本文主要是介绍北京人工智能数据运营平台发布,并开源大规模数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
6月14日,AI行业顶级盛会2024北京智源大会正式拉开帷幕。作为大会的重要组成部分,智源大会“人工智能+数据新基建”论坛同步召开。本论坛由北京智源人工智能研究院主办,中国互联网协会人工智能工委会和中国移动研究院承办。本次论坛邀请到来自中国互联网协会、中国移动通信集团有限公司、中国电子云、北京大学、复旦大学、南方电网、中国航信、国双科技等单位和学校的领导和专家,共同探讨面向人工智能+的数据汇聚、生产、挖掘、交易、流通的新路径,探索关于行业数据建设和模型训练、数据应用平台建设、数据智慧运营的新思路。同时,大会现场发布了“北京人工智能数据运营平台”(包括平台上线、重磅数据集开源和数据工具FlagData3.0),并启动了“行业数据集—场景应用创新计划”,为千行百业大模型落地构筑重要的数据基础。
构建平台能力,创新运营模式
北京人工智能数据运营平台:支持三种数据使用模式
本次论坛上,智源研究院联手京能数字产业有限公司(下简称京能数产)发布了北京人工智能数据运营平台。北京人工智能数据运营平台是在国家发展改革委、国家数据局指导下,北京市发展改革委主导,市委网信办、市科委、市经信局、海淀区政府、中国网络空间安全协会人工智能安全治理专委会等单位支持推动,由智源研究院牵头与京能数产等单位共建。数据平台实现数据的汇聚管理、处理加工,并提供多种模态的数据标注支持,支持多种数据汇聚和使用形式,不断扩充数据规模,为大模型行业发展提供坚实的数据支撑。
目前,数据运营平台支持开源开放、积分共享、数算一体三种数据运营模式。“开源开放”模式允许用户在遵守使用协议的前提下自由下载使用。“积分共享”模式面向数据工作组内的成员,根据数据贡献实行积分制,即成员单位贡献数据,按照计分标准获取相应积分,同时获得共享数据的权益。“数算一体”模式针对高价值数据,仅在平台上进行数据加工、训练使用,保证数据不出安全域。
开源超大规模高质量数据集
1、全球最大的多行业中英双语数据集IndustryCorpus 1.0,
本次论坛上,智源研究院发布全球最大的多行业中英双语数据集IndustryCorpus 1.0 ,大幅度提升了全球开源行业数据集的数据量,为大模型的行业落地提供了强有力的保障。同时,智源选取医疗行业数据集,完成了示范模型训练,取得了优异的模型行业能力提升,为行业模型训练提供高质量范例和参考。
当前,大模型在行业应用时面临着核心的挑战——海量、优质的行业数据集严重匮乏。行业数据具有特殊性、稀缺性的特点。特殊性是由于其包含了领域特有的知识、术语、规则、流程和逻辑,这些特性往往难以在通用数据集中充分覆盖。稀缺性是指行业数据严重短缺。当前已知的所有开源行业数据集(文本类)仅有约1.2TB,远远无法满足千行百业的模型需求。因此,智源研究院在过去半年不断积累,致力于打造多行业训练数据集IndustryCorpus。
IndustryCorpus 1.0数据集包含3.4TB开源的行业预训练数据(中文1TB,英文2.4TB),0.9TB的非开源定向申请的行业预训练数据,以及医疗和教育两个领域的开源高质量指令微调数据共61.3万条。IndustryCorpus 1.0的发布,大幅提升了全球开源行业数据集的数据量和丰富度,改善开源行业数据集匮乏的现状,显著增加公共领域高质量行业数据的可获取性,为企业、开发者、科研人员提供了具备行业特性、内容丰富、安全的训练资源,减少开发成本,提高开发效率,助力大模型快速向行业应用阶段发展。
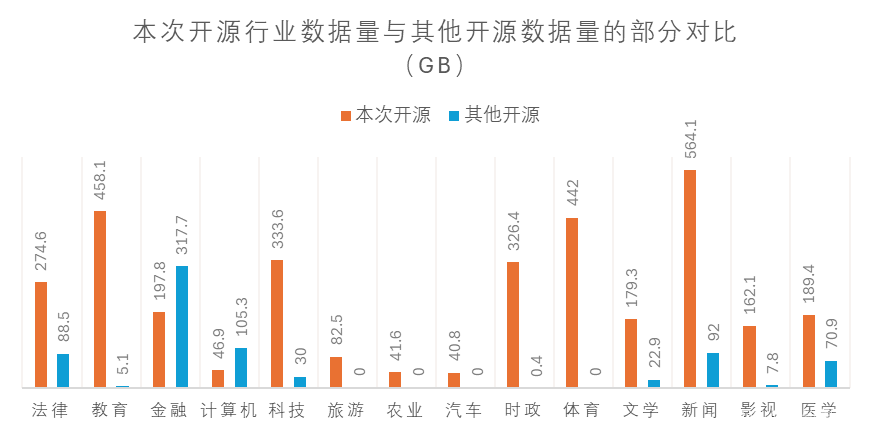
图1 本次开源行业数据量与其他开源数据量的部分对比(GB)
IndustryCorpus 1.0覆盖了18类行业的预训练数据集,其中科技类334GB,法律类275GB,医学类189GB,金融类198GB,新闻类564GB。除此之外,还包含教育、旅游、体育、汽车等,未来将进一步扩展至30类行业。同步发布的还有医疗和教育两个领域的指令微调数据集。IndustryCorpus 1.0的发布,有望大幅提升模型在专业领域的知识性,助力大模型的行业落地应用。

