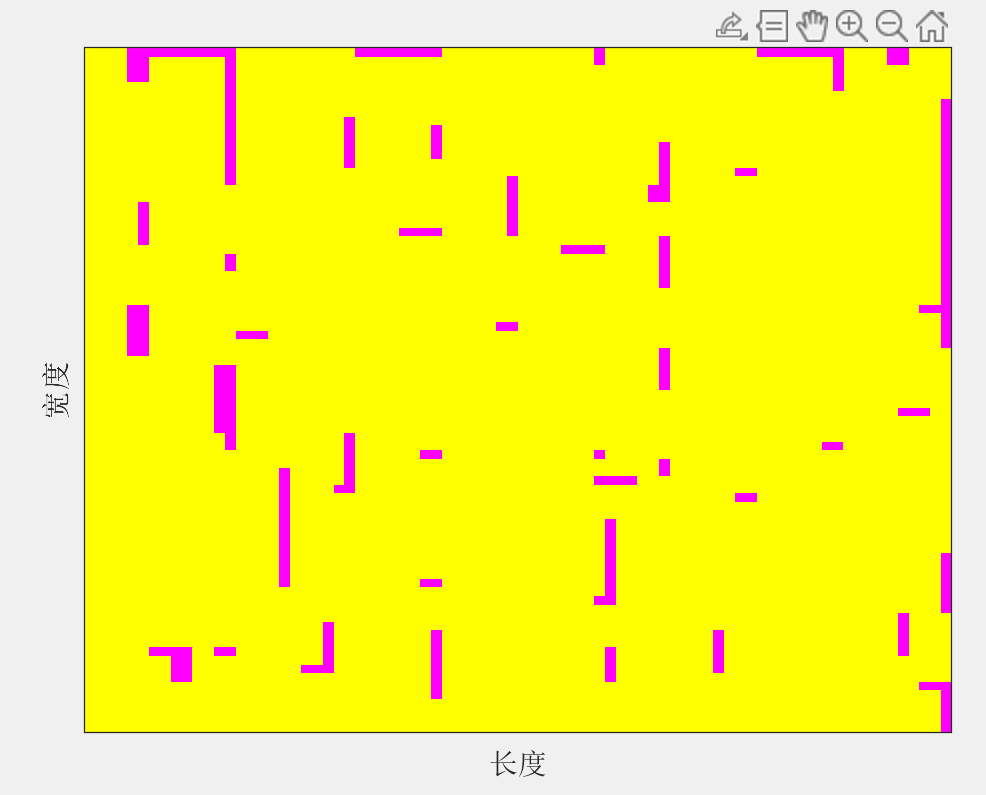
大规模装箱问题:蜣螂优化算法DBO求解二维装箱问题(MATLAB代码)
一、问题描述 装载率:所有选择的箱子的总面积与夹板面积之比 假设一共有300个箱子,如何设计算法,使得选择部分箱子放入80*80的甲板上,让甲板的装载率越大,要求箱子间不得重叠。 二、蜣螂优化算法求解二维装箱问题 蜣螂优化算法的目标函数是甲板的装载率 2.1部分代码 % ----------------------------------------------------------
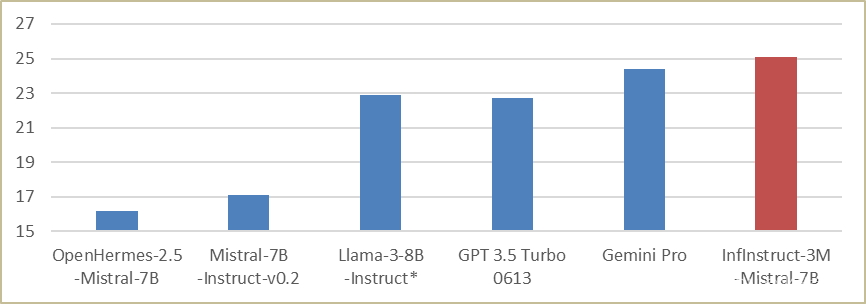
北京人工智能数据运营平台发布,并开源大规模数据集
6月14日,AI行业顶级盛会2024北京智源大会正式拉开帷幕。作为大会的重要组成部分,智源大会“人工智能+数据新基建”论坛同步召开。本论坛由北京智源人工智能研究院主办,中国互联网协会人工智能工委会和中国移动研究院承办。本次论坛邀请到来自中国互联网协会、中国移动通信集团有限公司、中国电子云、北京大学、复旦大学、南方电网、中国航信、国双科技等单位和学校的领导和专家,共同探讨面向人工智能+的数据汇聚、生

SK海力士计划于2024年第四季度启动GDDR7大规模生产
SK海力士,作为HBM市场的领头羊,于6月13日宣布,公司目标于2024年第四季度开始其GDDR7芯片的大规模生产。 与此同时,美光科技在Computex展会上也宣布推出其GDDR7图形内存,目前正处于样品测试阶段。据AnandTech报道,美光不仅计划在今年启动GDDR7的大规模生产,而且目标是在年底前让部分客户能够出货成品,其主要应用领域覆盖人工智能、游戏以及高性能计算。 另一方面,三
【紧急警示】Locked勒索病毒利用最新PHP远程代码执行漏洞大规模批量勒索!文末附详细加固方案
1. Locked勒索病毒介绍 locked勒索病毒属于TellYouThePass勒索病毒家族的变种,其家族最早于2019年3月出现,擅长利用高危漏洞被披露后的短时间内,利用1Day对暴露于网络上并存在有漏洞未修复的机器发起攻击。该家族在2023年下半年开始,频繁针对国内常见大型ERP系统的漏洞进行攻击,并且会利用钓鱼邮件针对财务人员个人主机进行钓鱼和入侵攻击。 其曾经使用过的代表性漏洞有:

Python 大规模数据存储与读取、并行计算:Dask库简述
本文转自:https://blog.csdn.net/sinat_26917383/article/details/78044437 数据结构与pandas非常相似,比较容易理解。 原文文档:http://dask.pydata.org/en/latest/index.html github:https://github.com/dask dask的内容很多,挑一些我比较看好的内容着重点一