scale专题
![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
引言 今天带来第一篇量化论文LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale笔记。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 大语言模型已被广泛采用,但推理时需要大量的GPU内存。我们开发了一种Int8矩阵乘法的过程,用于Transformer中的前馈和注意力投影层,这可以将推理所需

android xml之动画篇 alpha、scale、translate、rotate、set的属性及用法 和
1.简介 Android的补间动画TweenAnimation由四种类型组成:alpha、scale、translate、rotate,对应android官方文档地址:《Animation Resources》 逐帧动画 FrameAnimation(也称 Drawable Animation ):animation-list alpha 渐变透明度动画效果 scale 渐变
![Android AnimationDrawable资源 set[translate,alpha,scale,rotate]](https://img-blog.csdn.net/20170610181346934?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc29uZ3l1bG9uZzg4ODg=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
Android AnimationDrawable资源 set[translate,alpha,scale,rotate]
本文内容摘自《疯狂Android讲义 第三版-李刚著作》 xml <?xml version="1.0" encoding="utf-8"?><set xmlns:android="http://schemas.android.com/apk/res/android"android:duration="1000"android:fillAfter="true"android:f

CUICatalog: Invalid asset name supplied: (null), or invalid scale factor: 2.000000错误解决方案
[[UIImage imageNamed:@""] 当后面的字符串为空时,会出现题目中的错误 if (imagstr != nil) { cell.imageView.image =[UIImage imageNamed:imagstr]; }

《The Power of Scale for Parameter-Efficient Prompt Tuning》论文学习
系列文章目录 文章目录 系列文章目录一、这篇文章主要讲了什么?二、摘要中T5是什么1、2、3、 三、1、2、3、 四、1、2、3、 五、1、2、3、 六、1、2、3、 七、1、2、3、 八、1、2、3、 一、这篇文章主要讲了什么? The article “The Power of Scale for Parameter-Efficient Prompt Tuning

每日Attention学习16——Multi-layer Multi-scale Dilated Convolution
模块出处 [CBM 22] [link] [code] Do You Need Sharpened Details? Asking MMDC-Net: Multi-layer Multi-scale Dilated Convolution Network For Retinal Vessel Segmentation 模块名称 Multi-layer Multi-scale Dilate

MSRCR(Multi-Scale Retinex with Color Restore)
引言 始于Edwin Herbert Land(埃德温·赫伯特·兰德)于1971年提出的一种被称为色彩恒常的理论,并基于此理论的图像增强方法。Retinex这个词由视网膜(Retina)和大脑皮层(Cortex)合成而来.之所以这样设计,表明Land他也不清楚视觉系统的特性究竟取决于此两个生理结构中的哪一个,抑或两者都有关系。不同于传统的图像增强算法,如线性、非线性变换、图像锐化等只能增强图像

Large-Scale Relation Learning for Question Answering over Knowledge Bases with Pre-trained Langu论文笔记
文章目录 一. 简介1.知识库问答(KBQA)介绍2.知识库问答(KBQA)的主要挑战3.以往方案4.本文方法 二. 方法问题定义:BERT for KBQA关系学习(Relation Learning)的辅助任务 三. 实验1. 数据集2. Baselines3. Metrics4.Main Results 一. 简介 1.知识库问答(KBQA)介绍 知识库问答(KBQA
数据库学习笔记 --- 术语 Scale up 与 Scale out 区别
Scale Out(也就是Scale horizontally)横向扩展,向外扩展Scale Up(也就是Scale vertically)纵向扩展,向上扩展无论是Scale Out,Scale Up,Scale In,实际上就是一种架构的概念,这些概念用在存储上可以,用在数据库上,网络上一样可以。简单比喻下Scale out和Scale up,帮助我们理解:Scale Out,比如:我们

CV-Paper-增量学习-Large Scale Incremental Learning
目录 0 简介1 什么是偏差2 网络3 loss4 偏差矫正层 0 简介 就简单的说明一下好了,首先是使用蒸馏学习,然后再利用验证集来学习一个简单的线性变换 ax + b 来减少偏差。 这里是把验证集也拿过来训练了,虽然只是学习一个简单的线性变换,因为这个线性变换只有两个参数,所以需要的数据量非常少,虽然这个变换很简单,但是非常有效的提高精度。 文章中说的偏差指的是增量学习