图2 本次开源行业数据集按行业分布情况
为验证行业数据集应用效果,智源选取医疗行业数据集进行示范模型训练。智源基于Aquila通用模型完成继续预训练、SFT训练和RLHF训练,取得了优异的模型行业能力提升。对比继续预训练前的模型,在客观指标方面,采用医疗行业数据集经过继续预训练、SFT和DPO之后的示范医疗模型总体医疗能力提升20.1%(见图3)。在主观评测方面,在经过医疗行业SFT数据和DPO数据的训练后,示范医疗对话模型能力胜率达到82.2%,5分制多轮对话能力CMTMedQA评分达到4.45(见图4)。综上,行业数据集在一定程度上解决了用户行业数据获取难、训练效果不佳的难题。

图3 客观指标方面,采用医疗行业预训练数据集继续预训练、SFT和DPO之后的示范医疗模型总体医疗能力提升20.1%

图4 主观评测方面,经过医疗行业SFT数据和DPO数据训练后,示范医疗对话模型能力胜率达到82.2%
2、启动千万级指令微调数据集 InfinityInstruct 的开源项目
高质量的指令数据是大模型性能的“养料”。本次论坛上,智源研究院发布的千万级高质量指令微调数据集开源项目,包括基于开源数据集进行高质量筛选的数据,和通过数据合成方法构造的高质量指令数据。智源对现有开源数据进行领域分析确保合理类型分布,对大规模数据进行质量筛选保留高价值数据,针对开源数据缺乏的领域和任务,进行数据增广,并结合人工标注对数据质量进行控制,避免合成数据分布偏差。本次大会开源首批300万条经过模型验证的高质量中英文指令数据InfInstruct-3M,并将在未来一个月内完成 InfinityInstruct 千万条指令数据的全部验证和开源。为了验证InfInstruct-3M的质量,我们在Mistral-7B上面进行微调训练得到对话模型InfInstruct-3M-Mistral-7B。在ApacheEval的评测中,该模型明显优于其它同量级的对话模型(见图5)。这意味着,用户可以使用InfInstruct数据集,再加以自有应用数据,对基础模型进行微调,轻松获得专有的高质量中英双语对话模型。
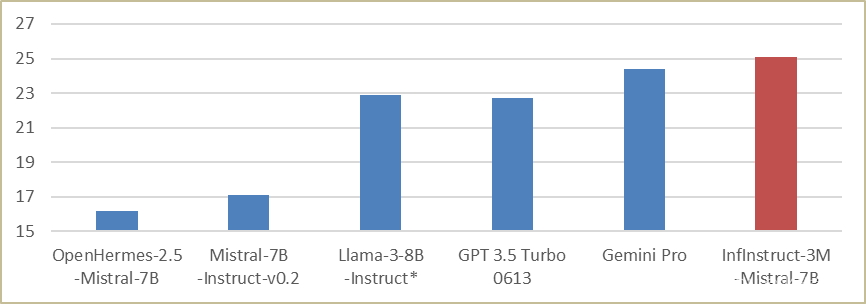
图5 使用ApacheEval评测对比多个对话模型的能力
3、构建通用数据集和行业数据集两大专区,满足用户不同需求
今年以来,智源汇聚了海量可直接用于算法训练的通用数据集和行业数据集。本次论坛上,智源发布通用数据集和行业数据集两大专区。
通用数据集为用于通用基础模型训练的多种模态数据。当前已经汇聚在数据运营平台的通用数据集有116个,总数据量700.27TB,其中文本数据9.76TB,多模态图文数据量75.31TB,视频数据量615TB,音频数据0.2TB。
行业数据集包含了行业领域特有的知识和信息,用于训练各种行业模型,推动人工智能从通用向专业化、精细化持续发展。目前行业专区数据集28个,数据量4.33TB,其中文本数据集22个,数据量4.3TB,多模态图文行业数据集6个,数据量0.03TB。
4、全面升级数据处理工具FlagData3.0,助力数据高质量发展
数据质量直接决定了大模型的输出能力,使用数据处理工具不断提升数据质量变得日益重要。智源研究院长期投入数据建设工作,开发了一批数据处理的高效工具。FlagData数据工具·开源项目包含清洗、标注、压缩、统计分析等功能在内的多个数据处理工具与算法,为提升数据质量带来直接的便利。
本次论坛上,FlagaData2.0全面升级为FlagData 3.0,一方面提供了傻瓜式语言数据处理工具,支持一键式搭建数据处理工作流。另一方面,为专业的进阶用户提供数十种数据加工算子,支持自定义数据处理流程。
三、“行业数据集—场景应用创新计划”启动,加速千行百业大模型落地
为推动人工智能在各行业深入应用、为大模型行业落地提供数据支撑,本次论坛上,智源研究院和中国互联网协会、中国互联网协会人工智能工作委员会联合发布“行业数据集—场景应用创新计划”。向全国企业征集场景应用模型需求,定向提供高质量行业数据集,助力一批场景应用模型的创新。最后,将依据模型应用成果组织评选优秀案例。
这篇关于北京人工智能数据运营平台发布,并开源大规模数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