使用SCALE分析单细胞ATAC-seq数据
SCALE全称是Single-Cell ATAC-seq analysis vie Latent feature Extraction, 从名字中就能知道这个软件是通过隐特征提取的方式分析单细胞ATAC-seq数据。 在文章中,作者从开发者的角度列出了目前的scATAC-seq分析软件,chromVAR, scABC, cisTopic, scVI,发现每个软件都有一定的不足之处,而从我们软件使

构建家庭NAS之二:TrueNAS Scale规划、安装与配置
首先声明一下,我用的版本是TrueNAS SCALE 24.04.1.1(目前的最新版本),其它版本的界面和操作方式或有不同。我安装使用过程中网上的一些教程里的操作方式和这个版本不一样,造成了一些困扰。 TrueNAS SCALE的最低硬件需求: 双核64位CPU8 GB内存(推荐16GB)16 GB SSD 系统盘2个相同容量的数据盘(其实1个盘也可以,后面细讲)不需要硬件RAID卡 存储
控件之Scale LabelScale
#ScaleScale 组件代表一个滑动条,可以为该滑动条设置最小值和最大值,也可以设置滑动条每次调节的步长。Scale 组件支持如下选项:from:设置该 Scale 的最小值。to:设置该 Scale 的最大值。resolution:设置该 Scale 滑动时的步长。label:为 Scale 组件设置标签内容。length:设置轨道的长度。width:设置轨道的宽度。tro
caffe中BatchNorm层和Scale层实现批量归一化(batch-normalization)注意事项
caffe中实现批量归一化(batch-normalization)需要借助两个层:BatchNorm 和 Scale BatchNorm实现的是归一化 Scale实现的是平移和缩放 在实现的时候要注意的是由于Scale需要实现平移功能,所以要把bias_term项设为true 另外,实现BatchNorm的时候需要注意一下参数use_global_stats,在训练的时候设为false,
Caffe Prototxt 特征层系列:Scale Layer
Scale Layer是输入进行缩放和平移,常常出现在BatchNorm归一化后,Caffe中常用BatchNorm+Scale实现归一化操作(等同Pytorch中BatchNorm) 首先我们先看一下 ScaleParameter message ScaleParameter {// The first axis of bottom[0] (the first input Blob) alo

【caffe转向pytorch】caffe的BN层+scale层=pytorch的BN层
caffe里面用BN层的时候通常后面接一下scale层,原因如下: caffe 中为什么bn层要和scale层一起使用 这个问题首先你要理解batchnormal是做什么的。它其实做了两件事。 输入归一化 x_norm = (x-u)/std, 其中u和std是个累计计算的均值和方差。 2)y=alpha×x_norm + beta,对归一化后的x进行比例缩放和位移。其中alpha和beta是

数据:人工智能的基石 | Scale AI 创始人兼 CEO 亚历山大·王的创业故事与行业洞见
引言 在人工智能领域,数据被誉为“新石油”,其重要性不言而喻。随着GPT-4的问世,AI技术迎来了新的浪潮。众多年轻创业者纷纷投身这一领域,Scale AI的创始人兼CEO亚历山大·王(Alexander Wang)就是其中的佼佼者。本文将深入探讨亚历山大的创业历程、对AI行业的见解以及他对未来的展望。 亚历山大·王的创业历程 亚历山大·王在19岁时就从麻省理工学院(MIT)辍学,创办了Sc

LSUN数据集(Large-Scale Scene Understanding)
LSUN数据集(Large-Scale Scene Understanding)是一个专为计算机视觉研究设计的大规模场景理解数据集。以下是对LSUN数据集的详细介绍: 创建与目的: LSUN数据集由斯坦福大学计算机视觉实验室创建,旨在为大规模场景理解问题提供数据支持。该数据集的设计初衷是为了满足深度学习和计算机视觉研究对大规模、多样性图像数据的需求,以训练出更准确、更强大的视觉模型。 数
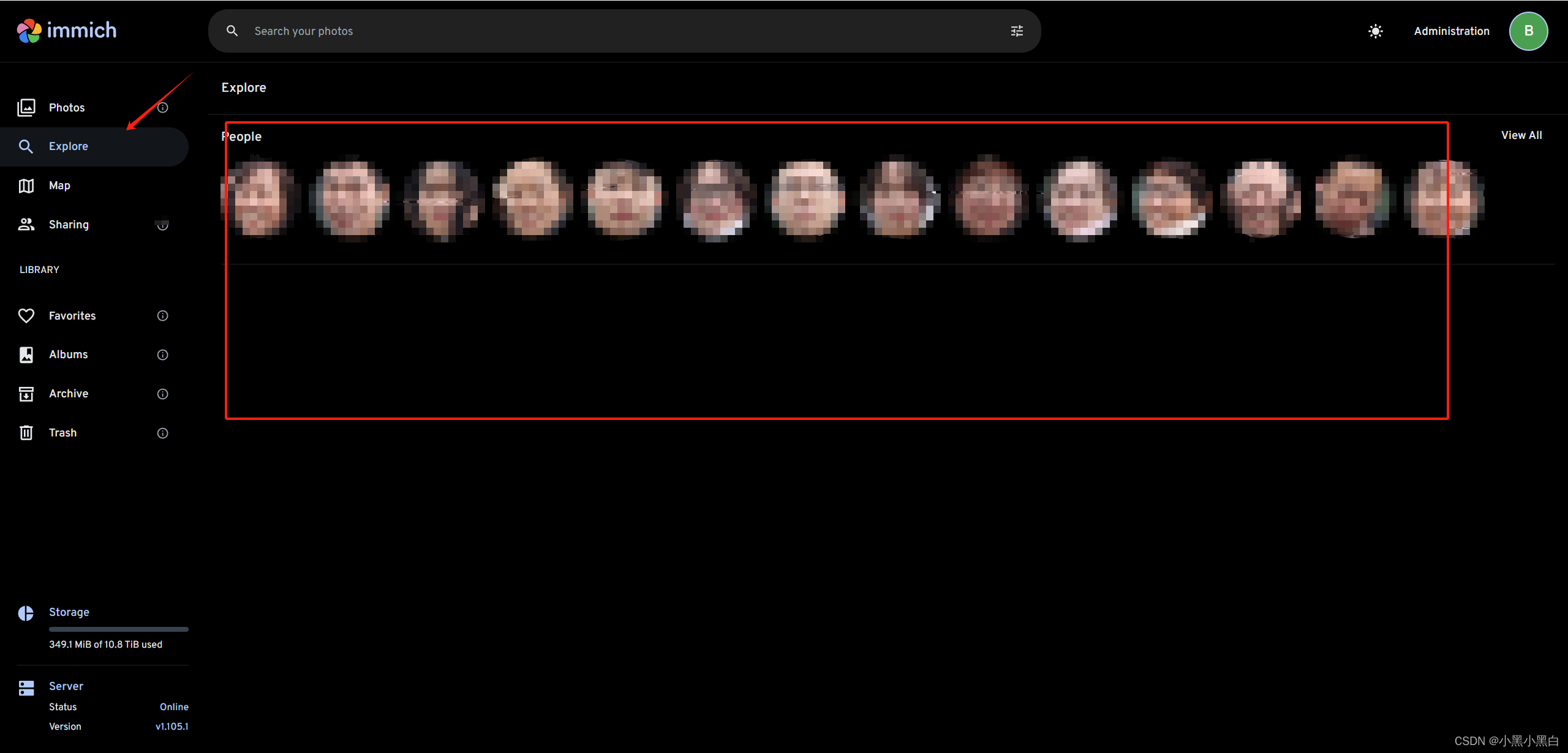
解决TrueNas Scale部署immich后人脸识别失败,后台模型下载异常,immich更换支持中文搜索的CLIP大模型
这个问题搞了我几天终于解决了,搜遍网上基本没有详细针对TrueNas Scale部署immich应用后,CLIP模型镜像下载超时导致人脸识别失败,以及更换支持中文识别的CLIP模型的博客。 分析 现象:TrueNas Scale安装immich官方镜像应用后,导入图片人脸识别失败,中文识别更不行,查看immich-machinelearning pod后台调用日志,显示huggingface.
sws_scale像素格式转换RGBA转YUV420P,并存入文件
#include <iostream>#include <fstream>using namespace std;extern "C" { //指定函数是c语言函数,函数名不包含重载标注//引用ffmpeg头文件#include <libswscale/swscale.h>}//预处理指令导入库#pragma comment(lib,"swscale.lib")#define

cicd 03--构建通用scale流程
cicd 03--构建通用scale流程 1 介绍2 cicd构建过程2.1 基本配置2.2 测试结果 3 注意事项4 说明 1 介绍 在实际项目中, 如果没有专用的变更系统,那么可以使用jenkins来快速实现各类基础流程,而且能够达到操作溯源的效果。本文基于jenkins做了一个简单的k8s服务scale流程,用于用户scale服务,同时达到操作溯源的目的。 2 cicd构
Comfyui工作流报错:Image scale to side 报错,安装了Derfuu-Nodes仍然没法运行
🎆问题描述 最近很多朋友在玩comfyui的时候,发现有个图像缩放的节点用不了了,同时报错: When loading the graph, the following node types were not found: Image scale to side Nodes that have failed to load will show as red on the graph. 看起
大屏幕适配方法之:transform:scale()
CSS3新增的属性transform主要用于设置元素的变形,比如旋转、倾斜、缩放等。我们今天要用到的正式它的缩放功能transform:scale() 取值 单一数值 单一的数值即指定了一个缩放系数,同时作用于 X 轴和 Y 轴让该元素进行缩放,相当于指定了单个值的 scale()(2D 缩放) 函数。 两个长度/百分比值 两个数值即分别指定了 2D 比例的 X 轴和 Y 轴的缩放系数,相
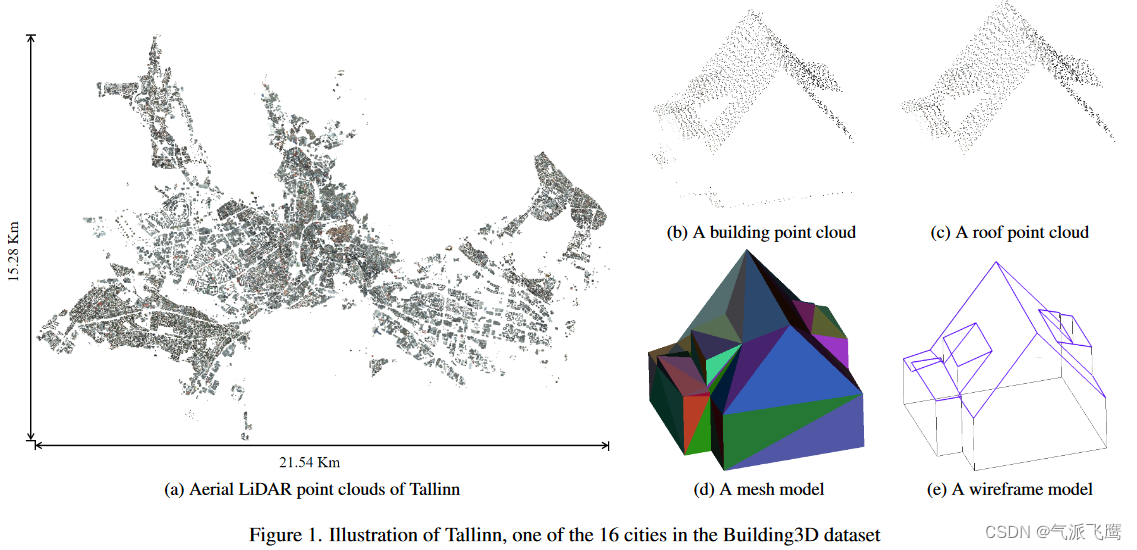
Building3D An Urban-Scale Dataset and Benchmarks 论文阅读
文章主页 Building3D 任务 提出了一个城市规模的数据集,由超过 16 万座建筑物以及相应的点云、网格和线框模型组成,覆盖爱沙尼亚的 16 个城市,面积约 998 平方公里。 动机 现有的3D建模数据集主要集中在家具或汽车等常见物体上。缺乏建筑数据集已成为将深度学习技术应用于城市建模等特定领域的主要障碍。 要点 数据集包含原始点云,建筑物点云,屋顶点云,以及网格模型和线框模
CGAffineTransfrom 1.transform 2.scale 3.Rotation
CGAffineTransfrom 包括三个东西:1.transform (移动)2.scale(缩放) 3.Rotation(旋转)